python0基础爬虫实战:看到血脉喷张的图片一键保存(附源码和解析过程)
Posted IT林哥
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python0基础爬虫实战:看到血脉喷张的图片一键保存(附源码和解析过程)相关的知识,希望对你有一定的参考价值。
前言
各位CSDN的朋友好啊!前俩天我在CSDN上发布了一篇python安装教程的博客:
最新版Python详细安装教程与特点介绍(新手Python基础入门必备)
接下来咱们就趁热打铁 ,手把手教大家爬虫实战:一键保存自己想要的图片,从此晚上不孤单😎
一、爬虫介绍
网络爬虫(又被称为网页蜘蛛,网络机器人)就是模拟浏览器发送网络请求,接收请求响应,一种按照一定的规则,自动地抓取互联网信息的程序。简单来讲,爬虫就是一个探测机器,它的基本操作就是模拟人的行为去各个网站溜达,点点按钮,查查数据,或者把看到的信息背回来。就像一只虫子在一幢楼里不知疲倦地爬来爬去。原则上,只要是浏览器(客户端)能做的事情,爬虫都能够做。

二、爬虫工具
工欲善其事,必先利其器
首先我们需要下载python,我下载的是官方最新的版本 3.9.6,其次我们需要一个运行Python的环境,我用的是pychram
没有的朋友们可以去看一下我上一篇博客,详细的介绍怎么样安装python以及pycharm
最新版Python详细安装教程与特点介绍(新手Python基础入门必备)

三、网站分析
这是林哥挑好的网站,当然你们也可以自己找网站
(http://www.netbian.com/meinv/),进入网站,美女图片映入眼帘
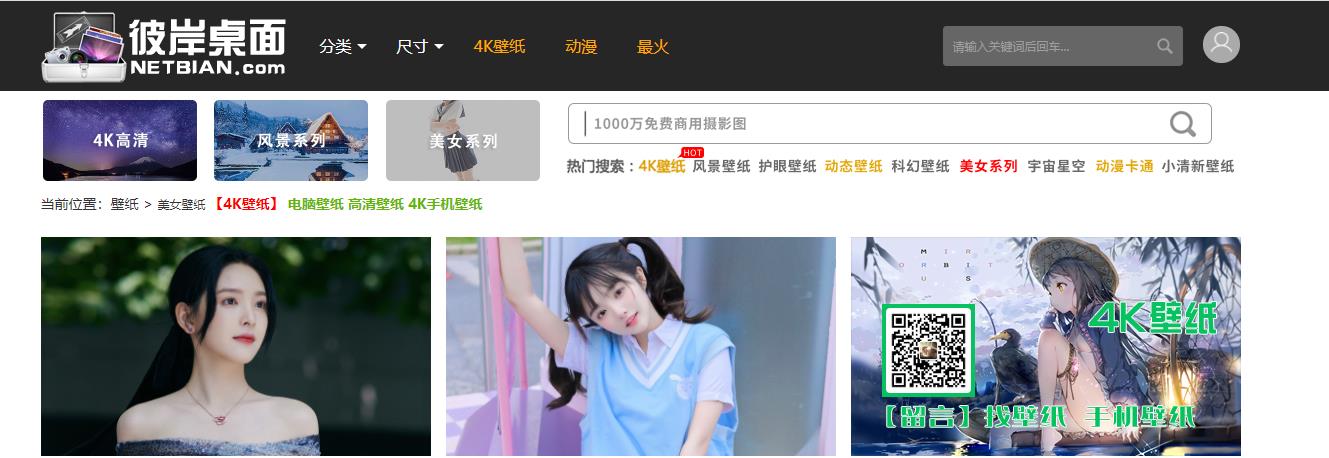
随便点开一个美女图片,查看它的url,http://www.netbian.com/desk/23749.htm
