一个基于运气的数据结构,你猜是啥?
Posted why技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一个基于运气的数据结构,你猜是啥?相关的知识,希望对你有一定的参考价值。

排行榜
懂行的老哥一看这个小标题,就知道我要以排行榜作为切入点,去讲 Redis 的 zset 了。
是的,经典面试题,请实现一个排行榜,大部分情况下就是在考验你知不知道 Redis 的 zset 结构,和其对应的操作。
当然了,排行榜我们也可以基于其他的解决方案。比如 mysql。
我曾经就基于 mysql 做过排行榜,一条 sql 就能搞定。但是仅限于数据量比较少,性能要求不高的场景(我当时只有 11 支队伍做排行榜,一分钟刷新一次排行榜)。
对于这种经典的面试八股文,网上一找一大把,所以本文就不去做相关解析了。
说好的只是一个切入点。
如果你不知道具体怎么实现,或者根本就不知道这题在问啥,那一定记得看完本文后要去看看相关的文章。最好自己实操一下。
相信我,八股文,得背,这题会考。
zset 的内部编码
众所周知,Redis 对外提供了五种基本数据类型。但是每一种基本类型的内部编码却是另外一番风景:

其中 list 数据结构,在 Redis 3.2 版本中还提供了 quicklist 的内部编码。不是本文重点,我提一嘴就行,有兴趣的朋友自己去了解一下。
本文主要探讨的是上图中的 zset 数据结构。
zset 的内部编码有两种:ziplist 和 skiplist。

其实你也别觉得这个东西有多神奇。因为对于这种对外一套,对内又是一套的“双标党”其实你已经很熟悉了。
它就是 JDK 的一个集合类,来朋友们,大胆的喊出它的名字:HashMap。
HashMap 除了基础的数组结构之外,还有另外两个数据结构:一个链表,一个红黑树。
这样一联想是不是就觉得也不过如此,心里至少有个底了。
当链表长度大于 8 且数组长度大于 64 的时候, HashMap 中的链表会转红黑数。
对于 zset 也是一样的,一定会有条件触发其内部编码 ziplist 和 skiplist 之间的变化?
这个问题的答案就藏在 redis.conf 文件中,其中有两个配置:

上图中配置的含义是,当有序集合的元素个数小于 zset-max-ziplist-entries 配置的值,且每个元素的值的长度都小于 zset-max-ziplist-value 配置的值时,zset 的内部编码是 ziplist。
反之则用 skiplist。
理论铺垫上了,接下我给大家演示一波。
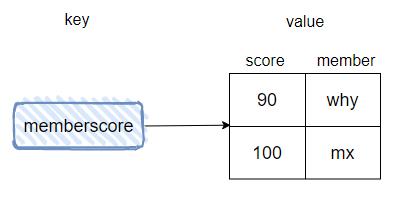
首先,我们给 memberscore 这个有序集合的 key 设置两个值,然后看看其内部编码:

