《LeetCode之每日一题》:99.删除排序链表中的重复元素 II
Posted 是七喜呀!
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《LeetCode之每日一题》:99.删除排序链表中的重复元素 II相关的知识,希望对你有一定的参考价值。
题目链接: 删除排序链表中的重复元素 II
有关题目
存在一个按升序排列的链表,给你这个链表的头节点 head ,
请你删除链表中所有存在数字重复情况的节点,只保留原始链表
中 没有重复出现 的数字。
返回同样按升序排列的结果链表。
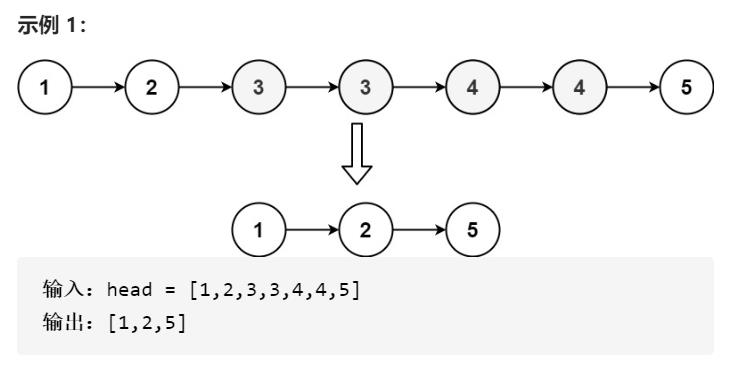
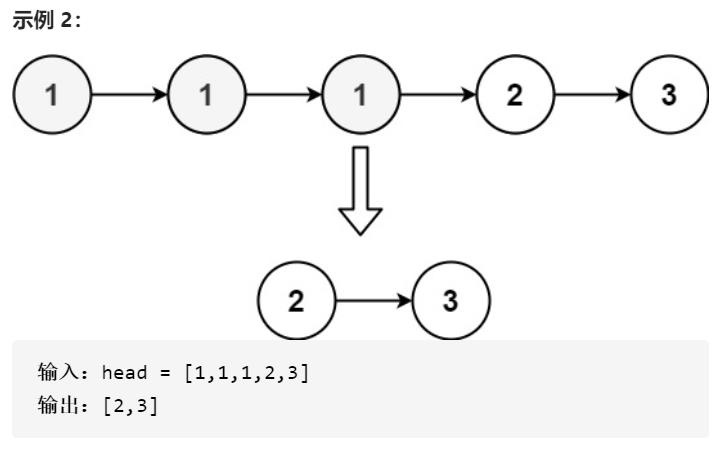
提示:
链表中节点数目在范围 [0, 300] 内
-100 <= Node.val <= 100
题目数据保证链表已经按升序排列
题解
法一:模拟哈希
代码一:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* deleteDuplicates(struct ListNode* head){
if(!head || !head->next) return head;
int arr[201];
memset(arr,0,sizeof(arr));
struct ListNode* move = head;
struct ListNode* dummy = (struct ListNode*)malloc(sizeof(struct ListNode));//创建哑节点
dummy->next = head;
struct ListNode* dummy_move = dummy;
while(move)
{
//根据题干,加100控制数组下标为非负数
arr[move->val + 100]++;
move = move->next;
}
move = head;
while(move)
{
if (arr[move->val + 100] == 1)
{
dummy_move->next = move;
//dummy_move移动,指向已经遍历的链表结尾
dummy_move = dummy_move->next;
}
move = move->next;
}
dummy_move->next = NULL;
return dummy->next;
}
代码二:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* deleteDuplicates(struct ListNode* head){
if (!head || !head->next) return head;
struct ListNode* move = head;
int arr[201];
memset(arr,0,sizeof(arr));
int flag = 0;//哨兵
while(move)
{
arr[move->val + 100]++;
move = move->next;
}
move = head;
struct ListNode* tmp = head;
for (int i = 0; i < 201; i++)
{
if (arr[i] == 1)
{
move->val = i - 100;
tmp = move;//结合有序性,实际上是重新构建一个链表
flag = 1;
move = move->next;
}
}
if (flag)
tmp->next = NULL;
else
head = NULL;
return head;
}
法二:哈希
代码一:不知道真超时还是写错了
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct HashTable {
int key,val;
UT_hash_handle hh;
};
struct ListNode* deleteDuplicates(struct ListNode* head){
struct ListNode* dummy = (struct ListNode*)malloc(sizeof(struct ListNode));//创建哑节点
struct ListNode* dummy_move = &dummy;
struct HashTable *hashTable = NULL;
struct ListNode* move = head;
while(move)
{
struct HashTable* tmp;
HASH_FIND(hh, hashTable, &move->val, sizeof(struct HashTable *), tmp);
if (tmp == NULL)
{
tmp = malloc(sizeof(struct HashTable));
tmp->key = move->val;
tmp->val = 1;
HASH_ADD(hh, hashTable, key, sizeof(struct HashTable *), tmp);
}
else
tmp->val++;
}
move = head;
while(move)
{
struct HashTable* tmp;
HASH_FIND(hh, hashTable, &move->val, sizeof(struct HashTable *), tmp);
if (tmp->val == 1)
