图解pandas的数据合并merge
Posted 尤尔小屋的猫
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了图解pandas的数据合并merge相关的知识,希望对你有一定的参考价值。
公众号:尤而小屋
作者:Peter
编辑:Peter
大家好,我是Peter~
在实际的业务需求中,我们的数据可能存在于不同的库表中。很多情况下,我们需要进行多表的连接查询来实现数据的提取,通过SQL的join,比如left join、left join、inner join等来实现。
在pandas中也有实现合并功能的函数,比如:concat、append、join、merge。本文中重点介绍的是merge函数,也是pandas中最为重要的一个实现数据合并的函数。
看完了你会放弃SQL吗?

Pandas连载文章
目前Pandas系列文章已经更新了13篇,文章都是以案例+图解的风格,欢迎访问阅读。有很多个人推荐的文章:
参数
官网学习地址:https://pandas.pydata.org/pandas-docs/stable/user_guide/merging.html#
pd.merge(left, # 待合并的2个数据框
right,
how='inner', # ‘left’, ‘right’, ‘outer’, ‘inner’, ‘cross’
on=None, # 连接的键,默认是相同的键
left_on=None, # 指定不同的连接字段:键不同,但是键的取值有相同的内容
right_on=None,
left_index=False, # 根据索引来连接
right_index=False,
sort=False, # 是否排序
suffixes=('_x', '_y'), # 改变后缀
copy=True,
indicator=False, # 显示字段来源
validate=None)
参数的具体解释为:
-
left、right:待合并的数据帧
-
how:合并的方式,有5种:{‘left’, ‘right’, ‘outer’, ‘inner’, ‘cross’}, 默认是 ‘inner’
1、 left:左连接,保留left的全部数据;right类似;类比于SQL的left join 或者right join
2、outer:全连接功能,类似SQL的full outer join
3、inner:交叉连接,类比于SQL的inner join
