探索Golang协程实现——从v1.0开始
Posted LNMPRG源码研究
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了探索Golang协程实现——从v1.0开始相关的知识,希望对你有一定的参考价值。
李乐
问题引入
提起协程,你可能会说,不就go func吗,我分分钟就能创建上万个协程。可是协程到底是什么呢?都说协程是用户态线程,这里的用户态是什么意思?都说协程比线程更轻量,协程轻量在哪里呢?
本文主要为读者介绍这些内容:
- Golang v1.0协程并发模型——MG模型,协程创建,协程切换,协程退出,以及g0协程,重在理解协程栈切换逻辑;
- 为了理解协程栈,还需要简单了解下虚拟内存,函数栈帧以及简单的汇编语言;
- Golang v1.0协程调度逻辑;
- defer,panic以及recover底层实现原理。
通过本篇文章,你将从根本上了解Golang协程。
注:为什么选择v1.0版本呢?因为他足够的简单,不过,麻雀虽小五脏俱全;而且你会发现,即使到了现在,Golang协程实现原理,也就那么回事。v1.0版本代码可以从github上下载,分支为release-branch.go1。
基础补充
在讲解Golang协程实现之前,还需要补充一些基础知识。理解协程,就需要理解函数栈帧,以及虚拟内存。而函数栈帧的管理,需要从汇编层次去解读。
PS:不要怕,汇编其实很简单,不过几条指令,几个寄存器而已。
虚拟内存
linux将内存组织为一些区域(段)的集合,如代码段,数据段,运行时堆,共享库段,以及用户栈都是不同的区域。如下图所示:

用户栈,自上而下增长,寄存器%rsp指向用户栈的栈顶位置;通过malloc分配的内存通常是在运行时堆。
想想函数调用过程,比如func1调用func2,待func2执行完毕后,还会回归道func1继续执行。该过程非常类似于栈结构,先入后出。大多数语言的函数调用都采用栈结构实现(基于用户栈),函数的调用与返回即对应一系列的入栈与出栈操作,而我们平常遇到的栈溢出就是因为函数调用层级过深,不断入栈导致的。函数栈帧如下图所示:

寄存器%rbp指向函数栈帧底部位置,寄存器%rsp指向函数栈帧顶部位置。可以看到,在函数栈帧入栈时候,还会将调用方函数栈帧的%rbp寄存器入栈,以及实现多个函数栈帧的链接关系。否则,当前函数执行完毕后,如何恢复其调用方的函数栈帧?
谁为我维护着函数栈帧结构呢?当然是我的代码了,可是我都没关注过这些啊。可以看看编译器生成的汇编代码,我们简单写一个c程序:
int add(int x, int y)
{
return x+y;
}
int main()
{
int sum = add(111,222);
}
查看编译结果:
main:
pushq %rbp
movq %rsp, %rbp
subq $16, %rsp
movl $222, %esi
movl $111, %edi
call add
movl %eax, -4(%rbp)
leave
ret
add:
pushq %rbp
movq %rsp, %rbp
movl %edi, -4(%rbp)
movl %esi, -8(%rbp)
movl -8(%rbp), %eax
movl -4(%rbp), %edx
addl %edx, %eax
popq %rbp
ret
可以看到main以及add函数入口,都对应有修改%rbp以及%rsp指令。
另外,读者请注意:这个示例,函数调用过程中,参数的传递以及返回值是通过寄存器传递的,比如第一个参数是%edi,第二个参数是%esi,返回值是%eax。参数以及返回值如何传递,其实并不是那么重要,约定好即可,比如Golang语言,参数以及返回值都是基于栈帧传递的。
汇编简介
任何架构的计算机都会提供一组指令集合,汇编是二进制指令的文本形式。指令由操作码和操作数组成;操作码即操作类型,操作数可以是一个立即数或者一个存储地址(内存,寄存器)。寄存器是集成在CPU内部,访问非常快,但是数量有限的存储单元。Golang使用plan9汇编语法,汇编指令的写法以及寄存器的命名略有不同
下面简单介绍一些常用的指令以及寄存器:
- MOVQ $10, AX:数据移动指令,该指令表示将立即数10存储在寄存器AX;AX即通用寄存器,常用的通用寄存器还有BX,CX,DX等等;注意指令后缀『Q』表示数据长度为8字节;
- ADDQ AX, BX:加法指令,等价于 BX += AX;
- SUBQ AX, BX:减法指令,等价于 BX -= AX;
- JMP addr:跳转道addr地址处继续执行;
- JMP 2(PC):CPU如何加载指令并执行呢?其实有个专用寄存器PC(等价于%rip),他指向下一条待执行的指令。该语句含义是,以当前指令为基础,向后跳转2行;
- FP:伪寄存器,通过symbol+offset(FP)形式,引用函数的输入参数,例如 arg0+0(FP),arg1+8(FP);
- 硬件寄存器SP:等价于上面出现过的%rsp,执行函数栈帧顶部位置);
- CALL func:函数调用,包含两个步骤,1)将下一条指令的所在地址入栈(还需要恢复到这执行);2)将func地址,存储在指令寄存器PC;
- RET:函数返回,功能为,从栈上弹出指令到指令寄存器PC,恢复调用方函数的执行(CALL指令入栈);
更多plan9知识参考:https://xargin.com/plan9-asse...
