sklearn RandomForest(随机森林)模型使用RandomSearchCV获取最优参数及模型效能可视化
Posted Data+Science+Insight
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了sklearn RandomForest(随机森林)模型使用RandomSearchCV获取最优参数及模型效能可视化相关的知识,希望对你有一定的参考价值。
sklearn RandomForest(随机森林)模型使用RandomSearchCV获取最优参数及模型效能可视化
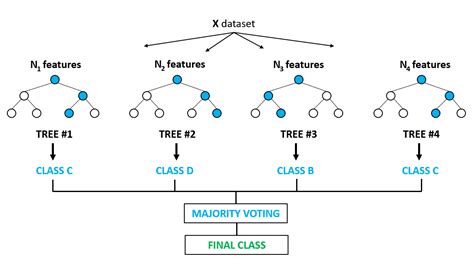
随机森林顾名思义,是用随机的方式建立一个森林,森林里面有很多的决策树组成,随机森林的每一棵决策树之间是没有关联的。在得到森林之后,当有一个新的输入样本进入的时候,就让森林中的每一棵决策树分别进行一下判断,看看这个样本应该属于哪一类(对于分类算法),然后看看哪一类被选择最多,就预测这个样本为那一类。随机森林可以既可以处理属性为离散值的量,比如ID3算法,也可以处理属性为连续值的量,比如C4.5算法。另外,随机森林还可以用来进行无监督学习聚类和异常点检测。
决策树(decision tree)是一个树结构(可以是二叉树或非二叉树)。其每个非叶节点表示一个特征属性上的测试,每个分支代表这个特征属性在某个值域上的输出,而每个叶节点存放一个类别。使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节点,将叶子节点存放的类别作为决策结果。
随机森林由决策树组成,决策树实际上是将空间用超平面进行划分的一种方法,每次分割的时候,都将当前的空间一分为二。
#
以上是关于sklearn RandomForest(随机森林)模型使用RandomSearchCV获取最优参数及模型效能可视化的主要内容,如果未能解决你的问题,请参考以下文章