4、cross:创建两个数据帧DataFrame的笛卡尔积,默认保留左边的顺序
-
on:连接的列属性;默认是两个DataFrame的相同字段
-
left_on/right_on:指定两个不同的键进行联结
-
left_index、right_index:通过索引进行合并
-
suffixes:指定我们自己想要的后缀
-
indictor:显示字段的来源
模拟数据
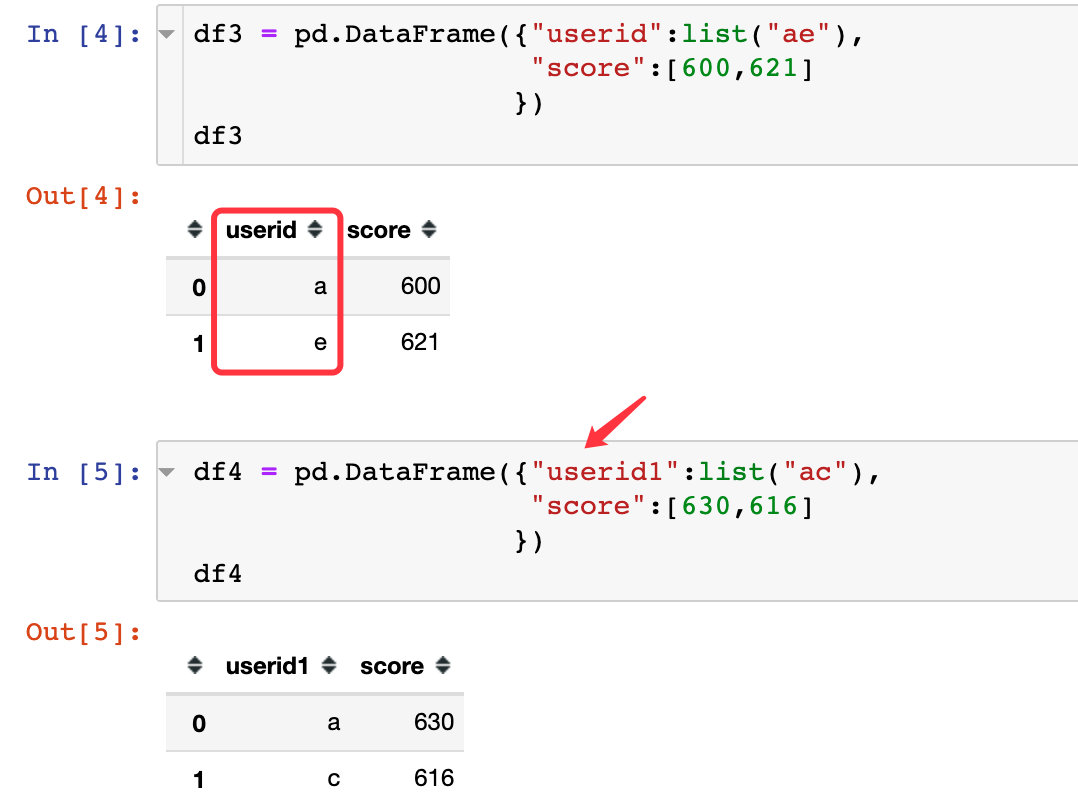
我们创建了4个DataFrame数据框;其中df1和df2、df3是具有相同的键userid;df4有类似的键userid1,取值也是ac,和df1或df2的userid取值有相同的部分。
import pandas as pd
import numpy as np

参数left、right
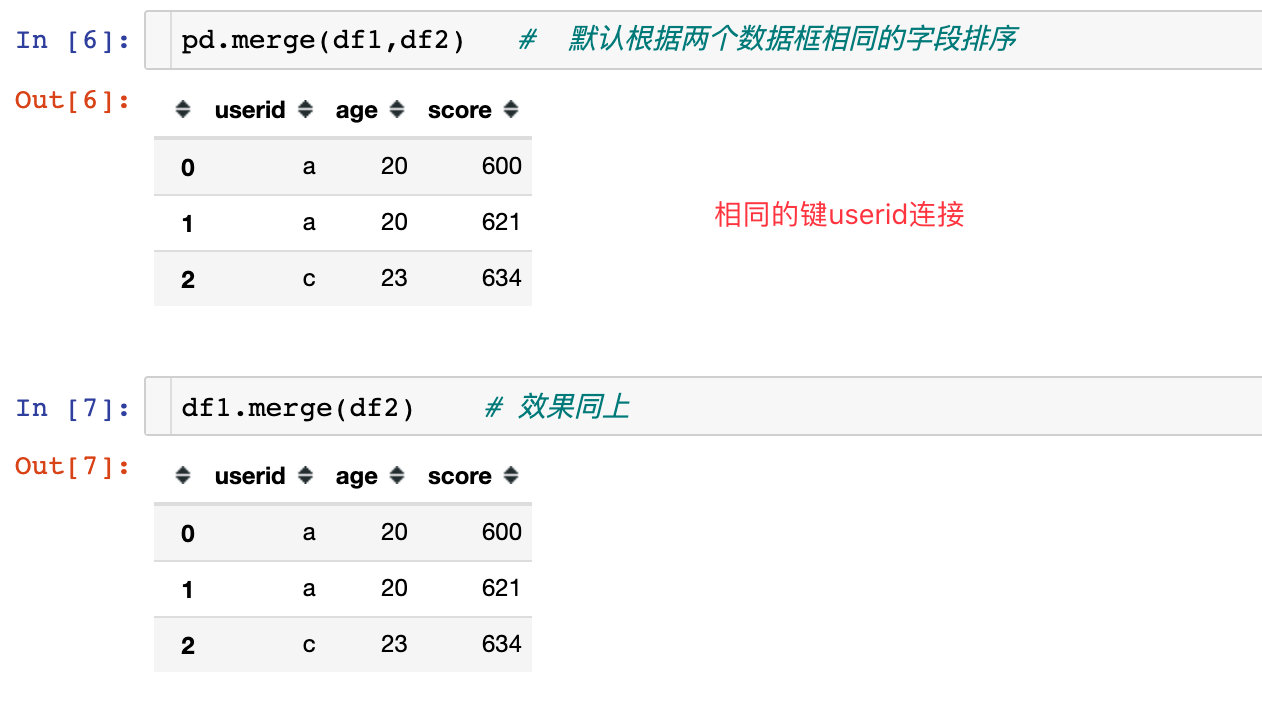
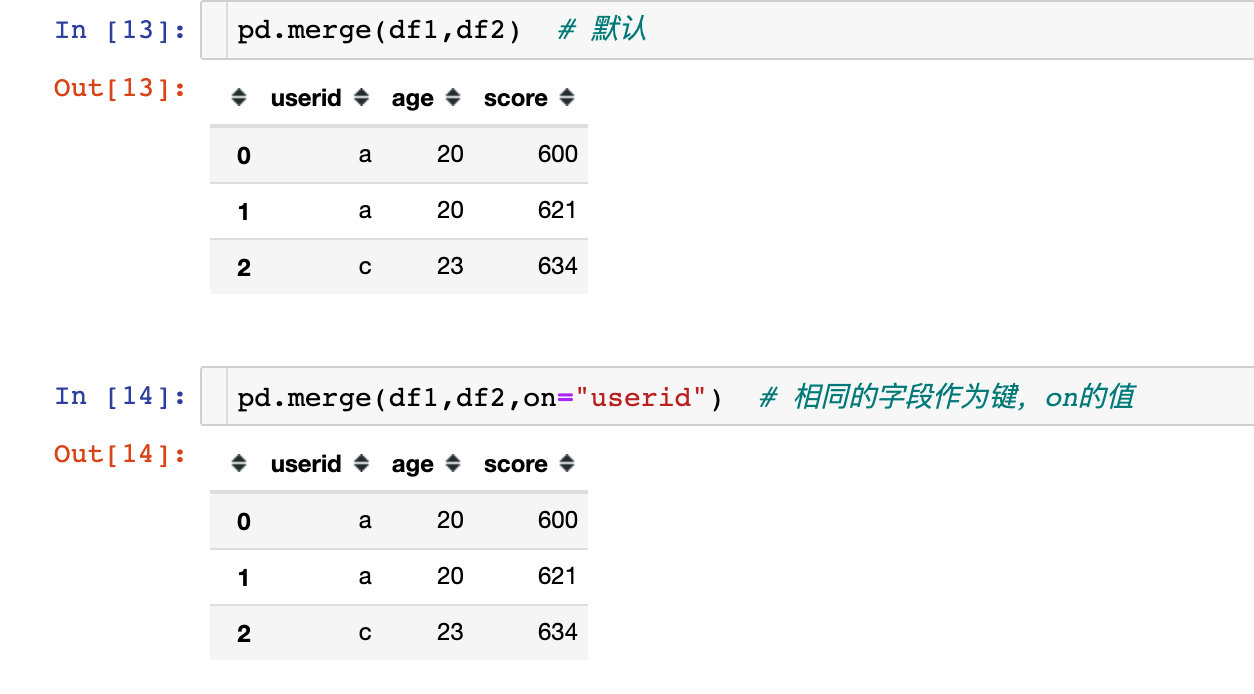
left、how就是需要连接的两个数据帧,一般有两种写法:
- pd.merge(left,right),个人习惯
- left.merge(right)
