备战秋招冲击大厂Java面试题系列—数据结构与算法
Posted Java-桃子
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了备战秋招冲击大厂Java面试题系列—数据结构与算法相关的知识,希望对你有一定的参考价值。
1. 数据结构定义
数据结构是计算机存储、组织数据的方式。数据结构是指相互之间存在一种或多种特定关系的数据元素的集合。通常情况下,精心选择的数据结构可以带来更高的运行或者存储效率。数据结构往往同高效的检索算法和索引技术有关。
- 数组:物理存储单元上连续、顺序的存储结构
- 链表:链表是一种物理存储单元上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的。
- 队列:队列(queue)是只允许在一端进行插入操作,而在另一端进行删除操作的线性表。
- 栈:栈(stack)又名堆栈,它是一种运算受限的线性表。限定仅在表尾进行插入和删除操作的线性表。这一端被称为栈顶,相对地,把另一端称为栈底。
- 堆:堆通常是一个可以被看做一棵完全二叉树的数组对象。将根结点最大的堆叫做最大堆或大根堆,根结点最小的堆叫做最小堆或小根堆。建堆时间复杂度O(n),堆总是满足下列性质:堆总是一棵完全二叉树;堆中某个结点的值总是不大于或不小于其父结点的值;
- 散列表:(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构
2. 堆的创建、插入、删除、堆排序
- 堆的插入:在已经建成的最小堆的后面插入元素,堆的结构可能被破坏,再向上调整使其满足性质。
- 堆的删除:删除时每次删除堆顶元素,删除方法:
1)将堆中最后一个元素代替堆顶元素。
2)将堆中元素个数减少一个,相当于将堆中最后一个元素删除。
3)此时堆的结构可能被破坏,在向下调整使其满足性质。 - 堆排序:
1)将堆顶元素与第size-1个元素交换。
2)hp->size–
3)将其余的元素调整为最小堆
4)重复1、2、3步hp->size-1次。
更多Java学习资料、面试真题获得,请【点击此处】
3. 跳表
跳表,是基于链表实现的一种类似“二分”的算法。它可以快速的实现增,删,改,查操作。这种链表加多级索引的结构,就叫做跳表。跳表的查询时间复杂度可以达到O(logn)。跳表也可以实现高效的动态更新,定位到要插入或者删除数据的位置需要的时间复杂度为O(logn).
在插入的时候,我们需要考虑将要插入的数据也插入到索引中去。在这里使用的策略是通过随机函数生成一个随机数K,然后将要插入的数据同时插入到k级以下的每级索引中。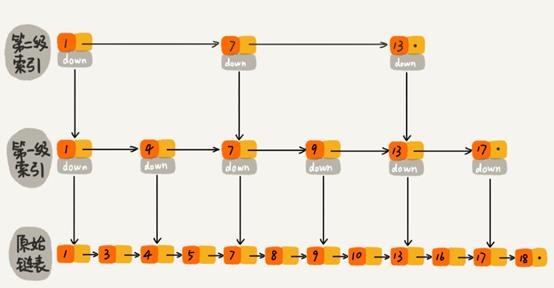
4. 排序算法
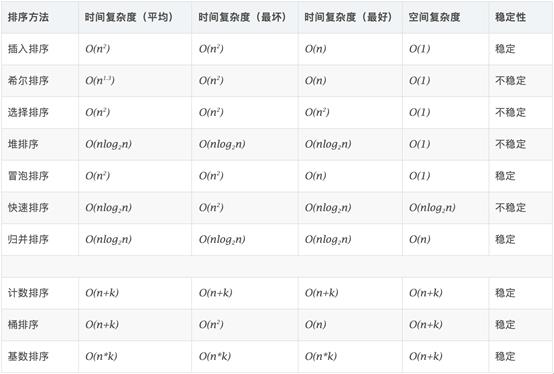
- 不同条件下,排序方法的选择
- 若n较小(如n≤50),可采用直接插入或直接选择排序。当记录规模较小时,直接插入排序较好;否则因为直接选择移动的记录数少于直接插人,应选直接选择排序为宜。
- 若文件初始状态基本有序(指正序),则应选用直接插入、冒泡或随机的快速排序为宜;
- 若n较大,则应采用时间复杂度为O(nlgn)的排序方法:快速排序、堆排序或归并排序。
a) 快速排序是目前基于比较的内部排序中被认为是最好的方法,当待排序的关键字是随机分布时,快速排序的平均时间最短;
b) 堆排序所需的辅助空间少于快速排序,并且不会出现快速排序可能出现的最坏情况。这两种排序都是不稳定的。
c) 若要求排序稳定,则可选用归并排序。 - TopK或优先队列通常用堆排序来实现
5. Bitmap位图算法
位图是指内存中连续的二进制位,用于对大量的整型数据做去重和查询。Bit-map就是用一个bit位来标记某个元素对应的Value,而Key即是该元素。由于采用了Bit为单位来存储数据,因此在存储空间方面,可以大大节省。
- bitmap应用
1)可进行数据的快速查找,判重,删除,一般来说数据范围是int的10倍以下。
2)去重数据而达到压缩数据
位图只是可以映射数字类型的数据,变成字符串以及其他文件好像就不再那么得心应手了,这时就要使用布隆过滤器
6. 布隆过滤器