下面写一个go程序,看看编译后的汇编代码:
package main
func addSub(a, b int) (int, int){
return a + b , a - b
}
func main() {
addSub(333, 222)
}汇编代码查看:go tool compile -S -N -l test.go
"".addSub STEXT nosplit size=49 args=0x20 locals=0x0
0x0000 00000 (test.go:3) MOVQ $0, "".~r2+24(SP)
0x0009 00009 (test.go:3) MOVQ $0, "".~r3+32(SP)
0x0012 00018 (test.go:4) MOVQ "".a+8(SP), AX
0x0017 00023 (test.go:4) ADDQ "".b+16(SP), AX
0x001c 00028 (test.go:4) MOVQ AX, "".~r2+24(SP)
0x0021 00033 (test.go:4) MOVQ "".a+8(SP), AX
0x0026 00038 (test.go:4) SUBQ "".b+16(SP), AX
0x002b 00043 (test.go:4) MOVQ AX, "".~r3+32(SP)
0x0030 00048 (test.go:4) RET
"".main STEXT size=68 args=0x0 locals=0x28
0x000f 00015 (test.go:7) SUBQ $40, SP
0x0013 00019 (test.go:7) MOVQ BP, 32(SP)
0x0018 00024 (test.go:7) LEAQ 32(SP), BP
0x001d 00029 (test.go:8) MOVQ $333, (SP)
0x0025 00037 (test.go:8) MOVQ $222, 8(SP)
0x002e 00046 (test.go:8) CALL "".addSub(SB)
0x0033 00051 (test.go:9) MOVQ 32(SP), BP
0x0038 00056 (test.go:9) ADDQ $40, SP
0x003c 00060 (test.go:9) RET分析main函数汇编代码:SUBQ $40, SP为自己分配栈帧区域,LEAQ 32(SP), BP,移动BP寄存器到自己栈帧结构的底部。MOVQ $333, (SP)以及MOVQ $222, 8(SP)在准备输入参数。
分析addSub函数汇编代码:"".a+8(SP)即输入参数a,"".b+16(SP)即输入参数b。两个返回值分别在24(SP)以及32(SP)。
注意:addSub函数,并没有通过SUBQ $xx, SP以,来为自己分配栈帧区域。因为addSub函数没有再调用其他函数,也就没有必要在为自己分配函数栈帧区域了。
另外,注意main函数,addSub函数,是如何传递与引用输入参数以及返回值的。
线程本地存储
线程本地存储(Thread Local Storage,简称TLS),其实就是线程私有全局变量。普通的全局变量,一个线程对其进行了修改,所有线程都可以看到这个修改;线程私有全局变量不同,每个线程都有自己的一份副本,某个线程对其所做的修改不会影响到其它线程的副本。
Golang是多线程程序,当前线程正在执行的协程,显然每个线程都是不同的,这就维护在线程本地存储。所以在Golang协程切换逻辑中,随处可见『get_tls(CX)』,用于获取当前线程本地存储首地址。
不同的架构以及操作系统,可以通过FS或者GS寄存器访问线程本地存储,如Golang程序,383架构Linux操作系统时,通过如下方式访问:
//"386", "linux"
"#define get_tls(r) MOVL 8(GS), r\\n"
//获取线程本地存储首地址
get_tls(CX)
//结构体G封装协程相关数据,DX存储着当前正在执行协程G的首地址
//协程调度时,保存当前协程G到线程本地存储
MOVQ DX, g(CX)线程本地存储简单了解下就行,更多知识可参考文章:https://www.cnblogs.com/abozh...
