Python实战手把手有教你写爬虫爬虫练手:看看爱奇艺的评论都在干啥(爬虫+词云分析)
Posted xihuanafengxx
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python实战手把手有教你写爬虫爬虫练手:看看爱奇艺的评论都在干啥(爬虫+词云分析)相关的知识,希望对你有一定的参考价值。
爬虫学习练练手:
刚好最近在学习爬虫,了解了一些基本的知识,以任务为导向去学习一下,所以根据自己的爱好出发,先来爬取一个《青春有你2》的评论吧。(可能会有点繁杂,主要记录自己在想什么,记录自己的思路)
我认为我写爬虫的时候基本就是在处理两方面:
第一:获取请求url,是直接那个网址就是呢,还是存在于另外的地方,这里我们可以用抓包工具去看
第二: 处理数据,将服务器返回的数据整理一下。
第一部分:获取请求URL(这也是最重要的,但是因为爱奇艺的离奇网址也为这一步添加了难度,我也是差点被困在里面了)*
爬取网址:https://www.iqiyi.com/v_19ry9w7eh8.html
- 第一步,我们可以先看一看这种评论数据是直接全部给你呢,还是随着你的刷新慢慢的给你呢
*使用request向服务器发个请求,得到html网页,在搜索框随便搜索一句评论,发现没有,这时候就可以断定是异步读取评论数据,且这个网址也不是我们需要的request URL
import requests
url= 'https://www.iqiyi.com/v_19ry9w7eh8.html'
headers ={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36 Edg/92.0.902.55'
}
request = requests.get(url, headers=headers)
request.encoding='utf-8'
response =request.text
print(response)
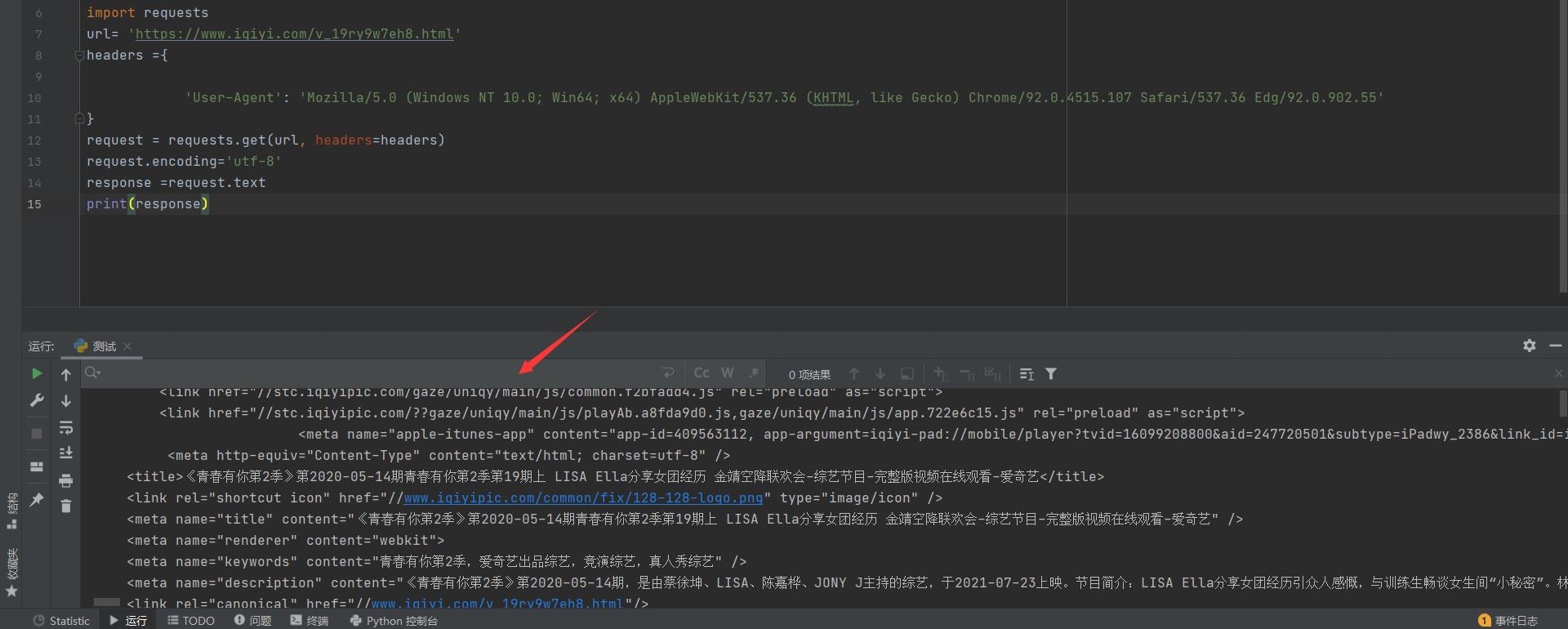
- 第二步,我们可以先打开之后直接F12,然后再次刷新页面,让抓包工具抓到所有的数据