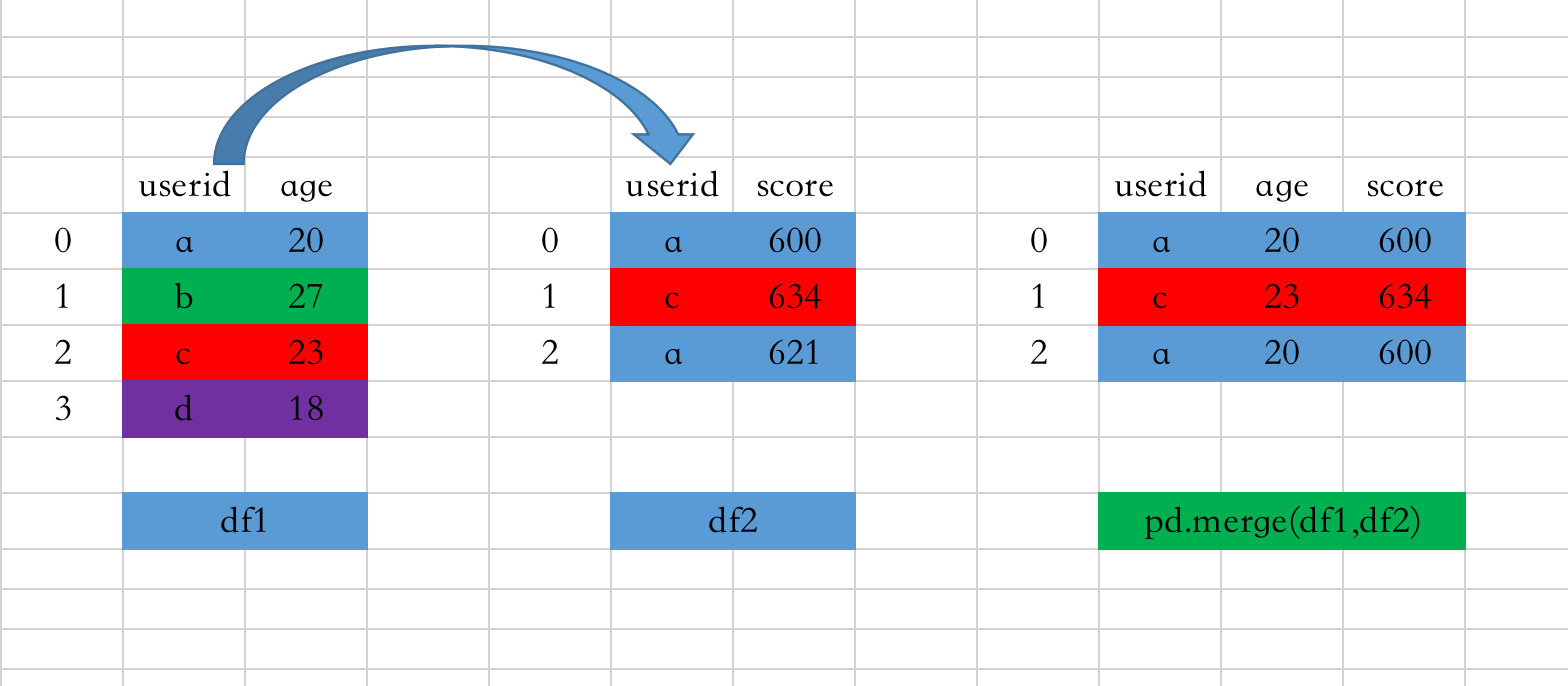
图解过程如下:
- 两个数据框df1(left)、df2(right)有相同的字段userid
- 默认是通过相同的字段(键)进行关联,取出键中相同的值(ac),而且每个键的记录要全部显示,比如a有多条记录
参数how
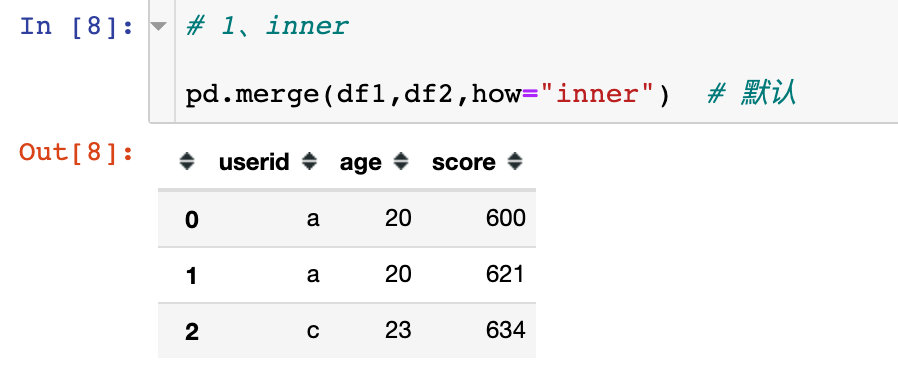
inner
inner称之为内连接。它会直接根据相同的列属性userid进行关联,取出属性下面相同的数据信息a、c
⚠️上面的图解过程就是默认的使用how=“inner”
outer
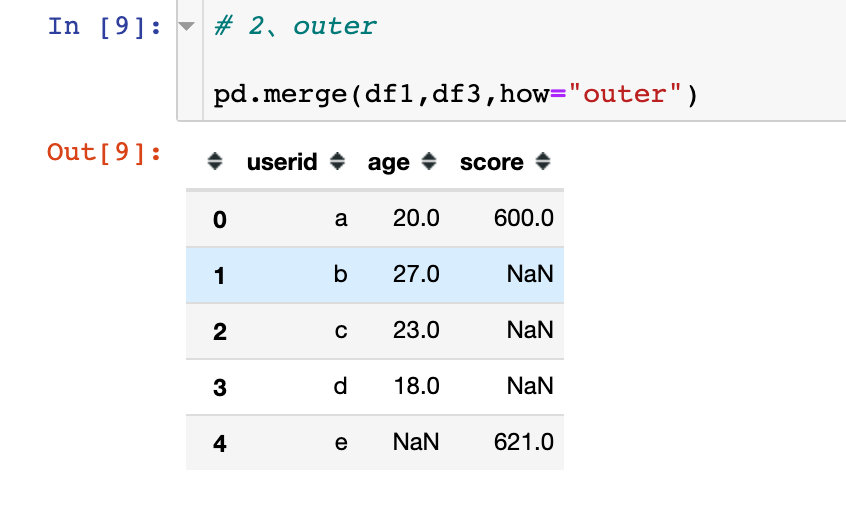
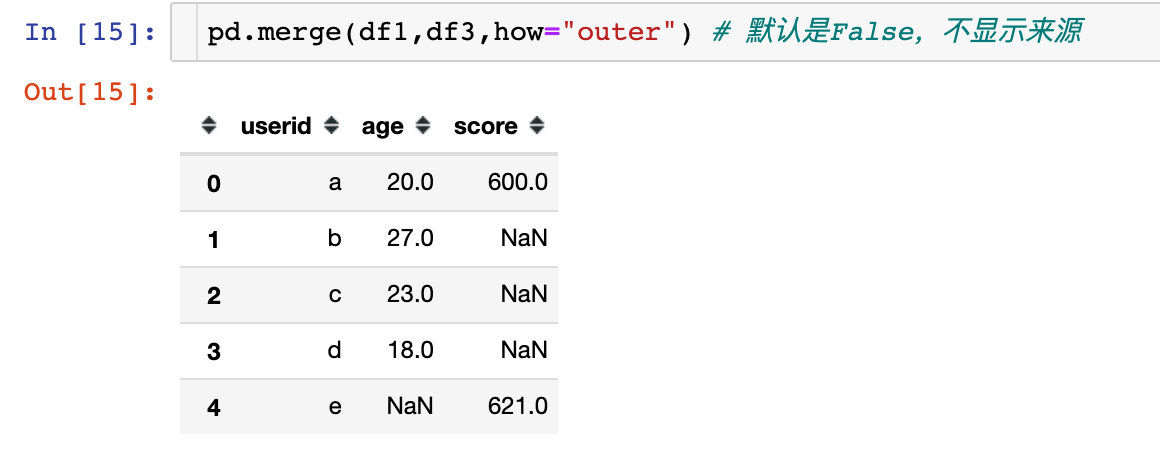
outer称之为外连接,在拼接的过程中会取两个数据框中键的并集进行拼接
- 外连接,取出全部交集键的并集。例子中是user的并集
- 如果某个键在某个数据框中不存在数据,则为NaN
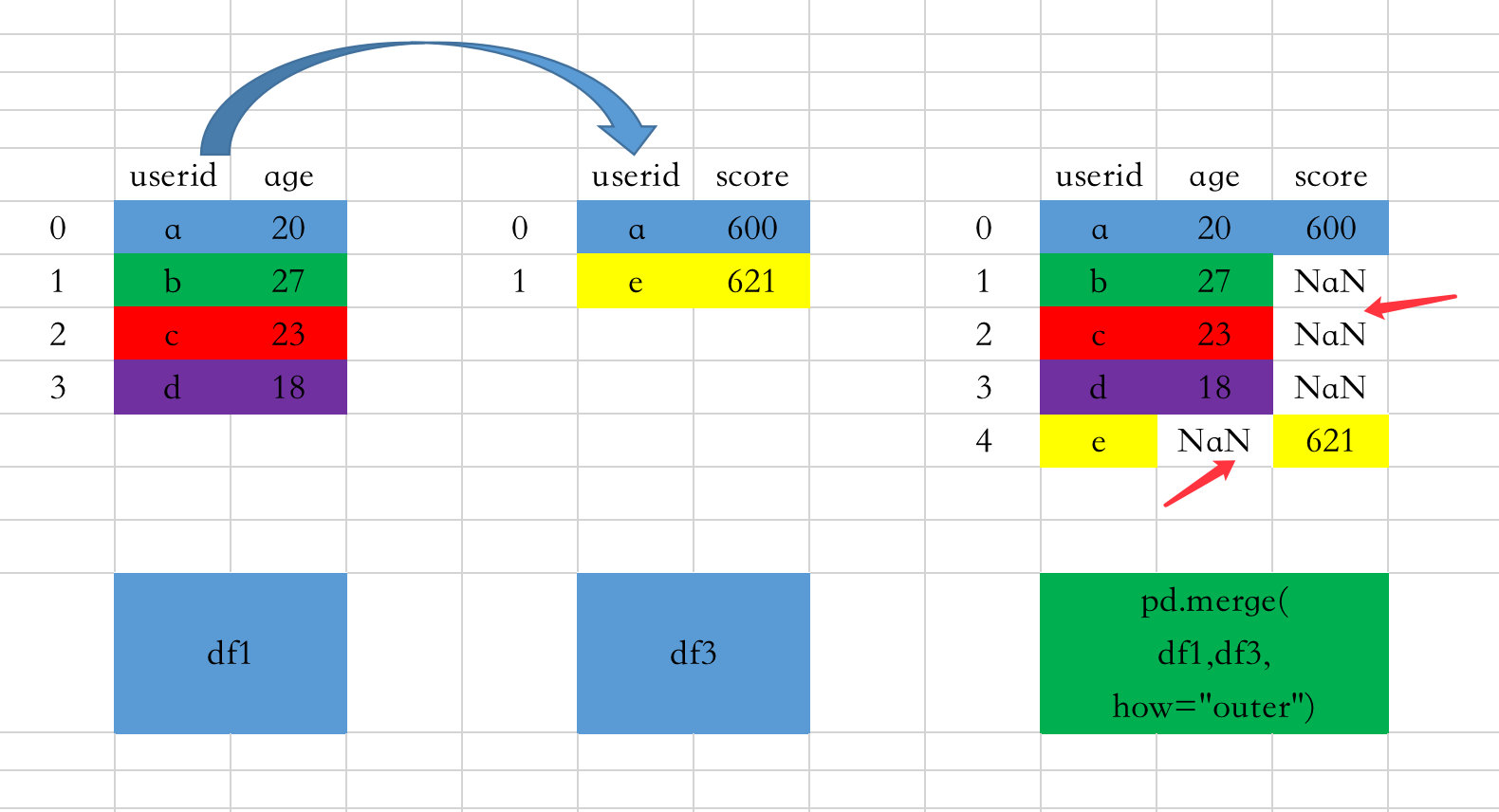
图解过程如下:
- 也是根据相同的字段来进行联结:userid
- 保留两边的全部数据,所以abcde全部存在