v1.0协程模型
很多人对Golang并发模型MPG应该是比较了解的,如下图所示。其中,G代表一个协程;M代表一个工作线程;P代表逻辑处理器,其维护着可运行协程的队列runq;需要注意的是,M只有和P绑定后,才能调度并执行协程。另外,g0是一个特殊的协程,用于执行调度逻辑,以及协程创建销毁等逻辑。

Golang v1.0版本并发模型还是比较简单的,这时候还没有逻辑处理器P,只有MG,如下图所示。注意这时候可运行协程队列维护在全局,因此每次调度都需要加锁,性能是比较低的。

数据结构
有几个重要的结构体我们需要简单了解下,比如M,G,以及协程调度相关Gobuf。
结构体M封装线程相关数据,字段较多,但是目前基本都可以不关注。结构体G封装协程相关数据,我们先了解这几个字段:
struct G
{
//协程ID
int32 goid;
//协程入口函数
byte* entry; // initial function
//协程栈
byte* stack0;
//协程调度相关
Gobuf sched;
//协程状态
int16 status;
}注意Gobuf结构,其定义了协程调度相关的上下文数据:
struct Gobuf
{
//寄存器SP
byte* sp;
//寄存器PC
byte* pc;
//执行协程对象
G* g;
};Golang定义协程有下面几种状态:
enum
{
//协程创建初始状态
Gidle,
//协程在可运行队列等待调度
Grunnable,
//协程正在被调度运行
Grunning,
//协程正在执行系统调用
Gsyscall,
//协程处于阻塞状态,没有在可运行队列
Gwaiting,
//协程执行结束,等待调度器回收
Gmoribund,
//协程已被回收
Gdead,
};协程状态转移如下图所示:

协程创建
通过go关键字可以很方便的创建协程,Golang编译器会将go关键字替换为runtime.newproc函数调用,函数newproc实现了协程的创建逻辑,定义如下:
//siz:参数数目;fn:入口函数
func newproc(siz int32, fn *funcval);在讲解协程创建之前,我们先思考下,需要创建什么?仅仅是一个结构体G吗?
我们回顾一下函数调用过程,func1调用func2,func2函数栈帧入栈,func2执行完毕,func2函数栈帧出栈,重新回到func1的函数栈帧。那如果func1以及func2代表着两个协程呢?这两个函数会并行执行,还能像函数调用过程一样吗?显然是不行的,因为func1以及func2函数栈帧需要随意切换。
我们可以类比下线程,多线程程序,每一个线程都有一个用户栈(参考虚拟内存结构,存在多个用户栈),该用户栈由操作系统维护(创建,切换,回收)。线程执行为什么需要用户栈呢?函数的局部变量,函数调用过程的入参传递,返回值传递,都是基于用户栈实现的。
协程也需要多个用户栈,只不过这些用户栈需要Golang来维护。我们能通过系统调用创建用户栈吗?显然是不能的。但是,我们上面提到过,寄存器%rsp以及寄存器%rbp指向了用户栈,CPU知道什么是栈什么是堆吗?不知道,他只需要基于寄存器%rsp入栈以及出栈就行了。正式基于此,我们可以偷梁换柱,在堆上申请一块内存,将寄存器%rsp以及寄存器%rbp指过去,从而将这块内存伪装成用户栈。
协程创建主要逻辑由函数runtime·newproc1实现,主要步骤有:1)从空闲链表中获取结构体G;2)如果没有获取到空闲的G,则重新分配,包括分配结构体G以及协程栈;3)将创建好的协程加入到可运行队列。
//fn:协程入口函数;argp:参数首地址;narg:输入参数所占字节数;nret:返回值所占字节数;callerpc:调用方PC指针
G* runtime·newproc1(byte *fn, byte *argp, int32 narg, int32 nret, void *callerpc) {
//根据参数数目,以及返回值数目;计算栈所需空间
siz = narg + nret;
//加锁;会操作全局数据
schedlock();
//从全局链表获取Gruntime·sched.gfree
if((newg = gfget()) != nil){
}{
//申请G,以及协程栈
newg = runtime·malg(StackMin);
}
//协程栈顶指针(栈自顶向下)
sp = newg->stackbase;
sp -= siz;
//初始化:协程状态,协程栈顶指针sp,协程退出处理函数pc,协程入口函数entry
newg->status = Gwaiting;
newg->sched.sp = sp;
newg->sched.pc = (byte*)runtime·goexit;
newg->sched.g = newg;
newg->entry = fn;
//协程数目统计
runtime·sched.gcount++;
//自增协程ID
runtime·sched.goidgen++;
newg->goid = runtime·sched.goidgen;
//将协程加入到可运行队列
newprocreadylocked(newg);
//释放锁
schedunlock();
return newg;
}这里读者需重点关注两处逻辑:1)runtime·malg申请协程栈空间,注意栈空间申请逻辑只能在g0栈执行,g0栈就是协程g0的栈,所以这里可能还存在栈的切换,下一个小节将详细介绍;2)初始化协程时候,注意协程栈顶指针sp,协程退出处理函数pc,协程入口函数entry,后面协程切换时候非常重要。
g0协程
我们之前说过,g0是一个特殊的协程,用于执行调度逻辑,以及协程创建销毁等逻辑。这句话还是比较抽象的,可能还是不明白g0协程到底是什么?其实只要记住一句话:程序逻辑的执行都需要栈空间。因此需要把调度逻辑,以及协程创建销毁等逻辑在独立的栈空间(g0栈)上执行。
所以随处可见这样的逻辑:
//协程栈申请,必须在g0栈
if(g == m->g0) {
// running on scheduler stack already.