bloom算法类似一个位图,用来判断某个元素(key)是否在某个集合中。和一般的位图不同的是,这个算法无需存储key的值,对于每个key,只需要k个比特位,每个存储一个标志,用来判断key是否在集合中。
- 应用场景:比如网络爬虫抓取时url去重,邮件提供商反垃圾黑名单Email地址去重,之所以需要k个比特位是因为我们大多数情况下处理的是字符串,那么不同的字符串就有可能映射到同一个位置,产生冲突。
- 优点:不需要存储key,节省空间
- 缺点:算法判断key在集合中时,有一定的概率key其实不在集合中,已经映射的数据无法删除
7. (Tire)字典树
- 定义:又称单词查找树,Trie树,是一种树形结构,是一种哈希树的变种。典型应用是用于统计,排序和保存大量的字符串(但不仅限于字符串),所以经常被搜索引擎系统用于文本词频统计。它的优点是:利用字符串的公共前缀来减少查询时间,最大限度地减少无谓的字符串比较,查询效率比哈希树高。
- 3个基本性质:
- 根节点不包含字符,除根节点外每一个节点都只包含一个字符;
- 从根节点到某一节点路径上经过的字符连接起来,为该节点对应的字符串;
- 每个节点的所有子节点包含的字符都不相同。
8. 海量数据找出前K大的数
top K类问题,通常比较好的方案是分治+Trie树/hash+小顶堆(就是上面提到的最小堆),即先将数据集按照Hash方法分解成多个小数据集,然后使用Trie树活着Hash统计每个小数据集中的query词频,之后用小顶堆求出每个数据集中出现频率最高的前K个数,最后在所有top K中求出最终的top K。
9. 五大查找方式

10. BFS、DFS优缺点
- 深搜优缺点
- 优点
- 能找出所有解决方案
- 优先搜索一棵子树,然后是另一棵,所以和广搜对比,有着内存需要相对较少的优点
- 缺点
- 要多次遍历,搜索所有可能路径,标识做了之后还要取消。
- 在深度很大的情况下效率不高
- 优点
- 广搜优缺点
- 优点
- 对于解决最短或最少问题特别有效,而且寻找深度小
- 每个结点只访问一遍,结点总是以最短路径被访问,所以第二次路径确定不会比第一次短
- 缺点
- 内存耗费量大(需要开大量的数组单元用来存储状态)
- 优点
更多Java学习资料、面试真题获得,请【点击此处】
11. 动态规划
- 核心思想:将大问题分为小问题进行解决,从而一步步获得最优解的处理算法,与分治算法不同的是适合于动态规划求解的问题,经分解得到的子问题往往不是相互独立的。
- 求解方式:填表
- 思想:w[i]为第i个商品的重量,v[i]代表第i个商品的价值,v[i][j]表示在前i个物品中能够装入容量为j的背包中的最大价值
a) v[i][0]=v[0][j]=0;//使得i和j刚好和第几个商品对应
b) 当w[i]>j时:v[i][j]=v[i-1][j];//当准备加入新增的商品的容量w[i]大于当前背包的容量j时就直接使用上一单元格的装入策略
c) 当w[i]<=j时:v[i][j]=max{v[i-1][j], v[i]+v[i-1][j-w[i]]};
//上一个单元格的装入的最大值v[i-1][j]
//v[i]当前商品的价值
//v[i-1][j-w[i]]装入i-1个商品剩余空间j-w[i]的最大值
1. //根据前面得到公式来动态规划处理
2. for(int i = 1; i < v.length; i++) {//不处理第一行i是从1开始的
3. for(int j=1; j < v[0].length; j++){//不处理第一列,j是从1开始的
4. //公式
5. if(w[i-1]> j){//因为我们程序i是从1开始的,因此原来公式中的w[i]修改成w[i-1]
6. v[][j]=v[i-1][j];
7. }else{
8. //说明:
9. //因为我们的i从1开始的,因此公式需要调整成
10. //v[i][j]=Math.max(v[i-1][j],val[i-1]+v[i-1][j-w[i-1]]);
11. v[][j]=Math.max(v[i-1][j], val[i]+v[i-1][j-w[i-1]]);
12. }
13. }
14. }
12. 什么样的题适合用动态规划?