{
dummy_move->next = move;
//dummy_move移动,指向已经遍历的链表结尾
dummy_move = dummy_move->next;
}
move = move->next;
dummy_move->next = NULL;
}
return dummy->next;
}
法三:迭代
代码一:
思路:
有序,值相同的节点会在一起
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* deleteDuplicates(struct ListNode* head){
if (!head || !head->next) return head;
struct ListNode* pre = NULL;
struct ListNode* cur = head;
while(cur->next)
{
//删除的为头节点
if (head->val == head->next->val)
{
while(head->next != NULL && head->val == head->next->val)//head->next != NULL不放在前面就有可能会越界
跳过当前的重复节点,使得head指向当前重复元素的最后一个位置
head = head->next;
if (head->next == NULL) return NULL;//通过[1,1]
head = head->next;//通过[1,1,1,2,2,3,5]
cur = head;
}
else//不是头节点
{
if (cur->val == cur->next->val)
{
while(cur->next != NULL && cur->val == cur->next->val)
//跳过当前的重复节点,使得cur指向当前重复元素的最后一个位置
cur = cur->next;
if (cur->next == NULL) //通过[1,2,2]
{
pre->next = NULL;
return head;
}
pre->next = cur->next;//通过[1,2,2,3,4]
cur = pre->next;
}
else
{
pre = cur;
cur = cur->next;
}
}
}
return head;
}
代码二:
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* deleteDuplicates(struct ListNode* head){
if (!head || !head->next) return head;
//创建哑节点
struct ListNode* dummy = (struct ListNode*)malloc(sizeof(struct ListNode));//创建哑节点
dummy->next = head;//合并出现删除头部的情况
struct ListNode* pre = dummy;
struct ListNode* cur = head;
while(cur)
{
//跳过当前的重复节点,使得cur指向当前重复元素的最后一个位置
while(cur->next && cur->val == cur->next->val)
cur = cur->next;
if (pre->next == cur)//pre和cur之间没有重复节点,pre后移
pre = pre->next;
else
//pre->next指向cur的下一个位置(相当于跳过了当前的重复元素)
//pre不移动,仍指向已经遍历的链表结尾
pre->next = cur->next;
//跳过了当前的重复元素
cur = cur->next;
}
return dummy->next;
}
代码三:
由于链表的头节点可能会被删除,同时为了维护一个不变的头节点
因此我们需要额外使用一个哑节点(dummy node)
/**
* Definition for singly-linked list.
* struct ListNode {
* int val;
* struct ListNode *next;
* };
*/
struct ListNode* deleteDuplicates(struct ListNode* head){
if (!head || !head->next) return head;
struct ListNode* dummy = (struct ListNode*)malloc(sizeof(struct ListNode));//创建哑节点
dummy->next = head;//合并出现删除头部的情况
struct ListNode* cur = dummy;
while(cur->next && cur->next->next)//通过[null,1,1,2]验证
{
if ( cur->next->val == cur->next->next->val)
{
int x = cur->next->val;//记录此时相等的值
while(cur->next && cur->next->val == x)//除去所有x
cur->next = cur->next->next;
}
else
cur = cur->next;
}
return dummy->next;
}

以上是关于《LeetCode之每日一题》:99.删除排序链表中的重复元素 II的主要内容,如果未能解决你的问题,请参考以下文章