stk = runtime·stackalloc(StackSystem + stacksize);
} else {
//runtime·mcall专门用于切换栈帧到g0
runtime·mcall(mstackalloc);
}
//协程调度,必须在g0栈
void runtime·gosched(void) {
runtime·mcall(schedule);
}runtime·mcall函数声明如下,其中fn就是切换到g0栈去执行的函数,如调度逻辑,栈帧分配逻辑:
void mcall(void (*fn)(G*))下面就只能硬着头皮看了,不去一行一行看runtime·mcall的汇编实现,永远无法真正理解协程栈切换的本质。
TEXT runtime·mcall(SB), 7, $0
//FP伪寄存器,fn+0(FP)方式可获得第一个参数fn,存储到寄存器DI
MOVQ fn+0(FP), DI
//线程本地存储,可以获取当前执行协程g,以及当前线程m
get_tls(CX)
//寄存器CX指向线程本地存储,g(CX)可获取当前执行协程,存储在寄存器AX
MOVQ g(CX), AX
//基于指令CALL调用函数runtime·mcall时候,会入栈指令寄存器PC;
//0(SP)即调用方下一条待执行指令
MOVQ 0(SP), BX
//g_sched即sched字段在结构体g偏移量;gobuf_pc即pc字段在结构体gobuf偏移量;
//g_sched以及gobuf_pc都是宏定义,并且由脚本生成
//保存当前协程上下文:下一条待执行指令
MOVQ BX, (g_sched+gobuf_pc)(AX)
//调用方栈顶位置,在8(SP);参考函数栈帧示意图
LEAQ 8(SP), BX
MOVQ BX, (g_sched+gobuf_sp)(AX)
//AX存储着当前协程
MOVQ AX, (g_sched+gobuf_g)(AX)
// AX为当前协程,m->g0为g0协程;判断当前协程是否是g0协程
MOVQ m(CX), BX
MOVQ m_g0(BX), SI
CMPQ SI, AX // if g == m->g0 call badmcall
JNE 2(PC)
//如果是,非法的runtime·mcall调用
CALL runtime·badmcall(SB)
//SI为g0协程,g(CX)协程本地存储,赋值当前执行协程为g0
//(程序很多地方都需要判断当前执行的是哪个协程,所以切换前需要更新)
MOVQ SI, g(CX) // g = m->g0
//SI为g0协程,恢复g0协程上下文:sp寄存器
MOVQ (g_sched+gobuf_sp)(SI), SP // sp = m->g0->gobuf.sp
//注意函数声明,void (*fn)(G*),输入参数为G。
//AX为即将换出的协程,这里将输入参数入栈
PUSHQ AX
//DI即第一个参数fn,调用该函数
CALL DI
POPQ AX
//因为fn理论上是死循环,永远不会执行结束;如果到这里说明出异常了
CALL runtime·badmcall2(SB)
RET每一行汇编的含义都有注释,这里就不再一一介绍。
通过runtime·mcall汇编实现,读者可以看到,协程切换,切换的就是指令寄存器PC,以及栈寄存器SP。重点关注当前协程下一条指令,以及协程栈顶指针获取方式。
需要特别注意的是:其输入参数fn永远不会返回,该函数会切换到其他协程执行。一旦fn执行返回了,会调用runtime·badmcall2抛异常(panic)。
最后可以思考下,m->g0即当前线程的g0协程,变量g即当前正在执行的协程,所以代码里才有这样的逻辑:
extern register G* g;
if(g == m->g0) {
}然而又发现,变量g定义的是全局寄存器变量,改变量理论上应该在协程切换时更新。可是协程切换时,确实没有更新的逻辑,只能找到更新线程本地存储的逻辑。其实这是因为Golang编译器做了一个改动,将extern register变量与协程本地存储关联起来了。
// on 386 or amd64, "extern register" generates
// memory references relative to the
// gs or fs segment.我们再回顾下协程创建过程中申请栈帧的逻辑:
G* runtime·malg(int32 stacksize) {
if(g == m->g0) {
// running on scheduler stack already.
stk = runtime·stackalloc(StackSystem + stacksize);
} else {
// have to call stackalloc on scheduler stack.