- 最值型动态规划,比如求最大,最小值是多少
- 计数型动态规划,比如换硬币,有多少种换法
- 坐标型动态规划,比如在m*n矩阵求最值型,计数型,一般是二维矩阵
-
区间型动态规划,比如在区间中求最值
13. 暴力匹配算法
1. public static int ViolenceMatch(String str1, String str2) {
2. char[] s1 = str1.toCharArray();
3. char[] s2 = str2.toCharArray();
4.
5. int i = 0;
6. int j = 0;
7.
8. while (i < s1.length && j < s2.length) {
9. if (s1[i] == s2[j]) {
10. i++;
11. j++;
12. } else {
13. i = i - (j - 1);
14. j = 0;
15. }
16. }
17.
18. if (j == s2.length) {
19. return i - j;
20. }
21.
22. return -1;
23. }
14. KMP算法
建立部分匹配表

移动位数 = 已匹配的字符数 – 对应的部分匹配值
1. public static int[] KmpMatchTable(String str) {
2. int[] matchTable = new int[str.length()];
3. matchTable[0] = 0;
4. for (int i = 1, j = 0; i < str.length(); i++) {
5. //不等时重新获取前一个的值,kmp算法核心
6. while (j > 0 && str.charAt(i) != str.charAt(j)) {
7. j = matchTable[j - 1];
8. }
9. //部分匹配则值+1
10. if (str.charAt(i) == str.charAt(j)) {
11. j++;
12. }
13. matchTable[i] = j;
14. }
15. return matchTable;
16. }
KMP搜索
1. public static int KMPMatch(String str1, String str2) {
2. int[] matchTable=KmpMatchTable(str2);
3.
4. for (int i = 0,j=0; i < str1.length(); i++) {
5. //处理不等情况
6. while(j>0&&str1.charAt(i)!=str2.charAt(j)){
7. j = matchTable[j-1];
8. }
9.
10. if (str1.charAt(i)==str2.charAt(j)){
11. j++;
12. }
13. if (j==str2.length()){
14. return i-j+1;
15. }
16. }
17.
18. return -1;
19. }
15. 贪心算法
16. 普利姆算法(prim)
- 求最小生成树
- 普里姆算法介绍
- 普利姆(Prim)算法求最小生成树,也就是在包含n个顶点的连通图中,找出只有(n-1)条边包含所有n个顶点的连通子图,也就是所谓的极小连通子图
-
普利姆的算法如下:
(1) 设G=(V,E)是连通网,T=(U,D)是最小生成树,V,U是顶点集合,E,D是边的集合
(2) 若从顶点u开始构造最小生成树,则从集合V中取出顶点u放入集合U中,标记顶点v的visited[u]=1
(3) 若集合U中顶点ui与集合V-U中的顶点vj之间存在边,则寻找这些边中权值最小的边,但不能构成回路,将顶点vj加入集合U中,将边(ui,vj)加入集合D中,标记visited[vj]=1
(4) 重复步骤②,直到U与V相等,即所有顶点都被标记为访问过,此时D中有n-1条边
(5) 提示:单独看步骤很难理解,我们通过代码来讲解,比较好理解.
