大数据数据倾斜问题与企业级解决方案
Posted 赵广陆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据数据倾斜问题与企业级解决方案相关的知识,希望对你有一定的参考价值。
1 数据倾斜问题
在实际工作中,如果我们想提高MapReduce的执行效率,最直接的方法是什么呢?
我们知道MapReduce是分为Map阶段和Reduce阶段,其实提高执行效率就是提高这两个阶段的执行效 率默认情况下Map阶段中Map任务的个数是和数据的InputSplit相关的,InputSplit的个数一般是和Block块 是有关联的,所以可以认为Map任务的个数和数据的block块个数有关系,针对Map任务的个数我们一般
是不需要干预的,除非是前面我们说的海量小文件,那个时候可以考虑把小文件合并成大文件。其他情况是不需要调整的,
那就剩下Reduce阶段了,咱们前面说过,默认情况下reduce的个数是1个,所以现在MapReduce任务的 压力就集中在Reduce阶段了,如果说数据量比较大的时候,一个reduce任务处理起来肯定是比较慢的,
所以我们可以考虑增加reduce任务的个数,这样就可以实现数据分流了,提高计算效率了。
但是注意了,如果增加Reduce的个数,那肯定是要对数据进行分区的,分区之后,每一个分区的数据会
被一个reduce任务处理。
那如何增加分区呢?
我们来看一下代码,进入WordCountJob中,
其实我们可以通过 job.setPartitionerClass 来设置分区类,不过目前我们是没有设置的,那框架中是不 是有默认值啊,是有的,我们可以通过 job.getPartitionerClass 方法看到默认情况下会使用 HashParti tioner 这个分区类
那我们来看一下HashPartitioner的实现是什么样子的
/** Partition keys by their {@link Object#hashCode()}. */
@InterfaceAudience.Public
@InterfaceStability.Stable
public class HashPartitioner<K, V> extends Partitioner<K, V> {
/** Use {@link Object#hashCode()} to partition. */
public int getPartition(K key, V value,
int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}
HashPartitioner继承了Partitioner,这里面其实就一个方法, getPartition ,其实map里面每一条数据
都会进入这个方法来获取他们所在的分区信息,这里的key就是k2,value就是v2
主要看里面的实现
(key.hashCode() & Integer.MAX_VALUE) % numReduceTasks 1
其实起决定性的因素就是 numReduceTasks 的值,这个值默认是1,通过 job.getNumReduceTasks() 可知。
所以最终任何值%1 都返回0,那也就意味着他们都在0号分区,也就只有这一个分区。
如果想要多个分区,很简单,只需要把 numReduceTasks 的数目调大即可,这个其实就是reduce任务的数 量,那也就意味着,只要redcue任务数量变大了,对应的分区数也就变多了,有多少个分区就会有多少个reduce任务,那我们就不需要单独增加分区的数量了,只需要控制好Redcue任务的数量即可。
增加redcue任务个数在一定场景下是可以提高效率的,但是在一些特殊场景下单纯增加reduce任务个数
是无法达到质的提升的。
下面我们来分析一个场景:
假设我们有一个文件,有1000W条数据,这里面的值主要都是数字,1,2,3,4,5,6,7,8,9,10,我们希望统计出来每个数字出现的次数其实在私底下我们是知道这份数据的大致情况的,这里面这1000w条数据,值为5的数据有910w条左 右,剩下的9个数字一共只有90w条,那也就意味着,这份数据中,值为5的数据比较集中,或者说值为5的数据属于倾斜的数据,在这一整份数据中,它占得比重比其他的数据多得多。
下面我们画图来具体分析一下:
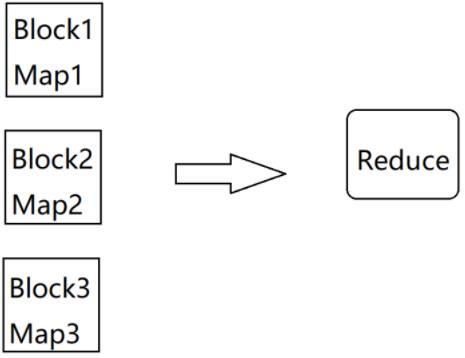
假设这1000W条数据的文件有3个block,会产生3个InputSplt,最终会产生3个Map任务,默认情况下只 有一个reduce任务,所以所有的数据都会让这一个reduce任务处理,这样这个Reduce压力肯定很大,大
量的时间都消耗在了这里
那根据我们前面的分析,我们可以增加reduce任务的数量,看下面这张图,我们把reduce任务的数量调 整到10个,这个时候就会把1000w条数据让这10 个reduce任务并行处理了,这个时候效率肯定会有一定
的提升,但是最后我们会发现,性能提升是有限的,并没有达到质的提升,那这是为什么呢?