此时有序集合的元素个数是 2,可以看到,内部编码采用的是 ziplist 的结构。
为了大家方便理解这个储存,我给大家画个图:
然后我们需要触发内部编码从 ziplist 到 skiplist 的变化。
先验证 zset-max-ziplist-value 配置,往 memberscore 元素中塞入一个长度大于 64字节(zset-max-ziplist-value默认配置)的值:
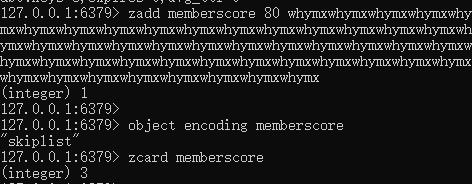
这个时候 key 为 memberscore 的有序集合中有 3 个元素了,其中有一个元素的值特别长,超过了 64 字节。
此时的内部编码采用的是 skiplist。
接下来,我们往 zset 中多塞点值,验证一下元素个数大于 zset-max-ziplist-entries 的情况。
我们搞个新的 key,取值为 whytestkey。
首先,往 whytestkey 中塞两个元素,这是其内部编码还是 ziplist:
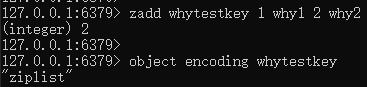
那么问题来了,从配置来看 zset-max-ziplist-entries 128。
这个 128 是等于呢还是大于呢?
没关系,我也不知道,试一下就行了。
现在已经有两个元素了,再追加 126 个元素,看看:
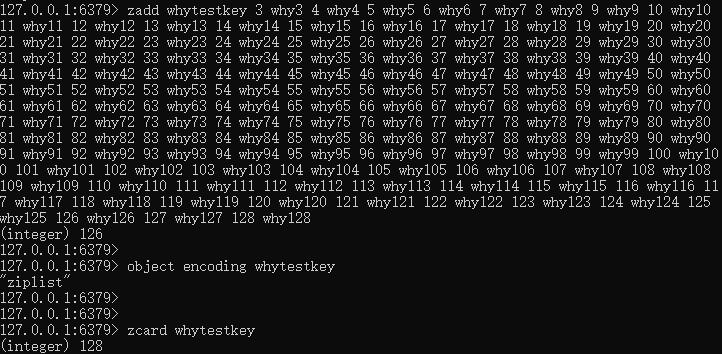
通过实验我们发现,当 whytestkey 中的元素个数是 128 的时候,其内部编码还是 ziplist。
那么触发其从 ziplist 转变为 skiplist 的条件是 元素个数大于 128,我们再加入一个试一试:
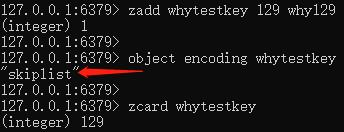
果然,内部编码从 ziplist 转变为了 skiplist。
理论验证完毕,zset 确实是有两幅面孔。
本文主要探讨 skiplist 这个内部编码。
它就是标题说的:基于运气的数据结构。
什么是 skiplist?
这个结构是一个叫做 William Pugh 的哥们在 1990 年发布的一篇叫做《Skip Lists: A Probabilistic Alternative to Balanced Trees》的论文中提出的。
论文地址:ftp://ftp.cs.umd.edu/pub/skipLists/skiplists.pdf
我呢,写文章一般遇到大佬的时候我都习惯性的去网上搜一下大佬长什么样子。也没别的意思。主要是关注一下他们的发量稀疏与否。

在找论文作者的照片之前,我叫他 William 先生,找到之后,我想给他起个“外号”,就叫火男:
他的主页就只放了这一张放荡不羁的照片。然后,我点进了他的 website:

里面提到了他的丰功伟绩。
我一眼瞟去,感兴趣的就是我圈起来的三个地方。
- 第一个是发明跳表。
- 第二个是参与了 JSR-133《Java内存模型和线程规范修订》的工作。
- 第三个是这个哥们在谷歌的时候,学会了吞火。我寻思谷歌真是人才辈出啊,还教这玩意呢?
eat fire,大佬的爱好确实是不一样。
感觉他确实是喜欢玩火,那我就叫他火男吧:

火男的论文摘要里面,是这样的介绍跳表的:

摘要里面说:跳表是一种可以用来代替平衡树的数据结构,跳表使用概率平衡而不是严格的平衡,因此,与平衡树相比,跳表中插入和删除的算法要简单得多,并且速度要快得多。
论文里面,在对跳表算法进行详细描述的地方他是这样说的:

首先火男大佬说,对于一个有序的链表来说,如果我们需要查找某个元素,必须对链表进行遍历。比如他给的示意图的 a 部分。
我单独截取一下:

这个时候,大家还能跟上,对吧。链表查找,逐个遍历是基本操作。
那么,如果这个链表是有序的,我们可以搞一个指针,这个指针指向的是该节点的下下个节点。
意思就是往上抽离一部分节点。
怎么抽离呢,每隔一个节点,就抽一个出来,和上面的 a 示意图比起来,变化就是这样的:

抽离出来有什么好处呢?
假设我们要查询的节点是 25 。
当就是普通有序链表的时候,我们从头节点开始遍历,需要遍历的路径是:
head -> 3 -> 6 -> 7 -> 9 -> 12 -> 17 -> 19 -> 21 -> 25
需要 9 次查询才能找到 25 。
但是当结构稍微一变,变成了 b 示意图的样子之后,查询路径就是:
第二层的 head -> 6 -> 9 -> 17 -> 21 -> 25。
5 次查询就找到了 25 。
这个情况下我们找到指定的元素,不会超过 (n/2)+1 个节点:

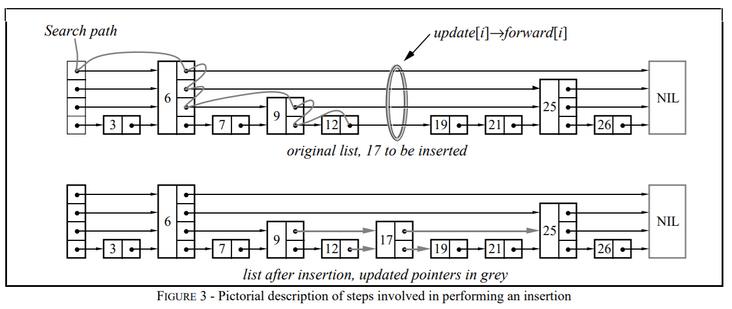
那么这个时候有个小问题就来了:怎么从 21 直接到 25 的呢?
看论文中的图片,稍微有一点不容易明白。
所以,我给大家重新画个示意图:

看到了吗?“多了”一个向下的指针。其实也不是多了,只是论文里面没有明示而已。
所以,查询 25 的路径是这样的,空心箭头指示的方向:

在 21 到 26 节点之间,往下了一层,逻辑也很简单。
21 节点有一个右指针指向 26,先判断右指针的值大于查询的值了。
于是下指针就起到作用了,往下一层,再继续进行右指针的判断。
其实每个节点的判断逻辑都是这样,只是前面的判断结果是进行走右指针。
按照这个往上抽节点的思想,假设我们抽到第四层,也就是论文中的这个示意图:

我们查询 25 的时候,只需要经过 2 次。
第一步就直接跳过了 21 之前的所有元素。
怎么样,爽不爽?

但是,它是有缺陷的。
火男的论文里面是这样说的:

This data structure could be used for fast searching, but insertion and deletion would be impractical.
查询确实飞快。但是对于插入和删除 would be impractical。
impractical 是什么意思?
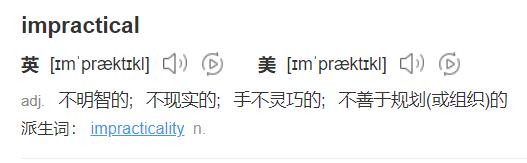
你看,又学一个四级单词。

对于插入和删除几乎是难以实现的。
你想啊,上面那个最底层的有序链表,我一开始就拿出来给你了。
然后我就说基于这个有序链表每隔一个节点抽离到上一层去,再构建一个链表。那么这样上下层节点比例应该是 2:1。巴拉巴拉的.....
但是实际情况应该是我们最开始的时候连这个有序链表都没有,需要自己去创建的。
就假设要在现有的这个跳表结构中插入一个节点,毋庸置疑,肯定是要插入到最底层的有序链表中的。
但是你破坏了上下层 1:2 的比例了呀?
怎么办,一层层的调整呗。
可以,但是请你考虑一下编码实现起来的难度和对应的时间复杂度?
要这样搞,直接就是一波劝退。
这就受不了了?
我还没说删除的事呢。
那怎么办?
看看论文里面怎么说到:

首先我们关注一下第一段划红线的地方。
火男写到:50% 的节点在第一层,25% 的节点在第二层, 12.5% 的节点在第三层。
你以为他在给你说什么?
他要表达的意思除了每一层节点的个数之外,还说明了层级:

没有第 0 层,至少论文里面没有说有第 0 层。
如果你非要说最下面那个有全部节点的有序链表叫做第 0 层,我觉得也可以。但是,我觉得叫它基础链表更加合适一点。
然后我再看第二段划线的地方。
火男提到了一个关键词:randomly,意思是随机。
说出来你可能不信,但是跳表是用随机的方式解决上面提出的插入(删除)之后调整结构的问题。
怎么随机呢?抛硬币。
是的,没有骗你,真的是“抛硬币”。

跳表中的“硬币”
当跳表中插入一个元素的时候,火男表示我们上下层之间可以不严格遵循 1:2 的节点关系。
如果插入的这个元素需要建立索引,那么把索引建立在第几层,都是由抛硬币决定的。
或者说:由抛硬币的概率决定的。
我问你,一个硬币抛出去之后,是正面的概率有多大?
是不是 50%?
如果我们把这个概率记为 p,那么 50%,即 p=1/2。
上面我们提到的概率,到底是怎么用的呢?
火男的论文中有一小节是这样的写的:

随机选择一个层级。他说我们假设概率 p=1/2,然后叫我们看图 5。
图 5 是这样的:

非常关键的一张图啊。
短短几行代码,描述的是如何选择层级的随机算法。
首先定义初始层级为 1(lvl := 1)。
然后有一行注释:random() that returns a random value in [0...1)
random() 返回一个 [0...1) 之间的随机值。
接下来一个 while...do 循环。
循环条件两个。
第一个:random() < p。由于 p = 1/2,那么该条件成立的概率也是 1/2。
如果每随机一次,满足 random() < p,那么层级加一。
那假设你运气爆棚,接连一百次随机出来的数都是小于 p 的怎么办?岂不是层级也到 100 层了?
第二个条件 lvl < MaxLevel,就是防止这种情况的。可以保证算出来的层级不会超过指定的 MaxLevel。
这样看来,虽然每次都是基于概率决定在那个层级,但是总体趋势是趋近于 1/2 的。
带来的好处是,每次插入都是独立的,只需要调整插入前后节点的指针即可。
一次插入就是一次查询加更新的操作,比如下面的这个示意图:
另外对于这个概率,其实火男在论文专门写了一个小标题,还给出了一个图表:

最终得出的结论是,火男建议 p 值取 1/4。如果你主要关心的是执行时间的变化,那么 p 就取值 1/2。
说一下我的理解。首先跳表这个是一个典型的空间换时间的例子。
一个有序的二维数组,查找指定元素,理论上是二分查找最快。而跳表就是在基础的链表上不断的抽节点(或者叫索引),形成新的链表。
所以,当 p=1/2 的时候,就近似于二分查找,查询速度快,但是层数比较高,占的空间就大。
当 p=1/4 的时候,元素升级层数的概率就低,总体层高就低,虽然查询速度慢一点,但是占的空间就小一点。
在 Redis 中 p 的取值就是 0.25,即 1/4,MaxLevel 的取值是 32(视版本而定:有的版本是64)。
论文里面还花了大量的篇幅去推理时间复杂度,有兴趣的可以去看着论文一起推理一下:

跳表在 Java 中的应用
跳表,虽然是一个接触比较少的数据结构。
其实在 java 中也有对应的实现。
先问个问题:Map 家族中大多都是无序的,那么请问你知道有什么 Map 是有序的呢?
TreeMap,LinkedHashMap 是有序的,对吧。
但是它们不是线程安全的。
那么既是线程安全的,又是有序的 Map 是什么?
那就是它,一个存在感也是低的不行的 ConcurrentSkipListMap。
你看它这个名字多吊,又有 list 又有 Map。
看一个测试用例:
`public class MainTest {
public static void main(String[] args) {
ConcurrentSkipListMap<Integer, String> skipListMap = new ConcurrentSkipListMap<>();
skipListMap.put(3,"3");
skipListMap.put(6,"6");
skipListMap.put(7,"7");
skipListMap.put(9,"9");
skipListMap.put(12,"12");
skipListMap.put(17,"17");
skipListMap.put(19,"19");
skipListMap.put(21,"21");
skipListMap.put(25,"25");
skipListMap.put(26,"26");
System.out.println("skipListMap = " + skipListMap);
}
}
`
输出结果是这样的,确实是有序的:

稍微的剖析一下。首先看看它的三个关键结构。
第一个是 index:
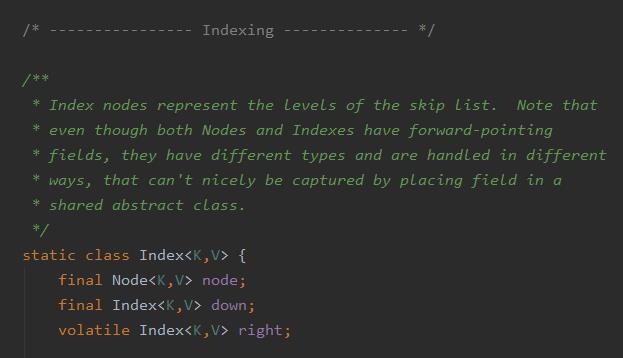
index 里面包含了一个节点 node、一个右指针(right)、一个下指针(down)。
第二个是 HeadIndex:
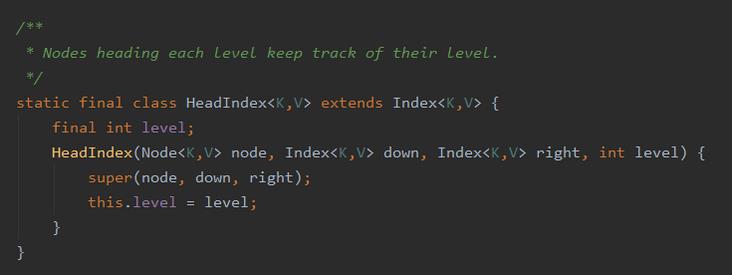
它是继承自 index 的,只是多了一个 level 属性,记录是位于第几层的索引。
第三个是 node:

这个 node 没啥说的,一看就是个链表。
这三者之间的关系就是示意图这样的:

我们就用前面的示例代码,先 debug 一下,把上面的示意图,用真实的值填充上。
debug 跑起来之后,可以看到当前是有两个层级的:
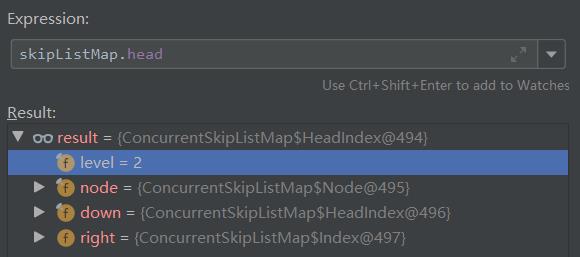
我们先看看第二层的链表是怎样的,也就是看第二层头节点的 right 属性:

所以第二层的链表是这样的:

第二层的 HeadIndex 节点除了我们刚刚分析的 right 属性外,还有一个 down,指向的是下一层,也就是第一层的 HeadIndex:

可以看到第一层的 HeadIndex 的 down 属性是 null。但是它的 right 属性是有值的:
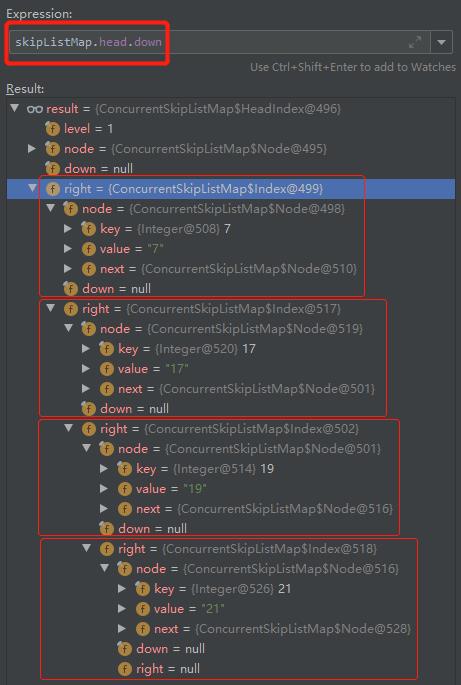
可以画出第一层的链表结构是这样的:

同时我们可以看到其 node 属性里面其实是整个有序链表(其实每一层的 HeadIndex 里面都有):

所以,整个跳表结构是这样的:

但是当你拿着同样的程序,自己去调试的时候,你会发现,你的跳表不长这样啊?
当然不一样了,一样了才是撞了鬼了。
别忘了,索引的层级是随机产生的。
ConcurrentSkipListMap 是怎样随机的呢?
带大家看看 put 部分的源码。

标号为 ① 的地方代码很多,但是核心思想是把指定元素维护进最底层的有序链表中。就不进行解读了,所以我把这块代码折叠起来了。
标号为 ② 的地方是 (rnd & 0x80000001) == 0。
这个 rnd 是上一行代码随机出来的值。
而 0x80000001 对应的二进制是这样的:

一头一尾都是1,其他位都是 0。
那么只有 rnd 的一头一尾都是 0 的时候,才会满足 if 条件,(rnd & 0x80000001) == 0。
二进制的一头一尾都是 0,说明是一个正偶数。
随机出来一个正偶数的时候,表明需要对其进行索引的维护。
标号为 ③ 的地方是判断当前元素要维护到第几层索引中。
((rnd >>>= 1) & 1) != 0 ,已知 rnd 是一个正偶数,那么从其二进制的低位的第二位(第一位肯定是0嘛)开始,有几个连续的 1,就维护到第几层。
不明白?没关系,我举个例子。
假设随机出来的正偶数是 110,其二进制是 01101110。因为有 3 个连续的 1,那么 level 就是从 1 连续自增 3 次,最终的 level 就是 4。
那么问题就来了,如果我们当前最多只有 2 层索引呢?直接就把索引干到第 4 层吗?
这个时候标号为 ④ 的代码的作用就出来了。
如果新增的层数大于现有的层数,那么只是在现有的层数上进行加一。
这个时候我们再回过头去看看火男论文里面的随机算法:

所以,你现在知道了,由于有随机数的出现,所以即使是相同的参数,每次都可以构建出不一样的跳表结构。
比如还是前面演示的代码,我 debug 截图的时候有两层索引。
但是,其实有的时候我也会碰到 3 层索引的情况。
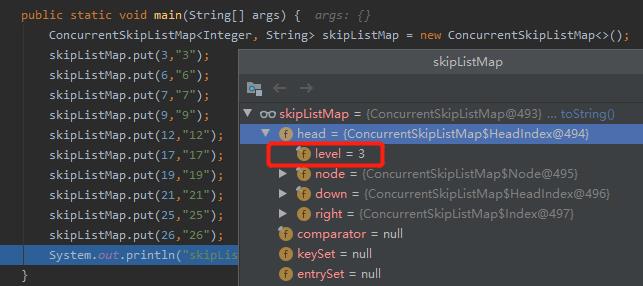
别问为什么,用心去感受,你心里应该有数。

另外,开篇用 redis 做为了切入点,其实 redis 的跳表整体思想是大同的,但是也是有小异的。
比如 Redis 在 skiplist 的 forward 指针(相当于 index)上,每个 forward 指针都增加了 span 属性。
在《Redis深度历险》一书里面对该属性进行了描述:

最后说一句(求关注)
好了,那么这次的文章就到这里啦。
才疏学浅,难免会有纰漏,如果你发现了错误的地方,可以提出来,我对其加以修改。 感谢您的阅读,我坚持原创,十分欢迎并感谢您的关注。

我是 why,一个被代码耽误的文学创作者,不是大佬,但是喜欢分享,是一个又暖又有料的四川好男人。
欢迎关注我呀。

以上是关于一个基于运气的数据结构,你猜是啥?的主要内容,如果未能解决你的问题,请参考以下文章