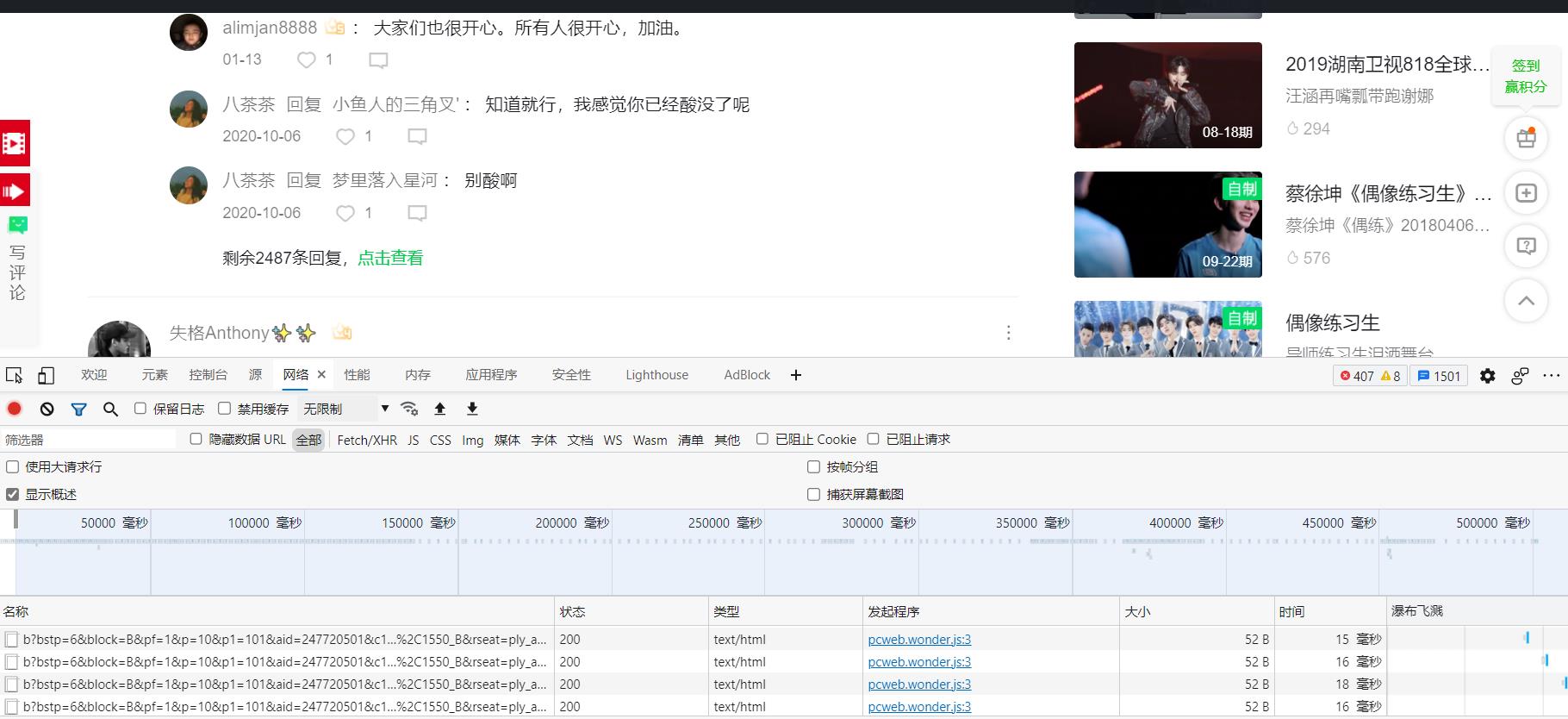
- 第三步,到了这个页面之后呢,我们可以先去尝试一下看看评论数据都存在哪里,随便复制一小段评论,然后点击抓包工具左上角的搜索
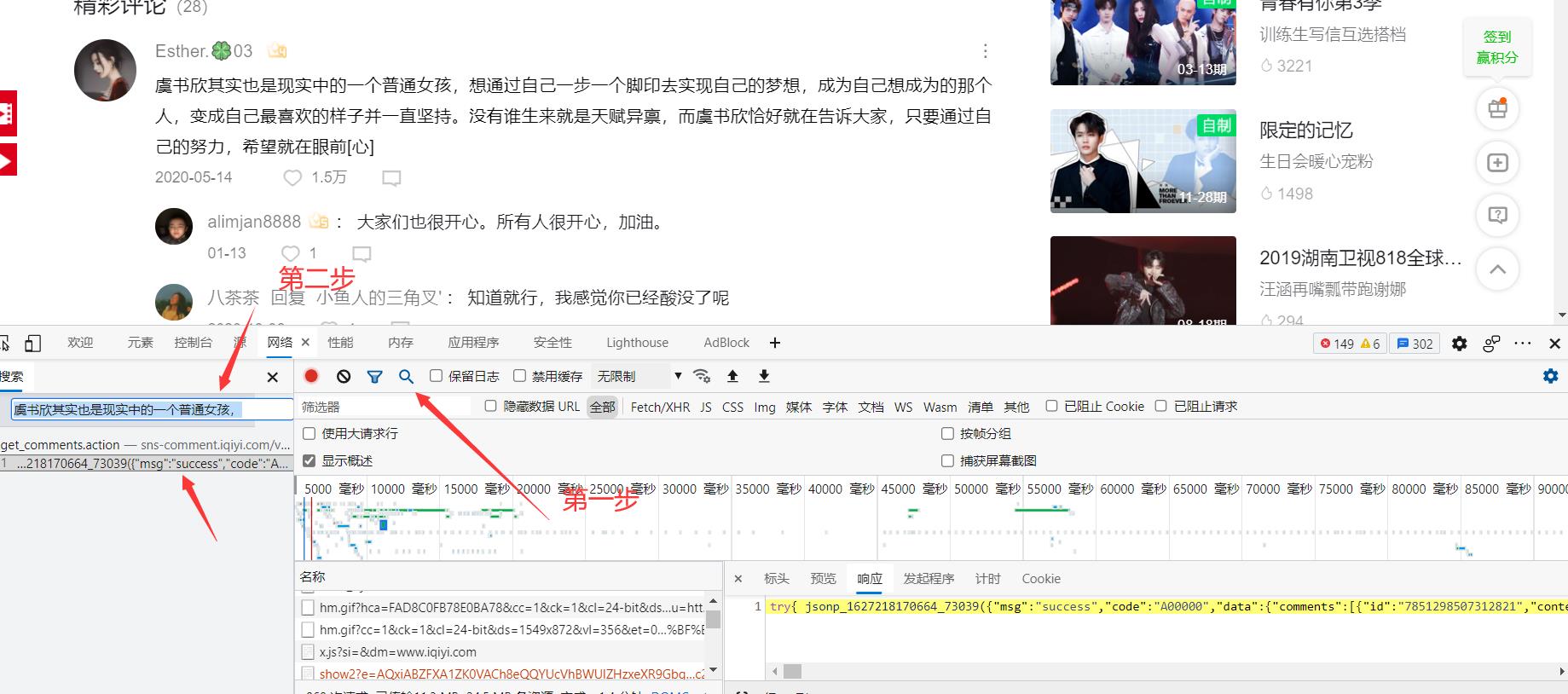
- 第四步,这时候我们就找到了我们的评论数据了,我们将指针放在这个评论数据上,并在旁边的文件框里面找到它。(这里建议点击一下名称,这样可以让这些得到的数据进行排序,更好得观察有规律的数据)
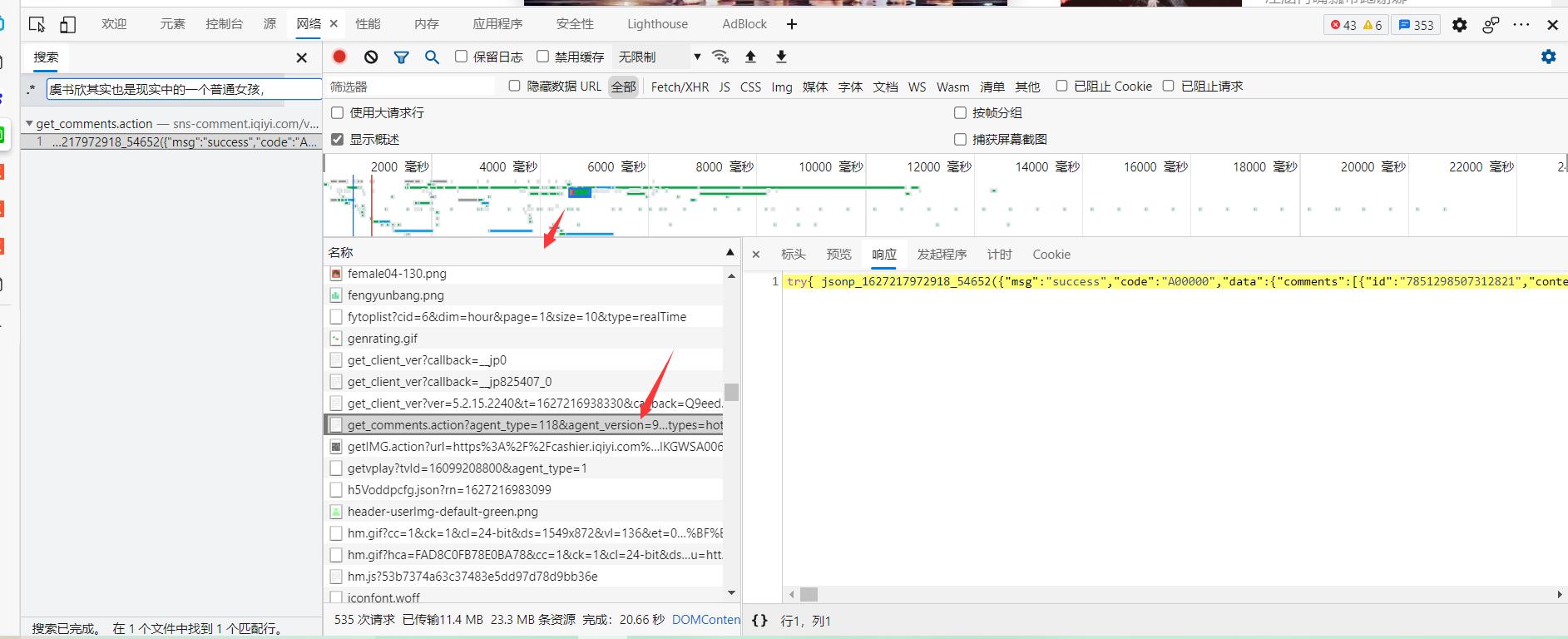
- 第五步,找到了它之后呢,我们可以先观察一下它的响应。发现他的数据是json格式的(这个有点经验吧,一般json格式的特点就是,列表和字典在一起),我们可以把这串数据到https://www.json.cn/去看一下这个响应的构成。
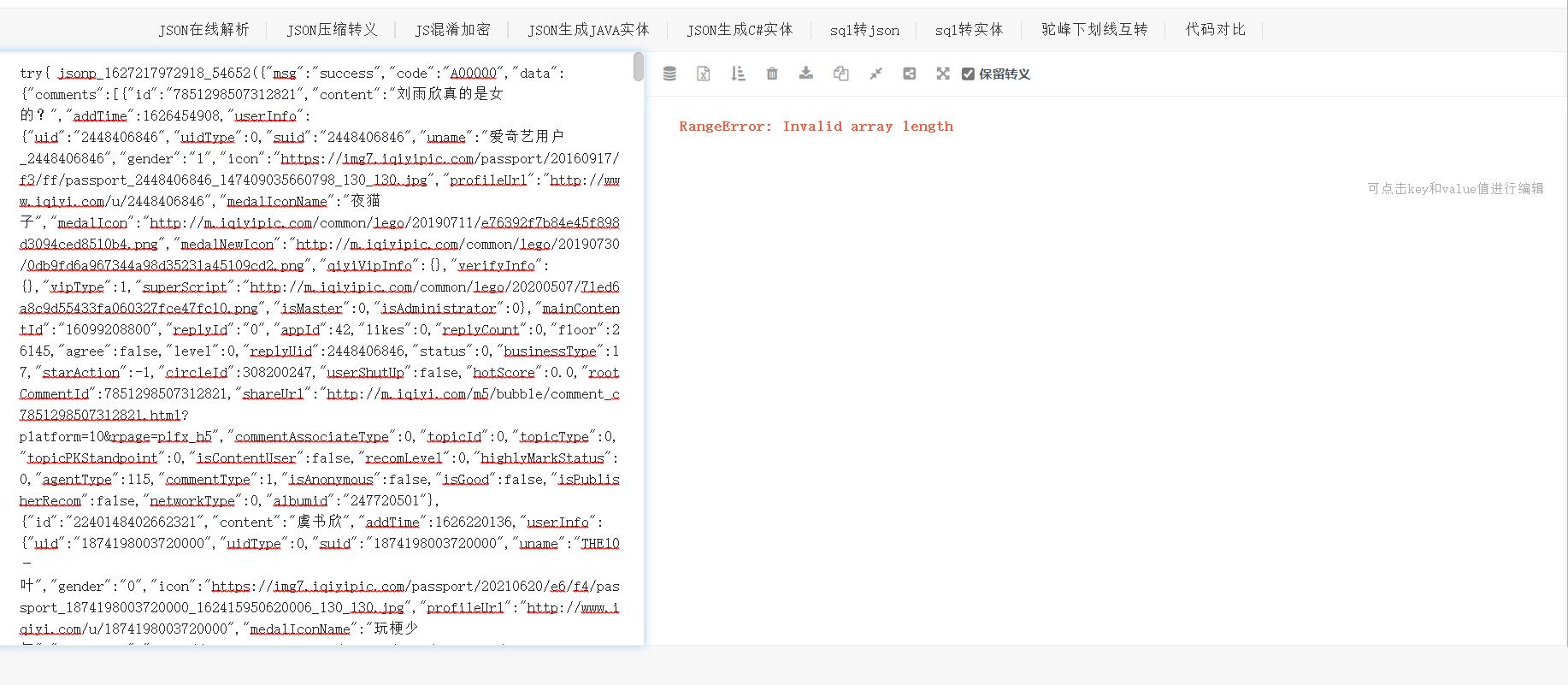
- 第六步看到报错之后呢,我们就会发现,这不是一个很正常的json格式数据,我们自习的看下数据的前面就会发现,这个字典前面还多出了一部分东西,我们可以将它删掉,然后我们就会得到一个正常的json数据了(这是一种经验之谈,其实在后面我们去分析请求网址的时候,想要等到一个规律的网址数据时,我们会有一种更方便的方法去获得这个json数据)(假如我们将浏览器返回给我们的数据整理成右图这样,那么我们获取数据就会十分简单了,下面也是为了这个目的)
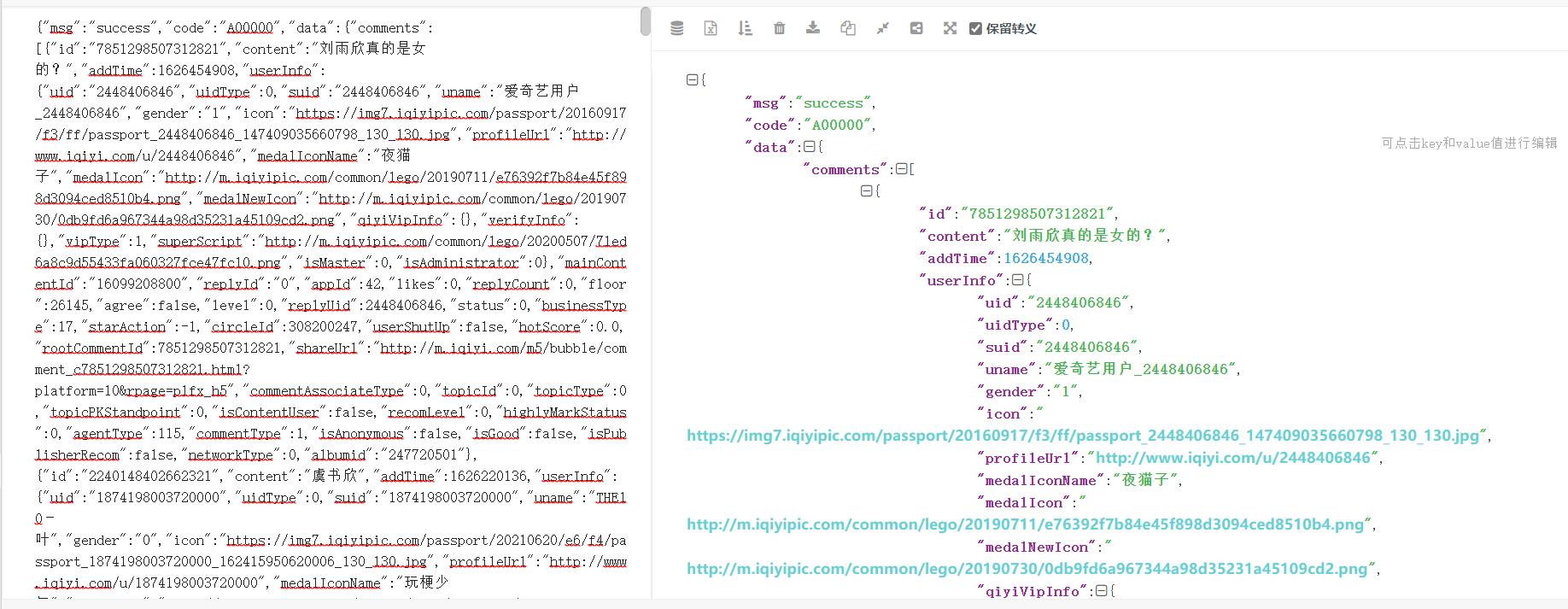
我们发现,这里的评论数据只有10条,明显不是全部的评论数据,但这时候我们就可以确定,这个get_comments.action基本就是评论数据所在的地方了,然后我们可以先留着这个网页,然后回去抓包工具的地方,继续观察。
- 第七步,当我们一步一步将评论往下面翻的时候,发现这个get_comments.action越来越多了,也证实了我们前面的想法
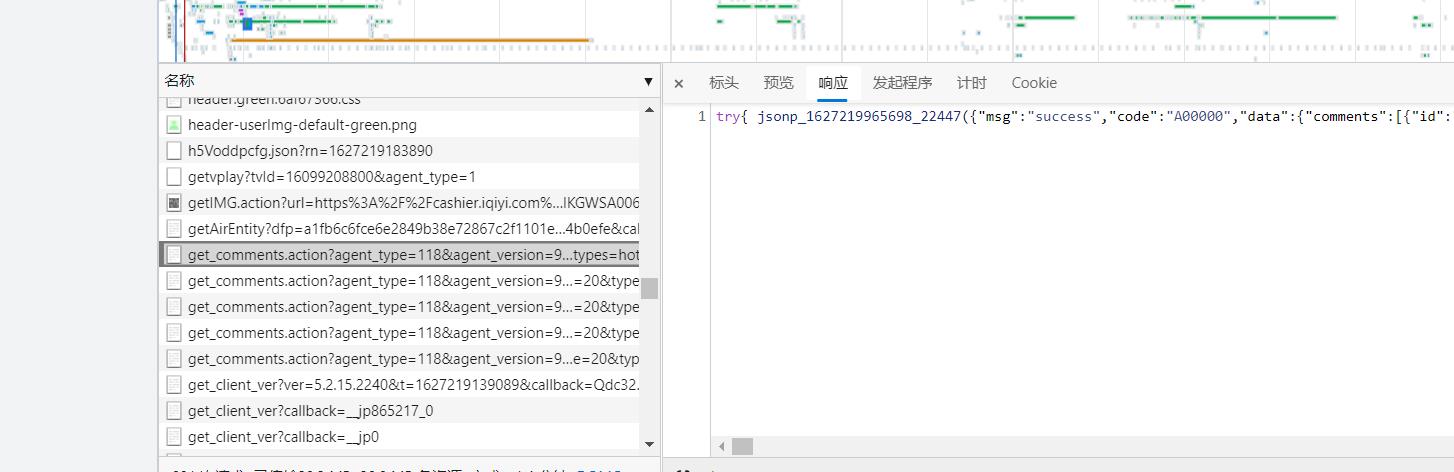