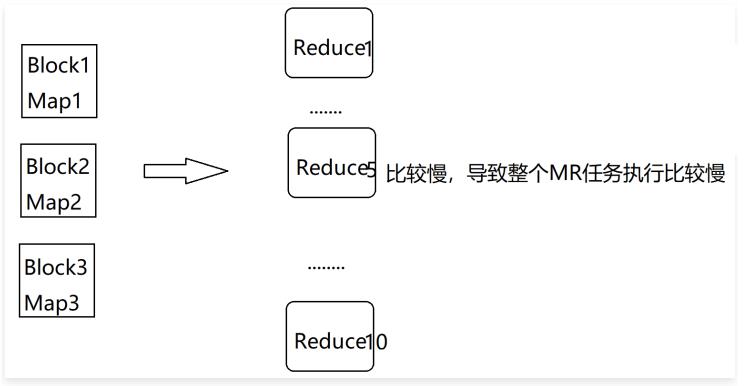
我们来分析一下,刚才我们说了我们这份数据中,值为5的数据有910w条,这就占了整份数据的90%
了,那这90%的数据会被一个reduce任务处理,在这里假设是让reduce5处理了,reduce5这个任务执行 的是比较慢的,其他reduce任务都执行结束很长时间了,它还没执行结束,因为reduce5中处理的数据 量和其他reduce中处理的数据量规模相差太大了,所以最终reduce5拖了后腿。咱们mapreduce任务执 行消耗的时间是一直统计到最后一个执行结束的reduce任务,所以就算其他reduce任务早都执行结束了
也没有用,整个mapreduce任务是没有执行结束的。
那针对这种情况怎么办?
这个时候单纯的增加reduce任务的个数已经不起多大作用了,如果启动太多可能还会适得其反。
其实这个时候最好的办法是把这个值为5的数据尽量打散,把这个倾斜的数据分配到其他reduce任务中去
计算,这样才能从根本上解决问题。
这就是我们要分析的一个数据倾斜的问题
MapReduce程序执行时,Reduce节点大部分执行完毕,但是有一个或者几个Reduce节点运行很慢,导
致整个程序处理时间变得很长具体表现为:Ruduce阶段一直卡着不动根据刚才的分析,有两种方案
- 增加reduce任务个数,这个属于治标不治本,针对倾斜不是太严重的数据是可以解决问题的,针对
倾斜严重的数据,这样是解决不了根本问题的 - 把倾斜的数据打散
这种可以根治倾斜严重的数据。
现在呢我们通过理论层面分析完了,那接下来我们来具体进入一个实际案例上手操作一下还使用我们刚才说的那一份数据,1000w条的,其中值为5的大致有910w条左右
其他的加起来一共90万条左右。
这个数据文件我已经生成好了,直接上传到linux服务器上就可以,上传到/data/soft目录下
[root@bigdata01 soft]# ll
total 2632200
drwxr-xr-x. 9 1001 1002 244 Apr 26 20:34 hadoop-3.2.0
-rw-r--r--. 1 root root 345625475 Jul 19 2019 hadoop-3.2.0.tar.gz
-rw-r--r--. 1 root root 1860100000 Apr 27 21:58 hello_10000000.dat
drwxr-xr-x. 7 10 143 245 Dec 16 2018 jdk1.8
-rw-r--r--. 1 root root 194042837 Apr 6 23:14 jdk-8u202-linux-x64.tar.gz
-rw-r--r--. 1 root root 147616384 Apr 27 16:22 s_name_140.dat
-rw-r--r--. 1 root root 147976384 Apr 27 16:22 s_name_141.dat
这个文件有点大,在windows本地无法打开,在这里我们去一条数据看一下数据格式,前面是一个数
字,后面是一行日志,这个数据是我自己造的,我们主要是使用前面的这个数字,后面的内容主要是为了
充数的,要不然文件太小,测试不出来效果。后面我们解析数据的时候只获取前面这个数字即可,前面这
个数字是1-10之间的数字
[root@bigdata01 soft]# tail -1 hello_10000000.dat
10 INFO main org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter: FileO
接下来把这个文件上传到hdfs上
[root@bigdata01 soft]# hdfs dfs -put hello_10000000.dat /
[root@bigdata01 soft]# hdfs dfs -ls /
-rw-r--r-- 2 root supergroup 1860100000 2020-04-27 22:01 /hello_10000000.d
下面我们来具体跑一个这份数据,首先复制一份WordCountJob的代码,新的类名为 WordCountJobSkew
package com.oldlu.mr;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.IOException;