g->param = (void*)(StackSystem + stacksize);
runtime·mcall(mstackalloc);
stk = g->param;
}
newg->stack0 = stk;
}
static void mstackalloc(G *gp) {
gp->param = runtime·stackalloc((uintptr)gp->param);
runtime·gogo(&gp->sched, 0);
}假设在协程A中,通过go关键字创建协程B;g->param变量即需要申请的协程栈大小。观察函数mstackalloc声明,该函数在g0栈上执行,其第一个参数gp指向协程A;栈空间申请完毕后,又通过runtime·gogo切换回协程,继续协程B的初始化。整个过程如下图所示:
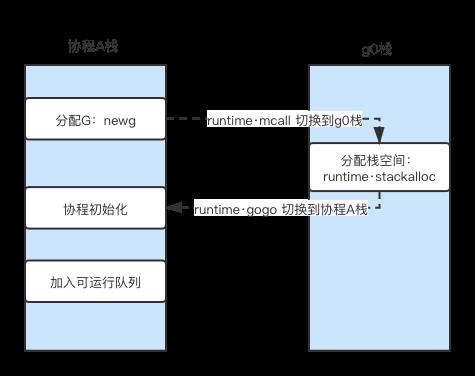
协程切换
协程创建,协程结束,协程因为某些原因阻塞,可能都会触发协程的切换。
如上一节介绍的函数runtime·gogo,就实现了协程切换功能。
//gobuf:待执行协程上下文结构;
void runtime·gogo(Gobuf*, uintptr);
TEXT runtime·gogo(SB), 7, $0
MOVQ 16(SP), AX // return 2nd arg
//第一个参数gobuf,存储在寄存器BX
MOVQ 8(SP), BX // gobuf
//gobuf_g即字段g相对于gobuf的偏移量;协程g存储在DX
MOVQ gobuf_g(BX), DX
MOVQ 0(DX), CX // make sure g != nil
//获取线程本地存储
get_tls(CX)
//即将执行的协程,保存在线程本地存储
MOVQ DX, g(CX)
//恢复协程上下文:栈顶寄存器SP
MOVQ gobuf_sp(BX), SP // restore SP
//恢复协程上下文:下一条指令
MOVQ gobuf_pc(BX), BX
//指令跳转,这就切换到新的协程了
JMP BX首次切换到协程时候,并不是通过runtime·gogo实现的。而是基于runtime·gogocall,为什么要区分呢?因为首次切换到协程,还有一些特殊任务需要处理,如提前设置好协程结束处理函数。
//gobuf:待执行协程上下文结构;第二个参数:协程入口函数
void runtime·gogocall(Gobuf*, void(*)(void));
static void schedule(G *gp) {
//协程上下文PC等于runtime·goexit,说明协程还没有开始执行过
if(gp->sched.pc == (byte*)runtime·goexit) {
runtime·gogocall(&gp->sched, (void(*)(void))gp->entry);
}
}
TEXT runtime·gogocall(SB), 7, $0
//第二个参数:协程入口函数
MOVQ 16(SP), AX // fn
//第一个参数,gobuf
MOVQ 8(SP), BX // gobuf
//待执行协程g,保存在寄存器DX
MOVQ gobuf_g(BX), DX
//获取线程本地存储
get_tls(CX)
//即将执行的协程,保存在线程本地存储
MOVQ DX, g(CX)
MOVQ 0(DX), CX // make sure g != nil
//恢复协程上下文:栈顶寄存器SP
MOVQ gobuf_sp(BX), SP // restore SP
//此时,gobuf_pc等于runtime·goexit,存储在寄存器BX
MOVQ gobuf_pc(BX), BX
//思考下为什么BX要入栈?
PUSHQ BX
//指令跳转,AX为协程入口函数
JMP AX
POPQ BX // not reachedruntime·gogocall以及runtime·gogo函数实现了协程的换入工作;另外,协程换出时候,通过runtime·gosave保存协程上下文,该函数在协程即将进入系统调用时候执行。
//gobuf:协程上下文结构
void gosave(Gobuf*)
TEXT runtime·gosave(SB), 7, $0
//第一个参数gobuf
MOVQ 8(SP), AX // gobuf
//调用方的栈顶位置存储在8(SP),参考函数栈帧示意图
LEAQ 8(SP), BX // caller\'s SP
//协程上下文:栈顶位置保存在gobuf->sp
MOVQ BX, gobuf_sp(AX)
//协程上下文:下一条待执行指令保存在在gobuf->pc
MOVQ 0(SP), BX // caller\'s PC
MOVQ BX, gobuf_pc(AX)
//获取线程本地存储
get_tls(CX)
MOVQ g(CX), BX
//当前协程g,存储在gobuf->g
MOVQ BX, gobuf_g(AX)
RET通过上面三个函数的汇编实现,相信读者对协程切换:上下文保存以及上下文恢复,都有了一定了解。
协程结束
想象下,如果某协程的处理函数为funcA,funcA执行完毕,相当于该协程的结束。这之后该怎么办?肯定需要执行特定的回收工作。注意到上面小节有一个函数,runtime·goexit,看名字协程结束时候应该执行这个函数。如何在funcA执行完毕后,调用runtime·goexit呢?
