unittest测试数据驱动ddtbing
Posted 鸟随二月
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了unittest测试数据驱动ddtbing相关的知识,希望对你有一定的参考价值。
文章目录
概述
unittest框架是基于UI界面层的单元功能测试框架(黑盒测试)(可以批量执行,与之相似的另一个是)
Java单元测试框架JUnit(白盒测试)
组成
(1)测试固件
setUp()进行初始化工作
tearDown()进行测试完后的清理工作
(2)TestCase测试用例
测试方法: test_
(3)批量执行
把多个测试用例(可以是一个脚本中,也可以是多个脚本中)放到一个测试套件中去执行。
(4)执行测试用例
TestRunner
(5)生成测试报告htmlRunner
代码示例
from selenium import webdriver
import unittest
import time
class Baidu1(unittest.TestCase):
# 测试固件
def setUp(self):
print("-----setUp-----")
self.driver = webdriver.Chrome()
self.url = "https://www.baidu.com/"
self.driver.maximize_window()
time.sleep(3)
def tearDown(self):
print("-----tearDown-----")
self.driver.quit()
# 测试用例
def test_hao(self):
driver = self.driver
url = self.url
driver.get(url)
driver.find_element_by_link_text("hao123").click()
time.sleep(6)
if __name__ == "__main__":
unittest.main(verbosity=0)
verbosity 是一个选项, 表示测试结果的信息复杂度,有三个值:
0 ( 静默模式): 你只能获得总的测试用例数和总的结果比如总共100个失败,20 成功80
1 ( 默认模式): 非常类似静默模式只是在每个成功的用例前面有个“ . ” 每个失败的用例前面有个“F”
2 ( 详细模式): 测试结果会显示每个测试用例的所有相关的信息
‘’’
addTest() 的应用
当有多个或者几百测试用例的时候, 这样就需要一个测试容器( 测试套件) ,把测试用例放在该容器中进行执行,unittest 模块中提供了TestSuite 类来生成测试套件,使用该类的构造函数可以生成一个测试套件的实例,该类提供了addTest来把每个测试用例加入到测试套件中。
将Baidu1.py等放在同一个目录testcase中
# -*- coding: utf-8 -*-
import unittest
import time
import Baidu1
# 手工添加案例到套件,
def createsuite():
suite = unittest.TestSuite()
# 将测试用例加入到测试容器(套件)中
suite.addTest(Baidu1.Baidu1("test_hao"))
return suite
if __name__ == "__main__":
suite = createsuite()
runner = unittest.TextTestRunner(verbosity=2)
runner.run(suite)
makeSuite()
在unittest 框架中提供了makeSuite() 的方法,makeSuite可以实现把测试用例类内所有的测试case组成的测试套件TestSuite ,unittest 调用makeSuite的时候,只需要把测试类名称传入即可。
addTest() 的应用中的createuite改为
# 手工添加案例到套件,
def createsuite():
suite = unittest.TestSuite()
# 将Baidu1类中的所有测试案例加入进来
suite.addTest(unittest.makeSuite(Baidu1.Baidu1))
return suite
TestLoader
TestLoader 用于创建类和模块的测试套件,一般的情况下,使TestLoader().loadTestsFromTestCase(TestClass)来加载测试类。
addTest() 的应用中的createuite改为
def createsuite():
suite1 = unittest.TestLoader().loadTestsFromTestCase(Baidu1.Baidu1)
suite = unittest.TestSuite([suite1])
return suite
discover()的应用
discover 是通过递归的方式到其子目录中从指定的目录开始, 找到所有测试模块并返回一个包含它们对象的TestSuite ,然后进行加载与模式匹配唯一的测试文件,discover 参数分别为
discover(dir,pattern,top_level_dir=None)
addTest() 的应用中的createuite改为
#手工添加案例到套件,
def createsuite():
discover=unittest.defaultTestLoader.discover('../test',pattern='test*.py',top_level_dir=None)
print discover
return discover
测试用例的顺序