/**
* 数据倾斜-增加Reduce任务个数
* <p>
* Created by admin
*/
public class WordCountJobSkew {
/**
* Map阶段
*/
public static class MyMapper extends Mapper<LongWritable, Text, Text, LongW
Logger logger =LoggerFactory.getLogger(MyMapper .class);
/**
* 需要实现map函数
* 这个map函数就是可以接收<k1,v1>,产生<k2,v2>
*
* @param k1
* @param v1
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable k1, Text v1, Context context)
throws IOException, InterruptedException {
//输出k1,v1的值
//System.out.println("<k1,v1>=<"+k1.get()+","+v1.toString()+">");
//logger.info("<k1,v1>=<"+k1.get()+","+v1.toString()+">");
//k1 代表的是每一行数据的行首偏移量,v1代表的是每一行内容
//对获取到的每一行数据进行切割,把单词切割出来
String[] words = v1.toString().split(" ");
//把单词封装成<k2,v2>的形式
Text k2 = new Text(words[0]);
LongWritable v2 = new LongWritable(1L);
//把<k2,v2>写出去
context.write(k2, v2);
}
}
/**
* Reduce阶段
*/
public static class MyReducer extends Reducer<Text, LongWritable, Text, LongW
Logger logger =LoggerFactory.getLogger(MyReducer.class);
/**
* @param k2
* @param v2s
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(Text k2,Iterable<LongWritable> v2s,Context co
throws IOException,InterruptedException{
//创建一个sum变量,保存v2s的和
long sum=0L;
//对v2s中的数据进行累加求和
for(LongWritable v2:v2s){
//输出k2,v2的值
//System.out.println("<k2,v2>=<"+k2.toString()+","+v2.get()+"
//logger.info("<k2,v2>=<"+k2.toString()+","+v2.get()+">");
sum+=v2.get();
//模拟Reduce的复杂计算消耗的时间
if(sum%200==0){
Thread.sleep(1);
}
}
//组装k3,v3
Text k3=k2;
LongWritable v3=new LongWritable(sum);
//输出k3,v3的值
//System.out.println("<k3,v3>=<"+k3.toString()+","+v3.get()+">");
//logger.info("<k3,v3>=<"+k3.toString()+","+v3.get()+">");
// 把结果写出去
context.write(k3,v3);
}
}
/**
* 组装Job=Map+Reduce
*/
public static void main(String[]args){
try{
if(args.length!=3){
//如果传递的参数不够,程序直接退出
System.exit(100);
}
//指定Job需要的配置参数
Configuration conf=new Configuration();
//创建一个Job
Job job=Job.getInstance(conf);
//注意了:这一行必须设置,否则在集群中执行的时候是找不到WordCountJob这个