再次回顾函数调用过程,以及函数栈帧示意图。函数funcA执行完毕时候,存在一个RET指令,该指令会弹出下一条待指令到指令寄存器PC,从而只限指令的跳转。我们再观察runtime·gogocall的实现逻辑,有这么一行指令:
TEXT runtime·gogocall(SB), 7, $0
//BX即gobuf->pc,初始为runtime·goexit
PUSHQ BX
//指令跳转,AX为协程入口函数
JMP AX
POPQ BX // not reached逻辑串起来了,PUSHQ BX,将函数runtime·goexit首地址入栈,因此协程执行结束后,RET弹出的指令就是函数runtime·goexit首地址,从而开始了协程回收工作。而函数runtime·goexit,则标记协程状态为Gmoribund,开始新一次的协程调度(会切换到g0调度)
void runtime·goexit(void)
{
g->status = Gmoribund;
runtime·gosched();
}v1.0协程调度
调度器负责维护协程状态,获取一个可运行协程并执行。调度逻辑主要在函数schedule中,正如上面所说,调度逻辑肯定需要运行在g0栈,因此通常这么执行调度函数:
runtime·mcall(schedule);调度函数的声明如下,输入参数gp是什么呢?当然是即将换出的协程,参数的准备可在runtime·mcall汇编中看到:
static void schedule(G *gp)
TEXT runtime·mcall(SB), 7, $0
//注意函数声明,void (*fn)(G*),输入参数为G。
//AX为即将换出的协程,这里将输入参数入栈
PUSHQ AX
//DI即第一个参数fn,调用该函数
CALL DI
切换到调度器后,会更新协程状态,接着从可运行队列获取一个新的协程去执行:
static void schedule(G *gp) {
if(gp != nil) {
switch(gp->status){
case Grunning:
//放入可运行列表
gp->status = Grunnable;
gput(gp);
break;
case Gmoribund:
//协程结束;回收到空闲列表,可重复利用
gp->status = Gdead;
gfput(gp);
//省略
}
}
// Find (or wait for) g to run.
//获取可运行协程
gp = nextgandunlock();
gp->status = Grunning;
//运行协程
if(gp->sched.pc == (byte*)runtime·goexit) {
runtime·gogocall(&gp->sched, (void(*)(void))gp->entry);
}
runtime·gogo(&gp->sched, 0);
}进一步,在调度函数schedule之上又封装了runtime·gosched,在触发协程调度时候,通常基于该函数完成。可以简单画下协程调度示意图:
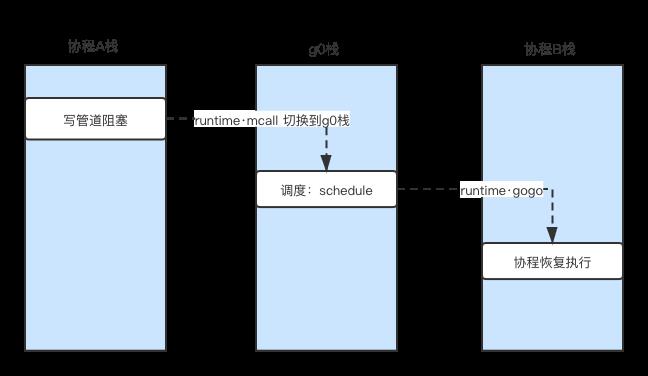
有很多种情况可能会触发协程调度:比如读写管道阻塞了,比如socket操作等等,下面将分别介绍。
管道channel
管道通常用于协程间的数据交互,管道的结构体定义如下:
struct Hchan
{
//已写入管道的数据总量
uint32 qcount; // total data in the q
//管道最大数据量
uint32 dataqsiz; // size of the circular q
//读管道阻塞的协程,是一个队列
WaitQ recvq; // list of recv waiters
//写管道阻塞的协程,是一个队列
WaitQ sendq; // list of send waiters
};写管道操作底层由函数runtime·chansend实现,读取管道操作底层由函数runtime·chanrecv实现。有两种情况会导致协程的阻塞:1)往管道写入数据时,已达到该管道最大数据量;2)从管道读取数据时,管道数据为空。我们以runtime·chansend为例:
void runtime·chansend(ChanType *t, Hchan *c, byte *ep, bool *pres) {
//管道为nil,阻塞当前协程,触发协程调度
if(c == nil) {
g->status = Gwaiting;
g->waitreason = "chan send (nil chan)";
runtime·gosched();
return; // not reached
}
if(c->dataqsiz > 0) {
//有缓冲管道,写入数据满了,阻塞该协程
if(c->qcount >= c->dataqsiz) {
g->status = Gwaiting;
g->waitreason = "chan send";
enqueue(&c->sendq, &mysg);
runtime·unlock(c);
runtime·gosched();
}
}
……
}更多详细的实现细节,读者可以查看函数runtime·chansend与runtime·chanrecv实现逻辑。
socket事件循环
socket读写怎么处理呢?熟悉高并发服务端编程的应该都了解:基于IO多路复用模型,比如epoll。Golang也是这么做的。
结构体pollServer封装了事件循环相关,其定义如下:
type pollServer struct {
//读写文件描述符,epoll在阻塞等待时候,可用于临时唤醒(只要执行下写或者读操作即可)