- 如果某边不存在键下面的某个值,则结果中用NaN补充。比如df1的userid中存在b,但是df3中不存在,则结果b对应的score为NaN,cd类似;e在df3中存在e的取值,但是df1中不存在,则age的值为NaN
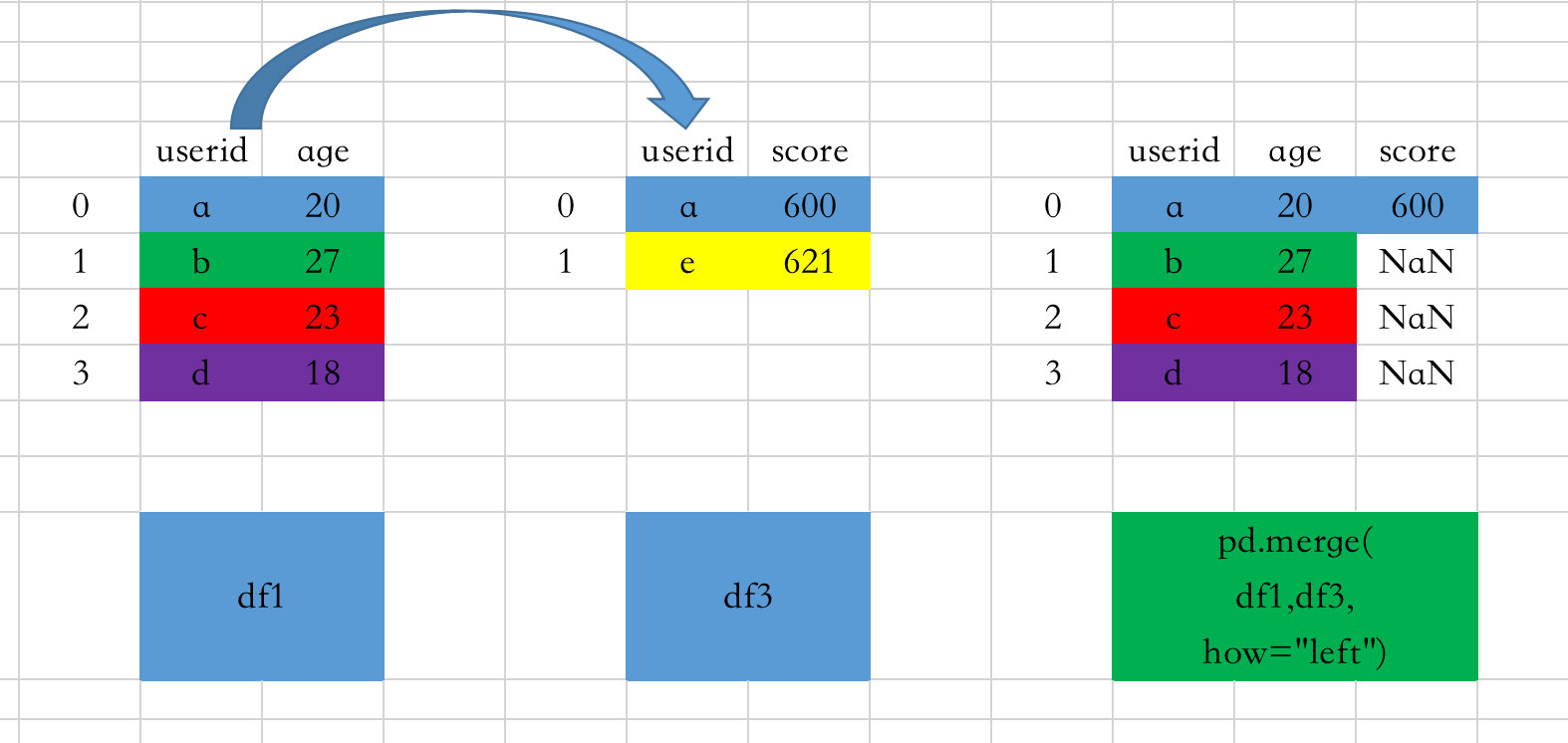
left
以左边数据框中的键为基准;如果左边存在但是右边不存在,则右边用NaN表示
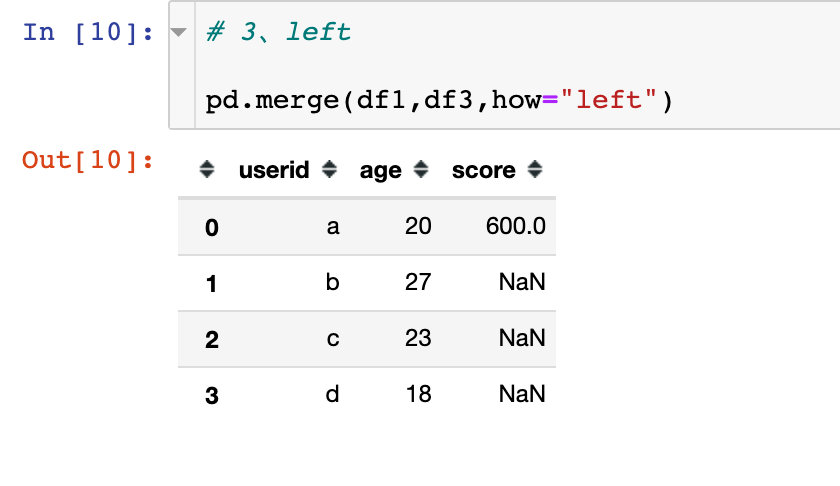
图解过程如下:
- 和上面图解过程的结果差别在于,没有出现e;
- 当how=“left”,只会保留df1(left)中userid下面的全部取值,不包含e
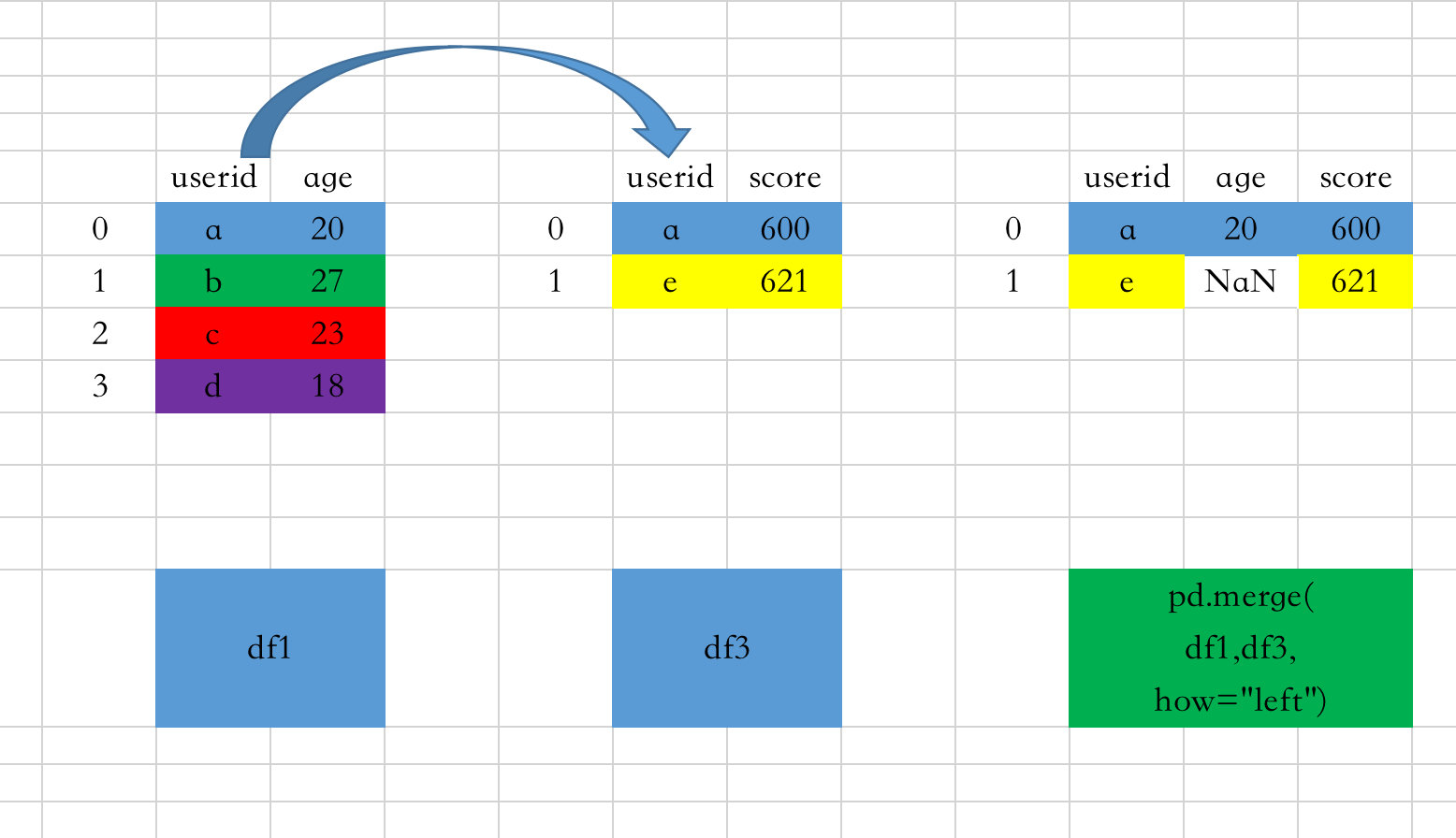
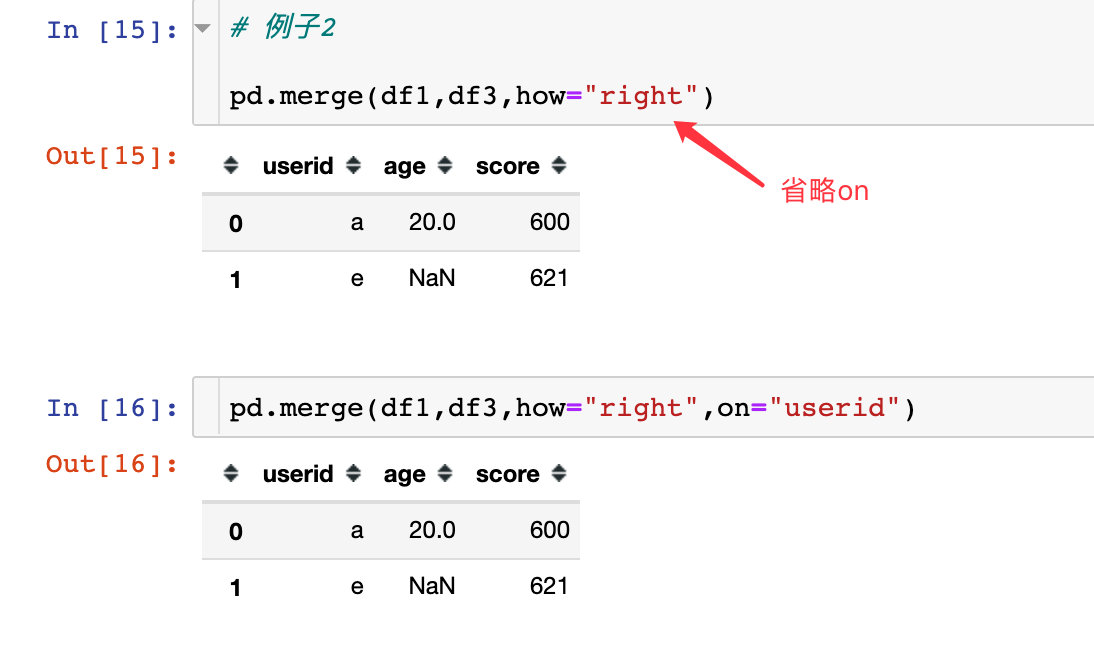
right
以右边数据框中的键的取值为基准;如果右边存在但是左边不存在,则左边用NaN表示
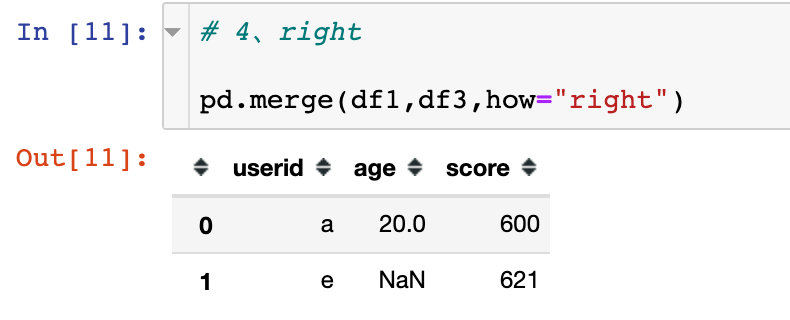
图解过程如下:
- 当how=“right”,只会保留df3(right)中userid的全部取值
