Note_Spark_Day08:Spark SQL(Dataset是什么外部数据源UDF定义和分布式SQL引擎)
Posted 大数据Manor
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Note_Spark_Day08:Spark SQL(Dataset是什么外部数据源UDF定义和分布式SQL引擎)相关的知识,希望对你有一定的参考价值。
stypora-copy-images-to: img
typora-root-url: ./
Spark Day08:Spark SQL

01-[了解]-昨日课程内容回顾
上次课程主要讲解3个方面内容:SparkSQL模块概述、DataFrame数据集及综合案例分析。
1、SparkSQL 模块概述
- 发展史【前世今生】
Shark -> SparkSQL(1.0) -> DataFrame(1.3) -> Dataset(1.6) -> Dataset/DataFrame(2.0)
Spark2.0中SparkSQL模块
不仅可以处理离线数据(批处理),还可以处理流式数据(流计算)
spark.read 批处理
spark.readStream 流计算
将SparkSQL可以处理流式数据功能,单独提出来,称为:StructuredStreaming结构化流
Spark2.2 版本
StructuredStreaming 发布Release版本
- 官方定义:
Spark框架模块,针对结构化数据处理模块
- Module,Structure结构化数据
- DataFrame,数据结构,底层还是RDD,加上Schema约束
- SQL 分析引擎,可以类似Hive框架,解析SQL,转换为RDD操作
- 4个特性
易用性、多数据源、JDBC/ODBC方式、与Hive集成
2、DataFrame 是什么
- 基于RDD之上分布式数据集,并且Schema信息,Schema就是数据内部结果,包含字段名称和字段类型
RDD[Person] 与 DataFrame比较
DataFrame知道数据内部结构,在计算数据之前,可以有针对性进行优化,提升性能
- DataFrame = RDD[Row] + Schema + 优化
来源Python中Pandas数据结构或R语言数据类型
- RDD 转换DataFrame方式
第一种:RDD[CaseClass]直接转换DataFrame
第二种:RDD[Row] + Schema
toDF函数,指定列名称,前提条件:RDD中数据类型为元组类型,或者Seq序列中数据类型为元组
3、电影评分统计分析【使用DataFrame封装】
- SparkSQL中数据分析2种方式:
方式一:SQL编程
类似Hive中SQL语句
方式二:DSL编程
调用DataFrame中函数,包含类似RDD转换函数和类似SQL关键词函数
- 案例分析
- step1、加载文本数据为RDD
- step2、通过toDF函数转换为DataFrame
- step3、编写SQL分析
先注册DataFrame为临时视图、再编写SQL执行
- step4、编写DSL分析
groupBy、agg、filter、sortBy、limit
导入函数库:import org.apache.spark.sql.functions._
- step5、保存结果数据
先保存到mysql表中
再保存到CSV文件
无论是编写DSL还是SQL,性能都是一样的,注意调整参数:Shuffle是分区数目
spark.sql.shuffle.partitions=200
Spark 3.0无需调整
02-[了解]-今日课程内容提纲
主要讲解4个方面内容:Dataset是什么、外部数据源、UDF定义和分布式SQL引擎
1、Dataset 数据结构
Dataset = RDD[T] + Schema,可以外部数据类型、也可以知道内部数据结构
以特殊编码存储数据,比RDD数据结构存储更加节省空间
RDD、DataFrame和Dataset区别与联系
2、外部数据源
如何加载和保存数据,编程模块
保存数据时,保存模式
内部支持外部数据源
自定义外部数据源,实现HBase,直接使用,简易版本
集成Hive,从Hive表读取数据分析,也可以将数据保存到Hive表,企业中使用最多
使用Hive框架进行数据管理,使用SparkSQL分析处理数据
3、自定义UDF函数
2种方式,分别在SQL中使用和在DSL中使用
4、分布式SQL引擎
此部分内容,与Hive框架功能一直
spark-sql 命令行,专门提供编写SQL语句
类似Hive框架种hive
SparkSQL ThriftServer当做一个服务运行,使用JDBC/ODBC方式连接,发送SQL语句执行
类似HiveServer2服务
- jdbc 代码
- beeline命令行,编写SQL
03-[掌握]-Dataset 是什么
Dataset是在Spark1.6中添加的新的接口,是DataFrame API的一个扩展,是Spark最新的数据抽象
,结合了RDD和DataFrame的优点。

