nuxt.js做站点地图(sitemap.xml)详解
Posted 郝峰Vip
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了nuxt.js做站点地图(sitemap.xml)详解相关的知识,希望对你有一定的参考价值。
前言
在做跨境电商项目中seo是必须要做的,seo中站点地图(sitemap.xml,robots.txt)又是必不可少的,这里就记录一下nuxt中站点地图是如何做的。
第一步:在根目录static目录下新建sitemap.js
sitemap.xml文件的内容
import axios from "axios";
const sitemap = {
path: '/sitemap.xml', //生成的文件路径
hostname: '自己的网站地址', //网站的网址
cacheTime: 1000 * 60 * 60 * 24, //一天的更新频率,只在generate:false有用
gzip: true, //生成.xml.gz的sitemap
generate: false,
exclude: ['/404', '/cart/api', '/confirmOrder/common/**', '/item/components/**','/category/minxinss','/category/components/**'], //排除不要的页面,这里的路径是相对于hostname
defaults: {
changefred: 'always',
lastmod: new Date()
},
routes: async () => {
let productList = await axios.post('商品列表接口地址', {
categoryId: "",
level: 0,
pageNum: 1,
pageSize: 20,
sort: "DEFAULT"
}
).then(res => {
let proList = res.data.data.list;
var siteArray = [];
let siteObject = {};
proList.forEach(element => {
siteObject = {
url: `/item/${element.id}.html`,
changefred: 'daily',
lastmod: new Date()
}
siteArray.push(siteObject);
});
return siteArray;
})
return productList ;
},
// 需要生成的xml数据,return 返回需要给出的xml数据
// routes:()=>{
// const routes = [{
// url:"/",
// changefred:'always',
// lastmod:new Date()
// }]
// return routes
// }
}
export default sitemap;
第二步:在根目录static目录下新建robots.txt
robots.txt文件可以指定爬虫只抓取指定的内容或者是禁止搜索部分内容。
# 该文件可以通过`你的网站域名/Robots.txt`直接访问
# User-agent作用:描述搜索引擎的名字,对于该文件来说至少药有一条user-agent记录,则该项的值设为*
User-agent: *
# Disallow: 描述不希望被访问到的一个url
Disallow: /bin/
Sitemap: 自己网站的域名/sitemap.xml
第三步:查看效果
- 1,在浏览器中打开
自己网站的域名/sitemap.xml看是否能直接打开,打开后文件如下所示
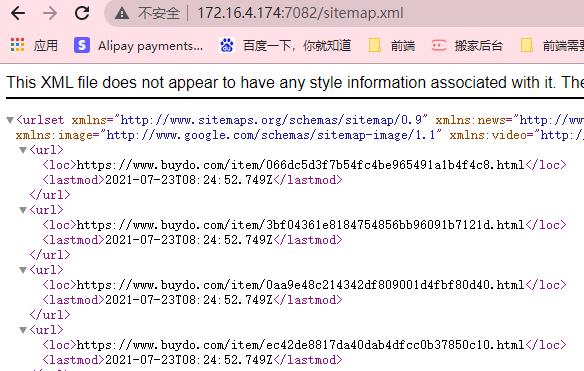
- 2,在浏览器中打开
自己网站的域名/Robots.txt看是否能直接打开,打开后文件如下所示
User-agent: *
Disallow: /404
Sitemap: 自己的域名/sitemap.xml
这两个文件都可以访问成功就说明你的站点地图做好了
以上是关于nuxt.js做站点地图(sitemap.xml)详解的主要内容,如果未能解决你的问题,请参考以下文章