pr, pw *os.File
//代理poll,底层可基于epoll/Kqueue等
poll *pollster // low-level OS hooks
//socket-fd在读写时候通常都有超时时间;deadline为最近的过期时间,用于设置epoll_wait阻塞时间
deadline int64 // next deadline (nsec since 1970)
}注:不了解epoll的读者,搜索一下就有很多文章介绍。
Golang进程启动时,会创建pollServer,并启动事件循环,详情参考函数newPollServer。
func newPollServer() (s *pollServer, err error) {
s = new(pollServer)
if s.pr, s.pw, err = os.Pipe(); err != nil {
return nil, err
}
//设置非阻塞标识
if err = syscall.SetNonblock(int(s.pr.Fd()), true); err != nil {
goto Errno
}
if err = syscall.SetNonblock(int(s.pw.Fd()), true); err != nil {
goto Errno
}
//初始化代理poll:可能是epoll/Kqueue等
if s.poll, err = newpollster(); err != nil {
goto Error
}
//监听s.pr,因此在向s.pw写数据时候,可以接触epoll阻塞(以epoll为例)
if _, err = s.poll.AddFD(int(s.pr.Fd()), \'r\', true); err != nil {
s.poll.Close()
goto Error
}
go s.Run()
return s, nil
}注意到这里通过go s.Run()启动了一个协程,即事件循环是以独立的协程在运行。事件循环无非就是,死循环,不断通过epoll_wait阻塞等待socket事件的发生。
func (s *pollServer) Run() {
for {
var t = s.deadline
//堵塞等待事件发生
fd, mode, err := s.poll.WaitFD(s, t)
//超时了,没有事件发生
if fd < 0 {
s.CheckDeadlines()
continue
}
//由于s.pr接触了阻塞,不是真正的socket-fd事件发生
if fd == int(s.pr.Fd()) {
} else {
netfd := s.LookupFD(fd, mode)
//唤醒阻塞在该fd上的协程
s.WakeFD(netfd, mode, nil)
}
}
}看到这我们大概明白了事件循环的逻辑,还有两个问题需要确定:1)socket读写操作实现逻辑;2)如何唤醒阻塞在该fd上的协程。
socket读写逻辑,由函数
pollServer.WaitRead或者pollServer.WaitWrite;即上层的网络IO最终都会走到这里。以WaitRead函数为例:
func (s *pollServer) WaitRead(fd *netFD) error {
err := s.AddFD(fd, \'r\')
if err == nil {
err = <-fd.cr
}
return err
}s.AddFD最终将socket-fd添加到epoll,并且会更新pollServer.deadline,这是一个非阻塞操作;接下来只需等待事件循环监听该fd读/写事件即可。读管道fd.cr导致了该协程的阻塞。
基于这些,我们很容易猜到,s.WakeFD唤醒阻塞在该fd上的协程,其实只需要往管道fd.cr/fd.cw写下数据即可。
defer/panic/recover
这几个关键字应该是很常见的,特别是panic,非常让人讨厌。关于这几个关键字的使用,这里就不介绍了。我们重点探索其底层实现原理。
defer以及panic定义在结构体G,结构体Defer以及Panic这里就不做过多介绍了:
struct G
{
//该协程是否发生panic
bool ispanic;
//defer链表
Defer* defer;
//panic链表
Panic* panic;
}我们先探索第一个问题,都知道defer是先入后出的,为什么呢?函数执行结束时执行defer,又是怎么实现的呢?defer关键字底层实现函数为runtime·deferproc:
uintptr runtime·deferproc(int32 siz, byte* fn, ...){
//初始化结构体Defer
d = runtime·malloc(sizeof(*d) + siz - sizeof(d->args));
d->fn = fn;
d->siz = siz;
//注意这里设置了调用方待执行指令地址
d->pc = runtime·getcallerpc(&siz);
//头插法,后插入的节点在头部;执行确实从头部遍历执行,因此就是先入后出
d->link = g->defer;
g->defer = d;
}那defer什么时候执行呢?在函数结束时,Golang编译器会在函数末尾添加runtime.deferreturn,用于执行函数fn,有兴趣的读者可以写个小示例,通过go tool compile -S -N -l test.go看看。
接下来我们探索第二个问题:panic是怎么触发程序崩溃的;defer与recover又是如何恢复这种崩溃的;A协程中触发panic,B协程中能否recover该panic呢?