这时候我们可以点开标头,复制一下他的请求url到记事本中,来分析一下他们的规律,并且可以将标头翻到最下面,看着查询字符串参数一起看(其实这里的参数,就是网址里面的参数,只是我更喜欢放记事本中来看)。
- 第八步,分析代码,我们可以将它分成参数的形式(习惯),我做了以下一个尝试
- 看到最下面一项callback,发现返回的给我们的是jsonp格式的数据,
- 我们可以将它先改成json数据试试,直接将网址放到浏览器中,发现返回的数据变成了json格式,(知道前面还是有多余的东西,说明这个返回的会限制返回的数据格式),
- 我们将这个参数删除掉,然后就会发现,这时候就是一个单纯的json格式的数据了,我们可以将它直接放到json转换器中。这样也更方便我们后面的解码

我们向服务器发起一个请求,使用这个网址
import requests
url= 'https://sns-comment.iqiyi.com/v3/comment/get_comments.action?agent_type=118&agent_version=9.11.5&authcookie=b3YOhPajFgcajWm1pRZnX5IKGWSA006JVVqm1Y9DVNFvTM9zm17t9ee5a61JpgV2TYcsg59&business_type=17&channel_id=6&content_id=16099208800&hot_size=10&last_id=&page=&page_size=10&types=hot,time'
headers ={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.107 Safari/537.36 Edg/92.0.902.55'
}
request = requests.get(url, headers=headers)
request.encoding='utf-8'
# 使用这一步,就是对于服务器返回的数据,我们要解码成json数据,输出的结果就是我们想要的json数据(可以使用字符串,字典的方法去调用里面的数据)
response =request.json()
print(response)
