大数据(8s)Spark结构化流
Posted 小基基o_O
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据(8s)Spark结构化流相关的知识,希望对你有一定的参考价值。
Structured Streaming编程指南
1、概念图
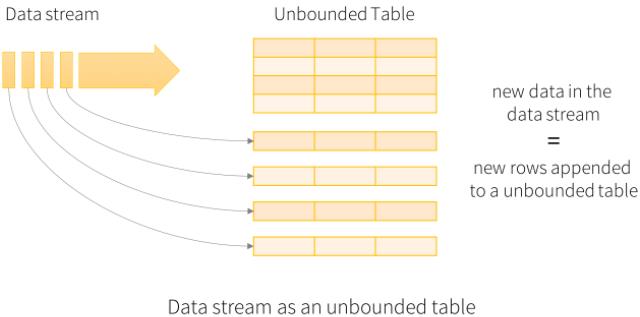
2、入门示例
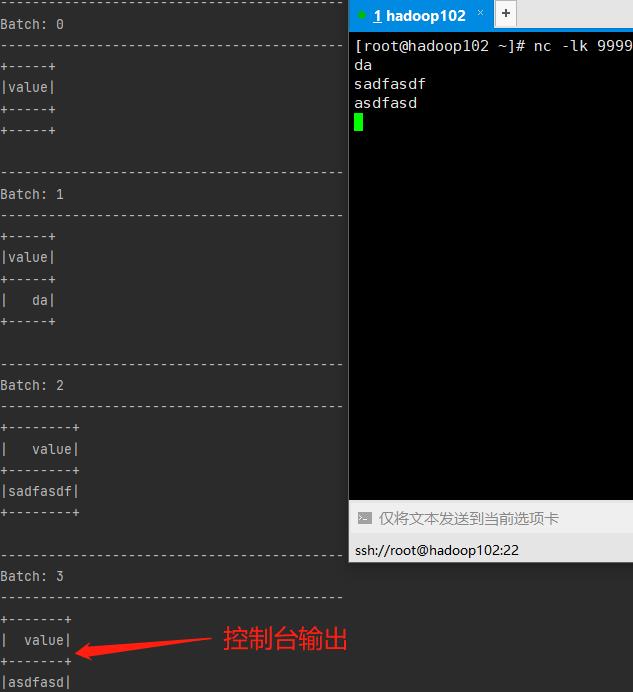
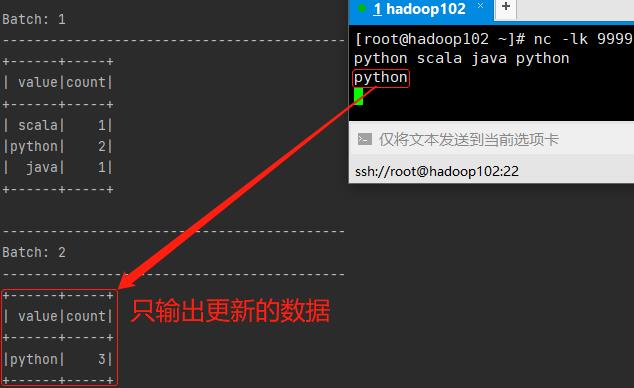
2.1、追加输出模式
// 创建 SparkSession对象
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
val c1: SparkConf = new SparkConf().setAppName("A1").setMaster("local[*]")
val spark: SparkSession = SparkSession.builder().config(c1).getOrCreate()
// 创建 接收套接字数据流的DataFrame
val lines = spark.readStream
.format("socket")
.option("host", "hadoop102")
.option("port", 9999)
.load()
// 运行查询
val query = lines.writeStream
.outputMode("append") // 输出模式:追加
.format("console") // 输出方式:打印到控制台
.start()
// 防止进程 在查询活跃时 退出
query.awaitTermination()
2.2、完全输出模式
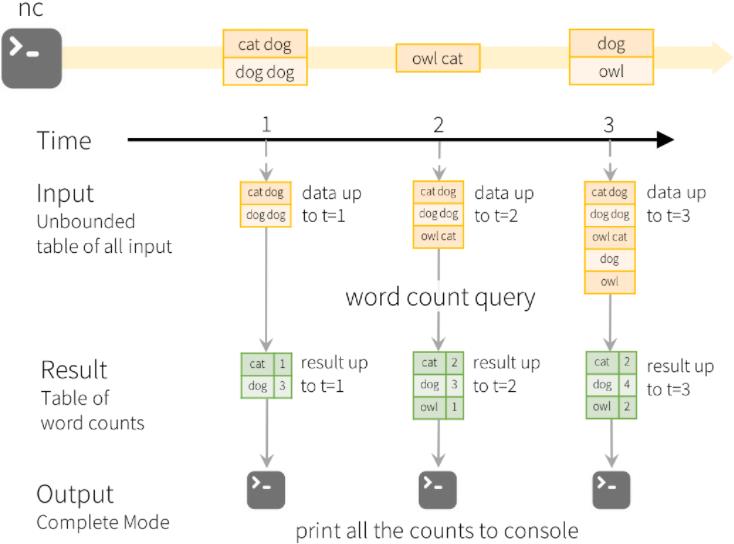
// 创建SparkSession对象
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.DataFrame
val c1: SparkConf = new SparkConf().setAppName("A1").setMaster("local[*]")
val spark: SparkSession = SparkSession.builder().config(c1).getOrCreate()
import spark.implicits._
