潜在语义分析(Latent Semantic Analysis)
Posted Data+Science+Insight
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了潜在语义分析(Latent Semantic Analysis)相关的知识,希望对你有一定的参考价值。
潜在语义分析(Latent Semantic Analysis)
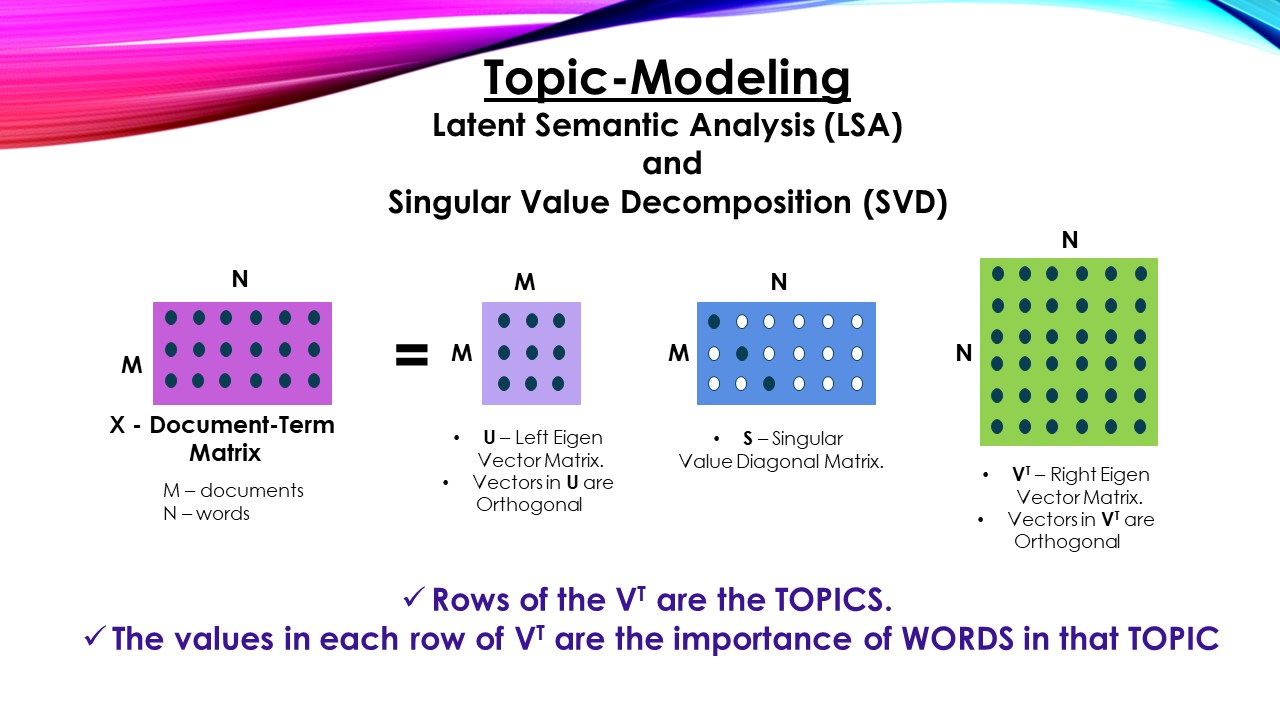
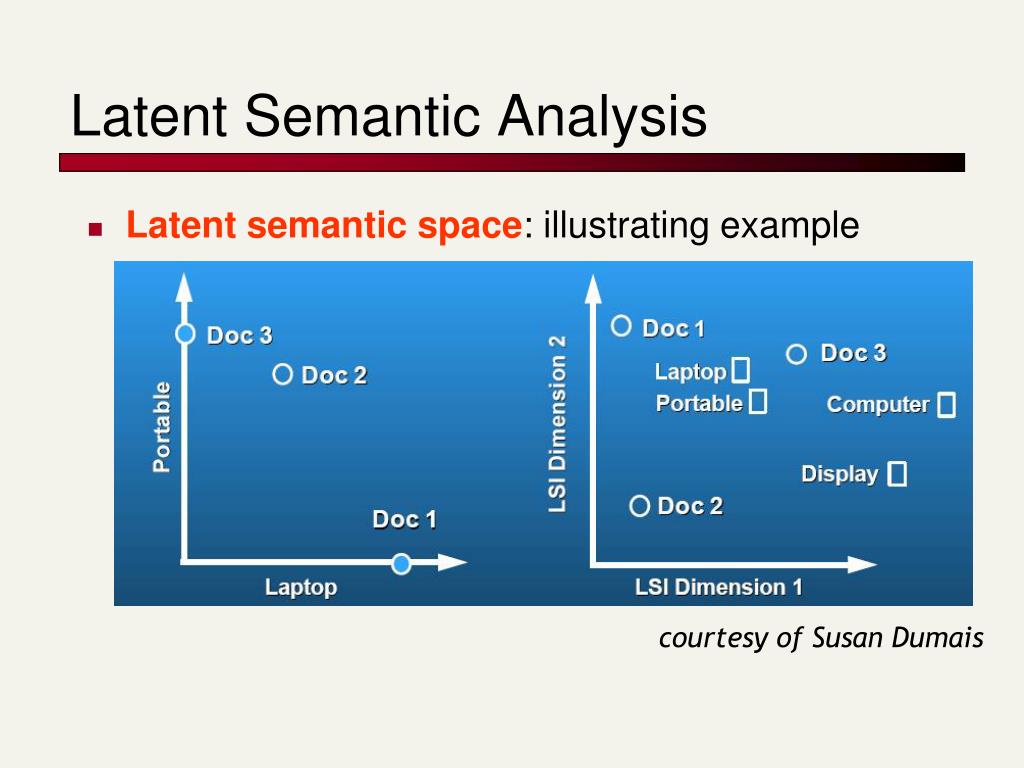
潜在语义分析(Latent Semantic Analysis, LSA)是自然语言处理中的一种方法或技术。潜在语义分析(LSA)的主要目标是为文本创建基于向量的表示,从而生成语义内容。通过向量表示(LSA)计算文本之间的相似度,选择有效相关词。在早期的许多技术文献中LSA模型被称为潜在语义索引LSI模型,但在信息检索任务中得到了改进。因此,查找接近查询的少数文档是从许多文档中选择的。LSA需要考虑关键字匹配、关键字数量匹配和基于单词在文档中出现次数的向量表示等方面。潜在语义分析(LSA)使用奇异值分解(SVD)重新排列数据。
奇异值分解(Singular Value Decomposition,SVD)是一种利用矩阵重新配置和计算向量空间所有极小值的方法。此外,向量空间中的极小值将从最重要到最不重要进行计算和组织。在LSA中,将使用最重要的假设来查找文本的意义,最不重要的将在假设中被忽略。通过搜索具有高相似率的单词,如果这些单词有相似的向量就会出现。描述LSA中最基本的步骤是,首先收集大量的相关文本,然后对其进行文档划分。然后为术语和文档制作共现矩阵,并提及单元名称,如文档x,术语y和m的维度值,术语n维向量的元。之后每个单元将被磨平和计算。最后,SVD将发挥重要作用,计算所有的减项并生成三个矩阵。
以上是关于潜在语义分析(Latent Semantic Analysis)的主要内容,如果未能解决你的问题,请参考以下文章