百变冰冰!手把手教你实现CVPR2021最新妆容迁移算法
Posted AI科技大本营
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了百变冰冰!手把手教你实现CVPR2021最新妆容迁移算法相关的知识,希望对你有一定的参考价值。


作者:小潘师兄
来源:AI算法与图像处理
简介
在本文中,我们从不同的角度将妆容迁移问题分解为两步提取-分配过程。为此,我们提出了一种基于风格的可控GAN模型,该模型由三个部分组成,每个部分分别对应于目标风格编码、人脸特征提取和化妆融合。具体地,特定于部件的样式编码器将参考图像的组件式构图样式编码为中间潜在空间W中的样式代码。样式代码丢弃空间信息,因此对空间错位保持不变。另一方面,样式码嵌入了组件信息,使得能够从多个参考中灵活地进行部分补码编辑,该样式码与源标识特征一起集成到一个具有多个AdaIN层的补码融合解码器中,以生成最终结果。
架构图:
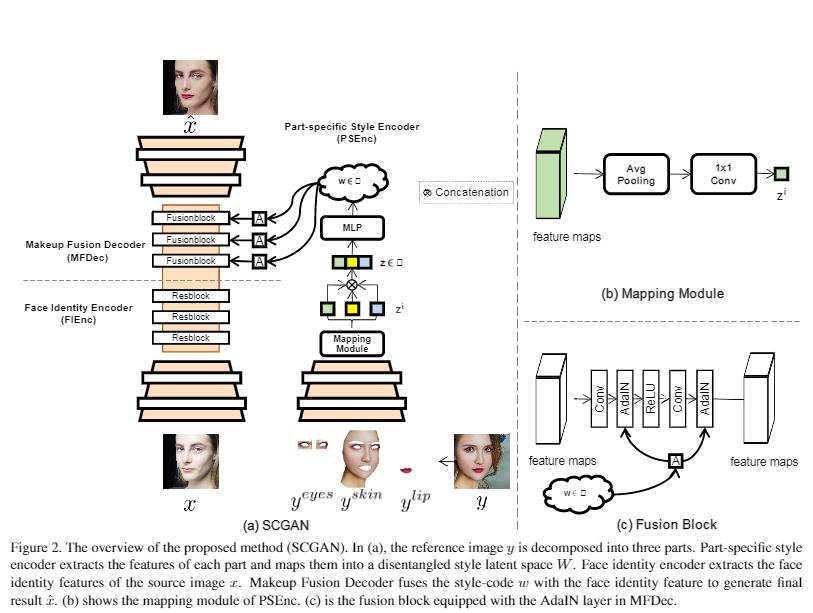
解析:提出的方法(SCGAN)的概述。在(a)中,参考图像y被分解为三部分。part-specific样式编码器提取每个部分的特征,并将其映射到一个分离的样式潜在空间W。人脸身份编码器提取源图像x的人脸身份特征。妆容融合解码器将样式码w与人脸身份特征融合,生成最终结果xˆ. (b) 显示PSEnc的映射模块(c) 是MFDec中装有AdaIN层的熔合块。
思路 & 效果
大概了解原理之后,我们开始实现:
步骤1:对人脸的五官(眼睛、眉毛、鼻子、嘴唇等等)进行分割。
步骤2:使用SCGAN 进行上妆。
这里的人脸五官分割模型采用的是:
https://github.com/zllrunning/face-parsing.PyTorch
先看一下效果:

卧槽,什么鬼,效果并不是很好,那么是SCGAN 的模型问题吗?
存在的问题:首先仔细回想一下处理的过程,来查看,第一步处理的时候发现,分割的效果并不理想,嘴唇位置和闭嘴的分割效果非常的差,这也导致了最后的效果并不是理想。因此,需要想办法优化分割的效果。

那么如何优化分割的效果?
重新训练?不存在的。
第一没有数据集,第二没有必要
我们知道深度学习模型的性能其实和数据集是有很强的相关性的,这里我们仔细观察一下人脸分割所采用的数据集 https://github.com/switchablenorms/CelebAMask-HQ

基本上采用的是使用仅包含人脸头部区域作为输入和制作label的,因此,这里尝试对输入的图片进行处理,裁剪成仅包含人脸区域的作为输入 (裁剪人脸区域)
因此现在的步骤变成:
1、裁剪人脸
2、对人脸的五官(眼睛、眉毛、鼻子、嘴唇等等)进行分割
3、使用SCGAN 进行上妆
详细操作流程
裁剪人脸:
这里直接使用 dlib, 裁剪出人脸的区域。
import cv2
import dlib
img = cv2.imread("bingbing.jpg")
height, width = img.shape[:2]
face_detector = dlib.get_frontal_face_detector()
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
faces = face_detector(gray, 1)
def get_boundingbox(face, width, height, scale=1.3, minsize=None):
"""
Expects a dlib face to generate a quadratic bounding box.
:param face: dlib face class
:param width: frame width
:param height: frame height
:param scale: bounding box size multiplier to get a bigger face region
:param minsize: set minimum bounding box size
:return: x, y, bounding_box_size in opencv form
"""
x1 = face.left()
y1 = face.top()
x2 = face.right()
y2 = face.bottom()
size_bb = int(max(x2 - x1, y2 - y1) * scale)
if minsize:
if size_bb < minsize:
size_bb = minsize
center_x, center_y = (x1 + x2) // 2, (y1 + y2) // 2
# Check for out of bounds, x-y top left corner
x1 = max(int(center_x - size_bb // 2), 0)
y1 = max(int(center_y - size_bb // 2), 0)
# Check for too big bb size for given x, y
size_bb = min(width - x1, size_bb)
size_bb = min(height - y1, size_bb)
return x1, y1, size_bb
if len(faces):
face = faces[0]
x,y,size = get_boundingbox(face, width, height)
cropped_face = img[y-50:y+size,x:x+size]
cv2.imwrite("cropped_face.jpg", cropped_face)
这里我偷偷换了一个素材。
输入:

输出:

这样子我们就完成了裁剪工作。
人脸五官分割:
使用的模型:
https://github.com/zllrunning/face-parsing.PyTorch
1)克隆项目:
git clone git@github.com:zllrunning/face-parsing.PyTorch.git
如果遇到下载问题参考之前的教程:
完美解决Github上下载项目失败或速度太慢的问题
2)环境配置 & 预训练模型:
因为这里,没有写环境相关相关的配置
但是这个人脸五官分割的模型是基于 BiSeNet(https://github.com/CoinCheung/BiSeNet)
这里推荐torch 1.6.0 torchvision 0.7.0,因为可以兼容后续的 SCGAN 模型,这里以cuda10.1为例 (已测试没有问题)
# 安装
conda install pytorch==1.6.0 torchvision==0.7.0 cudatoolkit=10.1 -c pytorch
或
pip install torch==1.6.0+cu101 torchvision==0.7.0+cu101 -f https://download.pytorch.org/whl/torch_stable.html
下载过慢,可以考虑换源,例如清华源、阿里源等,或者指定源(参考链接https://www.cnblogs.com/yuki-nana/p/10898774.html)
预训练模型:https://drive.google.com/open?id=154JgKpzCPW82qINcVieuPH3fZ2e0P812
将下载好的模型,放在 res/cp 路径下。
3)运行:
修改 test.py 文件
对下面的输入进行修改
if __name__ == "__main__":
evaluate(dspth='/home/zll/data/CelebAMask-HQ/test-img', cp='79999_iter.pth')
假设这里将要分割的图片放在test文件夹下,则这里修改成:
if __name__ == "__main__":
evaluate(dspth='test', cp='79999_iter.pth')
然后运行即可看到res/test_res 文件夹下有生成的结果
这里建议输入的图片后缀,不要是 png 否则会由于生成的文件名冲突导致我们想要的文件被覆盖了。此时生成的结果包含:


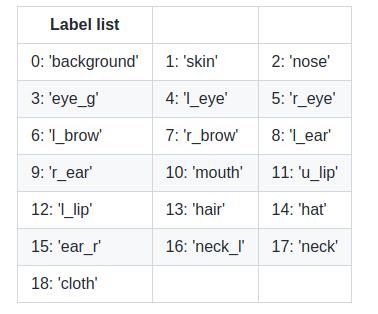
假设左边为图1,右边图2。图1 是对分割的结果进行上色,图2是对应的label 值,但是由于原始的label设置成很小的值(0-18),很难看出区别来。
具体的label对应的含义 ,可以参考下面
https://github.com/switchablenorms/CelebAMask-HQ/tree/master/face_parsing
这里我们已经完成了对人脸的分割处理
使用SCGAN 上妆:
1)克隆项目:
(https://github.com/makeuptransfer/SCGAN)
但是由于作者做了一些优化(version 2),目前没有把预训练的模型补充上去,因此这里可以别人fork的版本下载(https://github.com/tommy19970714/SCGAN/)
git clone git@github.com:tommy19970714/SCGAN.git
2)预训练权重下载:
https://drive.google.com/file/d/1t1Hbgqqzc_rV5v3gF7HuJ-xiuEVNb8sh/view
将 G.pth 和 vgg.pth 分别放在 文件夹 "./checkpoints" (自己新建一个)和 "./"(项目下) 下
3)修改必要文件和运行:
修改 test.py 文件,对下面的输入进行修改
首先这里还要做一些预处理,对label 进行一些变换。
这里作者已经给了代码(scripts/handdle_parsing.py),输入的图片是刚刚人脸分割获得的图 2,就是那个看上去黑乎乎的图片
修改 handdle_parsing.py 中的 root 和保存结果的结果名即可
root="./data/bingbing.png" # 假设输入的是
paths=["bingbing.png"]
运行后得到新的
将这两张图片分别放在./MT-Dataset/images/non-makeup/bingbing.png (原始图片)和/MT-Dataset/parsing/non-makeup/bingbing.png 即可
修改test.txt 文件
原始
non-makeup/xfsy_0444.png makeup/XMY-078.png
non-makeup/xfsy_0444.png makeup/licEnH3rBjSA.png
修改后
non-makeup/bingbing.png makeup/XMY-078.png
non-makeup/bingbing.png makeup/licEnH3rBjSA.png
最后运行即可看到结果(result 文件夹下)

如果你希望对保存的结果样式进行修改,可以看
/SCGAN/models/SCGAN.py 中的 imgs_save 函数 (这里就不展开)



如果你想尝试更多妆容可以去下载
http://colalab.org/projects/BeautyGAN


以上是关于百变冰冰!手把手教你实现CVPR2021最新妆容迁移算法的主要内容,如果未能解决你的问题,请参考以下文章