论文解读F-PointNet 使用RGB图像和Depth点云深度 数据的3D目标检测
Posted 一颗小树x
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文解读F-PointNet 使用RGB图像和Depth点云深度 数据的3D目标检测相关的知识,希望对你有一定的参考价值。
前言
F-PointNet 提出了直接处理点云数据的方案,但这种方式面临着挑战,比如:如何有效地在三维空间中定位目标的可能位置,即如何产生 3D 候选框,假如全局搜索将会耗费大量算力与时间。
F-PointNet是在进行点云处理之前,先使用图像信息得到一些先验搜索范围,这样既能提高效率,又能增加准确率。
论文地址:Frustum PointNets for 3D Object Detection from RGB-D Data
开源代码:https://github.com/charlesq34/frustum-pointnets
目录
一、基本思路
首先使用在 RGB 图像上运行的 2D 检测器,其中每个2D边界框定义一个3D锥体区域。然后基于这些视锥区域中的 3D 点云,我们使用 PointNet/PointNet++ 网络实现了 3D实例分割和非模态 3D 边界框估计。总结一下思路,如下:
- 基于图像2D目标检测。
- 基于图像生成锥体区域。
- 在锥体内,使用 PointNet/PointNet++ 网络进行点云实例分割。
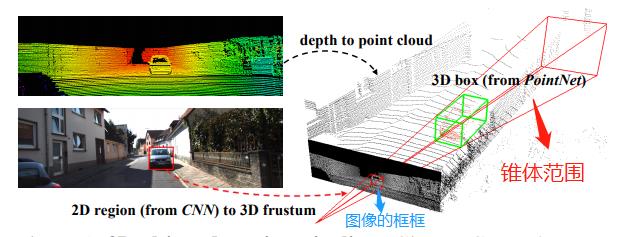
它是在进行点云处理之前,先使用图像信息得到一些先验搜索范围,这样既能提高效率,又能增加准确率。先看看下面这张图:
在这张图里,左上角的意思是先把图像和点云信息标定好(这个属于传感器的外参标定,在感知之前进行;获取两个传感器之间旋转矩阵和平移向量,就可以得到相互的位置关系)。
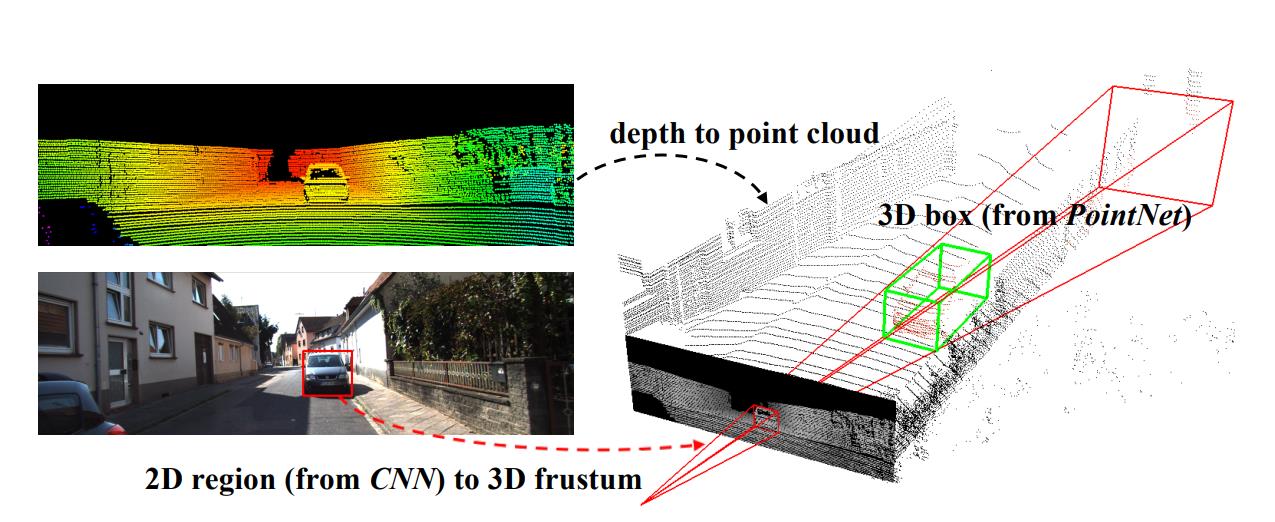
左下角是用目标检测算法检测出物体的边界框(BoundingBox),有了边界框之后,以相机为原点,沿边界框方向延伸过去就会形成一个锥体(上图的右半部分),该论文题目里frustum这个词就是锥体的意思。
然后用点云对该物体进行识别的时候,只需要在这个锥体内识别就行了,大大减小了搜索范围。
二、模型框架
模型结构如下:(可以点击图片放大查看)
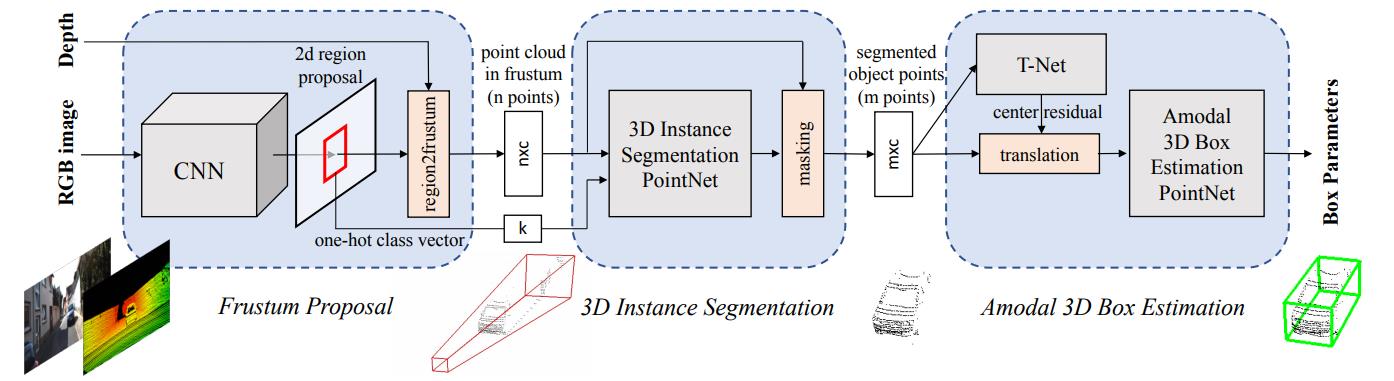
网络共分为三部分,第一部分是使用图像进行目标检测并生成锥体区域,第二部分是在锥体内的点云实例分割,第三部分是点云物体边界框的回归。
三、基于图像生成锥体区域
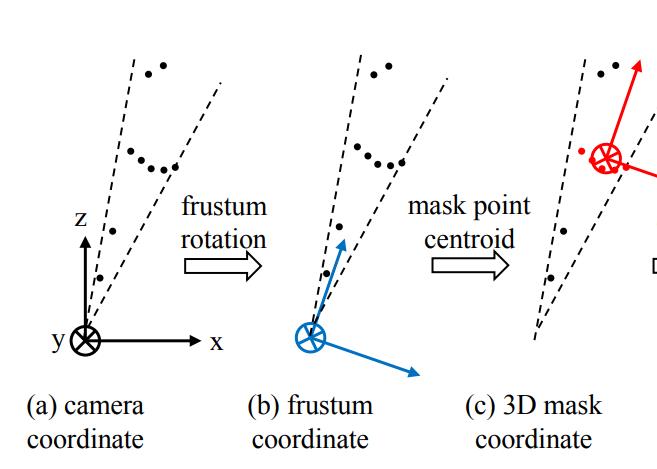
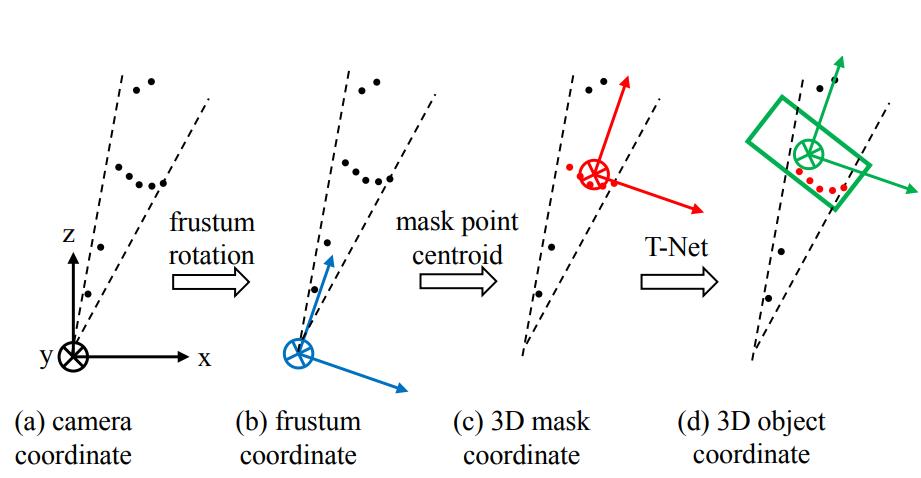
由于检测到的目标不一定在图像的正中心,所以生成的锥体的轴心就不一定和相机的坐标轴重合,如下图中(a)所示。为了使网络具有更好的旋转不变性,我们需要做一次旋转,使相机的Z轴和锥体的轴心重合。如下图中(b)所示。