- 第九步,我们就可以开始尝试找出代码的规律了,这里就省略最折磨的吧(总结,看到page=,经历使用page,不要去相信什么last_id之类的,我前面的误区就是,看到page为空,然后我对比几个评论的数据,发现只是last_id产生了变化,然后我就打算寻找出last_id的变化,但是我最后发现它是随机的,然后就自闭了,到最后还是抱着试一试的态度,去试了下page,发现这才是真爱),然后我就将content_id删除了,转而使用page为页面参数
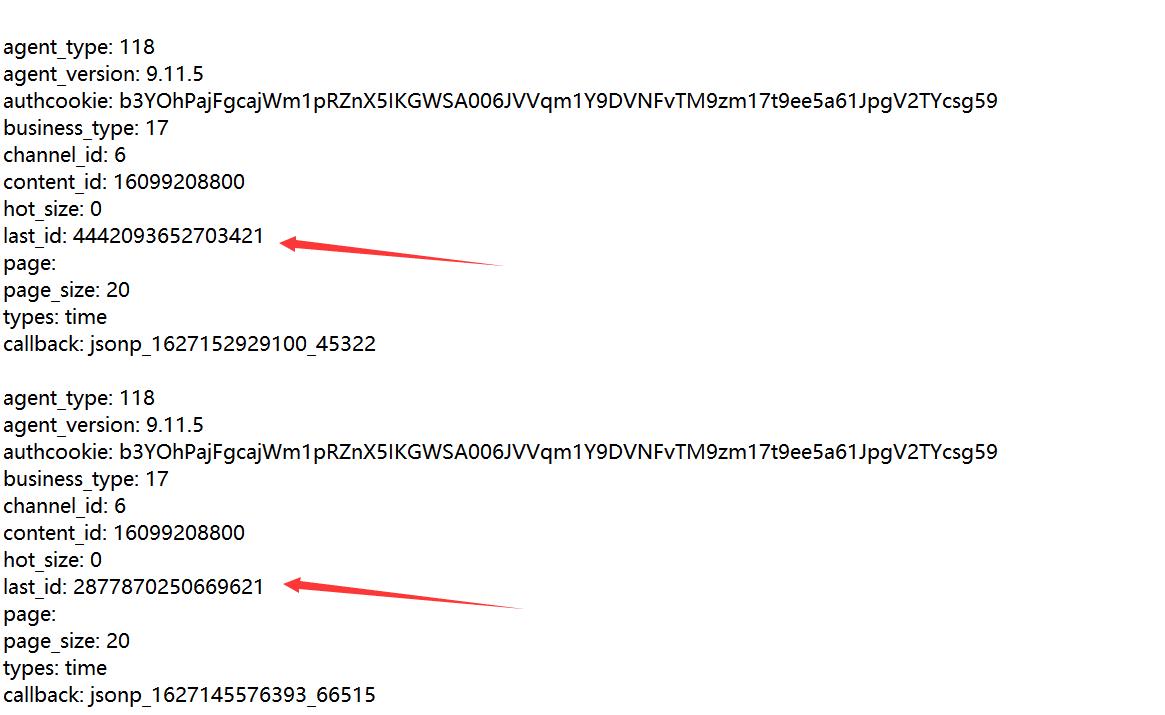
# 添加page参数,删除last_content
# 删除参数callback,返回的数据直接为字典
https://sns-comment.iqiyi.com/v3/comment/get_comments.action?agent_type=118
&agent_version=9.11.5
&authcookie=b3YOhPajFgcajWm1pRZnX5IKGWSA006JVVqm1Y9DVNFvTM9zm17t9ee5a61JpgV2TYcsg59
&business_type=17
&channel_id=6
&content_id=16099208800
# page_size中40条分为hot_size=0和普通comments=40条,只有第一页为10条,其余都为40条
&hot_size=30
&page_size=40
&types=hot,time
&page=1
找到规律了,这样我们就得到了请求url的格式了,只要去更改page就行了,然后就是开始处理一下它返回的数据了
第二部分,发起请求,处理服务器返回的数据
(中间也发现了一个很痛苦的问题,导致我一步一步调试,才看出来的)
第一步,我们对比着https://www.json.cn/整理好的数据,去得到一个列表
all_comments_list = response['data']['comments']
如果我们只是单纯的去按照常理去获得他们的评论数据的话,从他的page_size来看,每一页应该有40条数据,我去打印第一页的时候,直接就是超出了list,然后我就发现了,它的只要第一页是10条,其他的都是40条(无语~!),然后就让第一页单独立出来,本以为获取就结束了,没想到,下面才是最痛苦的问题。

