PDF Explained(翻译)第六章 文本和字体
Posted ball球
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PDF Explained(翻译)第六章 文本和字体相关的知识,希望对你有一定的参考价值。
本文是对PDF Explained(by John Whitington)第六章《Text And Fonts
》的摘要式翻译,并加入了一些自己的理解。
文本状态
文本状态相关的操作符和参数如下表所示:
| 操作符 | 操作数(参数) | 描述 | 默认值 | 例 |
|---|---|---|---|---|
| Tc | charSpace | Tc将字符间距设为charSpace | 0 |  |
| Tw | wordSpace | Tw将字符间距设为wordSpace | 0 |  |
| Tz | scale | Tz将水平缩放设置为scale/100 | 100(正常大小) | 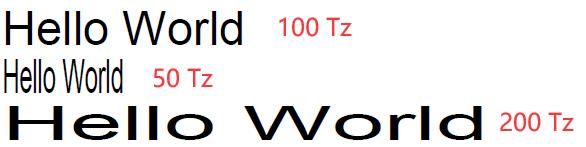 |
| TL | leading | TL将相邻两行文本行基线的垂直距离设为leading。只对T*和’'操作符产生作用。 | 0 |  |
| Tf | font, size | Tf设置字体为font, 字号为size。 | 无 | |
| Tr | render | Tr将文本渲染模式设为render(一个整数) | 0 | 详见手册5.2.5 Text Rendering Mode |
| Ts | rise | Ts将文本上升值设为rise | 0 | 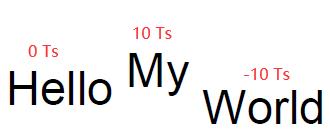 |
更多详细描述可参看手册5.2 Text State Parameters and Operators
文本状态与图形状态一起存储,使用上面的运算符进行操作。当前文本状态受堆栈运算符q和Q的影响。
打印文本
在页面上打印文本需要:
- 选择字体。
- 选择位置,大小和方向。
- 选择间距,颜色,文本渲染模式和其他参数。
- 从字体中选择字符,并在页面上显示。
文本段落
操作符BT表示文本落开始,ET为文本段落结束。用于在页面的内容流中显示文本的操作符只能出现在BT和ET之间。但是用于改变文本状态的操作符不受这种限制。 例:
1. 0. 0. 1. 50. 700. cm //Position at (50, 700)
BT //Begin text block
/F0 36. Tf //Select /F0 font at 36pt
(Hello, World!) Tj //Place the text string
ET //End text block
这里,我们使用Tf来选择字体及大小,使用Tj运算符来显示文本字符串。 我们依靠图形运算符cm来设置文本位置。现在,我们将讨论更改文本位置的其他方法。
文本空间和文本定位
显示文本的坐标系,就是文本空间。从文本空间到用户空间的转换决定了文本在页面上放置的位置。文本字符串中第一个字形的原点位于文本空间的原点。
有两种矩阵:
- 文本矩阵(Tm):定义了下一个字形的变换方式。可以通过文本定位操作符和文本显示操作符进行修改。
- 文本行矩阵(Tlm):当前行开头的文本矩阵的状态。
当开始一个新的文本段落时,矩阵会被重置为单位矩阵。这两个矩阵与字体大小,水平缩放和文本上升一起定义了从文本空间到用户空间的转换。
文本定位操作符如下表所示:
| 操作数 | 操作符 | 功能 |
|---|---|---|
| x, y | Td | 标识下一行文字的开始处,位置是从当前行的开始处偏移(x,y)。 |
| x, y | TD | 标识下一行文字的开始处,位置是从当前行的开始处偏移(x,y), 同时将前导(leadig)设为-y。x y TD等效于-y TL x y Td |
| - | T* | 移到下一行的开头。等效于0 leading Td, leading为当前的前导值。 |
| a,b,c,d,e,f | Tm | 将文本矩阵™和文本行矩阵(Tlm)设置为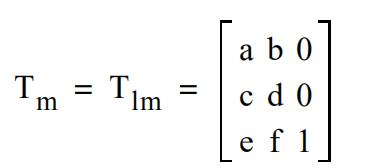 所有的操作数均为数字。 所有的操作数均为数字。 |
显示文本
Tj运算符在当前位置显示文本。为方便起见,提供了三个附加操作符(’,’'和TJ)。 下表为文本显示操作符:
| 操作数 | 操作符 | 功能 | 示例 |
|---|---|---|---|
| string | Tj | 在当前位置显示字符串 | |
| string | ’ | 移到下一行并显示文本字符串。等效于T* string Tj |  |