Dataset是一个强类型的特定领域的对象,这种对象可以函数式或者关系操作并行地转换。

从Spark 2.0开始,DataFrame与Dataset合并,每个Dataset也有一个被称为一个DataFrame的类型化视图,这种DataFrame是Row类型的Dataset,即Dataset[Row]。
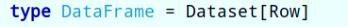
针对Dataset数据结构来说,可以简单的从如下四个要点记忆与理解:
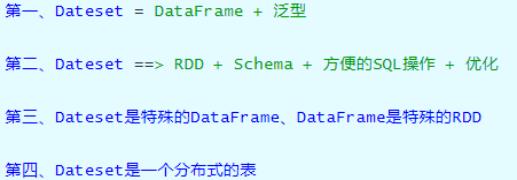
Spark 框架从最初的数据结构RDD、到SparkSQL中针对结构化数据封装的数据结构DataFrame,
最终使用Dataset数据集进行封装,发展流程如下。
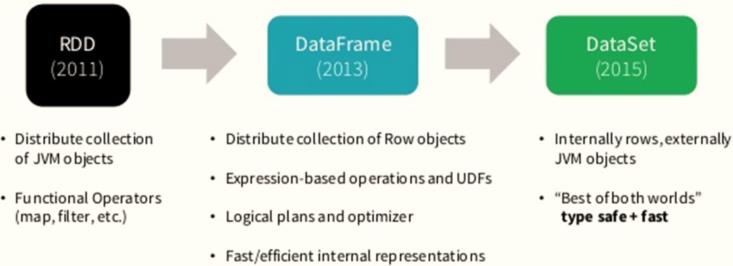
所以在实际项目中建议使用
Dataset进行数据封装,数据分析性能和数据存储更加好。
针对RDD、DataFrame与Dataset三者编程比较来说,Dataset API无论语法错误和分析错误在编译时都能发现,然而RDD和DataFrame有的需要在运行时才能发现。
此外RDD与Dataset相比较而言,由于Dataset数据使用特殊编码,所以在存储数据时更加节省内存。
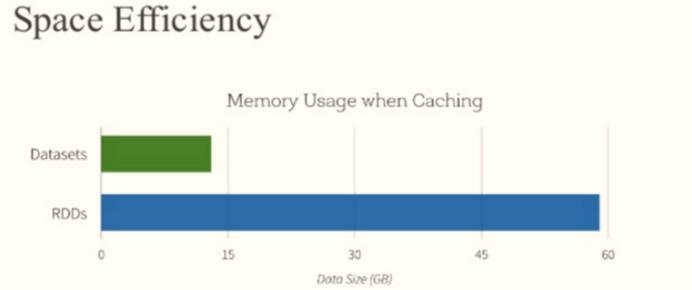
由于Dataset数据结构,是一个强类型分布式集合,并且采用特殊方式对数据进行编码,所以与DataFrame相比,编译时发现语法错误和分析错误,以及缓存数据时比RDD更加节省空间。
package cn.itcast.spark.ds
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.types.StructType
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession}
/**
* 采用反射的方式将RDD转换为Dataset
*/
object _01SparkDatasetTest {
def main(args: Array[String]): Unit = {
// 构建SparkSession实例对象,设置应用名称和master
val spark: SparkSession = SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[3]")
.getOrCreate()
import spark.implicits._
// 1. 加载电影评分数据,封装数据结构RDD
val rawRatingRDD: RDD[String] = spark.sparkContext.textFile("datas/ml-100k/u.data")
// 2. 将RDD数据类型转化为 MovieRating
/*
将原始RDD中每行数据(电影评分数据)封装到CaseClass样例类中
*/
val ratingRDD: RDD[MovieRating] = rawRatingRDD.mapPartitions { iter =>
iter.map { line =>
// 按照制表符分割
val arr: Array[String] = line.trim.split("\\\\t")
// 封装样例对象
MovieRating(
arr(0), arr(1), arr(2).toDouble, arr(3).toLong
)
}
}
// TODO: 3. 将RDD转换为Dataset,可以通过隐式转, 要求RDD数据类型必须是CaseClass
val ratingDS: Dataset[MovieRating] = ratingRDD.toDS()
ratingDS.printSchema()
ratingDS.show(10, truncate = false)
/*
Dataset 从Spark1.6提出
Dataset = RDD + Schema
DataFrame = RDD[Row] + Schema
Dataset[Row] = DataFrame
*/
// 从Dataset中获取RDD
val rdd: RDD[MovieRating] = ratingDS.rdd
val schema: StructType = ratingDS.schema
// 从Dataset中获取DataFrame
val ratingDF: DataFrame = ratingDS.toDF()
// 给DataFrame加上强类型(CaseClass)就是Dataset
/*
DataFrame中字段名称与CaseClass中字段名称一致
*/
val dataset: Dataset[MovieRating] = ratingDF.as[MovieRating]
// 应用结束,关闭资源
spark.stop()
}
}
04-[掌握]-RDD、DS和DF之间转换
实际项目开发,常常需要对RDD、DataFrame及Dataset之间相互转换,其中要点就是Schema约束结构信息。
