《Python深度学习》第五章-2(Cats_vs_Dogs)读书笔记
Posted Paul-Huang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《Python深度学习》第五章-2(Cats_vs_Dogs)读书笔记相关的知识,希望对你有一定的参考价值。
5.2 在小型数据集上从头开始训练一个卷积神经网络
5.2.1 深度学习与小数据问题的相关性
- 深度学习的一个基本特性就是能够独立地在训练数据中找到有趣的特征,无须人为的特征工程,而这只在拥有大量训练样本时才能实现。对于输入样本的维度非常高(比如图像)的问题尤其如此。
- 但如果模型很小,并做了很好的正则化,同时任务非常简单,那么几百个样本可能就足够了。
- 由于卷积神经网络学到的是 局 部 的 、 平 移 不 变 的 特 征 \\color{red}局部的、平移不变的特征 局部的、平移不变的特征,它对于感知问题可以高效地利用数据。
- 深度学习模型本质上具有高度的 可 复 用 性 \\color{red}可复用性 可复用性。
- 本节将重点讨论猫狗图像分类,数据集中包含 8000 张猫和狗的图像(4000 张猫的图像,4000 张狗的图像)。我们将 4000 张图像用于训练,2000 张用于验证,2000张用于测试。
- 大概流程:
- 首先,在 2000 个训练样本上训练一个简单的小型卷积神经网络,不做任何正则化,为模型目标设定一个基准。
-然 后,使用 数 据 增 强 ( d a t a a u g m e n t a t i o n ) \\color{red}数据增强(data augmentation) 数据增强(dataaugmentation),它在计算机视觉领域是一种非常强大的降低过拟合的技术。 - 最后,用 预 训 练 的 网 络 做 特 征 提 取 \\color{red}预训练的网络做特征提取 预训练的网络做特征提取, 对 预 训 练 的 网 络 进 行 微 调 \\color{red}对预训练的网络进行微调 对预训练的网络进行微调。
- 首先,在 2000 个训练样本上训练一个简单的小型卷积神经网络,不做任何正则化,为模型目标设定一个基准。
5.2.2 下载数据
Cat_vs_Dog数据下载:
- 链接:https://pan.baidu.com/s/1KGfmMjVxgDbcIM_aUvhocw 提取码:ai6u
import os, shutil
# 原始数据集解压目录的路径
original_dataset_dir = 'C:\\\\Users\\\\Administrator\\\\Python_learning\\\\kaggle_original_data'
# 保存较小数据集的目录
base_dir = 'C:\\\\Users\\\\Administrator\\\\Python_learning\\\\cats_and_dogs_small'
os.mkdir(base_dir)
# 分别对应划分后的训练、验证和测试的目录
train_dir = os.path.join(base_dir, 'train')
os.mkdir(train_dir)
validation_dir = os.path.join(base_dir, 'validation')
os.mkdir(validation_dir)
test_dir = os.path.join(base_dir, 'test')
os.mkdir(test_dir)
# 猫的训练图像目录
train_cats_dir = os.path.join(train_dir, 'cats')
os.mkdir(train_cats_dir)
# 狗的训练图像目录
train_dogs_dir = os.path.join(train_dir, 'dogs')
os.mkdir(train_dogs_dir)
# 猫的验证图像目录
validation_cats_dir = os.path.join(validation_dir, 'cats')
os.mkdir(validation_cats_dir)
# 狗的验证图像目录
validation_dogs_dir = os.path.join(validation_dir, 'dogs')
os.mkdir(validation_dogs_dir)
# 猫的测试图像目录
test_cats_dir = os.path.join(test_dir, 'cats')
os.mkdir(test_cats_dir)
# 狗的测试图像目录
test_dogs_dir = os.path.join(test_dir, 'dogs')
os.mkdir(test_dogs_dir)
# 将前 2000 张猫的图像复制到 train_cats_dir
fnames = ['cat.{}.jpg'.format(i) for i in range(2000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(train_cats_dir, fname)
shutil.copyfile(src, dst)
# 将接下来 1000 张猫的图像复制到 validation_cats_dir
fnames = ['cat.{}.jpg'.format(i) for i in range(2000, 3000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(validation_cats_dir, fname)
shutil.copyfile(src, dst)
# 将接下来的 1000 张猫的图像复制到 test_cats_dir
fnames = ['cat.{}.jpg'.format(i) for i in range(3000, 4000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(test_cats_dir, fname)
shutil.copyfile(src, dst)
# 将前 2000 张狗的图像复制到 train_dogs_dir
fnames = ['dog.{}.jpg'.format(i) for i in range(2000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(train_dogs_dir, fname)
shutil.copyfile(src, dst)