- 结果只保留了df3的userid下面的全部取值:a、e
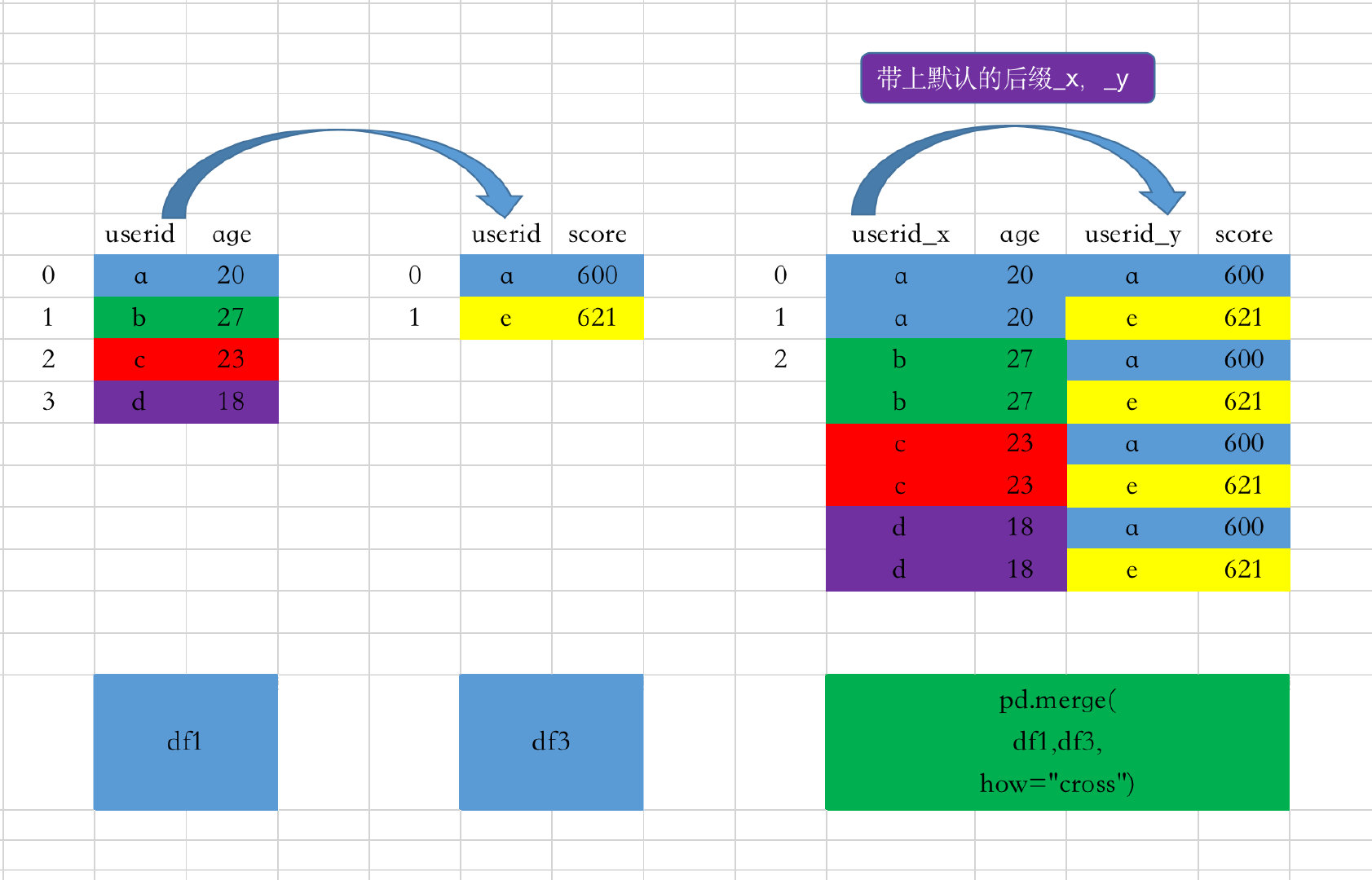
cross
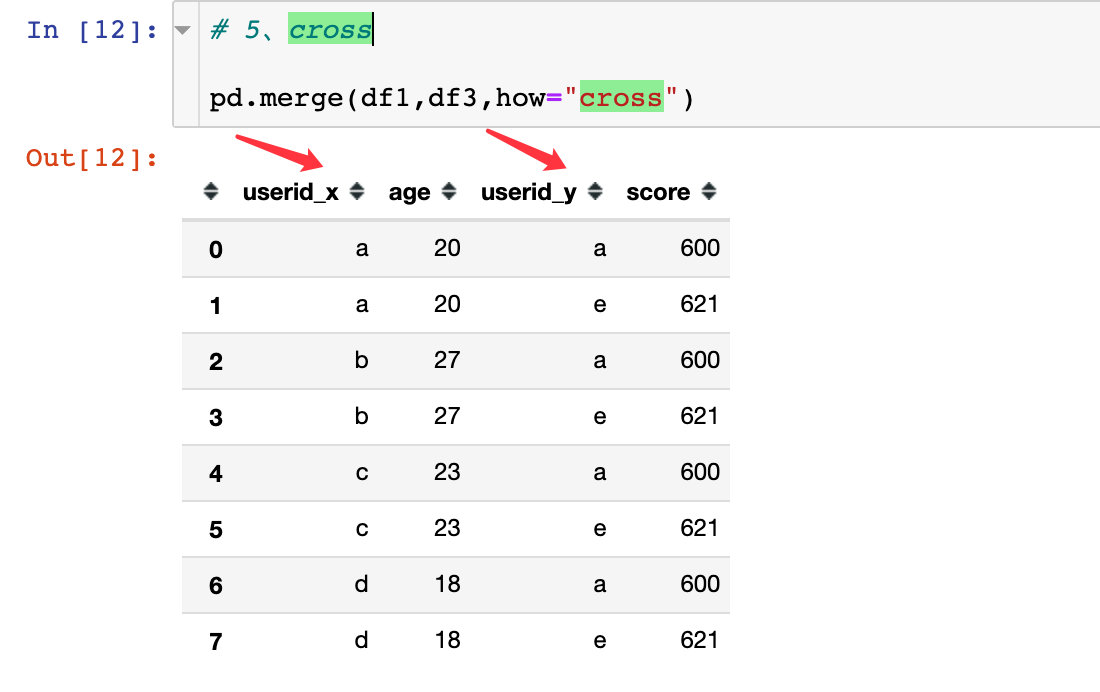
笛卡尔积:两个数据框中的数据交叉匹配,出现n1*n2的数据量
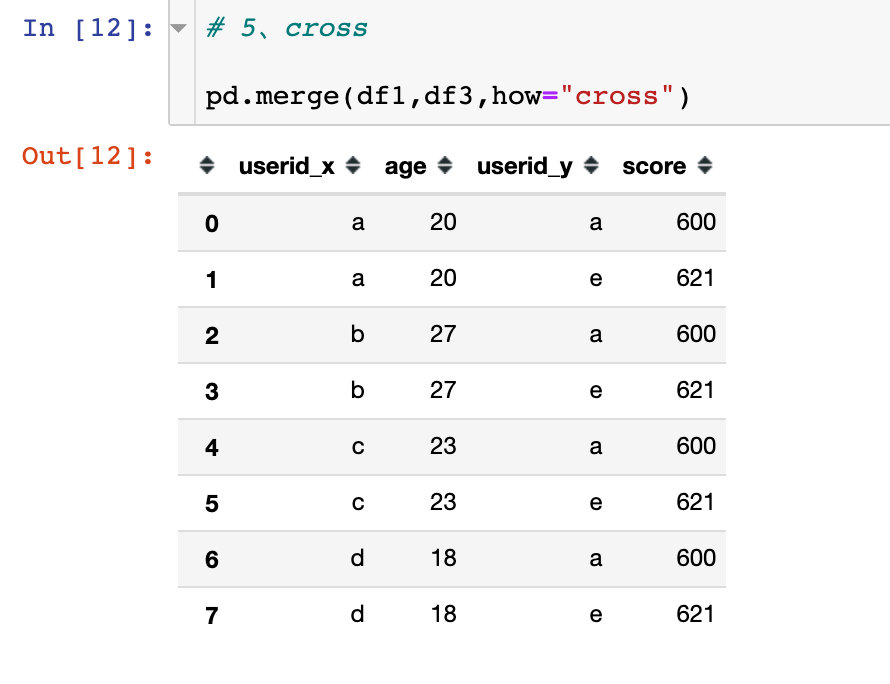
笛卡尔积的图解过程如下:
- 出现的数据量是4*2,userid下面的数据交叉匹配
- 在最终结果中相同的字段userid为了避免混淆,会带上默认的后缀
_x、_y
参数on
如果待连接的两个数据框有相同的键,则默认使用该相同的键进行联结。
上面的所有图解例子的参数on默认都是使用相同的键进行联结,所以有时候可省略。
再看个例子:
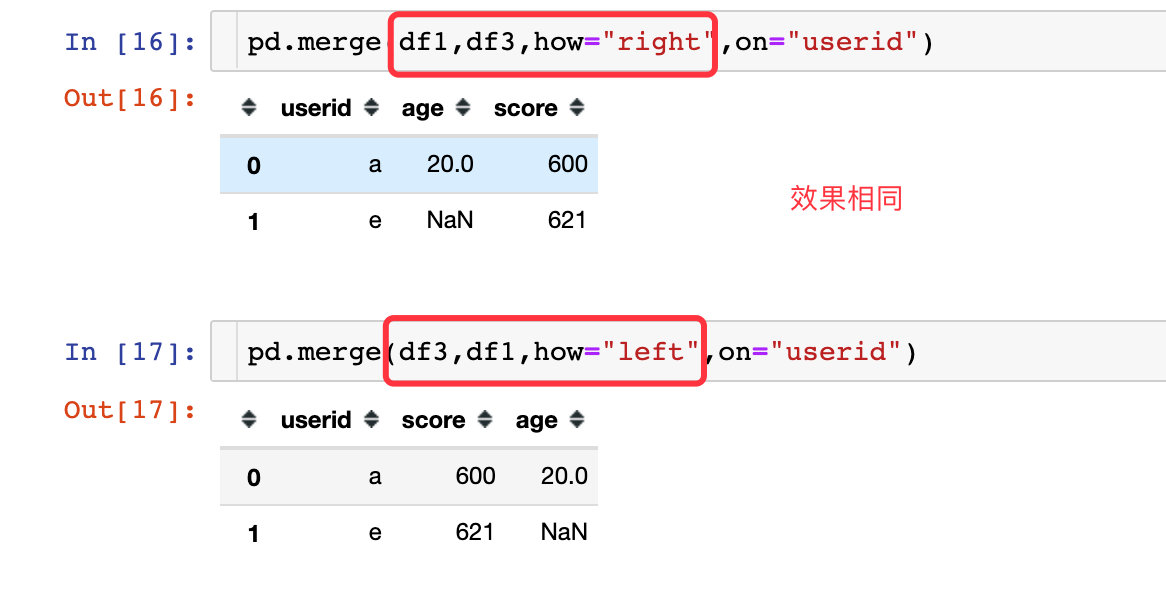
还可以将left和right的位置进行互换:
上面的两个例子都是针对数据框只有具有相同的一个键,如果不止通过一个键进行联结,该如何处理?通过一个来自官网的例子来解释,我们先创建两个DataFrame:df5、df6
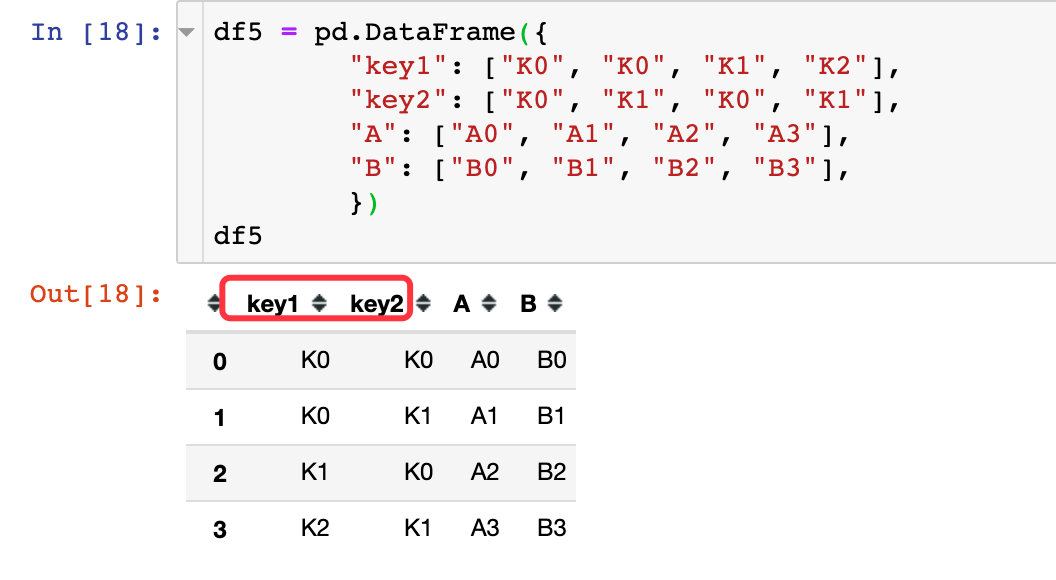