关键字panic底层实现函数为runtime·panic:
void runtime·panic(Eface e) {
p = runtime·mal(sizeof *p);
p->link = g->panic;
g->panic = p;
//遍历执行当前协程的defer链表
for(;;) {
d = g->defer;
if(d == nil)
break;
g->defer = d->link;
g->ispanic = true;
//反射调用d->fn
reflect·call(d->fn, d->args, d->siz);
//recover底层实现为runtime·recover,该函数会标记p->recovered=1
//如果已经执行了recover,则会消除这次崩溃
if(p->recovered) {
//将该defer又加入到协程链表;调度时候有用
d->link = g->defer;
g->defer = d;
//恢复程序的执行
runtime·mcall(recovery);
}
}
//如果没有recover住,则会打印堆栈信息,并结束进程
runtime·startpanic();
printpanics(g->panic);
runtime·dopanic(0); //runtime·exit(2)
}可以看到,发生panic后,只会遍历当前协程的defer链表,所以A协程中触发panic,B协程中肯定不能recover该panic。
最后一个问题,defer里面recover之后,Golang程序从哪里恢复执行呢?参考runtime·mcall(recovery),这就需要看函数recovery实现了:
static void
recovery(G *gp)
{
//获取第一个defer,即刚才就是该defer recover了
d = gp->defer;
gp->defer = d->link;
//注意在初始化defer时候,设置了调用方待执行指令地址,这里将其设置到协程调度上下文,从而恢复到这里执行
gp->sched.pc = d->pc;
//协程切换
runtime·gogo(&gp->sched, 1);
}注意在初始化defer时候,是如何设置pc的?基于函数runtime·getcallerpc。这样获取的是调用runtime.deferproc的下一条指令地址。
CALL runtime.deferproc(SB)
TESTL AX, AX
JNE 182这里通过TESTL校验AX寄存器内容是正数负数还是0值。AX寄存器存储的是什么呢?还需要继续探索。
仔细看看,这里协程切换时候,为什么runtime·gogo第二个参数是1呢?之前我们一直没有说第二个参数的作用。其实第二个参数是用作返回值的。参考runtime·gogo汇编实现,第二个参数拷贝到了寄存器AX,后面没有任何代码使用寄存器AX。
TEXT runtime·gogo(SB), 7, $0
MOVQ 16(SP), AX // return 2nd arg
//省略原来如此,runtime·gogo协程切换时候,设置的AX寄存器;在介绍虚拟内存章节,我们也提到,寄存器AX可以作为函数返回值。其实函数runtime·deferproc也有明确的解释:
// deferproc returns 0 normally.
// a deferred func that stops a panic
// makes the deferproc return 1.
// the code the compiler generates always
// checks the return value and jumps to the
// end of the function if deferproc returns != 0.
return 0;runtime·deferproc通常返回0值,但是在出现panic,并且捕获崩溃之后,runtime·deferproc返回1(基于runtime·gogo第二个参数以及AX寄存器实现)。这时候会通过JNE指令跳转到runtime.deferreturn继续执行,相当于函数执行结束。
最后我们简单画一下该过程示意图:
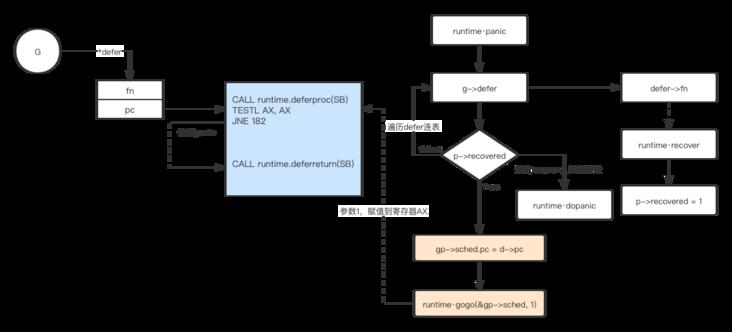
总结
本文以Golang v1.0版本为例,为读者讲解协程实现原理,包括协程创建,协程切换,协程退出,以及g0协程。v1.0协程调度还是比较简单的,很多因素可能引起协程的阻塞触发协程调度,本文简单介绍了管道chan,以及socket事件循环。最后,针对defer/panic/recover,我们介绍了其底层实现原理。
公众号
该系列文章会同步到以下公众号

以上是关于探索Golang协程实现——从v1.0开始的主要内容,如果未能解决你的问题,请参考以下文章
[Golang]实现一个带有等待和超时功能的协程池 - 类似Java中的ExecutorService接口实现