kafkaKafka 源码解析:Group 协调管理机制
Posted 九师兄
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了kafkaKafka 源码解析:Group 协调管理机制相关的知识,希望对你有一定的参考价值。

1.概述
在 Kafka 的设计中,消费者一般都有一个 group 的概念(当然,也存在不属于任何 group 的消费者),将多个消费者组织成一个 group 可以提升消息的消费处理能力,同时又能保证消息消费的顺序性,不重复或遗漏消费。一个 group 名下的消费者包含一个 leader 角色和多个 follower 角色,虽然在消费消息方面这两类角色是等价的,但是 leader 角色相对于 follower 角色还担负着管理整个 group 的职责。当 group 中有新的消费者加入,或者某个消费者因为一些原因退出当前 group 时,亦或是订阅的 topic 分区发生变化时,都需要为 group 名下的消费者重新分配分区,在服务端确定好分区分配策略之后,具体执行分区分配的工作则交由 leader 消费者负责,并在完成分区分配之后将分配结果反馈给服务端。
前面在分析消费者运行机制时曾多次提到 GroupCoordinator 类,本篇我们就来分析一下 GroupCoordinator 组件的作用和实现。GroupCoordinator 组件主要功能包括对隶属于同一个 group 的消费者进行分区分配、维护内部 offset topic,以及管理消费者和消费者所属的 group 信息等。集群中的每一个 broker 节点在启动时都会创建并启动一个 GroupCoordinator 实例,每个实例都会管理集群中所有消费者 group 的一个子集。
2.GroupCoordinator 组件的定义与启动
GroupCoordinator 类的字段定义如下:
class GroupCoordinator(
val brokerId: Int, // 所属的 broker 节点的 ID
val groupConfig: GroupConfig, // Group 配置对象,记录了 group 中 session 过期的最小时长和最大时长,即超时时长的合法区间
val offsetConfig: OffsetConfig, // 记录 OffsetMetadata 相关的配置项
val groupManager: GroupMetadataManager, // 负责管理 group 元数据以及对应的 offset 信息
val heartbeatPurgatory: DelayedOperationPurgatory[DelayedHeartbeat], // 管理 DelayedHeartbeat 延时任务的炼狱
val joinPurgatory: DelayedOperationPurgatory[DelayedJoin], // 管理 DelayedJoin 延时任务的炼狱
time: Time) extends Logging {
/** 标识当前 GroupCoordinator 实例是否启动 */
private val isActive = new AtomicBoolean(false)
// ... 省略方法定义
}
其中 GroupMetadataManager 类主要用于管理消费者 group 的元数据信息和 offset 相关信息,字段定义如下:
class GroupMetadataManager(val brokerId: Int, // 所属 broker 节点 ID
val interBrokerProtocolVersion: ApiVersion, // kafka 版本信息
val config: OffsetConfig, // 记录 OffsetMetadata 相关的配置项
replicaManager: ReplicaManager, // 管理 broker 节点上 offset topic 的分区信息
zkUtils: ZkUtils,
time: Time) extends Logging with KafkaMetricsGroup {
/** 消息压缩类型 */
private val compressionType: CompressionType = CompressionType.forId(config.offsetsTopicCompressionCodec.codec)
/** 缓存每个 group 在服务端对应的 GroupMetadata 对象 */
private val groupMetadataCache = new Pool[String, GroupMetadata]
/** 正在加载的 offset topic 分区的 ID 集合 */
private val loadingPartitions: mutable.Set[Int] = mutable.Set()
/** 已经加载完成的 offset topic 分区的 ID 集合 */
private val ownedPartitions: mutable.Set[Int] = mutable.Set()
/** 标识 GroupCoordinator 正在关闭 */
private val shuttingDown = new AtomicBoolean(false)
/** 记录 offset topic 的分区数目 */
private val groupMetadataTopicPartitionCount = getOffsetsTopicPartitionCount
/** 用于调度 delete-expired-consumer-offsets 和 GroupCoordinator 迁移等任务 */
private val scheduler = new KafkaScheduler(threads = 1, threadNamePrefix = "group-metadata-manager-")
// ... 省略方法定义
}
Kafka 服务在启动时针对每一个 broker 节点都会创建一个 GroupCoordinator 实例,并调用 GroupCoordinator#startup 方法启动运行。GroupCoordinator 在启动时主要是调用了 GroupMetadataManager#enableMetadataExpiration 方法启动 delete-expired-group-metadata 定时任务:
def startup(enableMetadataExpiration: Boolean = true) {
info("Starting up.")
if (enableMetadataExpiration) groupManager.enableMetadataExpiration()
isActive.set(true)
info("Startup complete.")