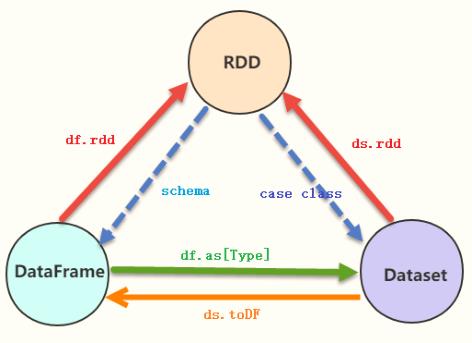
范例演示:分别读取people.txt文件数据封装到RDD、DataFrame及Dataset,查看区别及相互转换。
[root@node1 ~]# /export/server/spark/bin/spark-shell --master local[2]
21/04/27 09:12:40 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://node1.itcast.cn:4040
Spark context available as 'sc' (master = local[2], app id = local-1619485981944).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\\ \\/ _ \\/ _ `/ __/ '_/
/___/ .__/\\_,_/_/ /_/\\_\\ version 2.4.5
/_/
Using Scala version 2.11.12 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_241)
Type in expressions to have them evaluated.
Type :help for more information.
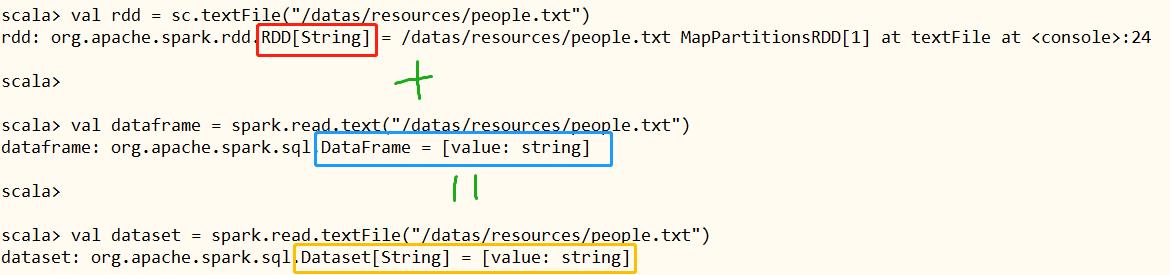
scala> val rdd = sc.textFile("/datas/resources/people.txt")
rdd: org.apache.spark.rdd.RDD[String] = /datas/resources/people.txt MapPartitionsRDD[1] at textFile at <console>:24
scala>
scala> val dataframe = spark.read.text("/datas/resources/people.txt")
dataframe: org.apache.spark.sql.DataFrame = [value: string]
scala>
scala> val dataset = spark.read.textFile("/datas/resources/people.txt")
dataset: org.apache.spark.sql.Dataset[String] = [value: string]
scala>
scala> dataframe.rdd
res0: org.apache.spark.rdd.RDD[org.apache.spark.sql.Row] = MapPartitionsRDD[6] at rdd at <console>:26
scala> dataset.rdd
res1: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[11] at rdd at <console>:26
scala>
scala> dataset.toDF()
res2: org.apache.spark.sql.DataFrame = [value: string]
scala> dataframe.as[String]
res3: org.apache.spark.sql.Dataset[String] = [value: string]
读取Json数据,封装到DataFrame中,指定CaseClass,转换为Dataset
scala> val empDF = spark.read.json("/datas/resources/employees.json")
empDF: org.apache.spark.sql.DataFrame = [name: string, salary: bigint]
scala>
scala> empDF.show()
+-------+------+
| name|salary|
+-------+------+
|Michael| 3000|
| Andy| 4500|
| Justin| 3500|
| Berta| 4000|
+-------+------+
scala>
scala> case class Emp(name: String, salary: Long)
defined class Emp
scala>
scala> val empDS = empDF.as[Emp]
empDS: org.apache.spark.sql.Dataset[Emp] = [name: string, salary: bigint]
scala> empDS.printSchema()
root
|-- name: string (nullable = true)
|-- salary: long (nullable = true)
scala> empDS.show()
