密度聚类算法DBSCAN实战及可视化分析
Posted Data+Science+Insight
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了密度聚类算法DBSCAN实战及可视化分析相关的知识,希望对你有一定的参考价值。
密度聚类算法DBSCAN实战及可视化分析
目录
DBSCAN实战及聚类效果可视化
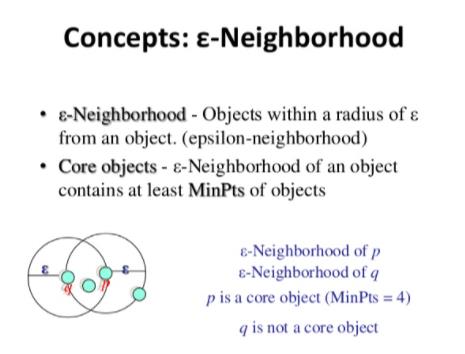
DBSCAN算法将数据集定义为高密度的连续区域,下面是它的工作原理:
对于每个实例,我们计算有多少实例位于离它很小的距离内(这个区域称为-邻域)。如果一个实例在它的-邻域中有≥min_samples实例,那么它被认为是一个核心实例。核心实例是那些位于密集区域的实例。
核心实例附近的所有实例都属于同一个族群。这个邻域可能包括其他核心实例。因此,相邻核心实例的长序列形成单个集群。
任何不是核心实例且在其邻域中没有核心实例的实例都被视为异常。
如果所有簇足够密集,并且它们被低密度区域很好地分隔,DBSCAN工作得很好。
#
from sklearn.cluster import DBSCAN
from sklearn.datasets import make_moons
X, y = make_moons(n_samples=1000, noise=0.05)
X.shape, y.shape((1000, 2), (1000,))
#
dbscan = DBSCAN(eps=0.05, min_samples=5)
dbscan.fit(X)DBSCAN(algorithm='auto', eps=0.05, leaf_size=30, metric='euclidean',
metric_params=None, min_samples=5, n_jobs=None, p=None)#获取聚类的预测标签
dbscan.labels_[:5]array([0, 0, 1, 0, 2])#如果样本的标签被标注为-1,那么意味着在DBSCAN算法看来该样本是一个异常样本;
# 获得核心样本的个数;
len(dbscan.core_sample_indices_)#
# actual core instances coords
dbscan.components_array([[ 1.97735134, 0.16746005],
[ 1.73191549, -0.24587221],
[ 0.04933691, 0.09386341],
...,
[ 0.9702814 , 0.18676075],
[-0.77970719, 0.60591176],
[ 0.39840368, 0.90286737]])
#可视化DBSCAN聚类的效果
plt.figure(figsize=(12, 8))
plt.scatter(X[:, 0], X[:, 1], c=dbscan.labels_)
plt.axis('off')
plt.show()
# 增大算法的临域值重新进行可视化分析
dbscan = DBSCAN(eps=0.2, min_samples=5)
dbscan.fit(X)DBSCAN(algorithm='auto', eps=0.2, leaf_size=30, metric='euclidean',
metric_params=None, min_samples=5, n_jobs=None, p=None)plt.figure(figsize=(12, 8))
plt.scatter(X[:, 0], X[:, 1], c=dbscan.labels_)
plt.axis('off')
plt.show()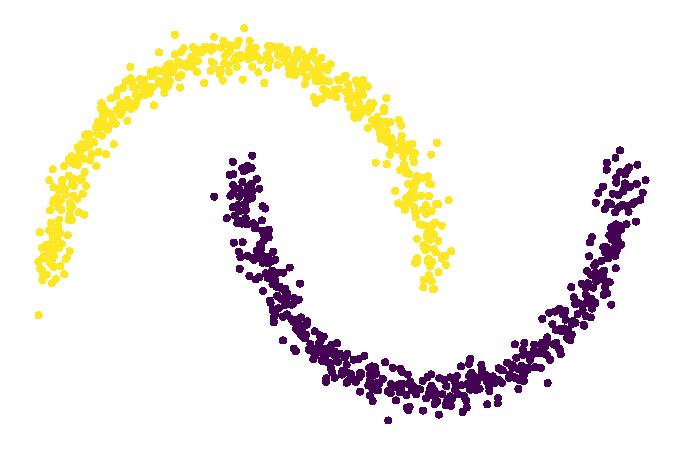
构建分类算法获得预测推理能力
# DBSCAN没有针对新实例的predict()方法,因此,我们将在训练目标上训练一个分类器来对新实例进行分类。
# 训练样本为DBSCAN聚类获得的核心实例,以及他们对应的聚类标签;
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=50)
knn.fit(dbscan.components_, dbscan.labels_[dbscan.core_sample_indices_])
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=None, n_neighbors=50, p=2,
weights='uniform')X_new = np.array([[-0.5, 0.], [0, 0.5], [1, -0.1], [2, 1]])
knn.predict(X_new)
knn.predict_proba(X_new)array([1, 0, 1, 0])array([[0.22, 0.78],
[1. , 0. ],
[0.18, 0.82],
[1. , 0. ]])注意,我们只在核心实例上训练分类器,但我们也可以选择在所有实例上训练分类器,或者在异常之外的所有实例上训练分类器。这取决于最后的任务。
因为我们没有在异常上训练我们的分类器,所以任何新的实例都将被放入我们的已知的聚类簇中。
引入一个最大距离是相当简单的,在这种情况下,远离两个簇的那两个实例就会被归类为异常样本。
y_dist, y_pred_idx = knn.kneighbors(X_new, n_neighbors=1)
y_pred = dbscan.labels_[dbscan.core_sample_indices_][y_pred_idx]
y_pred[y_dist > 0.2] = -1
y_pred.ravel()array([-1, 0, 1, -1])简而言之,DBSCAN是一个非常简单但强大的算法,能够识别任意形状的任意数目的集群。它对离群点具有鲁棒性,并且只有两个超参数(eps和min_samples)。
如果聚类簇之间的密度差异很大,那么它就不可能正确地捕捉所有的聚类簇。
Its computational complexity is roughly 𝑂(𝑚𝑙𝑜𝑔(𝑚))O(mlog(m)) making it pretty close to linear regarding the number of instances. However, its sklearn implementation can require up to 𝑂(𝑚2)O(m2) in memory if eps is large.
参考:Hands-on-Machine-Learning-with-Scikit-Learn-Keras-and-TensorFlow
参考:DBSCAN
以上是关于密度聚类算法DBSCAN实战及可视化分析的主要内容,如果未能解决你的问题,请参考以下文章