走进爬虫的世界
Posted 有理想的打工人
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了走进爬虫的世界相关的知识,希望对你有一定的参考价值。
初识爬虫
学习爬虫之前需要进行 相关环境的搭建,因为需要用到不属于python标准库的库或模块。
一、了解爬虫和浏览器的原理
1.浏览器的工作原理
给大家提供一个演示链接进行爬虫的学习(请使Google Chrome浏览器进行实操)。
这个网站上有一个菜品列表,如果我们希望保存部分想要的内容,可以将这部分内容粘贴到本地文档。 这个过程就是一个人和浏览器在交流的过程:

我们在浏览器中输入一个网址(URL),浏览器就会去存储放置这个网址资源文件的服务器获取这个网址的内容,这个过程就叫做「请求」(Request);当服务器收到了「请求」之后,会把对应的网站数据返回给浏览器,这个过程叫做「响应」(Response)。
所以当我们使用浏览器去浏览网页的时候,都是浏览器去向服务器请求数据,服务器返回数据给浏览器的过程。
当浏览器收到服务器返回的数据时,它会先「解析数据」,把数据变成人能看得懂的网页页面,然后我们就可以在这个页面内选择我们需要的内容进行保存,也即「筛选数据」。
2.爬虫的工作原理
上介绍到了浏览器的工作原理,下面我们开始了解爬虫。爬虫,从本质上来说,就是利用程序模拟人的浏览行为,在网上拿到我们所需要的数据。爬虫的能力很大,它既能给很多商业公司做数据分析,也能给我们的日常生活提供许多便利。比如我们最熟悉的搜索引擎——百度,它的核心技术之一就是爬虫,而且是 “一只” 巨大的爬虫。比如我们输入一个关键词:
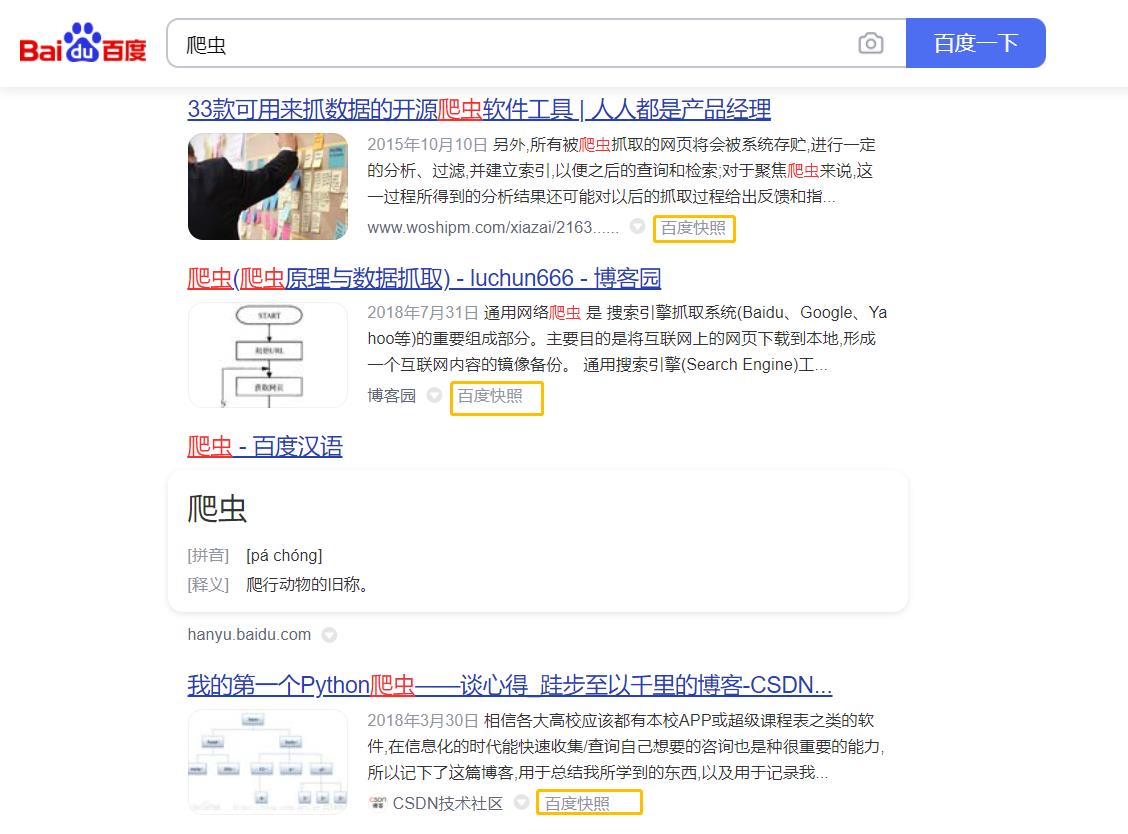
在使用百度搜索的时候,很多搜索结果下都会有一个 “百度快照” 的按钮。然后我们做一个实验,选一个结果分别点击词条和百度快照,对比以下显示结果:
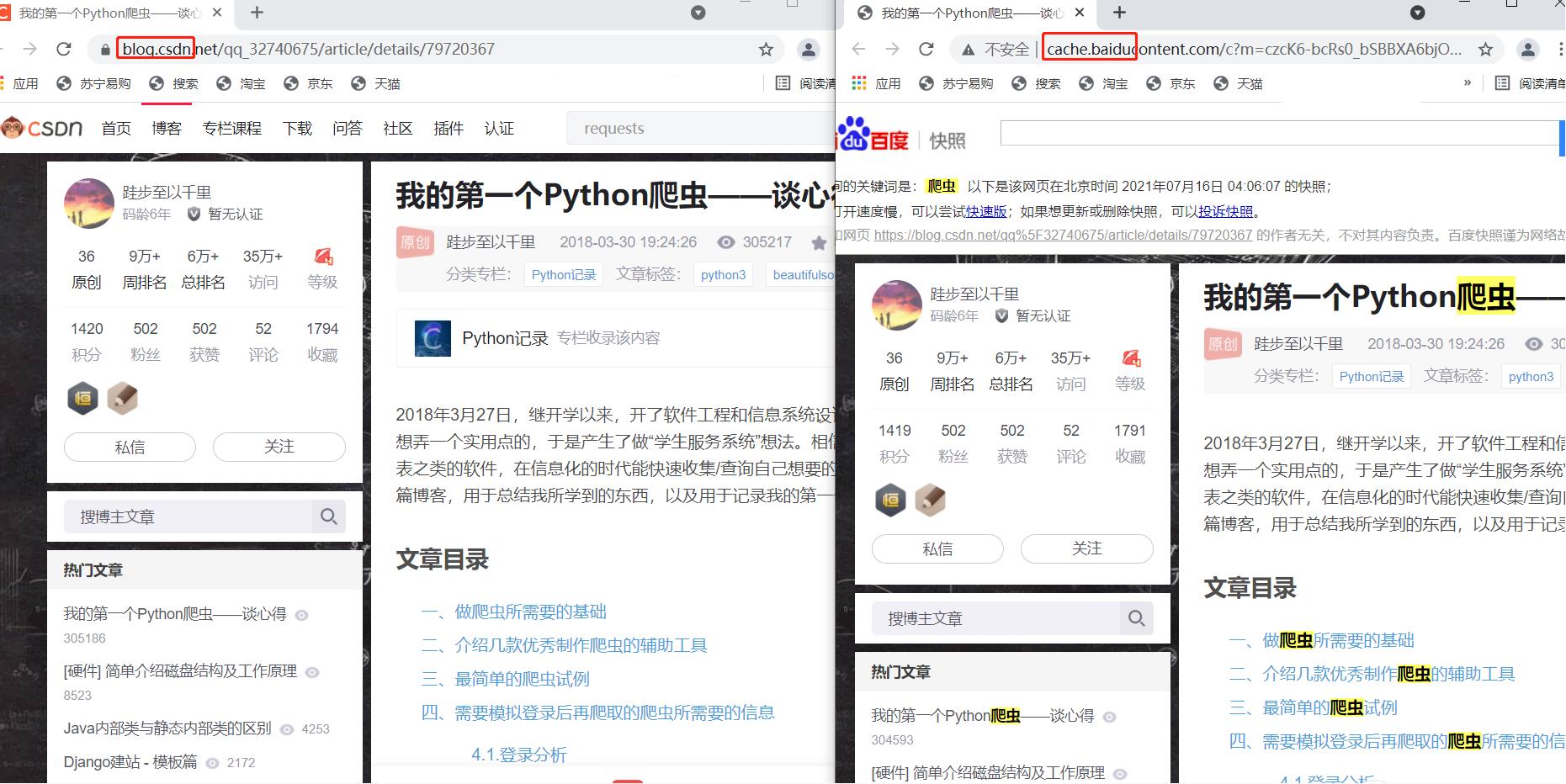
左面是点击词条进入的,右面是点击百度快照进入的。可以发现这两个页面显示内容是一样的,但点击百度快照进入的网页,其网址含有baidu字样,也就是这个网页属于百度而非CSDN博客。百度搜索的爬虫会一直在互联网上 “爬行”,把爬到的所有网站都保存到百度的服务器上。所以在百度搜索中能够搜到这些网站的超链接,点击后就可跳转到相应的网站。因此,我们和浏览器交互的过程也就成了:

然而爬虫的功能远不止于此,我们从网页内摘取有用的信息并保存的要求,爬虫都可以替我们完成。学会了爬虫,筛选数据、保存数据的过程就可以有爬虫一并代劳:
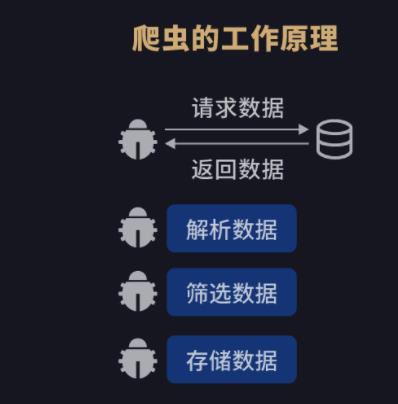
牢记爬虫的四个步骤:获取数据、解析数据、筛选数据、存储数据
2.1初识爬虫编写
i.了解requests库
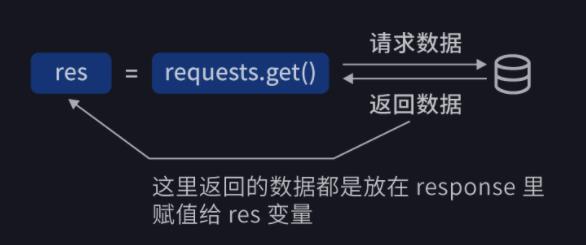
Python 是一门面向对象编程的语言,在面向对象的世界中,一切皆可为对象。Response 也是一个对象,它有自己的属性和方法。下面会挑一些常用到的给大家介绍。首先,我们需要用requests库的get方法完成获取数据,其具体使用方法为:
import requests
# 引用requests库
res=requests.get('URL')
# requests库中get()方法可以向服务器发送请求,URL是我们需要请求的网址
# 当请求得到响应后,服务器返回的数据就被赋值到变量res里
用一幅图片来展示这个过程:
注:没有安装requests库的小伙伴请回到文章开头进行相关环境的搭建
下面给大家提供一个练习URL,网页的内容为《滕文阁序》
import requests
res=requests.get('https://xiaoke.kaikeba.com/example/gexu/tengwanggexu.txt')
print(type(res))
# 输出res的类型
print(res)
# 输出为:<class 'requests.models.Response'>
# <Response [200]>
我们希望获得的结果为res的类型以及网页的内容。从结果可以看出,res的类型是“requests.models.Response”,但res的内容并不是我们希望看到的。下面给大家具体解释:
正如我们之前提到,requests是一个对象,它也有自己的属性和方法,我们最常用的属性有四种:
| 属性 | 功能 |
|---|---|
| requests.status_code | 检测请求是否成功 |
| requests.content | response对象的二进制数据 |