发现获取键值错误,我当时就懵逼了,没碰到过,然后一步一步去看数据才发现**(强烈安利在控制台中运行代码,类似于在jupyter中运行,可以一步一步来,还会给你显示参数)**
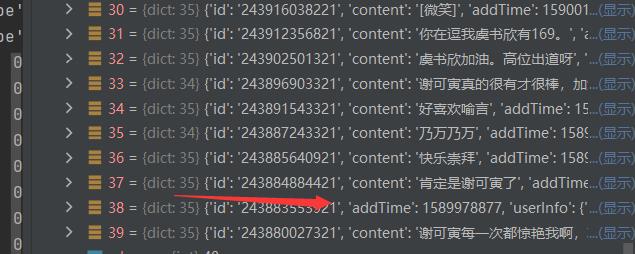
然后就发现了最阴间的问题,有些地方是没有content的,然后我就差点自闭了(这里找个好久好久)如下就解决了这个问题
if page == 1:
for i in range(10):
comments.append(all_comments_list[i]['content'])
# print(all_comments_list[i]['content'])
else:
for j in range(39):
# 因为存在有几个是没有content的情况,所以需要判断一下
if 'content' in all_comments_list[j]:
comments.append(all_comments_list[j]['content'])
# print(all_comments_list[j]['content'])
else:
comments.append(' ')
然后就开始处理数据了,删除转码失败的表情,和前面开头就有的标点符号和一些空的数据,为了下面更好的去分词。
'''
* name: not_empty:数据筛选
* para: NONE
* return:
* return_lx :
* writer: xihuanafeng
* function: 定义筛选规则,去除空, :和开头的,
* time: 2021/7/25
'''
def not_empty(s):
return s and s.strip() and s.strip(':') and s.strip(',')
'''
* name: comment_clear:数据整理函数
* para: 评论数据
* return: 整理好的评论数据
* return_lx : str
* writer: xihuanafeng