先记住这个网址,待会后面会用到

回到浏览器,打开F12,通过目标元素检查工具,点击刚刚我们点过的美女图片。通过它的元素我们可以知道a标签里的属性值href的链接就是上面我们访问美女图片的链接地址
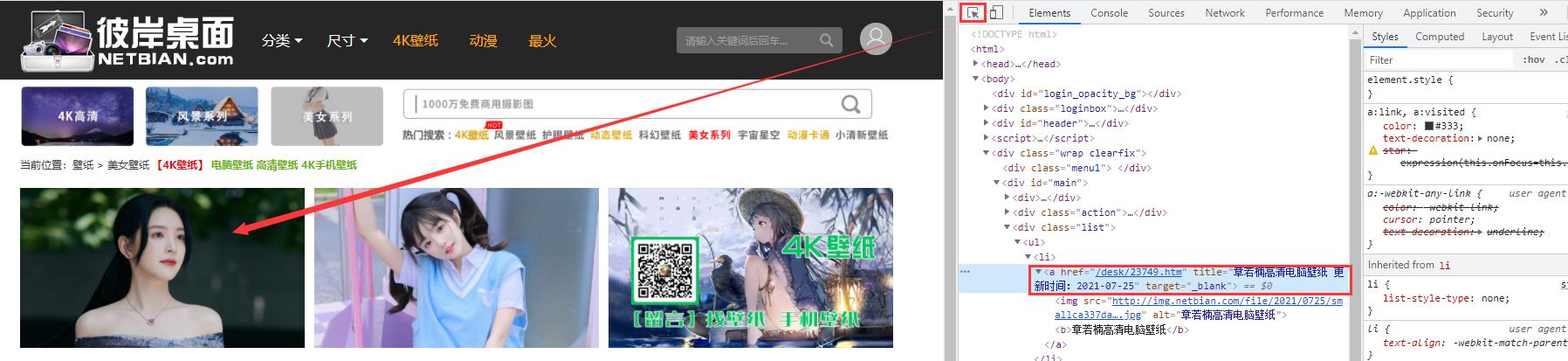
我们在大图的页面,同样用f12点击一下,找到图片的链接地址
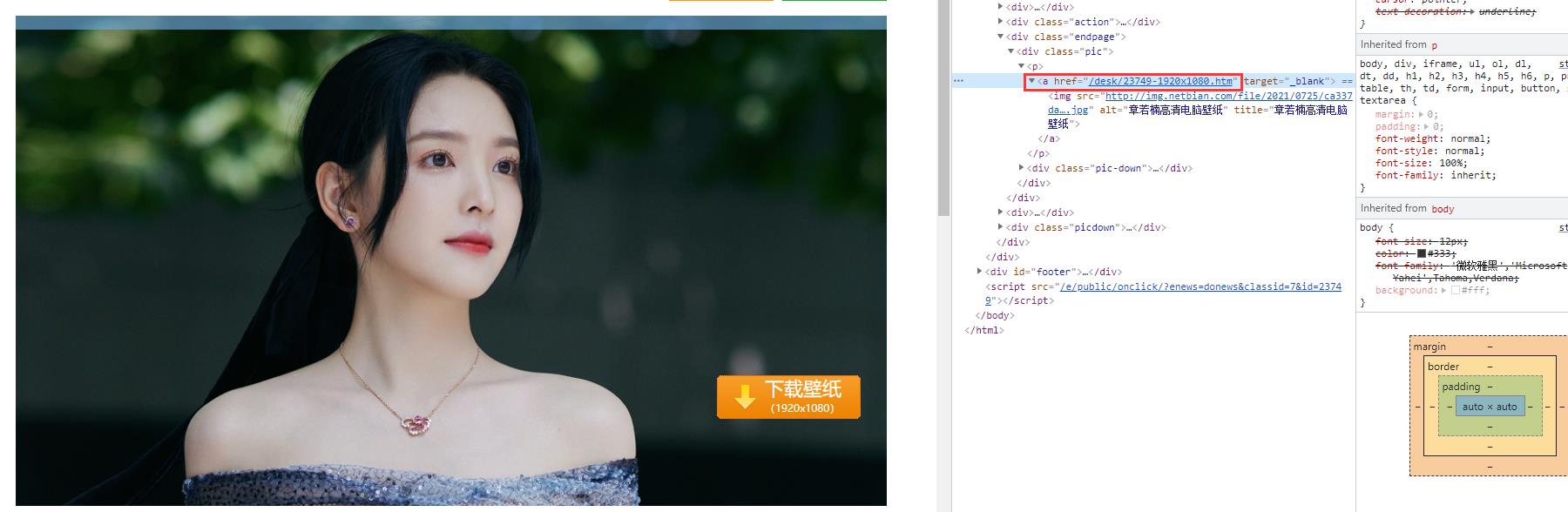
发现俩次链接相同,访问图片链接发现是我们要的美女图片。至此,对于网站的分析完毕。
四、代码实现
现在链接到手,话不多说,直接开干
import requests
from lxml import etree
import time
'''
1.访问网站首页
2.定位到每个美女图片的下载链接
3.定位到每个美女图片对应的大图链接
4.下载,保存美女图片
'''
if __name__ == '__main__':
t1 = time.time()
url = 'http://www.netbian.com/meinv/'
resp = requests.get(url)
resp.encoding = 'gbk'
with open('index.html', 'wb') as f:
f.write(resp.content)
tree = etree.HTML(resp.content)
node_list = tree.xpath('/html/body/div[2]/div[2]/div[3]/ul/li')
sub_url_list = []
for node in node_list:
if len(node.xpath('./a/@href')) > 0:
sub_url = node.xpath('./a/@href')[0]
if len(node.xpath('./a/@href')) > 0:
title = node.xpath('./a/b/text()')[0]
sub_url_list.append((sub_url, title))
#
base_url = 'http://www.netbian.com/'
for sub_url, title in sub_url_list:
s_page = base_url + sub_url
s_resp = requests.get(s_page)
s_tree = etree.HTML(s_resp.content)
img = s_tree.xpath('/html/body/div[2]/div[2]/div[3]/div/p/a/img/@src')[0]
suffix = img.split('.')[-1]
img_content = requests.get(img).content
with open(f'./image/{title}.{suffix}', 'wb') as f:
f.write(img_content)
f.close()
t2 = time.time()
print(t2-t1)
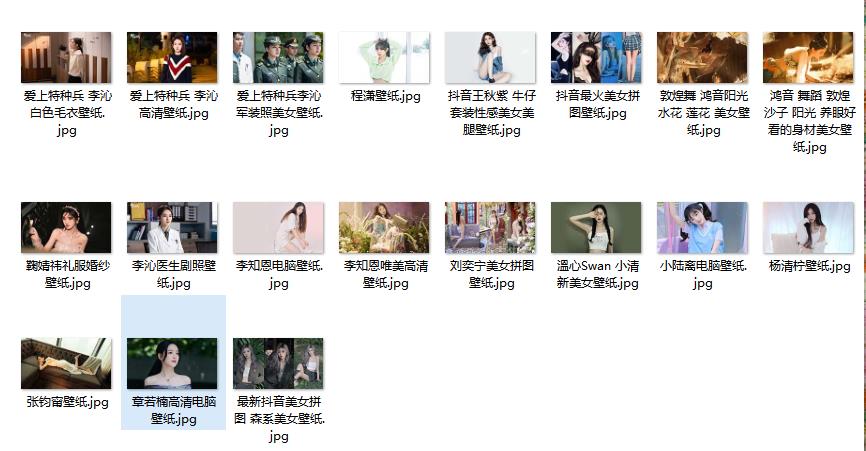
经过这么一系列的操作,我们的美女图片就到手啦
结语
到此有没有对 Python 小爬虫产生一个整体的认知呢,如果表示了解了,那么我们下一篇会循序渐进的谈谈其他 Python 爬虫技术点(当然了,上面代码虽然很少,但是你可能还是觉得有些看不懂,那就得自己去补习下相关知识了)
如果您觉得这篇文章有意思,麻烦一键三连支持一下林哥,或者也可以关注一下表示您对我文章的认可与鼓励。
愿大家都能在编程这条路,越走越远。**
以上是关于python0基础爬虫实战:看到血脉喷张的图片一键保存(附源码和解析过程)的主要内容,如果未能解决你的问题,请参考以下文章