}
def enableMetadataExpiration() {
// 启动定时任务调度器
scheduler.startup()
// 启动 delete-expired-group-metadata 定时任务
scheduler.schedule(name = "delete-expired-group-metadata",
fun = cleanupGroupMetadata,
period = config.offsetsRetentionCheckIntervalMs,
unit = TimeUnit.MILLISECONDS)
}
定时任务 delete-expired-group-metadata 的主要作用在于从 group 的元数据信息中移除那些已经过期的 topic 分区对应的 offset 元数据,并将这些元数据以消息的形式记录到 offset topic 中,具体执行流程如下:
- 依据当前时间戳计算并获取已经过期的 topic 分区对应的 offset 元数据信息;
- 将状态为 Empty 且名下记录的所有 offset 元数据都已经过期的 group 切换成 Dead 状态;
- 如果 group 已经失效,则从 GroupCoordinator 本地移除对应的元数据信息,并与步骤 1 中获取到的 offset 元数据信息一起封装成消息记录到 offset topic 中。
具体逻辑由 GroupMetadataManager#cleanupGroupMetadata 方法实现,如下:
private[coordinator] def cleanupGroupMetadata(): Unit = {
this.cleanupGroupMetadata(None)
}
def cleanupGroupMetadata(deletedTopicPartitions: Option[Seq[TopicPartition]]) {
val startMs = time.milliseconds()
var offsetsRemoved = 0
// 遍历处理每个 group 对应的元数据信息
groupMetadataCache.foreach { case (groupId, group) =>
val (removedOffsets, groupIsDead, generation) = group synchronized {
// 计算待移除的 topic 分区对应的 offset 元数据信息
val removedOffsets = deletedTopicPartitions match {
// 从 group 元数据信息中移除指定的 topic 分区集合
case Some(topicPartitions) => group.removeOffsets(topicPartitions)
// 移除那些 offset 元数据已经过期的,且没有 offset 待提交的 topic 分区集合
case None => group.removeExpiredOffsets(startMs)
}
// 如果 group 当前状态为 Empty,且名下 topic 分区所有的 offset 已经过期,则将该 group 状态切换成 Dead
if (group.is(Empty) && !group.hasOffsets) {
info(s"Group $groupId transitioned to Dead in generation ${group.generationId}")
group.transitionTo(Dead)
}
(removedOffsets, group.is(Dead), group.generationId)
}
// 获取 group 对应在 offset topic 中的分区编号
val offsetsPartition = partitionFor(groupId)
val appendPartition = new TopicPartition(Topic.GroupMetadataTopicName, offsetsPartition)
getMagic(offsetsPartition) match {
// 对应 group 由当前 GroupCoordinator 进行管理
case Some(magicValue) =>
val timestampType = TimestampType.CREATE_TIME
val timestamp = time.milliseconds()
// 获取当前 group 在 offset topic 中的分区对象
val partitionOpt = replicaManager.getPartition(appendPartition)
partitionOpt.foreach { partition =>
// 遍历处理每个待移除的 topic 分区对应的 offset 元数据信息,封装成消息数据
val tombstones = removedOffsets.map { case (topicPartition, offsetAndMetadata) =>
trace(s"Removing expired/deleted offset and metadata for $groupId, $topicPartition: $offsetAndMetadata")
val commitKey = GroupMetadataManager.offsetCommitKey(groupId, topicPartition)
Record.create(magicValue, timestampType, timestamp, commitKey, null)
}.toBuffer
trace(s"Marked ${removedOffsets.size} offsets in $appendPartition for deletion.")
// 如果当前 group 已经失效,则从本地移除对应的元数据信息,并将 group 信息封装成消息,
// 如果 generation 为 0 则表示当前 group 仅仅使用 kafka 存储 offset 信息
if (groupIsDead && groupMetadataCache.remove(groupId, group) && generation > 0) {
tombstones += Record.create(magicValue, timestampType, timestamp, GroupMetadataManager.groupMetadataKey(group.groupId), null)
trace(s"Group $groupId removed from the metadata cache and marked for deletion in $appendPartition.")