+-------+------+
| name|salary|
+-------+------+
|Michael| 3000|
| Andy| 4500|
| Justin| 3500|
| Berta| 4000|
+-------+------+
05-[掌握]-外部数据源之加载load和保存save数据
在SparkSQL模块,提供一套完成API接口,用于方便读写外部数据源的的数据(从Spark 1.4版本提供),框架本身内置外部数据源:
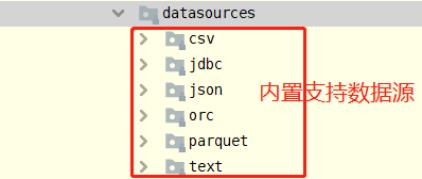
SparkSQL提供一套通用外部数据源接口,方便用户从数据源加载和保存数据,例如从MySQL表中既可以加载
读取数据:load/read,又可以保存写入数据:save/write。
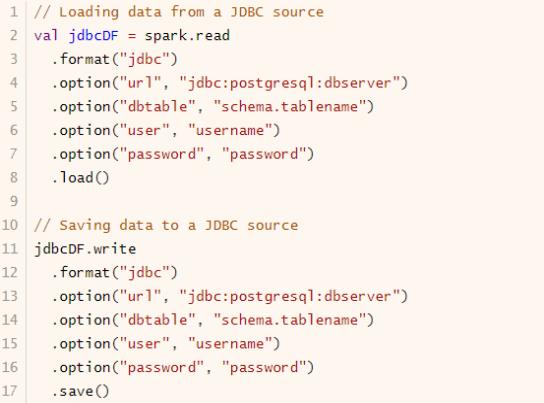
- Load 加载数据
在SparkSQL中读取数据使用SparkSession读取,并且封装到数据结构Dataset/DataFrame中。
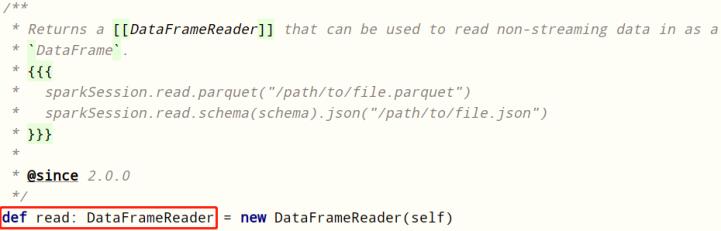
DataFrameReader专门用于加载load读取外部数据源的数据,基本格式如下:

SparkSQL模块本身自带支持读取外部数据源的数据:

- Save 保存数据
SparkSQL模块中可以从某个外部数据源读取数据,就能向某个外部数据源保存数据,提供相应接口,通过DataFrameWrite类将数据进行保存

与DataFrameReader类似,提供一套规则,将数据Dataset保存,基本格式如下:

SparkSQL模块内部支持保存数据源如下:

当将结果数据DataFrame/Dataset保存至Hive表中时,可以设置分区partition和分桶bucket,形式如下:

可以发现,SparkSQL模块中内置数据源中,并且对HBase表数据读取和写入支持,但是可以自己实现外部数据源接口,方便读写数据。
06-[了解]-外部数据源之案例演示及应用场景
scala> val peopleDF = spark.read.json("/datas/resources/people.json")
peopleDF: org.apache.spark.sql.DataFrame = [age: bigint, name: string]
scala> peopleDF.show()
+----+-------+
| age| name|
+----+-------+
|null|Michael|
| 30| Andy|
| 19| Justin|
+----+-------+
scala>
scala> val resultDF = peopleDF.select("name", "age")
resultDF: org.apache.spark.sql.DataFrame = [name: string, age: bigint]
scala>
scala> resultDF.show()
+-------+----+
| name| age|
+-------+----+
|Michael|null|
| Andy| 30|
| Justin| 19|
+-------+----+
scala>
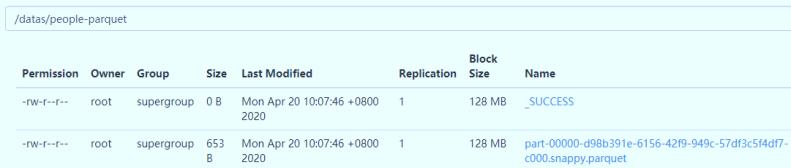
scala> resultDF.write.parquet("/datas/people-parquet")
scala> spark.read.parquet("/datas/people-parquet/part-00000-a967d124-52d8-4ffe-91c6-59aebfed22b0-c000.snappy.parquet")
res11: org.apache.spark.sql.DataFrame = [name: string, age: bigint]
scala> res11.show(
| )
+-------+----+
| name| age|
+-------+----+
|Michael|null|
| Andy| 30|
| Justin| 19|
+-------+----+
查看HDFS文件系统目录,数据已保存值parquet文件,并且使用snappy压缩。
07-[掌握]-外部数据源之保存模式SaveMode
当将DataFrame或Dataset数据保存时,默认情况下,如果存在,会抛出异常。

DataFrameWriter中有一个mode方法指定模式:
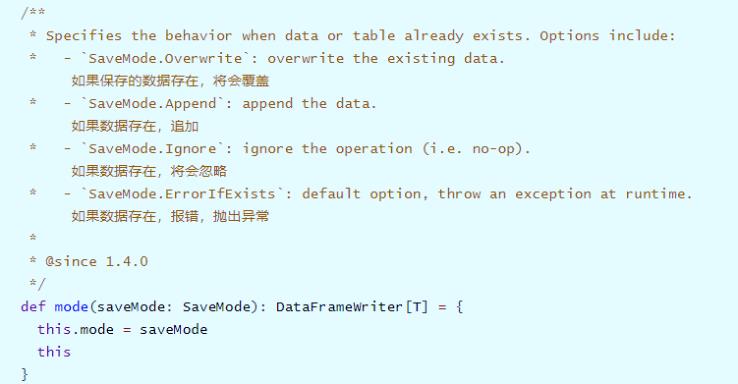
通过源码发现SaveMode时枚举类,使用Java语言编写,如下四种保存模式:
⚫ 第一种:Append 追加模式,当数据存在时,继续追加;
⚫ 第二种:Overwrite 覆写模式,当数据存在时,覆写以前数据,存储当前最新数据;
⚫ 第三种:ErrorIfExists 存在及报错;
⚫ 第四种:Ignore 忽略,数据存在时不做任何操作;
由于保存DataFrame时,需要合理设置保存模式,
