从零开始的AI·决策树原来这么好理解(附实例代码)
Posted 有理想、有本领、有担当的有志青年
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从零开始的AI·决策树原来这么好理解(附实例代码)相关的知识,希望对你有一定的参考价值。
从零开始的AI系列
前言
本文理论部分基于Peter Harrington的《机器学习实战》一书
决策树是一种树形结构,其中每个内部节点表示一个属性上的测试,每个分支代表一个测试输出,每个叶节点代表一种类别。分类树决策树是一种十分常用的分类方法。它是一种监督学习。
如果觉得AI学习枯燥,可以选择看一下这个老哥做的网站,趣味性直接拉满>>人工智能教程
一、权衡利弊
- 优点:计算复杂度不高,输出结果易于理解,对中间值的缺失不敏感,可以处理不相关特征数据。
- 缺点:可能会产生过度匹配问题。
- 适用数据类型:数值型和标称型。
二、整体感知
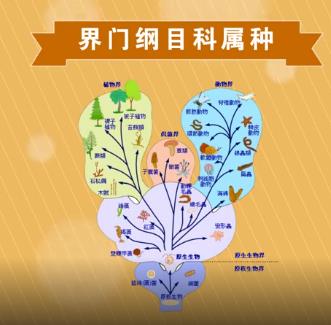
上述对生物种类的划分就可以通过决策树来实现。通过对每种生物特征不断划分,最终实现对生物进行分类的目的。
三、理论依据
如果我们知道依据什么特征,划分数据将会很容易,所以我们的主要工作做在选择特征上。由此我们引出 信息增益,获得信息增益最高的特征就是最好的选择
如何通过计算信息增益确定特征?
信息定义公式

信息熵定义公式

经验熵公式

|D|表示其样本容量
条件熵公式
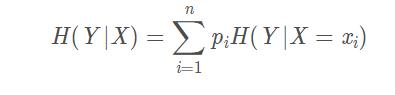
信息增益
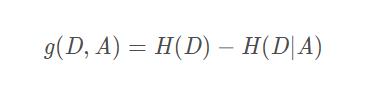
A是某一特征
四、具体实现过程及细节
#导入数据
import pandas as pd
Tianic = pd.read_csv(r'train.csv')
#划分数据集
from sklearn import model_selection
predictors=Tianic.columns[1:2]
X_train, X_test, Y_train, Y_test =model_selection.train_test_split(Tianic[predictors],Tianic.z,test_size=0.25,random_state=1234)
#构建函数模型并预测
from sklearn import tree
from sklearn import metrics
CART_Class=tree.DecisionTreeClassifier(max_depth=1,min_samples_leaf=1,min_samples_split=2)
decision_tree = CART_Class.fit(X_train,Y_train)
pred = CART_Class.predict(X_test)
print('准确率:\\n',metrics.accuracy_score(Y_test,pred))
以上是关于从零开始的AI·决策树原来这么好理解(附实例代码)的主要内容,如果未能解决你的问题,请参考以下文章