* function: 去除评论中的字母表情之类的数据
* time: 2021/7/25
'''
def comment_clear(content):
comment_clear_list = re.sub(r"</?(.+?)>| |\\t|\\r", "", content)
comment_clear_list = re.sub(r"\\n", " ", comment_clear_list)
clear_comment = re.sub('[^\\u4e00-\\u9fa5^a-z^A-Z^0-9]', '', comment_clear_list)
return clear_comment

接下来就是分词了
- 我们分词采用的是jieba(结巴),一个很好用的中文分词软件,大家可以去看下这位大佬的博客[https://blog.csdn.net/codejas/article/details/80356544],讲解的还是很清楚的。(我这里使用的是自定义的分词字典,在github里面有)
'''
* name: 分词函数
* para: 需要分词的句子或文本:str
* return: 分词后的数据
* return_lx : list
* writer: xihuanafeng
* function: 分词
* time: 2021/7/25
'''
def fenci(text):
jieba.load_userdict('add_words.txt') # 添加自定义字典
# seg = jieba.lcut(text, cut_all=False)
seg = jieba.lcut(text, cut_all=False) # 直接返回list
return seg
- 在分词的时候,会存在一些停用词,这些词不利于我们后面的分词,我们这里也将它去掉
'''
* name: 去除停用词
* para:
* return:
* return_lx :
* writer: xihuanafeng
* function:
* time: 2021/7/25
'''
def movestopwords(sentence, stopwords, counts):
'''
去除停用词,统计词频