使得将数据保存数据库时,存在一定问题的。
Append追加模式:
- 数据重复,最明显错误就是:主键已经存在
Overwrite覆盖模式:
- 将原来的数据删除,对于实际项目来说,以前分析结果也是需要的,不允许删除
08-[掌握]-外部数据源之案例演示(parquet、text和json)
SparkSQL模块中默认读取数据文件格式就是parquet列式存储数据,通过参数【
spark.sql.sources.default】设置,默认值为【parquet】。
范例演示代码:直接load加载parquet数据和指定parquet格式加载数据。
// 构建SparkSession实例对象
val spark: SparkSession = SparkSession.builder()
.master("local[4]")
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.config("spark.sql.shuffle.partitions", "4")
.getOrCreate()
import spark.implicits._
// TODO 1. parquet列式存储数据
// format方式加载
//val df1 = spark.read.format("parquet").load("datas/resources/users.parquet")
val df1: DataFrame = spark.read
.format("parquet")
.option("path", "datas/resources/users.parquet")
.load()
df1.printSchema()
df1.show(10, truncate = false)
// parquet方式加载
val df2: DataFrame = spark.read.parquet("datas/resources/users.parquet")
df2.show(10, truncate = false)
// load方式加载,在SparkSQL中,当加载读取文件数据时,如果不指定格式,默认是parquet格式数据
val df3: DataFrame = spark.read.load("datas/resources/users.parquet")
df3.show(10, truncate = false)
SparkSession加载文本文件数据,提供两种方法,返回值分别为DataFrame和Dataset
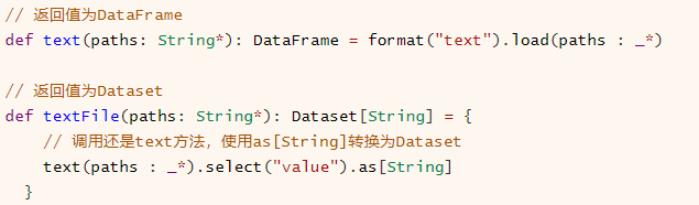
无论是
text方法还是textFile方法读取文本数据时,一行一行的加载数据,每行数据使用UTF-8编码的字符串,列名称为【value】。
// TODO: 2. 文本数据加载,text -> DataFrame textFile -> Dataset
// 无论是 text 还是 textFile 加载文本数据时,字段名称:value, 类型String
val peopleDF: DataFrame = spark.read.text("datas/resources/people.txt")
peopleDF.show(10, truncate = false)
val peopleDS: Dataset[String] = spark.read.textFile("datas/resources/people.txt")
peopleDS.show(10, truncate = false)
读取JSON格式文本数据,往往有2种方式:
- 方式一:直接指定数据源为json,加载数据,自动生成Schema信息
spark.read.json("")
- 方式二:以文本文件方式加载,然后使用函数(get_json_object)提取JSON中字段值
val dataset = spark.read.textFile("") dataset.select( get_json_object($"value", "$.name") )
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Z6rA4Zfq-1627175964710)(/img/image-20210427101740141.png)]
/* =========================================================================== */
// TODO: 3. 读取JSON格式数据,自动解析,生成Schema信息
val empDF: DataFrame = spark.read.json("datas/resources/employees.json")
empDF.printSchema()
empDF.show(10, truncate = false)
/* =========================================================================== */