job.setJarByClass(WordCountJobSkew.class);
//指定输入路径(可以是文件,也可以是目录)
FileInputFormat.setInputPaths(job,new Path(args[0]));
//指定输出路径(只能指定一个不存在的目录)
FileOutputFormat.setOutputPath(job,new Path(args[1]));
//指定map相关的代码
job.setMapperClass(MyMapper.class);
//指定k2的类型
job.setMapOutputKeyClass(Text.class);
//指定v2的类型
//指定reduce相关的代码
job.setReducerClass(MyReducer.class);
//指定k3的类型
job.setOutputKeyClass(Text.class);
//指定v3的类型
job.setOutputValueClass(LongWritable.class);
//设置reduce任务个数
job.setNumReduceTasks(Integer.parseInt(args[2]));
//提交job
job.waitForCompletion(true);
}catch(Exception e){
e.printStackTrace();
}
}
}
.对项目代码进行重新编译、打包,提交到集群去执行
第一次先使用一个reduce任务执行
[root@bigdata01 hadoop-3.2.0]# hadoop jar db_hadoop-1.0-SNAPSHOT-jar-with-dep
查看结果
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -cat /out10000000/*
1 100000
2 100000
3 100000
4 100000
5 9100000
6 100000
7 100000
8 100000
10 100000
9 100000
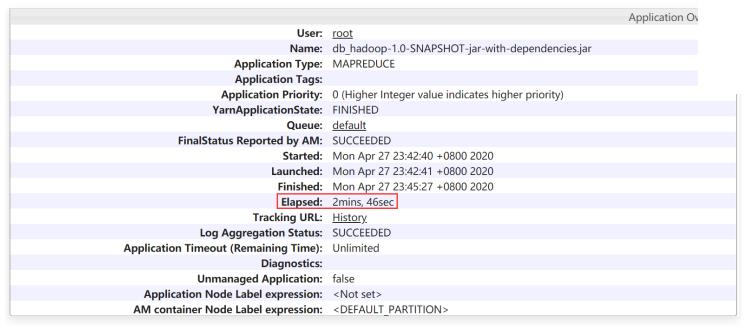
然后我们再到yarn的web界面查看任务的执行情况
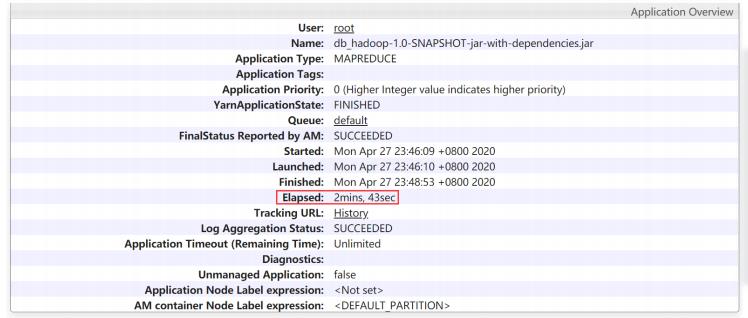
任务总的执行消耗时间为: Elapsed: 2mins, 46sec
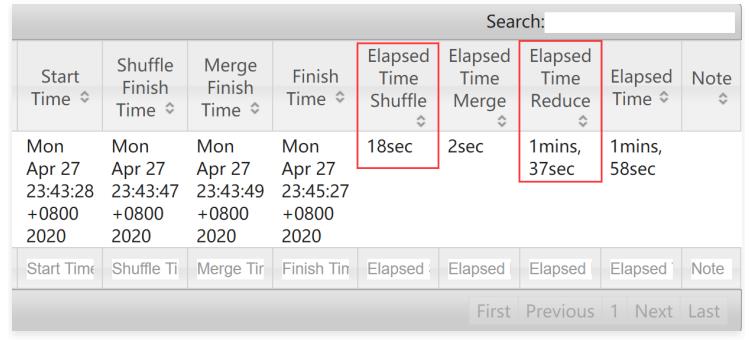
具体分析Reduce任务的执行时间
Shuffle执行的时间为18秒,Reduce执行的时间为1分37秒
接下来增加reduce任务的数量,增加到10个
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -rm -r /out10000000
[root@bigdata01 hadoop-3.2.0]# hadoop jar db_hadoop-1.0-SNAPSHOT-jar-with-dep
任务总的执行消耗时间为: Elapsed: 2mins, 43sec
仅提升了3秒,所以从这可以看出来,性能提升并不大
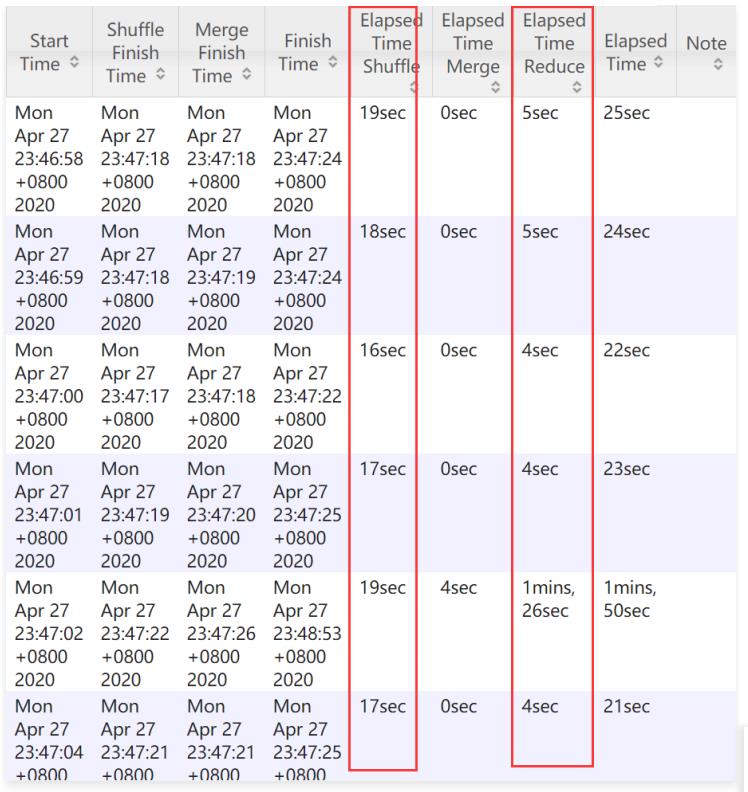
具体分析Reduce任务的执行时间
这里由于有10个reduce,所以一共有10行,在这我们截取了一部分,其中这里面有一个reduce任务消耗 的时间比较长,其他reduce任务的执行时间都是4~5秒,这个reduce任务的执行时间是1分26秒,那就意
味着值为5的那910w数据进入到这个reduce了,所以它执行的比较慢。
那我们再把reduce任务的个数提高一下,会不会提高性能呢?不会了,刚才从1个reduce任务提高到10
个reduce任务时间也就减少了三四秒钟,所以再增加reduce任务的个数就没有多大意义了。
那接下来就需要使用我们的绝招了,把倾斜的数据打散,在这里就是把5这个数字打散,
怎么打散呢?其实就是给他加上一些有规律的随机数字就可以了
在这里我们这样处理,我把5这个数值的数据再分成10份,所以我就在这个数值5后面拼上一个0~9的随
机数即可。
针对这个操作我们需要去修改代码,在这里我们再重新复制一个类,基于WordCountJobSkew复制,新
的类名是 WordCountJobSkewRandKey
