主题模型简介(Topic Models)
Posted Data+Science+Insight
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了主题模型简介(Topic Models)相关的知识,希望对你有一定的参考价值。
主题模型简介(Topic Models)
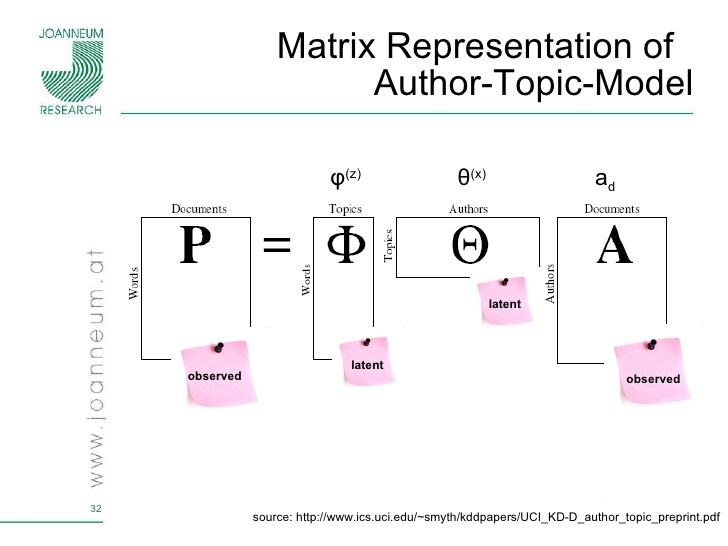
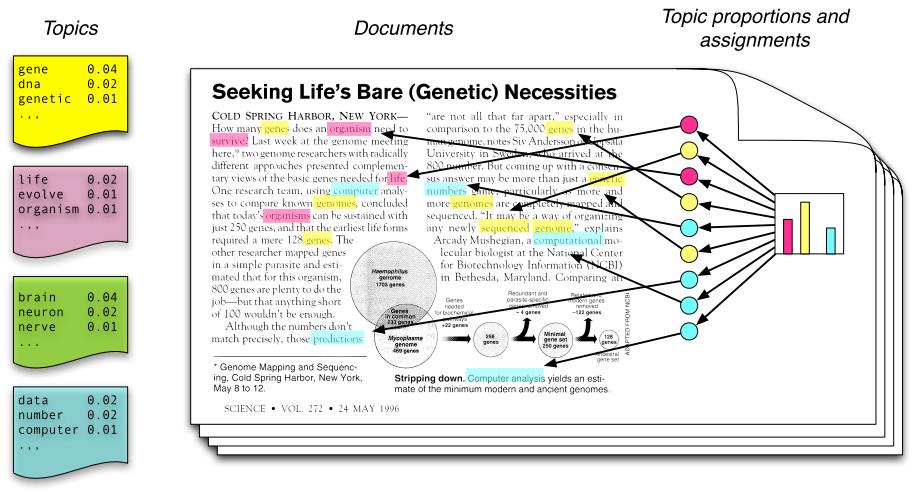
要想更好地管理当今爆炸式的电子文档档案,需要使用新的技术或工具来处理自动组织、搜索、索引和浏览大型电子文档集合。在当今机器学习和统计学研究的基础上,利用层次概率模型在文档集合中发现单词模式的新技术被开发出来。这些模型叫做“主题模型”。模式的发现往往反映了潜在的主题,这些主题被联合起来形成文档,例如分层概率模型很容易被推广到其他类型的数据中;主题模型被用来分析文字之外的很多东西例如图像、生物数据、测量信息和数据。
主题建模的核心在于发现单词使用的模式和关联具有相同模式的文档。所以,主题模型的思想是可以与文档一起工作的术语,而这些文档是主题的混合体,其中主题是单词上的概率分布。换言之,主题模型是文档的生成模型。它指定了一个生成文档的简单概率过程。通过选择一种主题分布来创建一个新的文档。随后,文档中的每个单词都可以根据分布随机选择一个主题。然后从主题中抽取一个单词。
主题建模始于一种称为潜在语义分析(LSA)的线性代数方法:找到文档术语矩阵的最佳低秩近似。虽然这些方法在最近几年重新兴起,但我们将重点放在概率方法上,它是直观的、工作良好的,并且很容易扩展(正如我们在后面的许多章节中看到的那样)。
以上是关于主题模型简介(Topic Models)的主要内容,如果未能解决你的问题,请参考以下文章
词袋模型(bag of words)构建并使用主题模型(topic models)特征进行文本聚类分析(clustering analysis)实战