| requests.text | response对象的字符数据 |
| requests.encoding | 查看或修改response对象使用的编码方式 |
因此我们想要输出网页的文字需要对刚刚的代码进行以下修改:
import requests
res=requests.get('https://xiaoke.kaikeba.com/example/gexu/tengwanggexu.txt')
print(res.status_code)
# 检测请求是否成功
print(res.encoding)
# 查看response对象使用的编码方式
# 如果需要修改编码方式,如改为gbk,代码要这样写:
# res.encoding = 'gbk'
# 有兴趣的小伙伴可以尝试一下,看会有什么样的结果~
print(res.text)
# 打印网页的内容
# 输出为:200
# utf-8
# 「网页内容」
但是,在运行这段代码的时候,我们遇到了有些小伙伴可能会遇到编码错误的问题,解决这个问题我们可以改变pycharm的文件编码方式的方法解决或者使用重新编译码的方式,将最后一句代码
print(res.text)
改为
res=res.text.encode('utf-8')
print(res.decode('utf-8-sig'))
注:如果出现这样的错误:

在文件第一行加上“ # coding=UTF8 ”就可以解决,下同。
接下来,我们看看200是个什么意思:
| 响应状态码 | 说明 | 例 | 例子解释 |
|---|---|---|---|
| 1xx | 请求接收 | 100 | 继续提出请求 |
| 2xx | 请求成功 | 200 | 请求成功 |
| 3xx | 重定向 | 305 | 应使用代理访问 |
| 4xx | 客户端错误 | 403 | 禁止访问 |
| 5xx | 服务器错误 | 503 | 服务器不可用 |
我们不需要都记清楚,只需要知道除了200之外,其他都是请求遇到问题了。其他的响应码的具体含义可以在百度上搜索。
再来说一下requests.content的功能,以二进制数据存储可以用于存储图像、音频、视频等,我们用一个存有一幅图片的网页进行演示:
{kind=link}
import requests
res = requests.get('https://img.kaikeba.com/web/kkb_index/img_index_logo.png')
pho=res.content
# pho存储网页内图片的二进制数据
with open('logo.png','wb') as p:
p.write(pho)
这里没有输出结果,但会生成一个png文件,存储网掌上的图片:
到这里,response的几个基础功能我们就介绍完了。
二、简要学习html
借用爬虫去网页爬取数据,必须了解一个网页的结构。所以我们先学习网页的基础 —— HTML。
1.什么是HTML
HTML(Hyper Text Markup Language) 是用来描述网页的一种语言,也叫超文本标记语言,把文本和文本以外的相关信息(例如大小,高度,颜色,位置等)组合在一起的语言。
HTML 是前端工程师使用的语言,用来设计 “网页的结构图”。 通过浏览器输入网站,浏览器会去这个网站对应的服务器请求,然后这个服务器会返回给我们这个网页的 HTML 代码,进而浏览器会把 HTML 解析成我们看到的网页。
下面我们用一个演示网站一起学习HTML代码。(请使Google Chrome浏览器进行实操)。打开网页后点击右键,选择查看源代码(或ctrl+u)。而后我们就可以看到HTML的源代码了:

代码可以在一个新的页面看到。但是大部分网站都会将 HTML 代码压缩,查看的时候比较费劲。所以我们可以在网页的空白处点击右键,然后选择 “检查”(ctrl + Shift + I),就可以在一个页面下见到网页内容和源代码类容了:
当我们把鼠标移动到代码上时,鼠标选到的这行代码对应着的左侧网页上这部分内容会被标亮。可以看到上述图片中,很多语句前都会有一个三角形符号,点击可以展开或合上对应的一段代码,这代表了HTML的层级关系。每一个可以展开和合上的小三角形里包含的内容,都是一个层级,它很像电脑中一层一层的文件夹。下面我们来具体学习HTML代码:
2.HTML的标签和元素
我们先建立一个.txt文档,在文档内写入以下内容:
<html>
<head>
<meta charset="utf-8">
</head>
<body>
<h1>我是一级标题</h1>
<h2>我是二级标题</h2>
<h3>我是三级标题</h3>
<p>我是一个段落啦</p>
</body>
</html>
然后保存起来,将文档的后缀改为.html,双击打开就可以看到一个网页:

在这段代码中,我们可以看到很多的“<>”括号,这种尖括号里面包含的就是标签。标签通常成对存在,分为开始标签(如< body >)和结束标签(如< /body >)。当然也有单独出现的标签比如 < meta charset=“utf-8” >,定义网页编码格式。
除了标签之外,我们还需要了解元素,所谓的元素,就是开始标签和结束标签以及夹在其之间的内容:

下面我们列出一些常用的元素:
| 开始标签 | 标签意义 | 结束标签 |
|---|---|---|
| < h1 > | 一级标题 | < /h1 > |
| < h2 > | 二级标题 | < /h2 > |
| < a > | 链接 | < /a> |
| < div > | 块,用来包含其他标签 | < /div > |
| < p > | 段落 | < /p > |
这就是HTML的一些基础知识了。
3.< head > 和 < body >
回到刚才的例子,我们可以看到在HTML的最外层有一个< html >标签,下面分别是< head >和< body >。< head > 元素就是网页头,< body > 元素就是网页体。他们构成了HTML的基本结构。也就是HTML的框架实际上是:

HTML中的元素和网页的内容是对应的。 但是网页头的内容是不会在网页中显示的。网页上看到的内容都是写在网页体里面的。让我们逐个了解:
3.1< head >
<head>
<meta charset="utf-8">
<title> title 标签里面包含的就是网页的名字 </title>
</head>
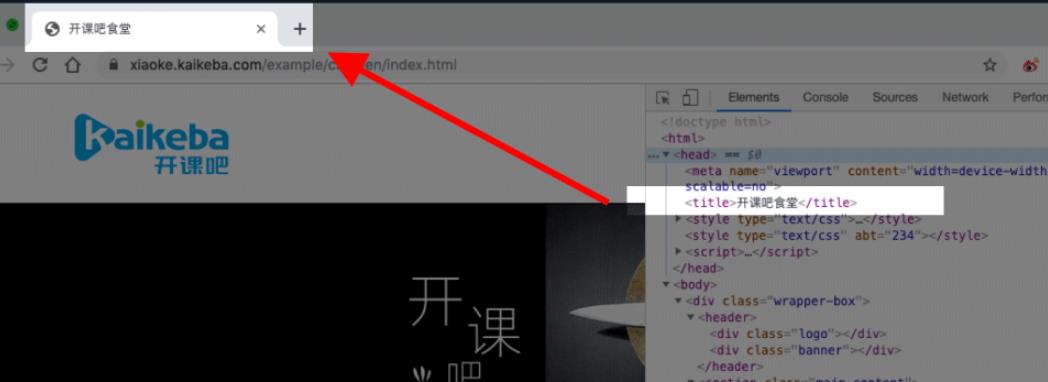
meta标签负责定义网页的编码格式,title元素用来设计网页的标题,会显示在浏览器的选项卡上:
3.2< body >
前面已经介绍过,< head >标签中的内容只会显示在浏览器的选项卡上,所以想要在网页的内容中显示的元素,要写到 < body > 标签中。我们对上文中的例子做一些完善:
<html>
<head>
<meta charset="utf-8">
<title>选项卡标题</title>
</head>
<body>
<h1>我是一级标题</h1>
<h3>我是三级标题</h3>
<h2>我是二级标题</h2>
<p>我是一个段落啦</p>
</body>
</html>
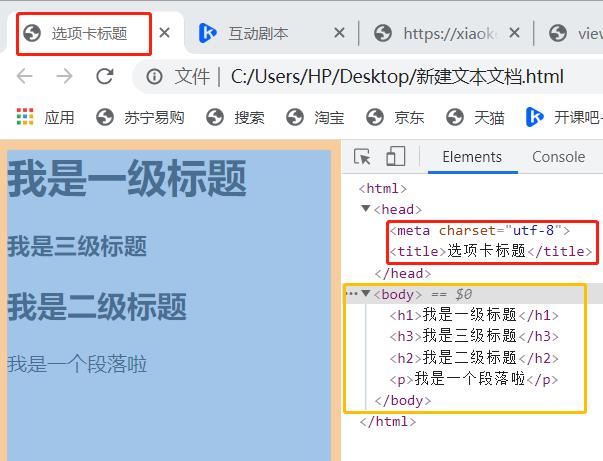
还是按照上文的方法操作,打开网页后,我们就可以看到:
4.设置标签的属性
我们先来观察以下代码:
<html>
<head>
<meta charset="utf-8">
<title>选项卡标题</title>
</head>
<body>
<h1 style="color:#ff0000;">欢迎来到我的主页</h1>
<a href="https://blog.csdn.net/weixin_54929649?spm=1001.2100.3001.5343" target="_blank">这里是我的主页~</a>
<br>
<p>感谢大家的支持,博主会为大家继续带来作品~</p>
</body>
</html>
打开网页,可以发现< h1 > 标签的颜色发生了改变,下面还添加了一个博主主页的链接。这些都是靠标签的属性1来完成的:

通过 HTML 属性,我们可以给标签设置各种信息,这里的
<h1 style="color:#ff0000;">欢迎来到我的主页</h1>
就是给< h1 >标题添加style属性,显示字体为红色。HTML的属性格式为:
<「开始标签」「space」「style="开始标签(例)" 」>
“style” 属性可以用来给文本类的标签定义多种样式,包括但不限于字体,字体颜色,字体大小,字体间距,文字对齐方式。属性只能在 HTML的开始标签中设置,在结束标签中设置属性不会生效。
在上面的例子中,我们还添加了一个可以跳转到官网的文字链接:
<a href="https://blog.csdn.net/weixin_54929649?spm=1001.2100.3001.5343" target="_blank">这里是我的主页~</a>
< a > 标签本身只是一个文字标签,用于展示文字内容。但加上了 “href” 属性之后,就可以为这段文字绑定一个链接。绑定后,我们可以通过点击文字直达规定的URL地址。
5.两个常用属性:class & id
设想一下以下场景:网页需要有一个统一的字体样式,我们需要怎么来设置?
最朴素的办法就是给每一段文字单独设置字体样式。但是这种方法会让工作量大大增加。有没有什么简单的办法帮我们完成这样的工作呢?