| wordspace, charspace, string | ‘’ | 移动到下一行并显示文本字符串,使用wordspace作为单词间距,charspace作为字符间距。等效于wordspace Tw charspace Tc string ' | |
| array | TJ | 允许调整单个字形的位置。数组里包含字串和数字。如果元素是字串则显示字串。如果是数字,数字的单位是文本空间单位的千分之一,会依据书写模式将其从当前的水平或垂直坐标中减去,从而改变下一个字形的位置。 |  |
一些例子
字符和单词间距
BT
/F0 36 Tf
1 0 0 1 120 350 Tm
50 TL
(Character and Word Spacing) Tj T*
3 Tc
(Character and Word Spacing) Tj T*
10 Tw
(Character and Word Spacing) Tj
ET
说明:
- 使用Tf设置字体/为F0,字号36。
- 使用Tm将文本位置设置为(120,350)
- 使用TL将前导设置为50
- 用Tj显示一个字符串,用T*移动到下一行
- 将字符间距设置为3,然后再次绘制字符串
- 将单词间距设置为10,并第三次绘制字符串
效果如下:

文本转换
在本例中,我们将展示文本转换如何与图形转换相结合。
0.96 0.25 -0.25 0.96 0 0 cm
BT
/F0 48 Tf
48 TL
1 0 0 1 270 240 Tm
(Text and graphics) Tj T*
(transforms combined) Tj T*
(with newlines) Tj
ET
说明:
- 使用cm设置图形矩阵,围绕原点逆时针旋转
- 使用Tf设置字体,TL设置前导
- 使用Tm设置文本矩阵,将起点设为(270,240)
- 使用Tj和T*写三行文本
效果如下:

文本提升
Ts运算符可用于调整文本的垂直位置:
BT
/F0 72 Tf
1 0 0 1 140 290 Tm
(Text) Tj
20 Ts
(Up) Tj
0 Ts
(and) Tj
-20 Ts
(Down) Tj
ET
效果如下:

字距和字形调整
TJ操作符可用于替代Tj,用于绘制具有水平字形调整的字符串。这种情况通常发生在使用文字处理器或打字机布局的情况下。TJ 操作符是一种对这些信息进行编码的便捷方法,无需再为每行文本使用数十个操作符:
BT
/F0 72 Tf
90 TL
1 0 0 1 240 330 Tm
[(PJ WAYNE)] TJ T*
[(P)150(J )(W)150(A)80(YN)20(E)] TJ
ET
我们在这里使了两次TJ; 一次显示文本正常,第二次调整了字距。结果如下图所示。

文本渲染模式
文本有八种渲染模式(译者注:原文是seven,但实际取值应该是0~7,原文应该是错的),可以使用Tr设置。其中四种用于将文本设置为剪切路径,一种用于编写不可见文本,这些不在本文讨论范畴。我们来看另外三种情况(模式0,1,2),别分用于区域填充,边缘填充,边缘加区域填充。
0.5 g
BT
/F0 72 Tf
1 0 0 1 160 380 Tm
90 TL
(Text Mode Zero) Tj T*
1 Tr
(Text Mode One) Tj T*
2 Tr
(Text Mode Two) Tj
ET
效果如下:

定义和嵌入字体
字体是特定字符集的字形(字符形状)的集合。在PDF中,字体由字体字典组成, 字典中定义了度量,字符集和编码(将文本字符串中的字符代码映射到字体中的字符),以及字体程序(实际的字体文件)。不同的类型字体(Type 1, TrueType等)有不同的存储格式。
PDF中的字体类型
PDF中可以使用大多数主流字体格式,包括
- Type 1字体
- TrueType字体
- Type 3字体
- CID字体
- OpenType字体
Type 1字体
我们以Type 1字体为例简要介绍下字体字典中的条目。下表中,*为必选项, **为14种标准字体以外的字体必选
| key | 值类型 | 值 |
|---|---|---|
| /Type* | 名称 | 必须是/Font |
| /Subtype* | 名称 | 必须是/Type1 |
| /BaseFont* | 名称 | 字体的PostScript名称 |
| /FirstChar** | 整数 | /Widths数组中的第一个编码 |
| /LastChar** | 整数 | /Widths数组中的最后一个编码 |
| /Widths** | 整数数组 | 数组长度为(/LastChar - /FirstChar + 1),给出这些字符的字形宽度,单位是以千分之一的文本空间单位。 |
| /FontDescriptor** | 间接引用字典 | 字体描述符字典,提供字体的度量(字形宽度除外) |