}
if (tombstones.nonEmpty) {
try {
// 往 offset topic 中追加消息,不需要 ack,如果失败则周期性任务稍后会重试
partition.appendRecordsToLeader(MemoryRecords.withRecords(timestampType, compressionType, tombstones: _*))
offsetsRemoved += removedOffsets.size
trace(s"Successfully appended ${tombstones.size} tombstones to $appendPartition for expired/deleted offsets and/or metadata for group $groupId")
} catch {
case t: Throwable =>
error(s"Failed to append ${tombstones.size} tombstones to $appendPartition for expired/deleted offsets and/or metadata for group $groupId.", t)
}
}
}
case None =>
info(s"BrokerId $brokerId is no longer a coordinator for the group $groupId. Proceeding cleanup for other alive groups")
}
}
info(s"Removed $offsetsRemoved expired offsets in ${time.milliseconds() - startMs} milliseconds.")
}
3.Group 状态定义与转换
GroupState 特质定义了 group 的状态,并由 GroupCoordinator 进行维护。围绕 GroupState 特质,Kafka 实现了 5 个样例对象,分别用于描述 group 的 5 种状态:
PreparingRebalance:表示 group 正在准备执行分区再分配操作。AwaitingSync:表示 group 正在等待 leader 消费者的分区分配结果,新版本已更名为 CompletingRebalance。Stable:表示 group 处于正常运行状态。Dead:表示 group 名下已经没有消费者,且对应的元数据已经(或正在)被删除。Empty:表示 group 名下已经没有消费者,并且正在等待记录的所有 offset 元数据过期。
Group 状态之间的转换以及转换原因如下图和表所示:
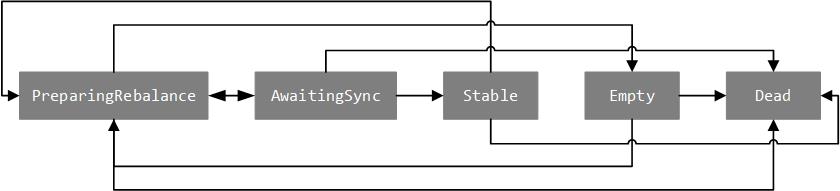
| 当前状态 | 目标状态 | 转换原因 |
|---|---|---|
| PreparingRebalance | AwaitingSync | group 之前名下所有的消费者都已经申请加入,或者等待消费者申请加入超时。 |
| PreparingRebalance | Empty | group 名下的所有消费者都已经离开。 |
| PreparingRebalance | Dead | group 对应的元数据信息被移除。 |
| AwaitingSync | Stable | group 收到来自 leader 消费者的分区分配结果。 |
| AwaitingSync | PreparingRebalance | 1. 有消费者申请加入或退出; 2. 名下消费者更新了元数据信息; 3. 名下消费者心跳超时。 |
| AwaitingSync | Dead | group 对应的元数据信息被移除。 |
| Stable | PreparingRebalance | 1. 有消费者申请加入或退出; 2. 名下消费者心跳超时。 |
| Stable | Dead | group 对应的元数据信息被移除。 |
| Empty | PreparingRebalance | 有消费者申请加入。 |
| Empty | Dead | 1. group 名下所有的 offset 元数据信息已经过期; 2. group 对应的元数据信息被移除。 |
| Dead | 无 |
4.故障转移机制
在 Kafka 0.8.2.2 版本中引入了使用 offset topic 存储消费 offset 位置数据,以解决之前版本中采用 ZK 存储所面临的性能压力和不稳定性,并由 GroupCoordinator 组件负责维护。Offset topic 与 Kafka 中的普通 topic 除了用途上的区别之外,在性质上没有任何区别,Kafka 默认为 offset topic 设置了 50 个分区,每个分区分配 3 个副本。当某个 broker 节点宕机时,如果该节点上正好运行着 offset topic 某个分区的 leader 副本,考虑服务可用性需要选举一个位于其它可用 broker 节点上的满足条件的 follower 副本作为新的 leader 副本,同时由位于该 broker 节点上的 GroupCoordinator 实例继续维护对应的 offset topic 分区。因为涉及到 GroupCoordinator 实例的变更,所以需要在新的 GroupCoordinator 实例接管维护这些 offset topic 分区时,需要在这些 GroupCoordinator 实例上恢复对应 group 的元数据信息(一个 offset topic 分区中记录了一批 group 的元数据和 offset 消费数据)。
之前的文章在分析 Kafka 的分区副本机制时曾介绍了对 LeaderAndIsrRequest 请求的处理,ReplicaManager 定义了 ReplicaManager#becomeLeaderOrFollower 方法用于对指定 topic 分区的副本执行角色切换。该方法接收一个 (Iterable[Partition], Iterable[Partition]) => Unit 类型的回调函数,用于分别处理完成 leader 角色和 follower 角色切换的分区对象集合,回调函数的具体定义位于 KafkaApis#handleLeaderAndIsrRequest 方法中,实现如下:
// 完成 GroupCoordinator 的迁移操作
def onLeadershipChange(updatedLeaders: Iterable[Partition], updatedFollowers: Iterable[Partition]) {
updatedLeaders.foreach { partition =>
// 仅处理 offset topic,当 broker 节点维护 offset topic 分区的 leader 副本时回调执行
if (partition.topic == Topic.GroupMetadataTopicName) coordinator.handleGroupImmigration(partition.partitionId)
}