// TODO: 实际开发中,针对JSON格式文本数据,直接使用text/textFile读取,然后解析提取其中字段信息
/*
{"name":"Andy", "salary":30} - value: String
| 解析JSON格式,提取字段
name: String, -> Andy
salary : Int, -> 30
*/
val dataframe: Dataset[String] = spark.read.textFile("datas/resources/employees.json")
// 对JSON格式字符串,SparkSQL提供函数:get_json_object, def get_json_object(e: Column, path: String): Column
import org.apache.spark.sql.functions.get_json_object
val df = dataframe
.select(
get_json_object($"value", "$.name").as("name"),
get_json_object($"value", "$.salary").cast(IntegerType).as("salary")
)
df.printSchema()
df.show(10, truncate = false)
09-[掌握]-外部数据源之案例演示(csv和jdbc)
关于CSV/TSV格式数据说明:

SparkSQL中读取CSV格式数据,可以设置一些选项,重点选项:

// TODO: 1. CSV 格式数据文本文件数据 -> 依据 CSV文件首行是否是列名称,决定读取数据方式不一样的
/*
CSV 格式数据:
每行数据各个字段使用逗号隔开
也可以指的是,每行数据各个字段使用 单一 分割符 隔开数据
*/
// 方式一:首行是列名称,数据文件u.dat
val dataframe: DataFrame = spark.read
.format("csv")
.option("sep", "\\\\t")
.option("header", "true")
.option("inferSchema", "true")
.load("datas/ml-100k/u.dat")
dataframe.printSchema()
dataframe.show(10, truncate = false)
// 方式二:首行不是列名,需要自定义Schema信息,数据文件u.data
// 自定义schema信息
val schema: StructType = new StructType()
.add("user_id", IntegerType, nullable = true)
.add("iter_id", IntegerType, nullable = true)
.add("rating", DoubleType, nullable = true)
.add("timestamp", LongType, nullable = true)
val df: DataFrame = spark.read
.format("csv")
.schema(schema)
.option("sep", "\\\\t")
.load("datas/ml-100k/u.data")
df.printSchema()
df.show(10, truncate = false)
在SparkSQL模块中提供对应接口,提供三种方式读取数据:
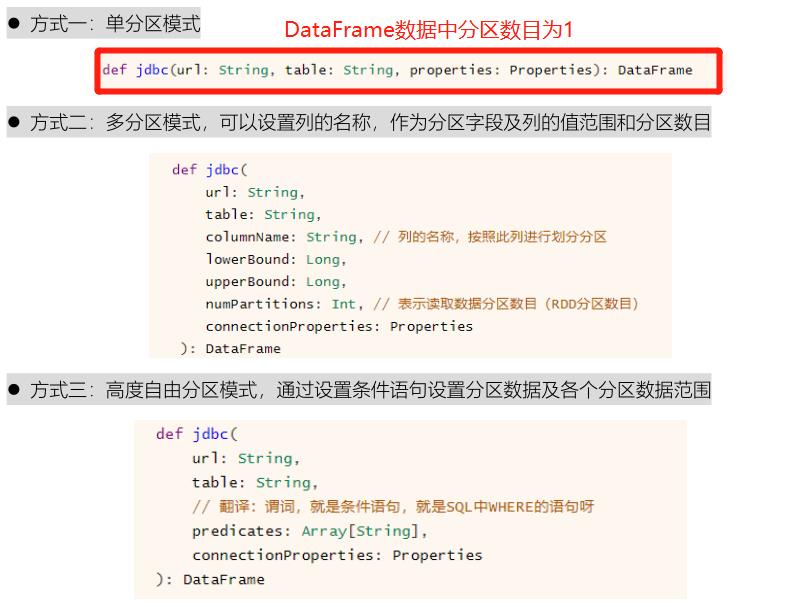
// TODO: 2. 读取MySQL表中数据
// 第一、简洁版格式
/*
def jdbc(url: String, table: String, properties: Properties): DataFrame
*/
val props = new Properties()
props.put("user", "root")
props.put("password", "123456")
props.put("driver", "com.mysql.cj.jdbc.Driver")
val empDF: DataFrame = spark.read.jdbc(
"jdbc:mysql://node1.itcast.cn:3306/?serverTimezone=UTC&characterEncoding=utf8&useUnicode=true", //
"db_test.emp", //
props //
)
println(s"Partition Number = ${empDF.rdd.getNumPartitions}")
empDF.printSchema()
empDF.show(10, truncate = false)
// 第二、标准格式写
/*
WITH tmp AS (
select * from emp e join dept d on e.deptno = d.deptno
)
*/