package com.oldlu.mr;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.IOException;
import java.util.Random;
*
*Created by admin
*/
public class WordCountJobSkewRandKey {
/**
* Map阶段
*/
public static class MyMapper extends Mapper<LongWritable, Text, Text, LongW
Logger logger =LoggerFactory.getLogger(MyMapper .class);
Random random = new Random();
/**
* 需要实现map函数
* 这个map函数就是可以接收<k1,v1>,产生<k2,v2>
*
* @param k1
* @param v1
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void map(LongWritable k1, Text v1, Context context)
throws IOException, InterruptedException {
//输出k1,v1的值
//System.out.println("<k1,v1>=<"+k1.get()+","+v1.toString()+">");
//logger.info("<k1,v1>=<"+k1.get()+","+v1.toString()+">");
//k1 代表的是每一行数据的行首偏移量,v1代表的是每一行内容
//对获取到的每一行数据进行切割,把单词切割出来
String[] words = v1.toString().split(" ");
//把单词封装成<k2,v2>的形式
String key = words[0];
if ("5".equals(key)) {
//把倾斜的key打散,分成10份
key = "5" + "_" + random.nextInt(10);
}
Text k2 = new Text(key);
LongWritable v2 = new LongWritable(1L);
//把<k2,v2>写出去
context.write(k2, v2);
}
}
/**
* Reduce阶段
*/
public static class MyReducer extends Reducer<Text, LongWritable, Text, LongW
Logger logger =LoggerFactory.getLogger(MyReducer.class);
/**
* 针对<k2,{v2...}>的数据进行累加求和,并且最终把数据转化为k3,v3写出去
*
* @param k2
* @param v2s
* @param context
* @throws IOException
* @throws InterruptedException
*/
@Override
protected void reduce(Text k2,Iterable<LongWritable> v2s,Context co
throws IOException,InterruptedException{
//创建一个sum变量,保存v2s的和
long sum=0L;
//对v2s中的数据进行累加求和
for(LongWritable v2:v2s){
//输出k2,v2的值
sum+=v2.get();
//模拟Reduce的复杂计算消耗的时间
if(sum%200==0){
Thread.sleep(1);
}
}
//组装k3,v3
Text k3=k2;
LongWritable v3=new LongWritable(sum);
//输出k3,v3的值
//System.out.println("<k3,v3>=<"+k3.toString()+","+v3.get()+">");
//logger.info("<k3,v3>=<"+k3.toString()+","+v3.get()+">");
// 把结果写出去
context.write(k3,v3);
}
}
/**
* 组装Job=Map+Reduce
*/