# 将接下来 1000 张狗的图像复制到 validation_dogs_dir
fnames = ['dog.{}.jpg'.format(i) for i in range(2000, 3000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(validation_dogs_dir, fname)
shutil.copyfile(src, dst)
# 将接下来 1000 张狗的图像复制到 test_dogs_dir
fnames = ['dog.{}.jpg'.format(i) for i in range(3000, 3000)]
for fname in fnames:
src = os.path.join(original_dataset_dir, fname)
dst = os.path.join(test_dogs_dir, fname)
shutil.copyfile(src, dst)
5.2.3 构建网络
-
建立网络
面对的是一个二分类问题,所以网络最后一层是使用 sigmoid 激活的单一单元(大小为1 的 Dense 层)。from tensorflow.keras import layers from tensorflow.keras import models model = models.Sequential() model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(150, 150, 3))) model.add(layers.MaxPooling2D((2, 2))) model.add(layers.Conv2D(64, (3, 3), activation='relu')) model.add(layers.MaxPooling2D((2, 2))) model.add(layers.Conv2D(128, (3, 3), activation='relu')) model.add(layers.MaxPooling2D((2, 2))) model.add(layers.Conv2D(128, (3, 3), activation='relu')) model.add(layers.MaxPooling2D((2, 2))) model.add(layers.Flatten()) model.add(layers.Dense(512, activation='relu')) model.add(layers.Dense(1, activation='sigmoid'))model.summary()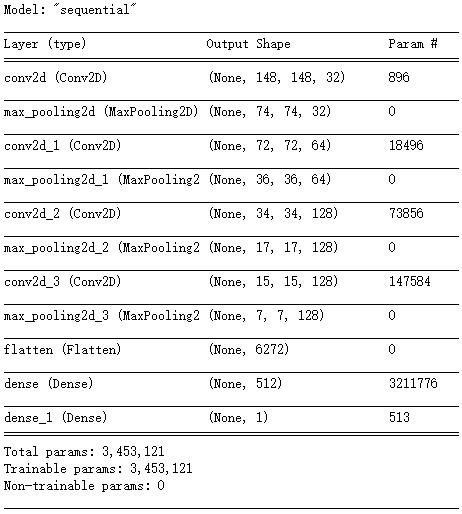
-
配置模型用于训练
因为网络最后一层是单一 sigmoid单元,所以我们将使用 二 元 交 叉 熵 作 \\color{red}二元交叉熵作 二元交叉熵作为损失函数。
from tensorflow.keras import optimizers model.compile(loss='binary_crossentropy', optimizer=optimizers.RMSprop(lr=1e-4), metrics=['acc'])
5.2.4 数据预处理
-
数据预处理基本步骤:
- 读取图像文件。
- 将 JPEG 文件解码为 RGB 像素网格。
- 将这些像素网格转换为浮点数张量。
- 将像素值(0~255 范围内)缩放到 [0, 1] 区间(正如你所知,神经网络喜欢处理较小的输入值)。
- Keras 拥有自动完成这些步骤的工具。Keras有一个图像处理辅助工具的模块,位于
keras.preprocessing.image。 - keras.preprocessing.image它包含ImageDataGenerator 类,可以快速创建 P y t h o n 生 成 器 \\color{red}Python 生成器 Python生成器,能够将硬盘上的图像文件自动转换为 预 处 理 好 的 张 量 批 量 \\color{red}预处理好的张量批量 预处理好的张量批量。
-
P
y
t
h
o
n
生
成
器
(
P
y
t
h
o
n
g
e
n
e
r
a
t
o
r
)
\\color{red}Python 生成器(Python generator)
Python生成器(Pythongenerator)是一个类似于迭代器的对象,一个可以和
for ...in运算符一起使用的对象。生成器是用yield运算符来构造的。
from tensorflow.keras.preprocessing.image import ImageDataGenerator # 将所有图像乘以 1/255 缩放 train_datagen = ImageDataGenerator(rescale=1./255) test_datagen = ImageDataGenerator(rescale=1./255) train_generator = train_datagen.flow_from_directory( train_dir, #目标目录 target_size=(150, 150), #将所有图像的大小调整为 150×150 batch_size=20, class_mode='binary') #因为使用了 binary_crossentropy损失,所以需要用二进制标签 validation_generator = test_datagen.flow_from_directory( validation_dir, target_size=(150, 150), batch_size=20, class_mode='binary')
-
Python批量生成器
for data_batch, labels_batch in train_generator: print('data batch shape:', data_batch.shape) print('labels batch shape:', labels_batch.shape) break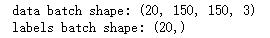
- Python生成器 在此处生成了
150×150的 RGB 图像[形状为(20,150, 150, 3)]与二进制标签[形状为(20,)]组成的批量。每个批量中包含 20 个样本(批量大小)。 -
生
成
器
会
不
停
地
生
成
这
些
批
量
\\color{red}生成器会不停地生成这些批量
生成器会不停地生成这些批量,它会不断循环目标文件夹中的图像。因此,需要在某个时刻终止(