updatedFollowers.foreach { partition =>
// 仅处理 offset topic,当 broker 节点维护 offset topic 分区的 follower 副本时回调执行
if (partition.topic == Topic.GroupMetadataTopicName) coordinator.handleGroupEmigration(partition.partitionId)
}
}
由上述实现可以看到该回调函数仅处理 offset topic 对应的分区,当 GroupCoordinator 实例开始维护 offset topic 某个分区的 leader 副本时会触发执行 GroupCoordinator#handleGroupImmigration 方法,而当 GroupCoordinator 实例开始维护 offset topic 某个分区的 follower 副本时会触发执行 GroupCoordinator#handleGroupEmigration 方法,下面分别对这两个方法的实现进行分析。
方法 GroupCoordinator#handleGroupImmigration 的实现如下:
def handleGroupImmigration(offsetTopicPartitionId: Int) {
groupManager.loadGroupsForPartition(offsetTopicPartitionId, onGroupLoaded)
}
private def onGroupLoaded(group: GroupMetadata) {
group synchronized {
info(s"Loading group metadata for ${group.groupId} with generation ${group.generationId}")
assert(group.is(Stable) || group.is(Empty))
// 遍历更新当前 group 名下所有消费者的心跳信息
group.allMemberMetadata.foreach(completeAndScheduleNextHeartbeatExpiration(group, _))
}
}
关于 GroupCoordinator#completeAndScheduleNextHeartbeatExpiration 方法的执行逻辑我们将在下一小节进行分析,这里我们主要来看一下 GroupMetadataManager#loadGroupsForPartition 方法的实现,该方法会基于 offset topic 更新对应 group 的元数据,并初始化每个 topic 分区对应的 offset 信息:
def loadGroupsForPartition(offsetsPartition: Int, onGroupLoaded: GroupMetadata => Unit) {
// 构建 offset topic 对应的 topic 分区对象
val topicPartition = new TopicPartition(Topic.GroupMetadataTopicName, offsetsPartition)
def doLoadGroupsAndOffsets() {
info(s"Loading offsets and group metadata from $topicPartition")
inLock(partitionLock) {
// 检测当前 offset topic 分区是否正在加载,如果已经处于加载中则返回
if (loadingPartitions.contains(offsetsPartition)) {
info(s"Offset load from $topicPartition already in progress.")
return
} else {
loadingPartitions.add(offsetsPartition)
}
}
try {
// 基于 offset topic 加载更新对应 group 的元数据信息,初始化每个 topic 分区对应的 offset 信息
this.loadGroupsAndOffsets(topicPartition, onGroupLoaded)
} catch {
case t: Throwable => error(s"Error loading offsets from $topicPartition", t)
} finally {
inLock(partitionLock) {
ownedPartitions.add(offsetsPartition)
loadingPartitions.remove(offsetsPartition)
}
}
}
// 异步调度执行
scheduler.schedule(topicPartition.toString, doLoadGroupsAndOffsets)
}
具体加载更新的过程采用异步调度的策略执行,实现位于 GroupMetadataManager#loadGroupsAndOffsets 方法中,该方法会读取对应 topic 分区下的所有消息数据,并依据消息的类型分别处理:
private[coordinator] def loadGroupsAndOffsets(topicPartition: TopicPartition, onGroupLoaded: GroupMetadata => Unit) {
// 获取指定 topic 分区的 HW 值
def highWaterMark: Long = replicaManager.getHighWatermark(topicPartition).getOrElse(-1L)
val startMs = time.milliseconds()
// 获取并处理 topic 分区对应的 Log 对象
replicaManager.getLog(topicPartition) match {
case None =>
// 不存在
warn(s"Attempted to load offsets and group metadata from $topicPartition, but found no log")
case Some(log) =>
var currOffset = log.logStartOffset
val buffer = ByteBuffer.allocate(config.loadBufferSize)
// 记录 topic 分区与对应的 offset 信息映射关系
val loadedOffsets = mutable.Map[GroupTopicPartition, OffsetAndMetadata]()
val removedOffsets = mutable.Set[GroupTopicPartition]()
// 记录 group 与对应的 group 元数据信息映射关系
val loadedGroups = mutable.Map[String, GroupMetadata]()