在 HTML 文档中,我们有一个关键词为 “class” 的属性,“class” 可以使属性值相同的元素复用同一套样式。修改一下我们之前的文本:
<html>
<head>
<meta charset="utf-8">
<title>选项卡标题</title>
<style>
.menu { /*以下是.menu的具体样式规定*/
float: left; /*控制元素浮动*/
margin: 10px; /*新建框外边距左侧边框和上文文字均为 10 像素*/
padding: 15px; /*文字与上述边框上下左右距离为均 15 像素*/
width: 350px; /*新建边框横向长度为 350 像素*/
height: 100px; /*新建边框纵向高度为 100 像素*/
border: 3px solid #ff0000; /*新建边框线条粗细为 3 像素,颜色为 ff0000*/
}
</style>
</head>
<body>
<h1 style="color:#ff0000;">欢迎来到我的主页</h1>
<h3>希望我的分享可以给大家带来帮助:</h3>
<a href="https://blog.csdn.net/weixin_54929649?spm=1001.2100.3001.5343" target="_blank">这里是我的主页,欢迎您的访问~</a>
<p></p>
<div class="menu">
<p>我是一个小程序员,通过写博客的方式记录我的学习过程。希望我的分享可以帮大家解除疑惑,也欢迎大家关注我,能给个赞的话更是不胜荣幸啦~
</p>
</div>
</body>
</html>
这段代码新增了一个属性,其代表的意义在的对应位置有所注释。我们来看修改后的文件样式:
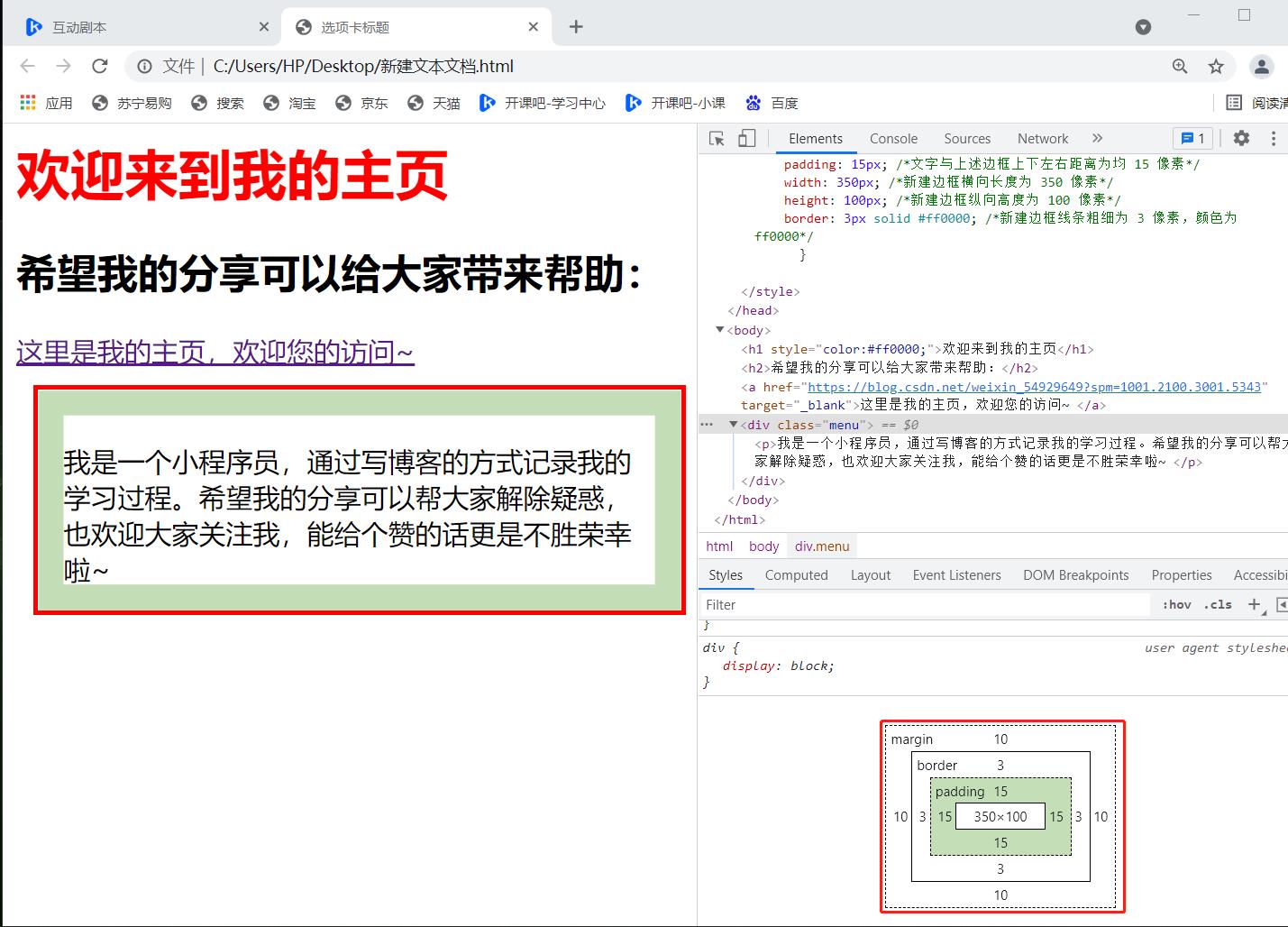
注:右下角用红框圈出来的图示就是我们使用的自定义menu。把鼠标移到不同的单词上,左侧对应的部分会增亮,可以更直观的学习。
观察这段代码,我们可以发现,在 < head > 的 < style > 中,我们定义了一个 “class”(menu前面的「.」)叫做 “menu” ,后面的大串样式代码是对 “menu” 这个“class” 的属性进行了描述。后面我们在 < body > 中的 < div > 标签定义它的 “class” = “menu” ,那么这个标签里就和 < head > 中 “menu” 定义的样式产生联系,也可以认为在这里使用了menu。在HTML中, 一个“class” 属性可以被多个不同的标签使用,用法相同。有兴趣的小伙伴可以自行尝试2。
说完class,我们来说一下id。id与class在< body >中的用法类似,它们存在的目的都是为了查找、定位元素,或者为元素设置样式。但是,id在< head >中的写法可是和class大不相同。下面我们用id来描述上述class描述出的样式:
<html>
<head>
<meta charset="utf-8">
<title>选项卡标题</title>
<style type="text/css">
#menu {float: left; margin: 10px;padding: 15px;width: 350px;height: 100px; border: 3px solid #ff0000;}
</style>
</head>
/*后面的代码和之前基本一样,只是把“class=”改成了“id=”,此处不再放了*/
仔细观察两者间< style >的不同,这几乎是两个属性唯一的区别了。