四、 在锥体内进行点云实例分割
实例分割使用PointNet。一个锥体内只提取一个物体,因为这个锥体是图像中的边界框产生的,一个边界框内也只有一个完整物体。
在生成锥体的时候提到了旋转不变性,此处完成分割这一步之后,还需要考虑平移不变性,因为点云分割之后,分割的物体的原点和相机的原点必不重合,而我们处理的对象是点云,所以应该把原点平移到物体中去,如下图中(c)所示。
五、生成精确边界框
生成精确边界框的网络结构:
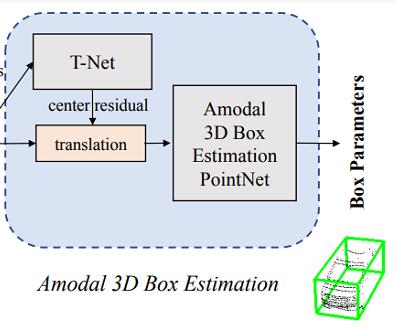
从这个结构里可以看出,在生成边界框之前,需要经过一个T-Net,这个东西的作用是生成一个平移量,之所以要做这一步,是因为在上一步得到的物体中心并不完全准确,所以为了更精确地估计边界框,在此处对物体的质心做进一步的调整,如下图中(d)所示。
下面就是边界框回归了,对一个边界框来讲,一共有七个参数,包括:
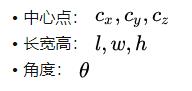
最后总的残差就是以上目标检测、T-Net和边界框残差之和,可以据此构建损失函数。
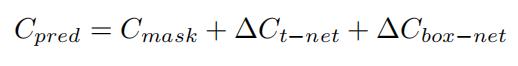
六、PointNet关键点
6.1 F-PointNet使用2D RGB图像
原因是
- 当时基于纯3D点云数据的3D目标检测对小目标检测效果不佳。所以F-PointNet先基于2D RGB做2D的目标检测来定位目标,再基于2d目标检测结果用其对应的点云数据视锥进行bbox回归的方法来实现3D目标检测。
- 使用纯3D的点云数据,计算量也会特别大,效率也是这个方法的优点之一。
使用成熟的2D CNN目标检测器(Mask RCNN)生成2D检测框,并输出one-hot 分类向量(即基于2D RGB图像的分类)。
6.2 锥体框生成
2D检测框结合深度信息,找到最近和最远的包含检测框的平面来定义3D视锥区域frustum proposal。然后在该frustum proposal里收集所有的3D点来组成视锥点云(frustum point cloud)。
七、实验结果
与其他模型对比:

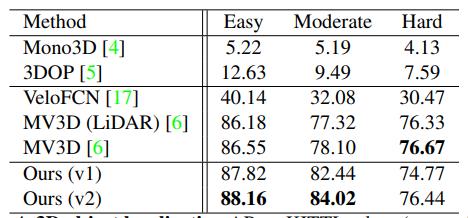
模型效果:

八、优点
(1)舍弃了global fusion,提高了检测效率;并且通过2D detector和3D Instance Segmentation PointNet对3D proposal实现了逐维(2D-3D)的精准定位,大大缩短了对点云的搜索时间。下图是通过3d instance segmentation将搜索范围从9m~55m缩减到12m~16m。

(2)相比于在BEV(Bird's Eye view)中进行3D detection,F-PointNet直接处理raw point cloud,没有任何维度的信息损失,使用PointNet能够学习更全面的空间几何信息,特别是在小物体的检测上有很好的表现。下图是来自Hao Su 2018年初的课程,现在的KITTI榜有细微的变动。
(3)利用成熟的2D detector对proposal进行分类(one-hot class vector,打标签),起到了一定的指导作用,能够大大降低PointNet对三维空间物体的学习难度。
九、模型代码
开源代码:https://github.com/charlesq34/frustum-pointnets
作者代码的运行环境:
系统:Ubuntu 14.04 或 Ubuntu 16.04
深度框架:TensorFlow1.2(GPU 版本)或 TensorFlow1.4(GPU 版本)
其他依赖库:cv2、mayavi等。
代码支持 Frustum PointNets 模型的训练和测试,以及基于预先计算的 2D 检测器输出(kitti/rgb_detections)评估 3D 目标检测结果。
参考:https://blog.csdn.net/congxing9333/article/details/109710411
https://zhuanlan.zhihu.com/p/87283846、https://www.codenong.com/cs105519981/

论文地址:Frustum PointNets for 3D Object Detection from RGB-D Data
开源代码:https://github.com/charlesq34/frustum-pointnets
本文只提供参考学习,谢谢。
以上是关于论文解读F-PointNet 使用RGB图像和Depth点云深度 数据的3D目标检测的主要内容,如果未能解决你的问题,请参考以下文章
论文解读 | F-PointNet, 使用RGB图像和Depth点云深度, 数据的3D目标检测
论文解读 | F-PointNet, 使用RGB图像和Depth点云深度, 数据的3D目标检测