val table: String = "(select ename,deptname,sal from db_test.emp e join db_test.dept d on e.deptno = d.deptno) AS tmp"
val joinDF: DataFrame = spark.read
.format("jdbc")
.option("url", "jdbc:mysql://node1.itcast.cn:3306/?serverTimezone=UTC&characterEncoding=utf8&useUnicode=true")
.option("driver", "com.mysql.cj.jdbc.Driver")
.option("user", "root")
.option("password", "123456")
.option("dbtable", table)
.load()
joinDF.printSchema()
joinDF.show(10, truncate = false)
从RDBMS表中读取数据,需要设置连接数据库相关信息,基本属性选项如下:
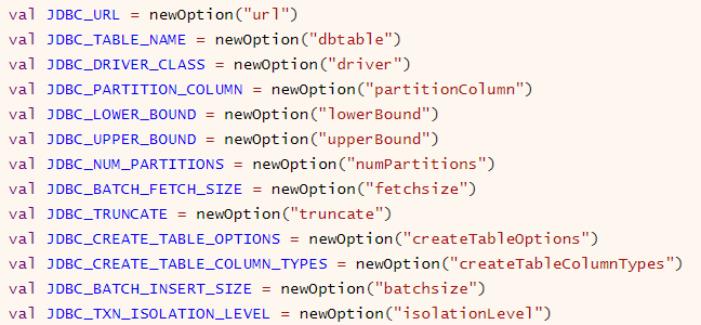
10-[掌握]-外部数据源之集成Hive(spark-shell)
Spark SQL模块从发展来说,从Apache Hive框架而来,发展历程:Hive(MapReduce)-> Shark(Hive on Spark) -> Spark SQL(SchemaRDD -> DataFrame -> Dataset),所以SparkSQL天然无缝集成Hive,可以加载Hive表数据进行分析。
- 第一步、当编译Spark源码时,需要指定集成Hive,命令如下

- 第二步、SparkSQL集成Hive本质就是:读取Hive框架元数据MetaStore,此处启动Hive MetaStore
服务即可。
# 直接运行如下命令,启动HiveMetaStore服务
[root@node1 ~]# hive-daemon.sh metastore
- 第三步、连接HiveMetaStore服务配置文件
hive-site.xml,放于【$SPARK_HOME/conf】目录
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hive.metastore.uris</name>
<value>thrift://node1.itcast.cn:9083</value>
</property>
</configuration>
- 第四步、案例演示,读取Hive中db_hive.emp表数据,分析数据
[root@node1 spark]# bin/spark-shell --master local[2]
21/04/27 10:55:37 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://node1.itcast.cn:4040
Spark context available as 'sc' (master = local[2], app id = local-1619492151923).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\\ \\/ _ \\/ _ `/ __/ '_/
/___/ .__/\\_,_/_/ /_/\\_\\ version 2.4.5
/_/
Using Scala version 2.11.12 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_241)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
scala> val empDF = spark.read.table("db_hive.emp")
empDF: org.apache.spark.sql.DataFrame = [empno: int, ename: string ... 6 more fields]
scala> empDF.show()
+-----+------+---------+----+----------+------+------+------+
|empno| ename| job| mgr| hiredate| sal| comm|deptno|
+-----+------+---------+----+----------+------+------+------+
| 7369| SMITH| CLERK|7902|1980-12-17| 800.0| null| 20|
| 7499| ALLEN| SALESMAN|7698| 1981-2-20|1600.0| 300.0| 30|
| 7521| WARD| SALESMAN|7698| 1981-2-22|1250.0| 500.0| 30|
| 7566| JONES| MANAGER|7839| 1981-4-2|2975.0| null| 20|