定义上,“id” 属性用于标识唯一的元素,而 “class” 用于标识一系列的元素。因此两者的关系可以以下图表示:

现在,我们可以对常用的属性进行一个总结了:
| 属性 | 用途 |
|---|---|
| class | 为HTML设置类名 |
| id | 为HTML元素设置唯一的id |
| href | URL融入文字 |
| style | 定义元素的样式 |
6.HTML的阅读和修改
不知不觉,我已经学完了HTML 的组成:标签、元素、结构、属性。现在让我们对照网页,尝试阅读一下:练习网址
网页体有三大部分,< header >、 < section > 、< footer >,分别对应了我们看到的网页的头部,中间内容,底部。
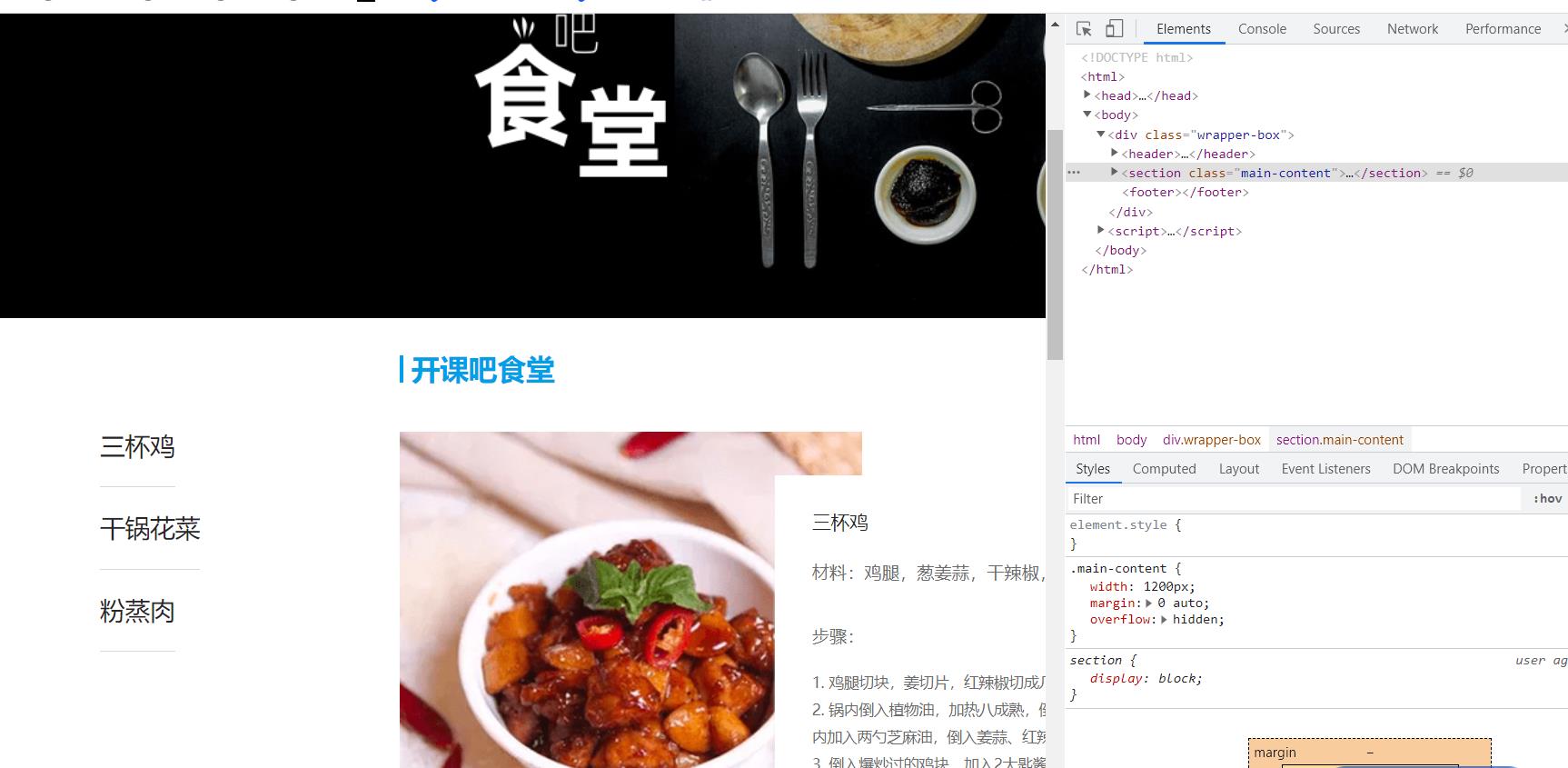
展开 < header > 标签,可以看到 < div class=“logo” > 和 < div class=“banner” > ,分别代表了最上面的网页 logo 和 logo 下面的 “开课吧食堂” 大图:
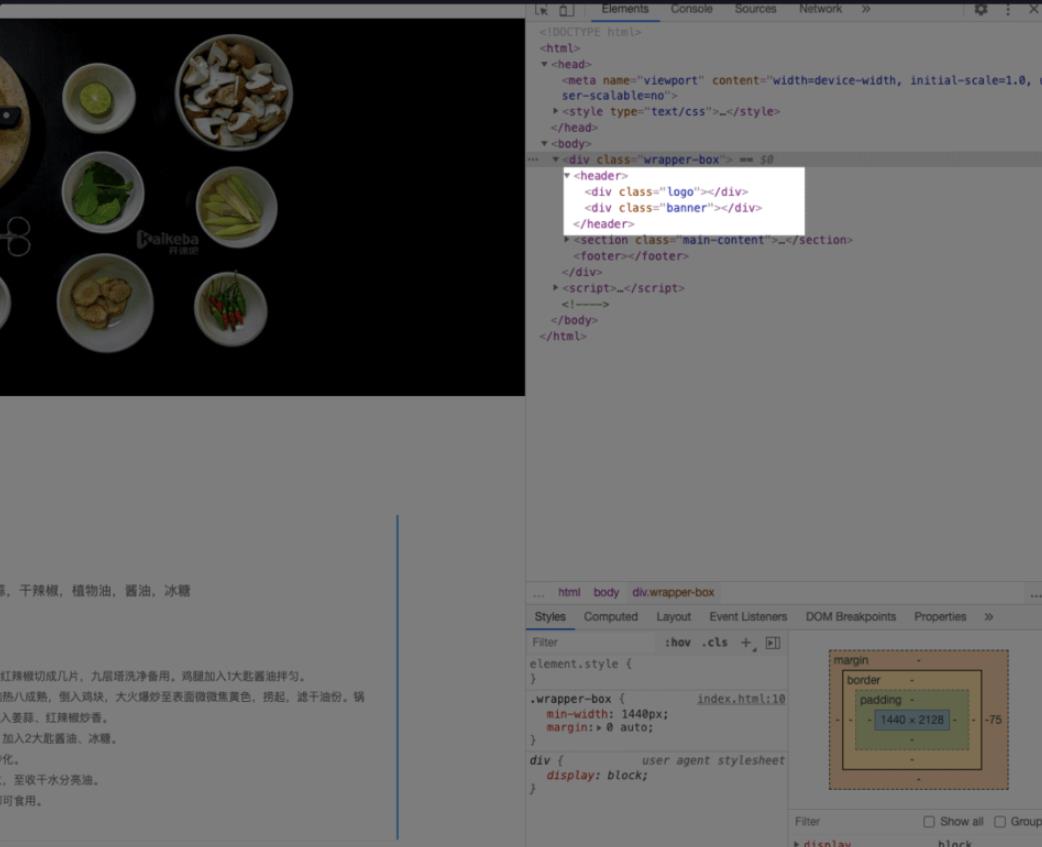
接着我们看看代表网页正文的
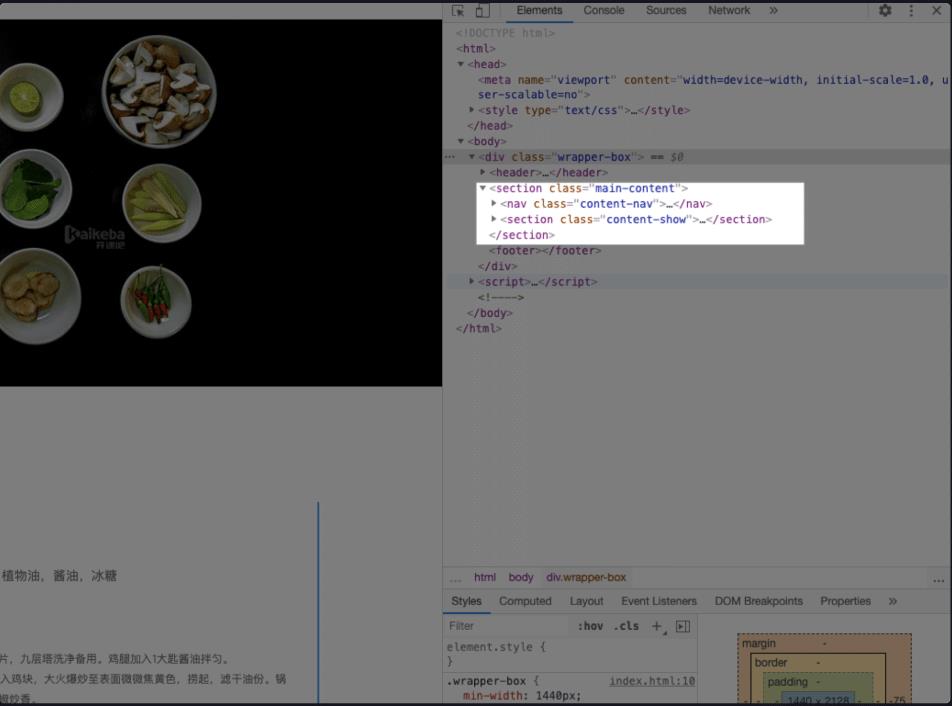
< section > 里面分为两部分,分别是 < nav class = “content-nav” > 和 < section class = “content-show” > ,代表了左边的菜品导航栏和右边的菜品内容。
很多标签的英文意思差不多对应了它的用途,比如说在 < body > 中的 < header > ,就定义了网页的最上面,也就是头部的部分。最下面的部分由 < footer > 标签来定义。 < nav > 就是 Navigation 这个单词的缩写,也就是导航栏的意思:
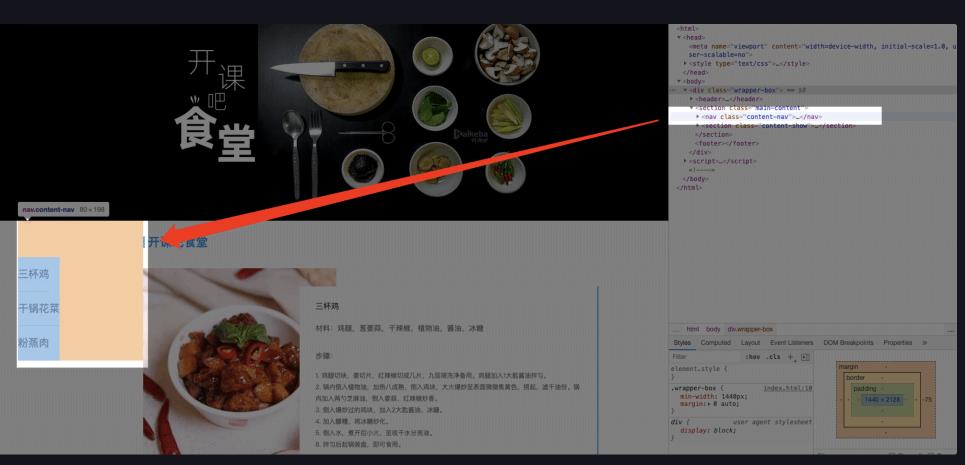
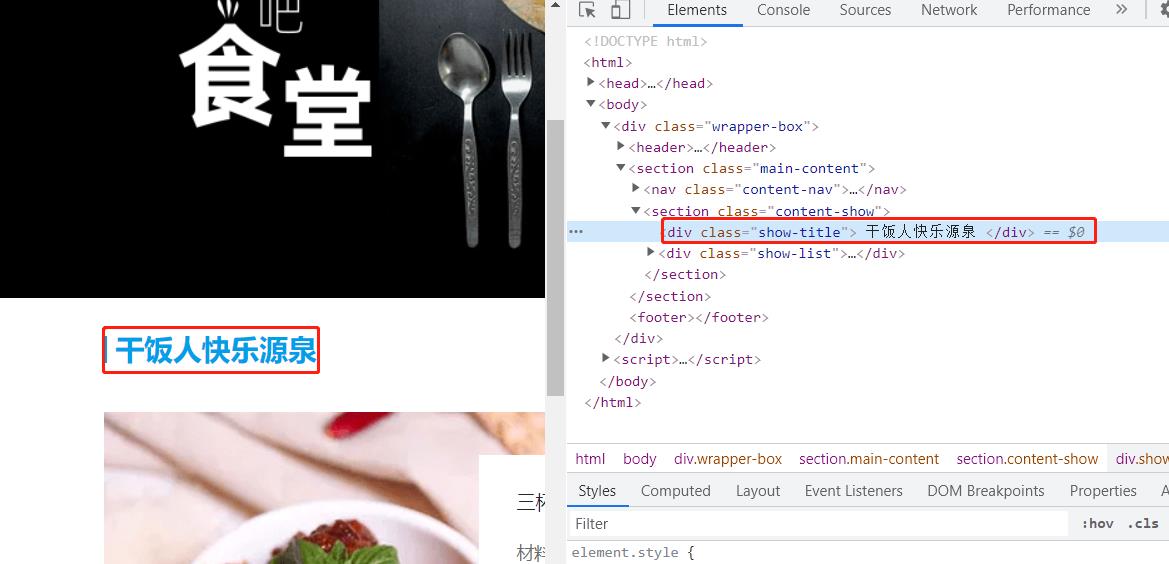
每个 < div > 都包含了一个 < a > 标签,分别对应了三个菜品 “三杯鸡”,“干锅花菜” 和 “粉蒸肉”。他们都由 “href” 属性定义了一个内部链接,点击的话,页面会滚动到相应菜品的位置。
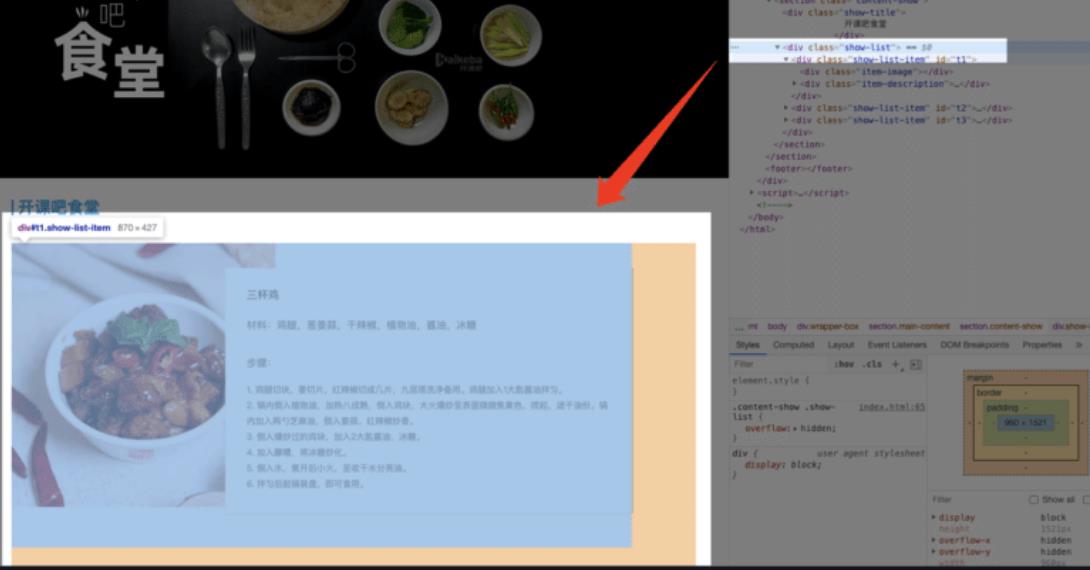
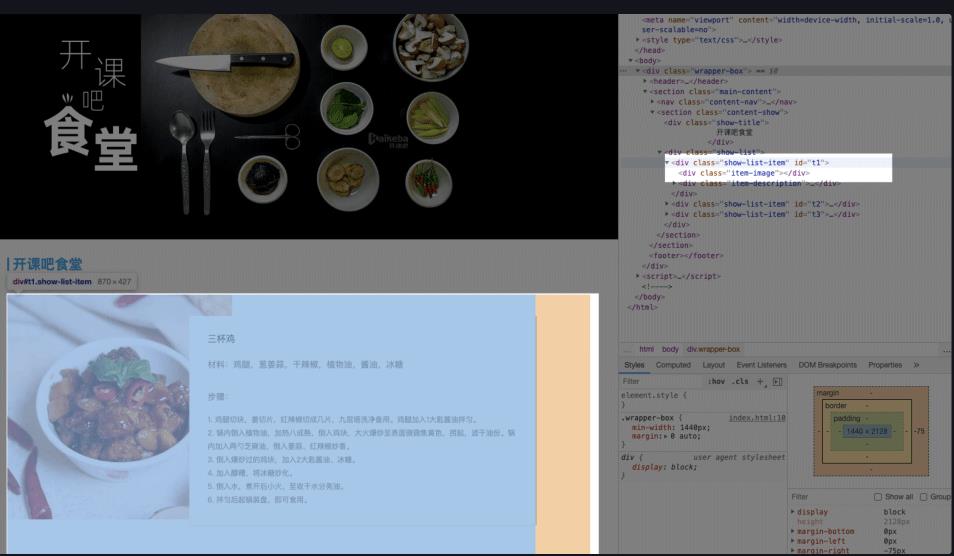
接下来我们展开 < section >,里面先用一个 < div > 定义了标题,然后一个 < div > 定义了一个菜品列表,展开菜品列表的 < div class = “show-list” > ,里面又是三个 < div class = “show-list-item” >:
这样,我们也就基本上可以看懂代码在说什么了,虽然很多语句都还没有接触到,不过并不妨碍我们对网页有了一个宏观的理解,想深度学习的小伙伴给大家推荐一个网站: w3school
下面我们学习修改网页。首先,给大家介绍一个功能:
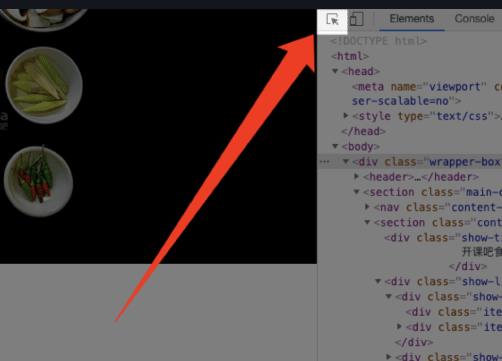
点击这个图标,然后把鼠标移到左面页面想要修改的位置,对应的代码就会在右侧高亮:
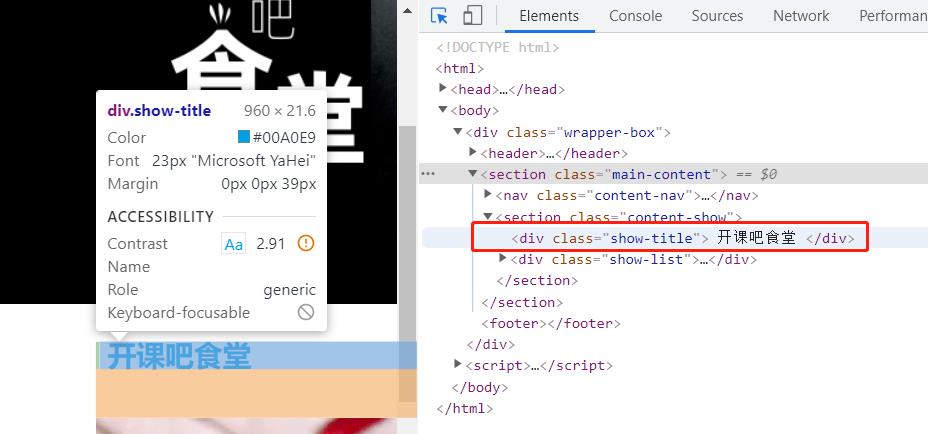
如果我们想修改这五个字,就可以双击高亮部分的文字,从而进行修改,或者右击这行代码选择Edit as HTML,然后进行修改。修改之后我们可以看到网页的变化:
这种方法很常用,如修改价格、清单等。但需要注意的是,我们这样的改动只能在当且页面生效,如果重新打开页面,显示的还是修改前的内容。
三、编写第一个爬虫
在这一节中我们学习如何在已有的网页源代码中获取需要的信息,这个过程需要借助BeautifulSoup 模块。
1.BeautifulSoup模块功能简述
先让我们回顾一下爬虫的四个步骤:获取数据、解析数据、提取数据、存储数据。在第一节的学习中,我们介绍了获取数据, 第二节的HTML知识,则有助于我们解析和提取网页源代码中的数据。而BeautifulSoup模块的主要功能在于解析数据和提取数据。那么什么是解析数据呢?我们在浏览网页时,服务器会返回HTML的源代码。浏览器需要将代码翻译成我们能看懂的样子,之后我们才能阅读网页进行各种操作,这个过程就叫做解析数据。相应地,爬虫也需要使用类似的工具将HTML源代码翻译成程序员读得懂的代码。在解析数据完成后,我们需要将需要的数据从源代码中有针对性的提取出来,这个过程就叫提取数据。
2.BeautiSoup的使用
2.1 使用BeautiSoup解析数据
BeautifulSoup 解析数据的方法比较容易理解:
bs对象=BeautiSoup(要解析的文本,'解析器')
需要被解析的文本必须是字符串类型的值或变量,解析器的种类有很多,这里介绍一个 Python 内置库:html.parser。这个解析器相对来说比较简单。下面我们观察以下代码:
import requests
from bs4 import BeautifulSoup as bs
ht=requests.get('https://xiaoke.kaikeba.com/example/canteen/index.html')
print(type(ht.text))
# 查看ht.text的数据类型
print(ht.text)
# 查看ht.text内容
soup=bs(ht.text,'html.parser')
# 第一个参数必须是字符串类型的数据,所以要写成ht.test
print(type(soup))
# 查看soup的数据类型
print(soup)
# 查看soup的内容
# 输出为:<class 'str'>
# 网页的源代码
# <class 'bs4.BeautifulSoup'>
# 网页的源代码
观察结果不难发现,打印soup和ht.text的结果都为网页的源代码,好像虽然使用了 BeautifulSoup来解析数据,但从直观上来看,得到的结果和没解析之前一样。不过仔细观察可以发现,这两者的类型并不相同。打印出来的是一样的文本,是因为BeautifulSoup对象在直接打印它的时候会自动调用该对象内的str方法,所以直接打印bs对象显示字符串是str的返回结果。
之后我们还需要进行提取数据的操作,如果我们得到的结果是没有经过解析的,也就是说没有一个BeautifulSoup对象,将无法调用相关的属性和方法。所以使用BeautifulSoup库进行解析是必要的。
2.2使用BeautifulSoup库提取数据
上文已经将网页的源代码保存到了变量soup里,下面我们就要学习如何从soup里提取出我们需要的内容。首先给大家介绍一个函数select,这个函数可以帮助我们在bs4.BeautifulSoup类型的变量中提取所需要的信息:
| 格式 | 示例 | 功能 |
|---|---|---|
| 变量名.select(‘标签名’) | soup.select(‘div’) | 提取对应标签名(< div >)下的所有内容 |
| 变量名.select(’.类名’) | soup.select(’.desc-material’) | 提取< body >中使用了该类名的所有内容 |