| /Encoding | 名称字典 | 字体的字符编码,例如/MacRomanEncoding或/WinAnsiEncoding。 |
| /ToUnicode | 流 | 一个包含了用于提取文本内容指令的流。 |
有14种标准的Type 1字体是所有PDF应用都必须支持的。不过,目前Adobe建议将所有的字体嵌入文档,即使这些标准字体也不例外。以下是标准字体列表:
- Times-Roman
- Times-Bold
- Times-Italic
- Times-BoldItalic
- Helvetica
- Helvetica-Bold
- Helvetica-Oblique
- Helvetica-BoldOblique
- Courier
- Courier-Bold
- Courier-Oblique
- Courier-BoldOblique
- Symbol
- ZapfDingbats
下面是一个Tyep 1字体的简单示例:
1 0 obj
<< /Type /Font
/Subtype /Type1
/BaseFont /Times-Roman
/FirstChar 0
/LastChar 255
/Widths [ 255 255 255 255 ... 744 268 380 380 380 380 380 380 380 380 380 380 ]
/FontDescriptor 2 0 R
/Encoding /WinAnsiEncoding
>>
省略号…是我们省略的内容,不是PDF语言的一部分。稍后我们将讨论/FontDescriptor和/Encoding。该字体共有256个字符,/Widths数组为每个字符提供宽度值。
字体编码
字体编码描述字符编码(内容流字符串中的字符)和字体中的字形描述之间的映射。
最简单的/Encoding可以只是一个标准编码的名子,这些编码在PDF标准文档的附录D中定义。更复杂的编码则需要通字典来定义。下表列出了编码字典中的条目:
| key | 值类型 | 值 |
|---|---|---|
| /Type | 名称 | 必须是/Encoding |
| /BaseEncoding | 名称 | 基础编码,/Differences用于定义与该基础编码的差异。可以是预定义编码之一,包括/MacRomanEncoding, /MacExpertEncoding, /WinAnsiEncoding。如果基础编码不存在,则/Differences用来描述与自字体文件内置编码的差异。 |
| /Differences | 整数和名称的数组 | 定义与基础编码的差异。包含0个或多个部分,每个部分以数字n开头,后跟字符n,n + 1,n + 2等的字形名称。例如[6 /endash /emdash 34 /space] 表示6映射到/endash,7映射到/emdash,34映射到/space。 |
在下面的示例中,字体的编码定义了与内置字体编码的区别,将字符1 替换为字符/bullet(项目符号点)。这意味着PDF 查看器可以正确剪切和粘贴文本,因为它知道字符编码1是一个项目符号( /bullet是在Adobe Glyph List中预定义的名称)。
25 0 obj
<< /Type /Font
/Subtype /Type1
/Encoding 23 0 R //Reference to the encoding dictionary
/BaseFont /Symbol
/ToUnicode 24 0 R //Instructions for conversion to Unicode
>>
endobj
23 0 obj //Encoding dictionary
<< /Type /Encoding
/BaseEncoding /WinAnsiEncoding //The base encoding
/Differences [ 1 /bullet ] //The differences
>>
endobj
嵌入字体
创建PDF文件时,必须嵌入字体。我们需要如下步骤:
- 提取字体文件中的各种细节–这些细节用于填写字体字典,字体度量和字体编码字典。
- 如果字体格式允许,则从相关字体文件中删除这些细节,只留下字形描述–所有这些信息现在都在字体字典中。这减小了嵌入字体的大小。
- 可以只保留字体的子集,删除整个字形描述,将字体文件减少到一个只包含实际使用的字符的文件。
下例给出了嵌入字体的示例。
9 0 obj
<</Type /Font
/Subtype /TrueType It's a TrueType font
/BaseFont /GCCBBY+TT8Et00 Font is TT8Et00. GCCBBY+ prefix identifies as a subset font.