| 7654|MARTIN| SALESMAN|7698| 1981-9-28|1250.0|1400.0| 30|
| 7698| BLAKE| MANAGER|7839| 1981-5-1|2850.0| null| 30|
| 7782| CLARK| MANAGER|7839| 1981-6-9|2450.0| null| 10|
| 7788| SCOTT| ANALYST|7566| 1987-4-19|3000.0| null| 20|
| 7839| KING|PRESIDENT|null|1981-11-17|5000.0| null| 10|
| 7844|TURNER| SALESMAN|7698| 1981-9-8|1500.0| 0.0| 30|
| 7876| ADAMS| CLERK|7788| 1987-5-23|1100.0| null| 20|
| 7900| JAMES| CLERK|7698| 1981-12-3| 950.0| null| 30|
| 7902| FORD| ANALYST|7566| 1981-12-3|3000.0| null| 20|
| 7934|MILLER| CLERK|7782| 1982-1-23|1300.0| null| 10|
+-----+------+---------+----+----------+------+------+------+
scala> empDF.printSchema()
root
|-- empno: integer (nullable = true)
|-- ename: string (nullable = true)
|-- job: string (nullable = true)
|-- mgr: integer (nullable = true)
|-- hiredate: string (nullable = true)
|-- sal: double (nullable = true)
|-- comm: double (nullable = true)
|-- deptno: integer (nullable = true)
scala>
scala> spark.sql("select * from db_hive.emp").show()
+-----+------+---------+----+----------+------+------+------+
|empno| ename| job| mgr| hiredate| sal| comm|deptno|
+-----+------+---------+----+----------+------+------+------+
| 7369| SMITH| CLERK|7902|1980-12-17| 800.0| null| 20|
| 7499| ALLEN| SALESMAN|7698| 1981-2-20|1600.0| 300.0| 30|
| 7521| WARD| SALESMAN|7698| 1981-2-22|1250.0| 500.0| 30|
| 7566| JONES| MANAGER|7839| 1981-4-2|2975.0| null| 20|
| 7654|MARTIN| SALESMAN|7698| 1981-9-28|1250.0|1400.0| 30|
| 7698| BLAKE| MANAGER|7839| 1981-5-1|2850.0| null| 30|
| 7782| CLARK| MANAGER|7839| 1981-6-9|2450.0| null| 10|
| 7788| SCOTT| ANALYST|7566| 1987-4-19|3000.0| null| 20|
| 7839| KING|PRESIDENT|null|1981-11-17|5000.0| null| 10|
| 7844|TURNER| SALESMAN|7698| 1981-9-8|1500.0| 0.0| 30|
| 7876| ADAMS| CLERK|7788| 1987-5-23|1100.0| null| 20|
| 7900| JAMES| CLERK|7698| 1981-12-3| 950.0| null| 30|
| 7902| FORD| ANALYST|7566| 1981-12-3|3000.0| null| 20|
| 7934|MILLER| CLERK|7782| 1982-1-23|1300.0| null| 10|
+-----+------+---------+----+----------+------+------+------+
scala> spark.sql("select e.ename, e.sal, d.dname from db_hive.emp e 以上是关于Note_Spark_Day08:Spark SQL(Dataset是什么外部数据源UDF定义和分布式SQL引擎)的主要内容,如果未能解决你的问题,请参考以下文章