public static void main(String[]args){
try{
if(args.length!=3){
//如果传递的参数不够,程序直接退出
System.exit(100);
}
//指定Job需要的配置参数
Configuration conf=new Configuration();
//创建一个Job
Job job=Job.getInstance(conf);
//注意了:这一行必须设置,否则在集群中执行的时候是找不到WordCountJob这个
job.setJarByClass(WordCountJobSkewRandKey.class);
//指定输入路径(可以是文件,也可以是目录)
FileInputFormat.setInputPaths(job,new Path(args[0]));
//指定输出路径(只能指定一个不存在的目录)
FileOutputFormat.setOutputPath(job,new Path(args[1]));
//指定map相关的代码
job.setMapperClass(MyMapper.class);
//指定k2的类型
job.setMapOutputKeyClass(Text.class);
//指定v2的类型
job.setMapOutputValueClass(LongWritable.class);
//指定reduce相关的代码
job.setReducerClass(MyReducer.class);
//指定k3的类型
job.setOutputKeyClass(Text.class);
//指定v3的类型
job.setOutputValueClass(LongWritable.class);
//设置reduce任务个数
job.setNumReduceTasks(Integer.parseInt(args[2]));
//提交job
job.waitForCompletion(true);
}catch(Exception e){
}
}
}
只需要在map中把k2的值修改一下就可以了,这样就可以把值为5的数据打散了。
编译打包,提交到集群
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -rm -r /out10000000
[root@bigdata01 hadoop-3.2.0]# hadoop jar db_hadoop-1.0-SNAPSHOT-jar-with-dep
执行成功之后查看结果
注意,这个时候获取到的并不是最终的结果,因为我们把值为5的数据随机分成多份了,最多分成
10份
[root@bigdata01 hadoop-3.2.0]# hdfs dfs -cat /out10000000/*
1 100000
5_3 1012097
2 100000
5_4 1011163
3 100000
5_5 1010498
4 100000
5_6 1010755
5_7 1010823
5_8 1012394
6 100000
7 100000
5_0 1011274
8 100000
10 100000
5_1 1009972
9 100000
5_2 1011024
任务总的执行消耗时间为: Elapsed: 1mins, 39sec
这次任务执行时间节省了1分钟多的左右,在这就属于质的提升了,相当于节省了将近一半的时间了
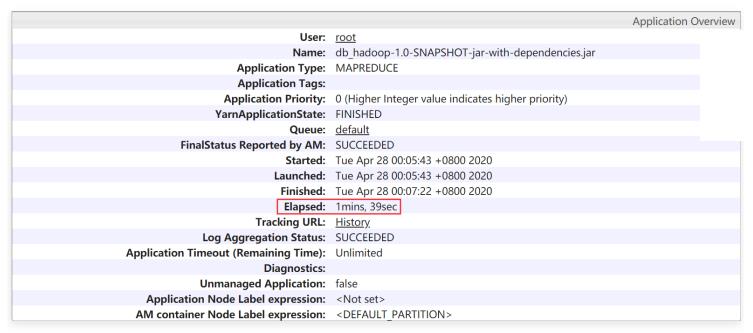
查看一下reduce任务执行情况,在这里就没有发现特别耗时的reduce任务了,消耗的时间几乎都差不

但是这个时候我们获取到的最终结果是一个半成品,还需要进行一次加工,其实我们前面把这个倾斜的数据打散之后相当于做了一个局部聚合,现在还需要再开发一个mapreduce任务再做一次全局聚合,其实 也很简单,获取到上一个map任务的输出,在map端读取到数据之后,对数据先使用空格分割,然后对 第一列的数据再使用下划线分割,分割之后总是取第一列,这样就可以把值为5的数据还原出来了,这个时候数据一共就这么十几条,怎么处理都很快了,这个代码就给大家留成作业了,我们刚才已经把详细的过程都分析过了,大家下去之后自己写一下。这就是针对数据倾斜问题的处理方法,面试的时候经常问到,大家一定要能够把这个思路说明白。
以上是关于大数据数据倾斜问题与企业级解决方案的主要内容,如果未能解决你的问题,请参考以下文章