参数 file_path:停用词文本路径 stopwords:停用词list counts: 词频统计结果
return:None
'''
out = []
for word in sentence:
if word not in stopwords:
if len(word) != 1:
counts[word] = counts.get(word, 0) + 1
return None
分好词之后呢,我们就进入到最后的阶段了,统计好词频去绘制词云图
'''
* name: 绘制词频统计表
* para: counts: 词频统计结果 num:绘制topN
* return: None
* return_lx : None
* writer: xihuanafeng
* function:
* time: 2021/7/25
'''
def drawcounts(counts, num):
'''
绘制词频统计表
参数 counts: 词频统计结果 num:绘制topN
return:none
'''
x_aixs = []
y_aixs = []
c_order = sorted(counts.items(), key=lambda x: x[1], reverse=True)
# print(c_order)
for c in c_order[:num]:
x_aixs.append(c[0])
y_aixs.append(c[1])
# 设置显示中文
matplotlib.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
matplotlib.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
plt.bar(x_aixs, y_aixs)
plt.title('词频统计结果')
plt.show()
'''
* name: 根据词频绘制词云图
* para: 参数 word_f:统计出的词频结果
* return: None
* return_lx : None
* writer: xihuanafeng
* function:
* time: 2021/7/25
'''
def drawcloud(word_f):
'''
根据词频绘制词云图
参数 word_f:统计出的词频结果
return:none
'''
# 加载背景图片
cloud_mask = np.array(Image.open('cluod.png'))
# 忽略显示的词
st = set(["东西", "这是"])
# 生成wordcloud对象
wc = WordCloud(background_color='white',
mask=cloud_mask,
max_words=150,
font_path='simhei.ttf',
min_font_size=10,
max_font_size=100,
width=400,
relative_scaling=0.3,
stopwords=st)
wc.fit_words(word_f)
wc.to_file('pic.png')
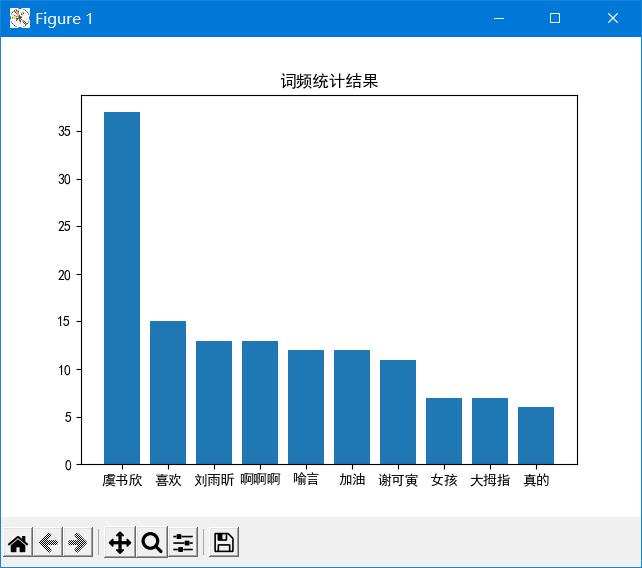
这是我们得到的词频统计表
这是我们得到的词云图
ps:效果还是挺不错的。爱奇艺的评论绝绝子,还是很乐观的。

总结:
- 第一点,爬虫方面问题:前面写的几个爬虫,像爬取京东的评论数据和爬取一个神奇网站的图片都没有碰到过这样的问题,网址寻找规律基本就是去尝试使用page参数,其他的变化基本可以后看。
- 第二点,数据处理方面:第一次碰见空值,导致无法很直接的去获取到全部数据,对于绘制词频图,和词云基本都是有相同的模板,都是通过调用一个库就可以轻松解决的。
希望各位大佬可以提提意见,可以说是第一次认真写博客,语言之类的也有点语无伦次。爱奇艺的评论真的把我爬吐了。。
已经开源在GitHub了,大家觉得写的可以的话可以点一点star的
或许大家进不去,大家可以上镜像站,也可以下载的,好像只是不可以点star
以上是关于Python实战手把手有教你写爬虫爬虫练手:看看爱奇艺的评论都在干啥(爬虫+词云分析)的主要内容,如果未能解决你的问题,请参考以下文章
手把手教你写电商爬虫-第五课 京东商品评论爬虫 一起来对付反爬虫
手把手教你写电商爬虫-第五课 京东商品评论爬虫 一起来对付反爬虫