unittest 框架默认加载测试用例的顺序是根据ASCII 码的顺序,数字与字母的顺序为: 09,AZ,a~z 。
所以, TestAdd 类会优先于TestBdd 类被发现, test_aaa() 方法会优先于test_ccc() 被执行。对于测试目录与测试文件来说, unittest 框架同样是按照这个规则来加载测试用例。
忽略测试用例
测试用例代码示例
@unittest.skip("skipping")
def test_baidusearch(self):
driver = self.driver
driver.get(self.base_url + "/")
driver.find_element_by_id("kw").click()
driver.find_element_by_id("kw").clear()
driver.find_element_by_id("kw").send_keys(u"测试")
driver.find_element_by_id("su").click()
driver.find_element_by_id("su").click()
unittest断言
自动化的测试中, 对于每个单独的case来说,一个case的执行结果中, 必然会有期望结果与实际结果, 来判断该case是通过还是失败, 在unittest 的库中提供了大量的实用方法来检查预期值与实际值, 来验证case的结果, 一般来说, 检查条件大体分为等价性, 逻辑比较以及其他, 如果给定的断言通过, 测试会继续执行到下一行的代码, 如果断言失败, 对应的case测试会立即停止或者生成错误信息( 一般打印错误信息即可) ,但是不要影响其他的case执行
序号 断言方法 断言描述
1 assertEqual(arg1, arg2, msg=None) 验证arg1=arg2,不等则fail
2 assertNotEqual(arg1, arg2, msg=None) 验证arg1 != arg2, 相等则fail
3 assertTrue(expr, msg=None) 验证expr是true,如果为false,则fail
4 assertFalse(expr,msg=None) 验证expr是false,如果为true,则fail
5 assertIs(arg1, arg2, msg=None) 验证arg1、arg2是同一个对象,不是则fail
6 assertIsNot(arg1, arg2, msg=None) 验证arg1、arg2不是同一个对象,是则fail
7 assertIsNone(expr, msg=None) 验证expr是None,不是则fail
8 assertIsNotNone(expr, msg=None) 验证expr不是None,是则fail
9 assertIn(arg1, arg2, msg=None) 验证arg1是arg2的子串,不是则fail
10 assertNotIn(arg1, arg2, msg=None) 验证arg1不是arg2的子串,是则fail
11 assertIsInstance(obj, cls, msg=None) 验证obj是cls的实例,不是则fail
12 assertNotIsInstance(obj, cls, msg=None) 验证obj不是cls的实例,是则fail
例子:
在类中使用:
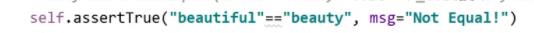
html测试用例报告
addTest() 的应用中 if name == “main”:改为
if __name__ == "__main__":
curpath = sys.path[0]
# 取当前时间
now = time.strftime("%Y-%m-%d-%H %M %S", time.localtime(time.time()))
if not os.path.exists(curpath + '/resultreport'):
os.makedirs(curpath + '/resultreport')
filename = curpath + '/resultreport/' + now + 'resultreport.html'
# 导出html报告
with open(filename, 'wb') as fp:
runner = HTMLTestRunner.HTMLTestRunner(stream=fp, title=u'测试报告', description=u'用例执行情况',verbosity=2)
suite = createsuite()
runner.run(suite)
异常捕捉和错误截图
添加一个新的测试类:
# -*- coding: utf-8 -*-
from selenium import webdriver
import unittest
import time
import os
import re
from selenium.common.exceptions import NoAlertPresentException
from selenium.common.exceptions import NoSuchElementException
class Baidu1(unittest.TestCase):
def setUp(self):
self.driver = webdriver.Chrome()
self.driver.implicitly_wait(30)
self.base_url = "http://www.baidu.com/"
self.verificationErrors=[]
self.accept_next_alert = True
def tearDown(self):
self.driver.quit()
