深度学习笔记:正则化问题总结
Posted AI 菌
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习笔记:正则化问题总结相关的知识,希望对你有一定的参考价值。
文章目录
理论系列:
实战系列:
一、正则化的作用
如下图(左)所示:当网络欠拟合时,说明网络存在着高偏差问题。如下图(右)所示:当网络过拟合时,说明存在着高方差问题。
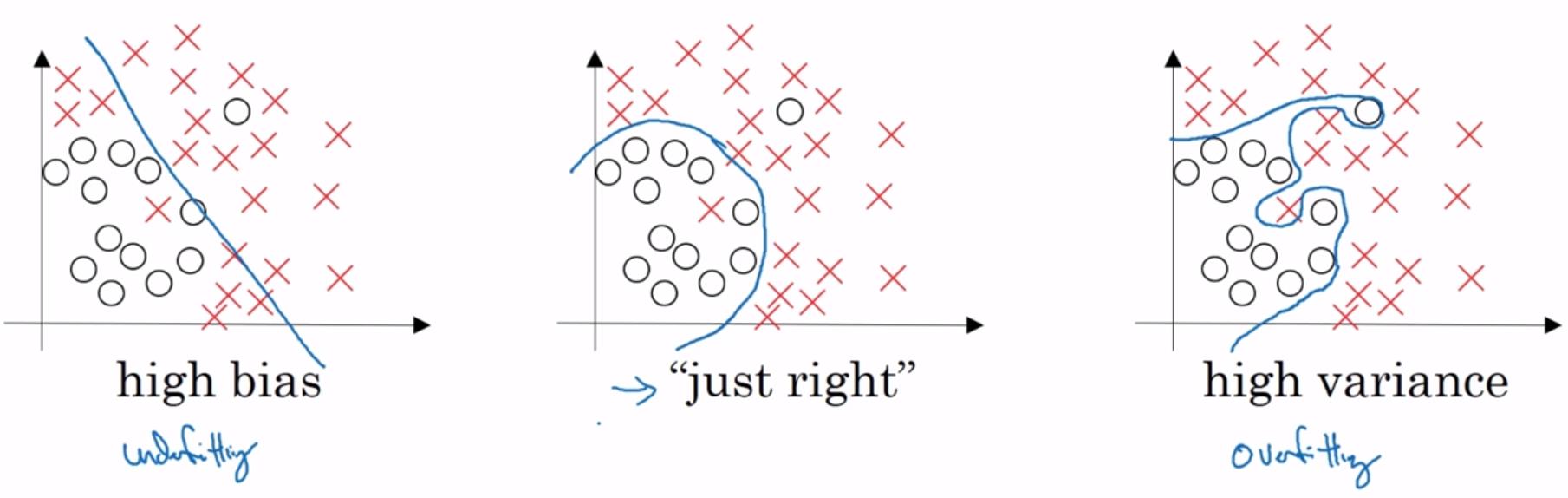
如果你怀疑神经网络过度拟合了数据,即存在高方差问题,那么最先想到的方法可能是正则化,正则化能够有效降低方差,同时不影响偏差。另一个解决高方差的方法就是准备更多数据。但是你可能无法时时准备足够多的训练数据,或者,获取更多数据的成本很高。那么,正则化方法是你最好的选择,它能在不增加任何数据的情况下,有助于避免过度拟合,提升网络性能。
二、如何判断过拟合 or 欠拟合
如下图所示,是吴恩达课程中给出的一个猫狗图像分类的例子,我们通过在训练集和验证集上的准确率,来判断网络存在高方差或者高偏差问题,从而进一步判断模型过拟合 or 欠拟合。

假设训练集和验证集标签误差为0%-1%,且数据来自于相同分布。其训练集和验证集上的测试准确度如上图所示,一共有四组不同的数据。可以得出如下结论:
- 训练集分类误差1%,验证集分类误差11%:高方差问题,即存在过拟合;
- 训练集分类误差15%,验证集分类误差16%:高偏差问题,即存在欠拟合;
- 训练集分类误差15%,验证集分类误差30%:高方差、高偏差问题;
- 训练集分类误差0.5%,验证集分类误差1%:低方差、低偏差问题;
在训练集和验证集标签误差接近0,且数据集来源同一分布的前提下,针对以上问题,我们一般先看训练集,再同时看训练集和验证集的测试误差,来判断有无高方差、高偏差问题。
注意:对于一些标签误差比较大的数据集,包含噪声图像的数据集,或者训练集与验证集不是同一分布,则以上归纳不适用。