| 变量名.select(’#id名’) | soup.select(’#form’) | 提取< body >中使用了该id名的标签,这里会输出< form …>…< /form >这段内容 |
| 变量名.select(‘标签名#id名’) | soup.select(‘a#link’) | 组合查找,提取开始标签内同时含a和id=link的内容 |
| 变量名.select(‘外标签>内标签’) | soup.select(‘head>tittle’) | 提取< head >标签下的< tittle >标签内容 |
下面我们举个例子,提取演示网页中的菜名
首先,我们找到菜名对应的标签:

看到了class=“…”了吗?这说明菜名前都会调用class。因此我们可以用变量名.select(’.类名’) 格式提取所有的菜名:
import requests
from bs4 import BeautifulSoup as bs
res=requests.get('https://xiaoke.kaikeba.com/example/canteen/index.html')
html=res.text
sp = bs(html, 'html.parser')
desc=sp.select('.desc-title')
print(desc)
print(type(desc))
# 查看desc的类型
# 输出为:[<div class="desc-title">三杯鸡</div>, <div class="desc-title">干锅花菜</div>, <div class="desc-title">粉蒸肉</div>]
# <class 'bs4.element.ResultSet'>
这样一来我们的菜名就都找出来了。看到desc的数据类型和打印出的结果不难发现,bs4.element.ResultSet的数据类型非常类似于列表,事实上,我们可以把他就当做列表进行后续处理。其实提取内容一般都可以依据标签和属性进行,因此给大家介绍函数find()和find_all():
| 方法 | 作用 | 用法 | 示例 | 要点提示 |
|---|---|---|---|---|
| find() | 提取满足要求的首个数据 | 对象.find(标签,属性) | desc.find(div,class_=‘desc-title’)或desc.find(class_=‘desc-title’) | 标签和属性任选其一或同时存在 |
| find_all() | 提取满足要求的全部数据 | 对象.find_all (标签(可省略),属性) | desc.find(div,class_=‘desc-title’) | 标签和属性任选其一或同时存在 |
这个种用法和select的功能相似,并且这两种函数可以满足我们大部分的需求。需要注意的是,当使用的定位属性是class时,需要写成class_= '…'的形式,用以区分python语法中的类。大家可以将上文代码中的
desc=sp.select('.desc-title')
替换为
desc=sp.find_all('class_=desc-title')
运行看结果(输出结果和类型)是否一致。
我们使用
print(desc)
打印出来的内容是一个bs4.element.ResultSet(理解成列表)类型的数据,因此,如果需要把这部分内容存入我们自己的txt文档中,就需要将列表中的每个元素逐一列出:
**加粗样式**import requests
from bs4 import BeautifulSoup as bs