self.assertEqual([],self.verificationErrors)
# 忽略此测试用例
@unittest.skip("skipping")
def test_baidusearch(self):
driver = self.driver
driver.get(self.base_url)
driver.find_element_by_id("kw").clear()
driver.find_element_by_id("kw").send_keys(u"大虞海棠")
driver.find_element_by_id("su").click()
time.sleep(6)
def test_baidu(self):
driver = self.driver
driver.get(self.base_url)
driver.maximize_window()
driver.find_element_by_id("kw").send_keys("向往的生活")
driver.find_element_by_id("su").click()
time.sleep(6)
print(driver.title)
try:
self.assertEqual(driver.title, u"百度一下,你就知道", msg="不相等")
except:
self.saveScreenShot(driver, "hao.png") # 出现异常就调用截图函数进行截图
time.sleep(5)
# 截图函数
def saveScreenShot(self, driver, file_name): # 参数:驱动,截图名字
if not os.path.exists("./image"):
os.makedirs("./image")
now = time.strftime("%Y%m%d-%H%M%S", time.localtime(time.time()))
driver.get_screenshot_as_file("./image/"+now+"-"+file_name)
time.sleep(3)
if __name__ == "__main__":
unittest.main()
数据驱动
1.ddt使用文档
2.安装
打开cmd 输入
pip install ddt
3.简单使用
一次一个参数
from selenium import webdriver
import unittest
import time
from ddt import ddt, unpack, data, file_data
@ddt
class Baidu1(unittest.TestCase):
# 测试固件
def setUp(self):
print("-----setUp-----")
self.driver = webdriver.Chrome()
self.url = "https://www.baidu.com/"
self.driver.maximize_window()
time.sleep(3)
def tearDown(self):
print("-----tearDown-----")
self.driver.quit()
@data("王凯", "Lisa", "特朗普", "蒋欣")
def test_baidu1(self, value):
driver = self.driver
driver.get(self.url)
driver.maximize_window()
driver.find_element_by_id("kw").clear()
driver.find_element_by_id("kw").send_keys(value)
driver.find_element_by_id("su").click()
time.sleep(3)
if __name__ == "__main__":
unittest.main(verbosity=0)
多个参数驱动
from selenium import webdriver
import unittest
import time
from ddt import ddt, unpack, data, file_data
@ddt
class Baidu1(unittest.TestCase):
# 测试固件
def setUp(self):
print("-----setUp-----")
self.driver = webdriver.Chrome()
self.url = "https://www.baidu.com/"
self.driver.maximize_window()
time.sleep(3)
def tearDown(self):
print("-----tearDown-----")
self.driver.quit()
@unpack
@data(['Lisa', u"Lisa_百度搜索"], [u"双笙", u"7887双笙_百度搜索"])
def test_baidu2(self, value, expected_value):
driver = self.driver
driver.get(self.url )
driver.find_element_by_id("kw").clear()
driver.find_element_by_id("kw").send_keys(value)
driver.find_element_by_id("su").click()
driver.maximize_window()
time.sleep(6)
# 判断搜索网页的title和我们期望的是否一致
self.assertEqual(expected_value, driver.title, msg="和预期搜索结果不一致!")