- 在假设前提下,如果训练集上的测试误差过高,则存在高偏差,这时候最应该采取的方式是:选择更大、更深的网络,或者其他更合适的网络。
- 如果在训练集上的测试误差很低,但是在验证集上的误差较高时,这是高方差问题,即过拟合现象,这时候应该采取的最佳措施依次是:数据增广、正则化、其他更合适的神经网络。
三、常见正则化方法
正则化是通过在损失函数上添加额外的正则项(模型复杂度惩罚项),来限制网络模型的复杂度,以此约束网络的实际容量,从而防止模型出现过拟合。
因此,在原损失函数上增加正则化项后,我们的目标损失函数就变为:
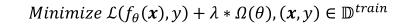
式子中的第一项为原始的损失函数,第二项是正则项,
λ
\\lambda
λ 是正则化系数。
(1)L0正则化
L0 正则化是指采用 L0 范数作为模型复杂度惩罚项
Ω
(
θ
)
\\Omega(\\theta)
Ω(θ) 的正则化方式,即
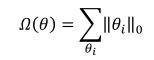
其中,L0范数定义为:
θ
i
\\theta_i
θi中非零元素的个数。通过约束
Ω
(
θ
)
\\Omega(\\theta)
Ω(θ) 的大小,可以迫使网络中的连接权值大部分为0。但是由于L0 范数并不可导,不能利用梯度下降法进行优化,所以在神经网络中的使用并不多。
(2)L1正则化
采用 L1 范数作为稀疏性惩罚项
Ω
(
θ
)
\\Omega(\\theta)
Ω(θ) 的正则化方式叫做 L1 正则化,即
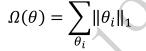
其中,L1 范数定义为:
θ
i
\\theta_i
θi 中所有元素的绝对值之和。L1 正则化也叫 Lasso Regularization,它是连续可导的,在神经网络中使用广泛。
(3)L2正则化
采用 L2 范数作为稀疏性惩罚项
Ω
(
θ
)
\\Omega(\\theta)
Ω(θ) 的正则化方式叫做 L2 正则化,即
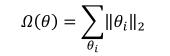
其中 L2 范数定义为:
θ
i
\\theta_i
θi 中所有元素的平方和。L2 正则化也叫 Ridge Regularization,它和 L1 正则化一样,也是连续可导的,在神经网络中使用更广泛。
(4)其他方法
除了 L1、L2 正则化以外,还有一些解决过拟合的方法,比如:最大范数约束正则化、数据增强、更改网络结构、Early Stopping、Dropout正则化等等。
四、正则化原理

以逻辑回归问题为例,使用L2正则化时,需要在损失函数上加入相应的正则化项。值得注意的是:正则化项只是针对参数W,而没有b。这是为什么呢?
原因是:W是高维参数,可以反映方差。而b只是一个标量,是众多参数中的一个,所以加入原损失函数作用不大。
还有一个是L1正则化,它的结果是使模型的参数更多趋向0,从而使得网络变得更加稀疏。但这并不是典型的模型压缩方法,原因是参数所占内存并没有减少多少。所以现在,大家更倾向使用L2正则化。
λ \\lambda λ是正则化系数,实际训练时,一般先尝试较小的正则化系数 λ \\lambda λ,观测网络是否出现过拟合现象。然后尝试逐渐增大 λ \\lambda λ 参数来增加网络参数稀疏性,提高泛化能力。但是,过大的 λ \\lambda λ 参数会使得W变得很小,此时网络接近成为一个比较深的线性回归,而不是一个复杂的非线性回归网络。
五、Dropout正则化
(1)Dropout
Dropout通过随机断开神经网络之间的连接,减少每次训练时实际参与计算的模型的参数量,从而减少了模型的实际容量,来防止过拟合。如下图所示,虚线表示按照概率随机断开神经网络的连接线:
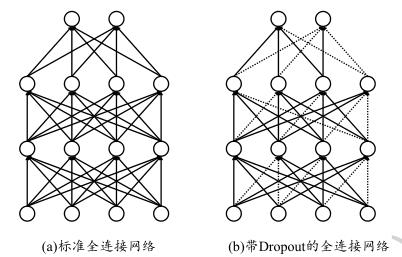
具体来讲:对于某层的每个神经元,在训练阶段会以一定的概率 p 随机将该神经元重置为0(即断开这些连接);在测试阶段,所有的神经元都将被激活(恢复连接),但是其权重要乘以 (1-p),以保证训练和测试阶段各自的权重拥有相同的期望。
(2)Drop Connect
Drop Connect 改变了在 Dropout 中对每个层随机选择激活函数的设置为0的做法,将网络架构权重的一个随机子集设置为0。所以,Drop Connect 和 Dropout 的不同之处在于,它引入的是权重的稀疏性,而不是层的输出向量的稀疏性。
六、Dropout工作流程
假设网络输入是x,输出是y。正常的训练流程是:将x通过网络前向传播,然后通过误差反向传播,更新参数让网络进行学习。使用Dropout之后,流程变成:
- 在前向传播的时候,会让某些隐藏层神经元的激活值以一定的概率 p 停止工作;
- 输入x通过随机断开后的网络进行前向传播,然后通过随机断开后的网络反向传播;
- 当按照上述方式训练一小批样本后,在恢复连接的神经元上按照SGD更新对应的参数(w, b0);
- 继续重复以上的过程,知道网络模型得到一定的要求。
以上是关于深度学习笔记:正则化问题总结的主要内容,如果未能解决你的问题,请参考以下文章
神经网络和深度学习笔记 - 第三章 如何提高神经网络学习算法的效果