res=requests.get('https://xiaoke.kaikeba.com/example/canteen/index.html')
html=res.text
sp = bs(html, 'html.parser')
desc=sp.find_all(class_='desc-title')
with open('menu.txt','a') as f:
for i in desc:
f.write(i+'\\n')
我们希望这样就可以得到一个不够完美的文档,里面存着菜名和一部分网页源代码。运行试试:
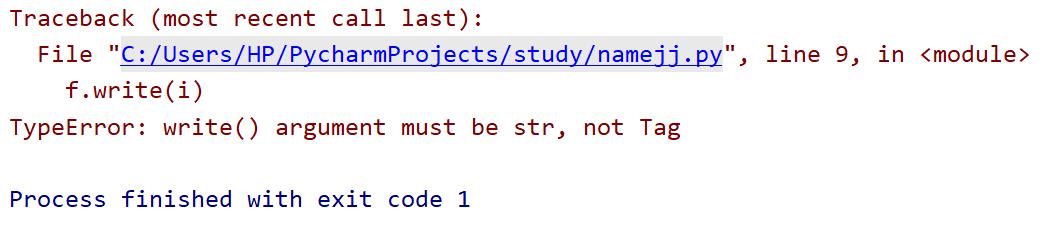
这里出现了一个错误提示。从这个提示中,我们可以看出,i是一个Tag类型的数据,是 Tag 对象。而write函数只能操作str类型。那么什么是Tag对象呢?
可以查看一下,无论使用.find_all()、.find()还是.select() 提取到的数据都是Tag对象,Tag对象也有属于自己的属性和方法,这里介绍几个最常用的:
| 属性/方法 | 作用 |
|---|---|
| < bs4.BeautifulSoup>类型数据.find(参数) / find_all(参数) | 提取内容,结果为Tag。如果没填写参数则把< bs4.BeautifulSoup>类型数据转化为< bs4.BeautifulSoup.Tag>类型数据 |
| Tag对象. text | 提取Tag对象中的文字 |
| Tag[‘属性名’] | 提取Tag中的这个属性的值 |
这么看来,我们使用Tag.text可以直接在提取到的源代码中筛选文字内容进行保存。修改一下之前的代码验证看看:
import requests
from bs4 import BeautifulSoup as bs
res=requests.get('https://xiaoke.kaikeba.com/example/canteen/index.html')
html=res.text
sp = bs(html, 'html.parser')
desc=sp.find_all(class_='desc-title')
with open('menu.txt','a') as f:
for i in desc:
f.write(i.text+'\\n')
运行后,我们看到一个新的文档:
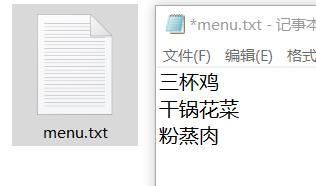
很符合我们的预期。
到这里,我们已经学完了如何使用BeautifulSoup库的相关知识来解析和提取数据。现在在进行一下梳理:
其实说白了,从最开始用 requests 库获取数据,到用 BeautifulSoup 库来解析数据,再继续用 BeautifulSoup 库提取数据,不断经历的是我们操作对象的类型转换。
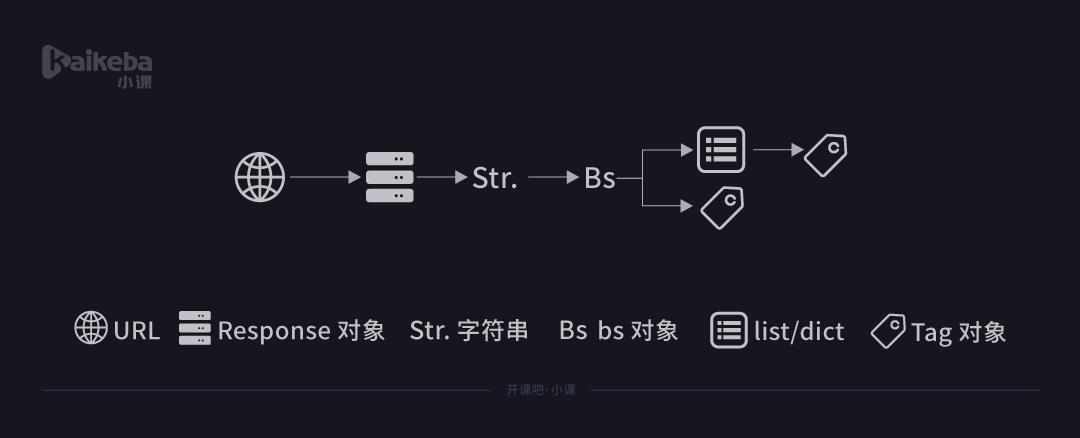
这样看起来是不是形象很多?那么这次的内容就介绍完了,顺便提一嘴,find()和find_all()的参数其实不止标签和属性两种,依照官方的定义,它们的的参数是:
find(tag,attributes,recursive,text,keywords)
find_all(tag,attributes,recursive,text,keywords)
但是上文介绍的方法足以应付大多数情况,因此这里就先不给大家介绍了,有兴趣的小伙伴可以去官网学习。
以上是关于走进爬虫的世界的主要内容,如果未能解决你的问题,请参考以下文章