print(expected_value)
print(driver.title)
time.sleep(6)
if __name__ == "__main__":
unittest.main(verbosity=0)
从txt中读取数据
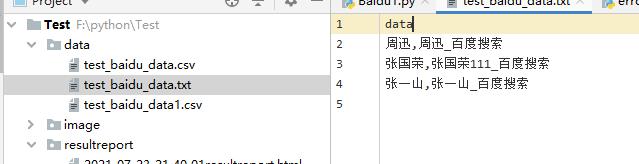
# -*- coding: utf-8 -*-
from selenium import webdriver
import unittest
import time
from ddt import ddt, unpack, data, file_data
import sys, csv
def getCsv(file_name):
rows = []
path = sys.path[0]
with open(path+'/data/'+file_name, 'rt') as f:
readers = csv.reader(f, delimiter=',', quotechar='|')
next(readers, None)
for row in readers:
temprows=[]
for i in row:
# 周迅,周迅_百度搜索
temprows.append(i)
rows.append(temprows)
return rows
@ddt
class Baidu1(unittest.TestCase):
# 测试固件
def setUp(self):
print("-----setUp-----")
self.driver = webdriver.Chrome()
self.url = "https://www.baidu.com/"
self.driver.maximize_window()
time.sleep(3)
def tearDown(self):
print("-----tearDown-----")
self.driver.quit()
@unpack
@data(*getCsv('test_baidu_data.txt'))
def test_baidu2(self, value, expected_value):
driver = self.driver
driver.get(self.url )
driver.find_element_by_id("kw").clear()
driver.find_element_by_id("kw").send_keys(value)
driver.find_element_by_id("su").click()
driver.maximize_window()
time.sleep(2)
# 判断搜索网页的title和我们期望的是否一致
self.assertEqual(expected_value, driver.title, msg="和预期搜索结果不一致!")
print(expected_value)
print(driver.title)
time.sleep(2)
if __name__ == "__main__":
unittest.main(verbosity=0)
从json中读取数据
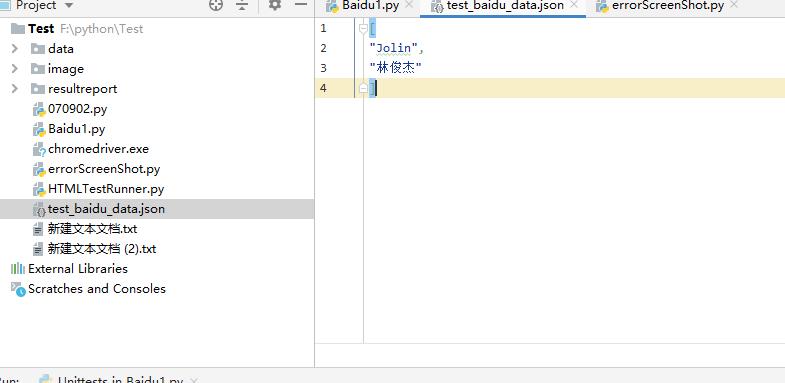
# -*- coding: utf-8 -*-
from selenium import webdriver
import unittest
import time
from ddt import ddt, unpack, data, file_data
import sys, csv
def getCsv(file_name):
rows = []
path = sys.path[0]
with open(path+'/data/'+file_name, 'rt') as f:
readers = csv.reader(f, delimiter=',', quotechar='|')
next(readers, None)
for row in readers:
temprows=[]
for i in row:
# 周迅,周迅_百度搜索
temprows.append(i)
rows.append(temprows)
print(rows)
return rows
@ddt
class Baidu1(unittest.TestCase):
# 测试固件
def setUp(self):
print("-----setUp-----")
self.driver = webdriver.Chrome()
self.url = "https://www.baidu.com/"
self.driver.maximize_window()
time.sleep(3)
def tearDown(self):
print("-----tearDown-----")
self.driver.quit()
@file_data('test_baidu_data.json')
def test_baidu1(self, value):
driver = self.driver
driver.get(self.url)
driver.maximize_window()
driver.find_element_by_id("kw").clear()
driver.find_element_by_id("kw").send_keys(value)
driver.find_element_by_id("su").click()
# time.sleep(6)
# self.assertEqual(driver.title, expected_value, msg="搜索结果和期望不一致!")
time.sleep(3)
if __name__ == "__main__":
unittest.main(verbosity=0)
以上是关于unittest测试数据驱动ddtbing的主要内容,如果未能解决你的问题,请参考以下文章