val removedGroups = mutable.Set[String]()
// 从 Log 对象中第一个 LogSegment 开始读取日志数据,直到 HW 位置为止,
// 加载 offset 信息和 group 元数据信息
while (currOffset < highWaterMark && !shuttingDown.get()) {
buffer.clear()
// 读取日志数据到内存
val fileRecords = log
.read(currOffset, config.loadBufferSize, maxOffset = None, minOneMessage = true)
.records.asInstanceOf[FileRecords]
val bufferRead = fileRecords.readInto(buffer, 0)
// 遍历处理消息集合(深层迭代)
MemoryRecords.readableRecords(bufferRead).deepEntries.asScala.foreach { entry =>
val record = entry.record
require(record.hasKey, "Group metadata/offset entry key should not be null")
// 依据消息的 key 决定当前消息的类型
GroupMetadataManager.readMessageKey(record.key) match {
// 如果是记录 offset 的消息
case offsetKey: OffsetKey =>
val key = offsetKey.key
if (record.hasNullValue) {
// 删除标记,则移除对应的 offset 信息
loadedOffsets.remove(key)
removedOffsets.add(key)
} else {
// 非删除标记,解析并更新 key 对应 offset 信息
val value = GroupMetadataManager.readOffsetMessageValue(record.value)
loadedOffsets.put(key, value)
removedOffsets.remove(key)
}
// 如果是记录 group 元数据的消息
case groupMetadataKey: GroupMetadataKey =>
val groupId = groupMetadataKey.key
val groupMetadata = GroupMetadataManager.readGroupMessageValue(groupId, record.value)
if (groupMetadata != null) {
// 非删除标记,记录加载的 group 元数据信息
trace(s"Loaded group metadata for group $groupId with generation ${groupMetadata.generationId}")
removedGroups.remove(groupId)
loadedGroups.put(groupId, groupMetadata)
} else {
// 删除标记
loadedGroups.remove(groupId)
removedGroups.add(groupId)
}
// 未知的消息 key 类型
case unknownKey =>
throw new IllegalStateException(s"Unexpected message key $unknownKey while loading offsets and group metadata")
}
currOffset = entry.nextOffset
}
}
// 将在 offset topic 中存在 offset 信息的 topic 分区以是否在 offset topic 中包含 group 元数据信息进行区分
val (groupOffsets, emptyGroupOffsets) = loadedOffsets
.groupBy(_._1.group)
.mapValues(_.map { case (groupTopicPartition, offset) => (groupTopicPartition.topicPartition, offset) })
.partition { case (group, _) => loadedGroups.contains(group) }
// 遍历处理在 offset topic 中存在 group 元数据信息的 group
loadedGroups.values.foreach { group =>
val offsets = groupOffsets.getOrElse(group.groupId, Map.empty[TopicPartition, OffsetAndMetadata])
// 更新 group 对应的元数据信息,主要是更新名下每个 topic 分区对应的 offset 信息
loadGroup(group, offsets)
onGroupLoaded(group)
}
// 遍历处理在 offset topic 中不存在 group 元数据信息的 group,但是存在 offset 信息,新建一个
emptyGroupOffsets.foreach { case (groupId, offsets) =>
val group = new GroupMetadata(groupId)
// 更新 group 对应的元数据信息,主要是更新名下每个 topic 分区对应的 offset 信息
loadGroup(group, offsets)
onGroupLoaded(group)
}
// 检测需要删除的 group 元数据信息,如果对应 group 在本地有记录且在 offset topic 中存在 offset 信息,
// 则不应该删除,此类 group 一般仅依赖 kafka 存储 offset 信息,而不存储对应的 group 元数据信息
removedGroups.foreach { groupId =>
if (groupMetadataCache.contains(groupId) && !emptyGroupOffsets.contains(groupId))
throw new IllegalStateException(s"Unexpected unload of active group $groupId while loading partition $topicPartition")
}
}
kafkaKafka 之 Group 状态变化分析及 Rebalance 过程
KafkaKafka Producer整体架构概述及源码分析
kafkakafka获取消费组异常 EOFException: null & KeeperErrorCode
kafkaKafka源码解析 - LogSegment以及Log初始化