17. 二叉树的中序遍历
1. List<Integer> list = new ArrayList<>();
2. public TreeNode increasingBST(TreeNode root) {
3. if(null==root)return null;
4. Deque<TreeNode> queue = new ArrayDeque<>();
5. while(root!=null||!queue.isEmpty()){
6. while(root!=null){
7. queue.add(root);
8. root = root.left;
9. }
10. root = queue.pollLast();
11. list.add(root.val);
12. root=root.right;
13. }
14. return list;
15. }
18. 二叉树层序遍历
1. public List<List<Integer>> levelOrder(TreeNode root) {
2. List<List<Integer>> res = new ArrayList<>();
3. Queue<TreeNode> queue = new ArrayDeque<>();
4. if (root != null) {
5. queue.add(root);
6. }
7. while (!queue.isEmpty()) {
8. int n = queue.size();//记录节点个数
9. List<Integer> level = new ArrayList<>();
10. //遍历每个节点的左右子节点
11. for (int i = 0; i < n; i++) {
12. TreeNode node = queue.poll();
13. level.add(node.val);
14. if (node.left != null) {
15. queue.add(node.left);
16. }
17. if (node.right != null) {
18. queue.add(node.right);
19. }
20. }
21. res.add(level);
22. }
23.
24. return res;
25. }
19. 二叉树之字形打印
1. public List<List<Integer>> zigzagLevelOrder(TreeNode root) {
2. List<List<Integer>> res = new ArrayList<>();
3. if (root == null)
4. return res;
5. //创建队列,保存节点
6. Queue<TreeNode> queue = new LinkedList<>();
7. queue.add(root);//先把节点加入到队列中
8. boolean leftToRight = true;//第一步先从左边开始打印
9. while (!queue.isEmpty()) {
10. //统计这一层有多少个节点
11. int count = queue.size();
12. //记录每层节点的值
13. List<Integer> level = new ArrayList<>();
14. //遍历这一层的所有节点,把他们全部从队列中移出来,顺便
15. //把他们的值加入到集合level中,接着再把他们的子节点(如果有)
16. //加入到队列中
17. for (int i = 0; i < count; i++) {
18. //poll移除队列头部元素(队列在头部移除,尾部添加)
19. TreeNode node = queue.poll();
20. //判断是从左往右打印还是从右往左打印。
21. if (leftToRight) {
22. //如果从左边打印,直接把访问的节点值加入到列表level的末尾
23. level.add(node.val);
24. } else {
25. //如果是从右边开始打印,每次要把访问的节点值加入到列表的最前面
26. level.add(0, node.val);
27. }
28. //左右子节点如果不为空会被加入到队列中
29. if (node.left != null)
30. queue.add(node.left);
31. if (node.right != null)
32. queue.add(node.right);
33. }
34. //把这一层的节点值加入到集合res中
35. res.add(level);
36. //改变下次访问的方向
37. leftToRight = !leftToRight;
38. }
39. return res;
40. }
20. 判断A是否是B的子树
1. public class Solution {
2. //分为两个函数,一个用于遍历节点当做子树的根节点,
3. public boolean hasSubtree(TreeNode root1,TreeNode root2) {
4. if(root1==null||root2==null) return false;
5. //直接判断isSubTree(root1,root2),并且采取||的方式确定结果。
6. return isSubTree(root1,root2)||hasSubtree(root1.left,root2)
7. ||hasSubtree(root1.right,root2);
8. }
9. //另一个用于判断是否是子树(必须要root2先空)
10. public boolean isSubTree(TreeNode root1,TreeNode root2){
11. if(root2==null) return true;
12. if(root1==null) return false;
13. if(root1.val==root2.val){
14. return isSubTree(root1.left,root2.left)&&
15. isSubTree(root1.right,root2.right);
16. }else{
17. return false;
18. }
19. }
20. }
21. 最小硬币数
- 动态规划算法题:给定不同面额的硬币数组coins和总额amounts,求能够组成总额的最小硬币数。如coins=[1,2,5],amounts=11,那么最少硬币数为5+5+1=3.
1. public static int CoinsChange(int[] coins, int amount, int coinSize) {
2. if (null == coins || amount == 0) return -1;
3.
4. int[] temp = new int[amount + 1];
5. for (int i = 0; i <= amount; i++) {
6. temp[i] = amount + 1;
7. }
8. temp[0] = 0;
9. for (int i = 1; i <= amount; i++) {
10. for (int j = 0; j < coinSize; j++) {
11. if (i >= coins[j]) {
12. temp[i] = Math.min(temp[i], 1 + temp[i - coins[j]]);
13. }
14. }
15. }
16. return temp[amount] > amount ? -1 : temp[amount];
17. }更多Java学习资料、面试真题获得,请【点击此处】
以上是关于备战秋招冲击大厂Java面试题系列—数据结构与算法的主要内容,如果未能解决你的问题,请参考以下文章