//创建 接收套接字数据流的DataFrame
val lines: DataFrame = spark.readStream
.format("socket")
.option("host", "hadoop102")
.option("port", 9999)
.load()
val wordCount = lines.as[String].flatMap(_.split(" ")).groupBy("value").count()
//运行查询
val query = wordCount.writeStream
.outputMode("complete") // 输出模式:追加
.format("console") // 输出方式:打印到控制台
.start()
//防止进程 在查询活跃时 退出
query.awaitTermination()
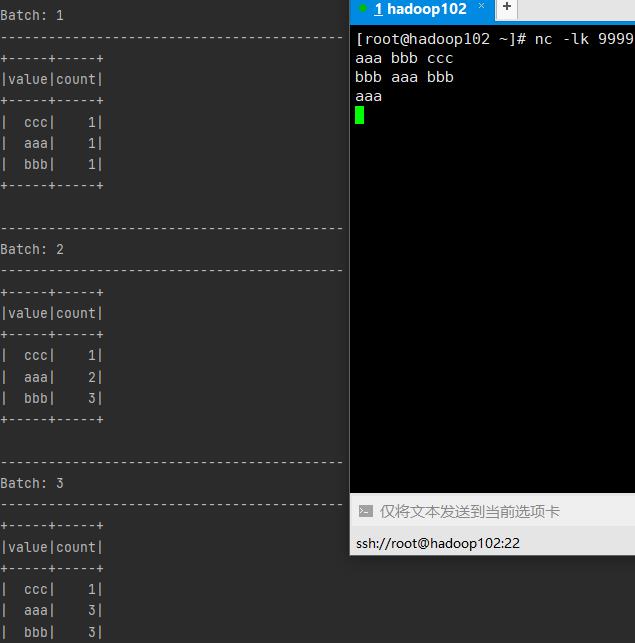
2.3、更新输出模式
// 创建SparkSession对象
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.DataFrame
val c1: SparkConf = new SparkConf().setAppName("A1").setMaster("local[*]")
.set("spark.sql.shuffle.partitions", "2") // 设置shuffle分区数(提速)
val spark: SparkSession = SparkSession.builder().config(c1).getOrCreate()
import spark.implicits._
//创建 接收套接字数据流的DataFrame
val lines: DataFrame = spark.readStream
.format("socket")
.option("host", "hadoop102")
.option("port", 9999)
.load()
val wordCount = lines.as[String].flatMap(_.split(" ")).groupBy("value").count()
//运行查询
val query = wordCount.writeStream
.outputMode("update") // 输出模式:追加
.format("console") // 输出方式:打印到控制台
.start()
//防止进程 在查询活跃时 退出
query.awaitTermination()