break)迭代循环。
- Python生成器 在此处生成了
-
利用批量生成器拟合模型
history = model.fit_generator( train_generator, steps_per_epoch=200, # steps_per_epoch * batch_size = 4000(训练数据为4000) epochs=30, validation_data=validation_generator, validation_steps=50)fit_generator方法来拟合,它在数据生成器上的效果和fit相同。fit_generator参数:
- 第一个参数是Python 生成器:可以不停地生成输入和目标组成的批量,比如train_generator。
- 第二个参数是steps_per_epoch:从生成器中抽取steps_per_epoch个批量后(即运行了steps_per_epoch次梯度下降),拟合过程将进入下一个轮次。本例中,每个批量包含 20 个样本,所以读取完所有 4000 个样本需要 200个批量。
- 第三个参数是validation_data:这个参数可以是一个数据生成器,但也可以是 Numpy 数组组成的元
组。 如果向 validation_data 传入一个生成器,那么这个生成器应该能够不停地生成验证数据批量,因此你还需要指定validation_steps参数,说明需要从验证生成器中抽取多少个批次用于评估。
-
保存模型
model.save('cats_and_dogs_small_1.h5') -
绘制训练过程中的损失曲线和精度曲线
import matplotlib.pyplot as plt acc = history.history['acc'] val_acc = history.history['val_acc'] loss = history.history['loss'] val_loss = history.history['val_loss'] epochs = range(1, len(acc) + 1) plt.plot(epochs, acc, 'bo', label='Training acc') plt.plot(epochs, val_acc, 'b', label='Validation acc') plt.title('Training and validation accuracy') plt.legend() plt.figure() plt.plot(epochs, loss, 'bo', label='Training loss') plt.plot(epochs, val_loss, 'b', label='Validation loss') plt.title('Training and validation loss') plt.legend() plt.show()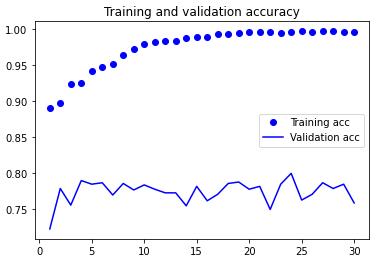
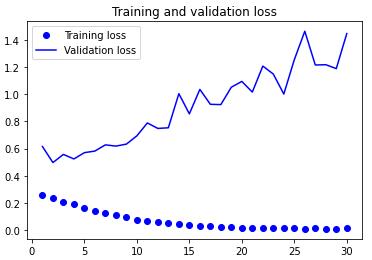
这些图像中都能看出过拟合的特征。训练精度随着时间线性增加,直到接近 100%,而验证精度则停留在 70%~72%。验证损失仅在 5 轮后就达到最小值,然后保持不变,而训练损失则一直线性下降,直到接近于 0。
5.2.5 使用数据增强
-
数据增强的定义:
数据增强是从现有的训练样本中生成更多的训练数据,其方法是利用多种能够生成可信图像的随机变换来增加
(augment)样本。 -
数据增强的目标: 模 型 在 训 练 时 不 会 两 次 查 看 完 全 相 同 的 图 像 。 \\color{red}模型在训练时不会两次查看完全相同的图像。 模型在训练时不会两次查看完全相同的图像。让模型能够观察到数据的更多内容,从而具有更好的泛化能力。
-
在 Keras 中,通过对
ImageDataGenerator读取的图像执行多次随机变换来实现。例如:datagen = ImageDataGenerator( rotation_range=40, width_shift_range=0.2, height_shift_range=0.2, shear_range=0.2, zoom_range=0.2, horizontal_flip=True, fill_mode='nearest')rotation_range是角度值(在 0~180 范围内),表示图像随机旋转的角度范围。width_shift和height_shift是图像在水平或垂直方向上平移的范围(相对于总宽度或总高度的比例)。shear_range是随机错切变换的角度。zoom_range是图像随机缩放的范围。horizontal_flip是随机将一半图像水平翻转。如果没有水平不对称的假设(比如真实世界的图像),这种做法是有意义的。fill_mode是用于填充新创建像素的方法,这些新像素可能来自于旋转或宽度/高度平移。
-
显示几个随机增强后的训练图像
# 图像预处理工具的模块 from tensorflow.keras.preprocessing import image fnames = [os.path.join(train_cats_dir, fname) for fname in os.listdir(train_cats_dir)] # 选择一张图像进行增强 img_path = fnames[3] # 读取图像并调整大小 img = image.load_img(img_path, target_size=(150, 150)) # 将其转换为形状 (150, 150, 3) 的 Numpy 数组 x = image.img_to_array(img) # 将其形状改变为 (1, 150, 150, 3) x = x.reshape((1,) + x.shape) #生成随机变换后的图像批量。 #循环是无限的,因此你需要在某个时刻终止循环 i = 0 for batch in datagen.flow(x, batch_size=1): plt.figure(i) imgplot = plt.imshow(image.array_to_img(batch[0])) i += 1 if i % 4 == 0: break plt.show()
-
增加过dropout层,降低过拟合
为了进一步降低过拟合,你还需要向模型中添加一个Dropout层,添加到密集连接分类器之前。
定义一个包含dropout的新卷积神经网络:model = models.Sequential() model.add(layers.Conv2D(32,