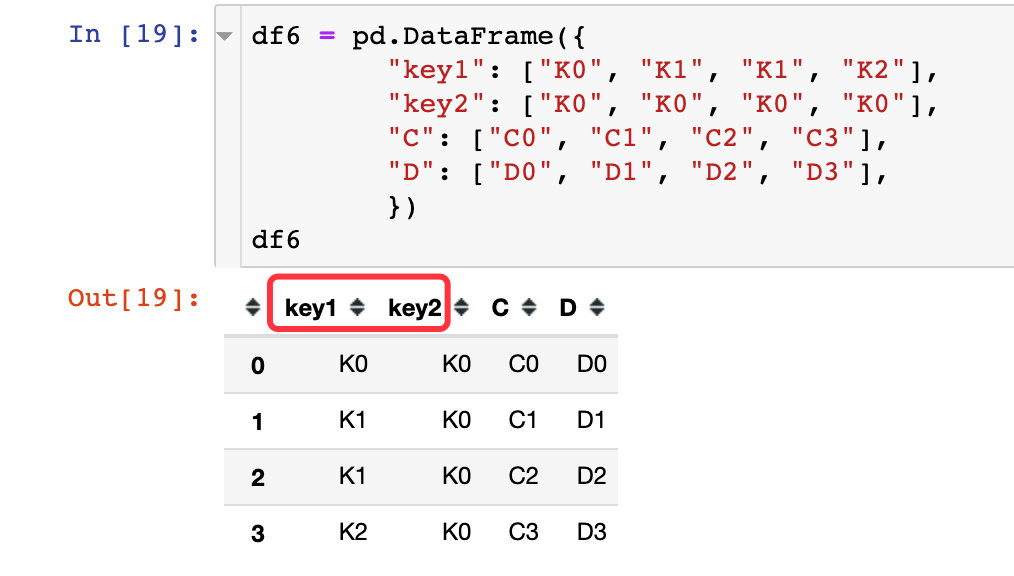
现在进行两个数据框的合并:

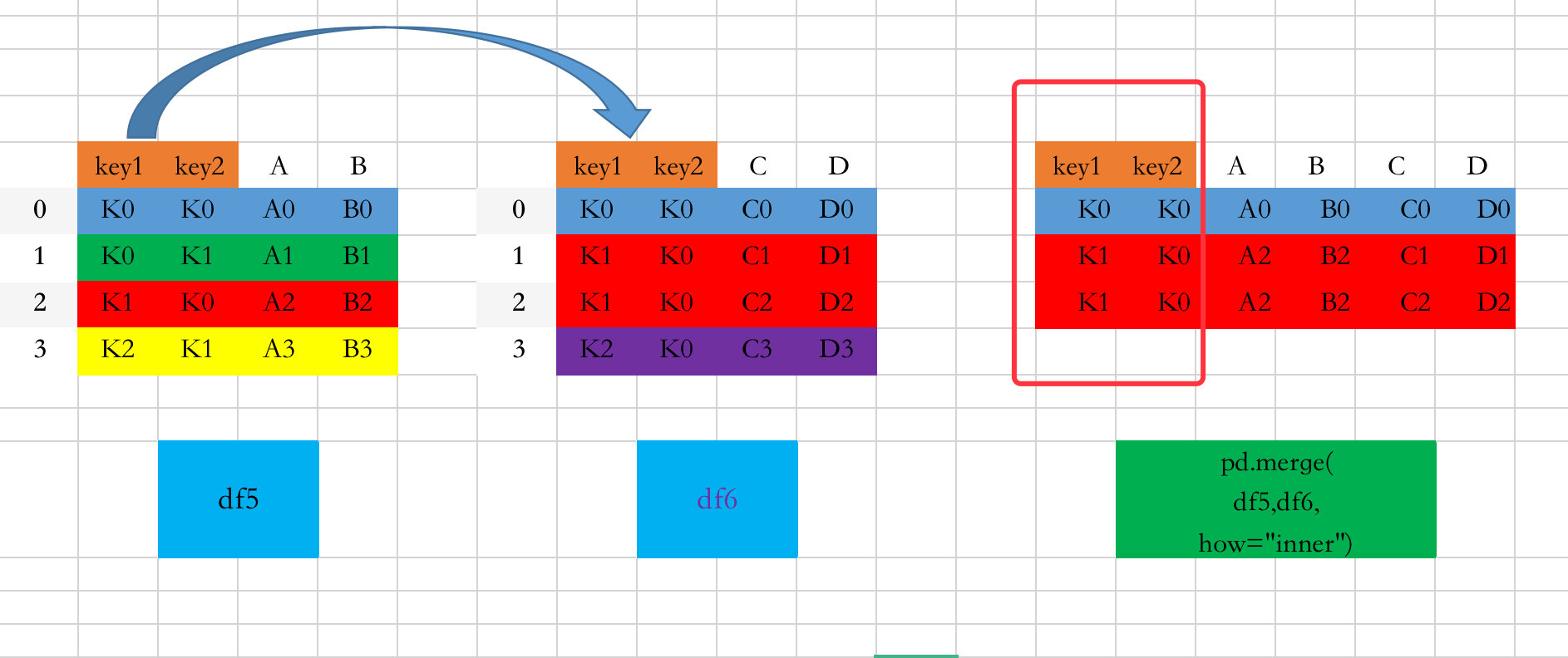
合并的图解过程如下:
- 通过on参数指定两个连接的字段key1、key2
- 只有当两个数据框中的key1和key2的取值完全相同的时候(交集),才会保留下来;比如都出现了key1=K0,key2=K0和key1=K1,key2=K0。
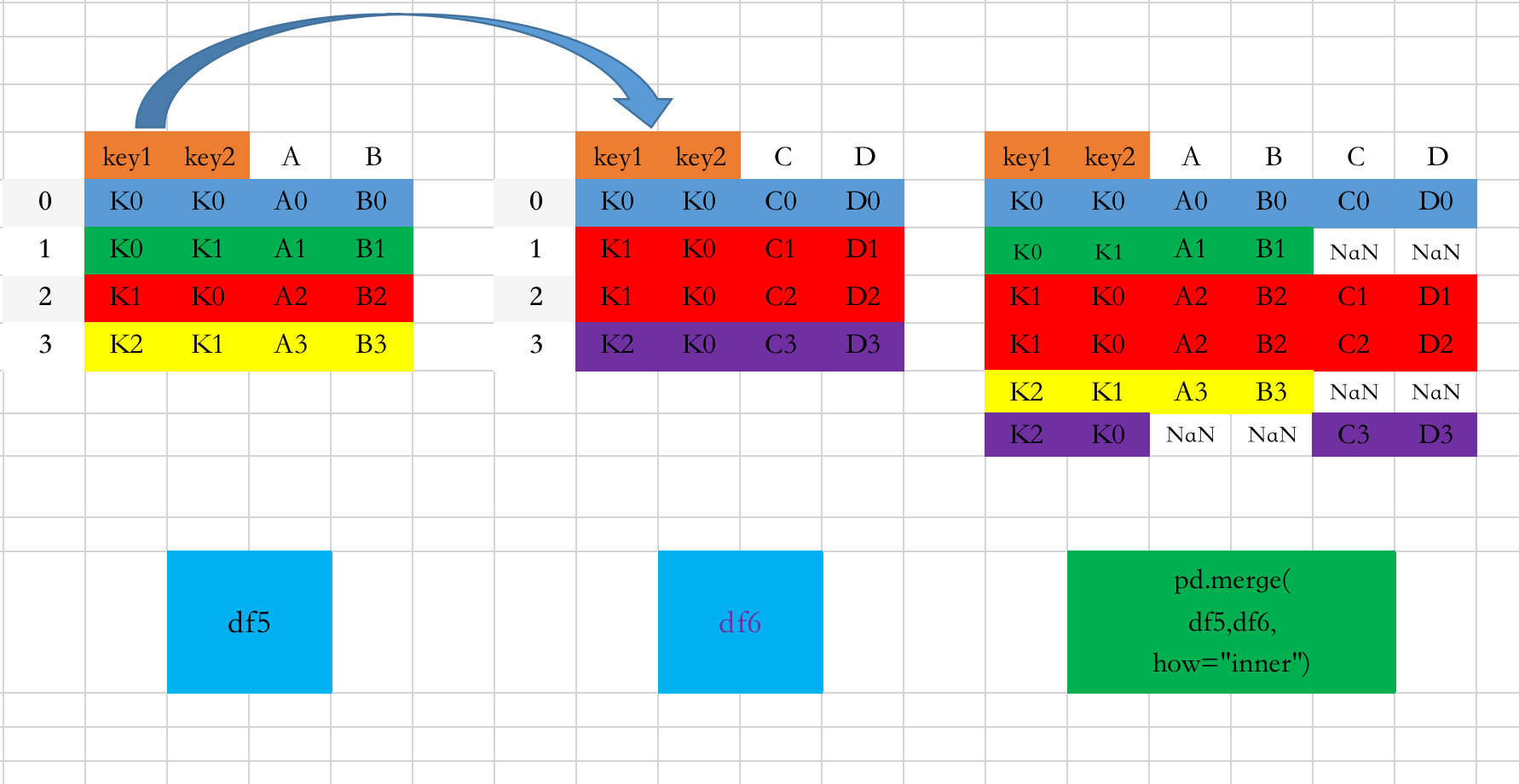
在看一个通过how="outer"进行连接的案例:

看看图解的过程:
- 指定连接的两个键key1、key2
- 使用how=“outer”,会保留两个数据框中的全部数据。某个数据框中不存在键的值,则取NaN
参数left_on、right_on
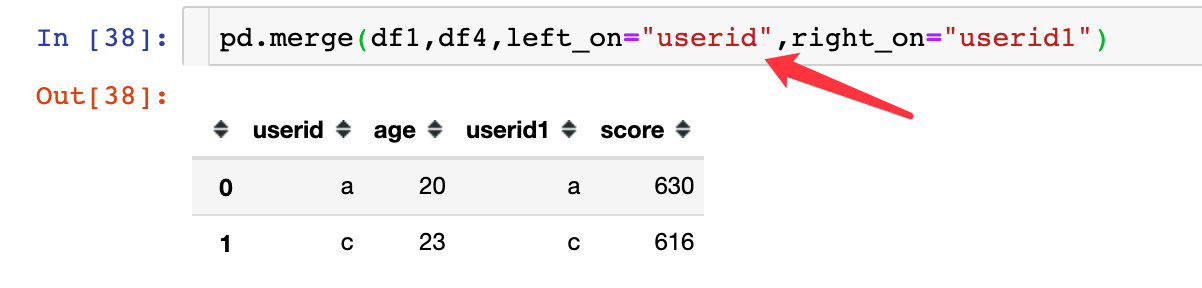
上面在连接合并的时候,两个数据框之前都是有相同的字段,比如userid或者key1和key2。但是如何两个数据框中没有相同的键,但是这些键中的取值有相同的部分,比如我们的df1、df3:

在这个时候我们就使用left_on和right_on参数,分别指定两边的连接的键:
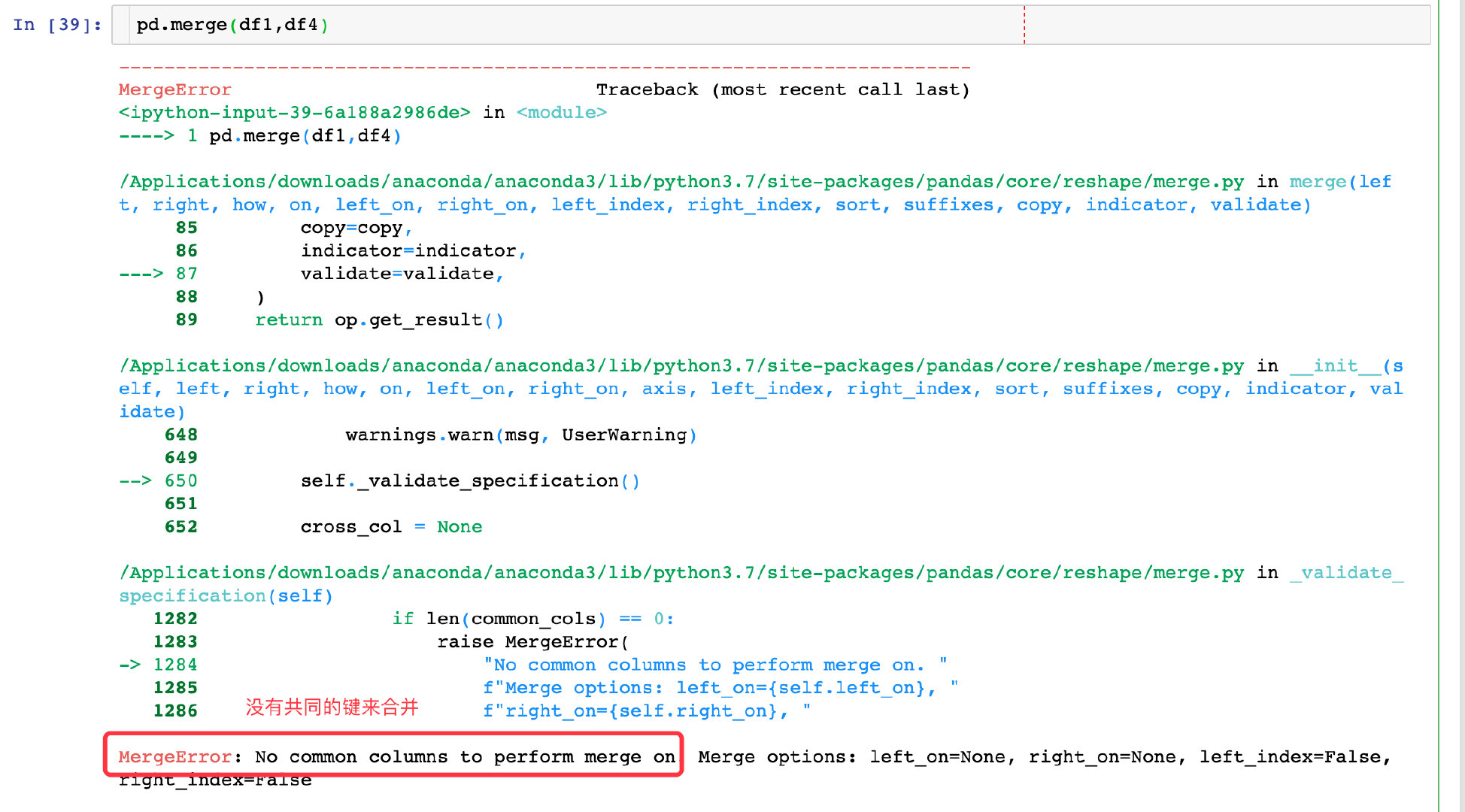
如果我们不指定,系统就会报错,因为这两个数据框是没有相同的键,本身是无法连接的:
参数suffixes
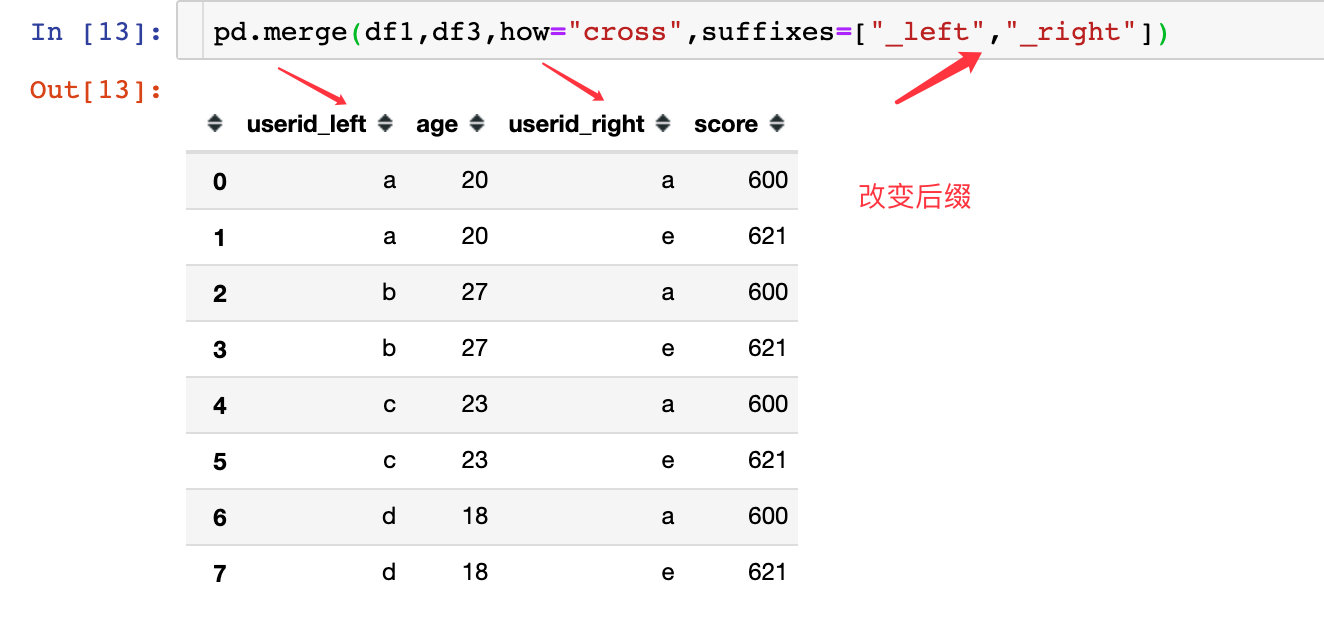
如果连接之后结果有相同的字段出现,默认后缀是_x_、_y。这个参数就是改变我们默认的后缀。我们回顾下笛卡尔积的形成;
现在我们可以指定想要的后缀:
indicator
这个参数的作用是表明生成的一条记录是来自哪个DataFrame:both、left_only、right_only
如果带上参数会显示一个新字段_merge:

不带上参数的话,默认是不会显示来源的,看默认的情况:
总结
merge函数真的是非常强大,在工作中也使用地很频繁,完全可以实现SQL中的join效果。希望本文的图解能够帮助读者理解这个合并函数的使用。同时pandas还有另外几个与合并相关的函数,比如:join、concat、append,会在下一篇文中统一讲解。
以上是关于图解pandas的数据合并merge的主要内容,如果未能解决你的问题,请参考以下文章