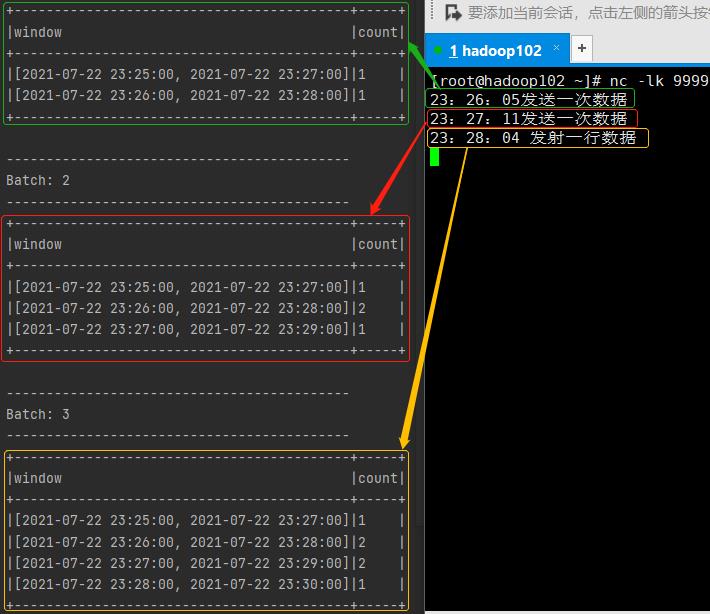
3、滑窗
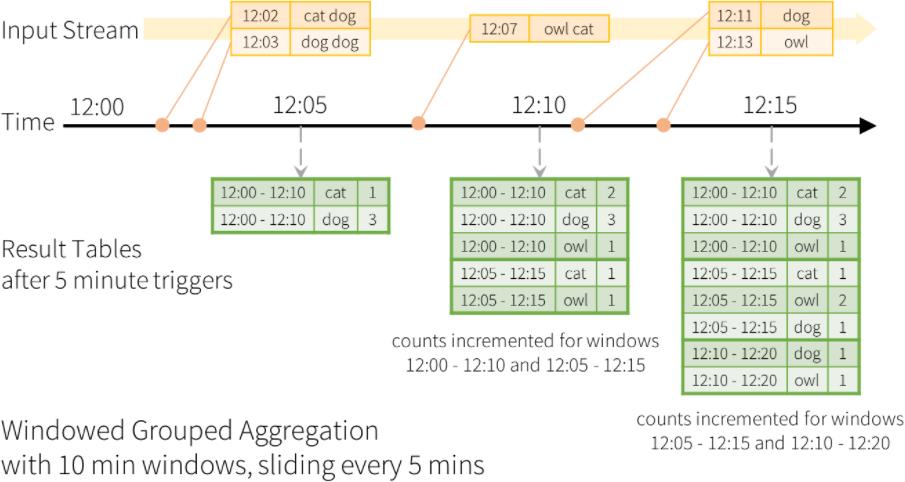
时间窗口归整原理:https://yellow520.blog.csdn.net/article/details/118997612
// 导入Spark相关
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.streaming.{OutputMode, StreamingQuery}
import org.apache.spark.sql.functions.{window, column}
// 导入时间相关
import java.sql.Timestamp
import java.time.LocalDateTime
// 创建sparkSession
val sparkConf = new SparkConf().setAppName("A0").setMaster("local[*]")
.set("spark.sql.shuffle.partitions", "1")
val sparkSession = SparkSession.builder.config(sparkConf).getOrCreate
import sparkSession.implicits._
// 读取数据流
val ds = sparkSession.readStream
.format("socket").option("host", "hadoop102").option("port", 9999)
.load()
.map(_ => Timestamp.valueOf(LocalDateTime.now)) // 每行数据转成1个时间
.toDF("now") // 设置字段名,后面groupBy该字段
// 开窗
val query: StreamingQuery = ds
.groupBy(window(column("now"), "2 minutes", "1 minutes"))
.count().orderBy("window")
.writeStream.outputMode(OutputMode.Complete()).format("console")
.option("truncate", "false").start()
query.awaitTermination()
以上是关于大数据(8s)Spark结构化流的主要内容,如果未能解决你的问题,请参考以下文章