/FontDescriptor 8 0 R
/FirstChar 1 There are 41 characters in this font.
/LastChar 41
/Widths
[603 603 603 603 603 603 603 603 603 603 603 603 603 603 The widths. It's a fixed-width font.
603 603 603 603 603 603 603 603 603 603 603 603 603 603
603 603 603 603 603 603 603 603 603 603 603 603 603]
/Encoding 14 0 R
>>
14 0 obj The font encoding
<< /Type /Encoding
/BaseEncoding /WinAnsiEncoding The base encoding
/Differences The changes. In this case, it's a subset font with the characters at position 1 onward.
[1 /w /i /d /g /e /t /s /T /h /space /r /u /l /a /x /bracketleft
/underscore /J /o /n /S /m /quotesingle /A /p /c /bracketright
/one /colon /braceleft /b /k /braceright /v /period /parenleft
/two /parenright /asterisk /y /P]
>>
endobj
8 0 obj The font descriptor, giving the remaining metrics.
<< /Type /FontDescriptor
/FontName /GCCBBY+TT8Et00
/FontBBox [0 -205 602 770]
/Flags 4
/Ascent 770
/CapHeight 770
/Descent -205
/ItalicAngle 0
/StemV 90
/MissingWidth 602
/FontFile2 12 0 R The actual font file, here in TrueType format.
>>
endobj
从文档中提取文本
通常在文件的字体词典中会包含足够的信息以便 获取实际字符标识(而不仅仅是字形)。这对于Adobe Reader一类的PDF阅读应用
非常重要,因为有了这些信息用户才可以进行文本搜索和复制。
有两种机制实现这一点:
- 字体中的/Encoding条目(将字符编码映射到Adobe字形列表,比如/bullet)。
- 更先进的机制,/ToUnicode条目,提供一段程序,其语言由Adobe定义。程序字符代码直接映射到Unicode实体。以下是/ToUnicode程序的示例:
23 0 obj
<< /Length 317 >>
stream
/CIDInit /ProcSet findresource begin 12 dict begin begincmap /CIDSystemInfo <<
/Registry (Symbol+0) /Ordering (T1UV) /Supplement 0 >> def
/CMapName /Symbol+0 def
1 begincodespacerange <01> <01> endcodespacerange
1 beginbfrange
<01> <01> <2022> //Maps character code 1 to Unicode U+2022, the bullet point.
endbfrange
endcmap CMapName currentdict /CMap defineresource pop end end
endstream
endobj
提取文本的另一个难点是重构内容流中的文本操作符。为了调整字距或对齐等原因,操作符会将文本时行拆分,行尾的连字符可能会中断字符流。文本操作符甚至有可能出现乱序。不过,大多通常情况下都可以顺利完成文本重建。
译者推荐阅读
文本空间和文本定位一节中提到了文本矩阵,以下材料有助于你更好的理解这种转换矩阵
- Text Operators, The Tm Operator一节讲述了矩阵中abcdef的意义。
- How to read a PDF text matrix, Affine transformation这两篇有助于你理解如何通过矩阵对文本进行各种拉伸,旋转操作。
- 如果你还想了解更多和本章相关的细节,可以阅读手册第五章
以上是关于PDF Explained(翻译)第六章 文本和字体的主要内容,如果未能解决你的问题,请参考以下文章