如何提高代码的可读性 学习笔记
Posted 薯条
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何提高代码的可读性 学习笔记相关的知识,希望对你有一定的参考价值。
本文整理自 taowen 师傅在滴滴内部的分享。
1.Why
对一线开发人员来说,每天工作内容大多是在已有项目的基础上继续堆代码。当项目实在堆不动时就需要寻找收益来重构代码。既然我们的大多数时间都花在坐在显示器前读写代码这件事上,那可读性不好的代码都是在谋杀自己or同事的生命,所以不如一开始就提炼技巧,努力写好代码; )
2.How
为提高代码可读性,先来分析代码实际运行环境。代码实际运行于两个地方:cpu和人脑。对于cpu,代码优化需理解其工作机制,写代码时为针对cpu特性进行优化;对于人脑,我们在读代码时,它像解释器一样,一行一行运行代码,从这个角度来说,要提高代码的可读性首先需要知道大脑的运行机制。

下面来看一下人脑适合做的事情和不适合做的事情:
大脑擅长做的事情
| 名称 | 图片 | 说明 |
|---|---|---|
| 对象识别 |  | 不同于机器学习看无数张猫片之后可能还是不能准确识别猫这个对象,人脑在看过几只猫之后就可以很好的识别。 |
| 空间分解 |  | 人脑不需要标注,可以直观感受到空间中的不同物体。 |
| 时序预测 |  | 你的第一感觉是不是这个哥们要被车撞了? |
| 时序记忆 |  | 作为人类生存本能之一,我们多次走过某个地方时,人脑会对这个地方形成记忆。 |
| 类比推测 | 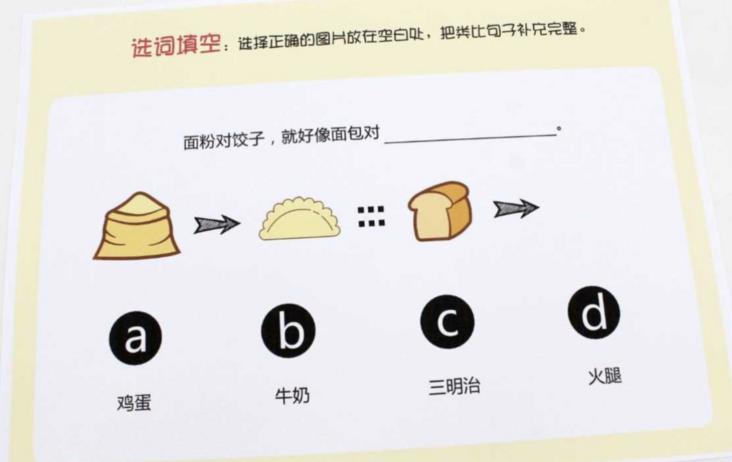 | 人脑还有类比功能,比如说这道题大多数人会选择C吧。 |
大脑不擅长做的事情
| 名称 | 图片 | 例子 |
|---|---|---|
| 无法映射到现实生活经验的抽象概念 | 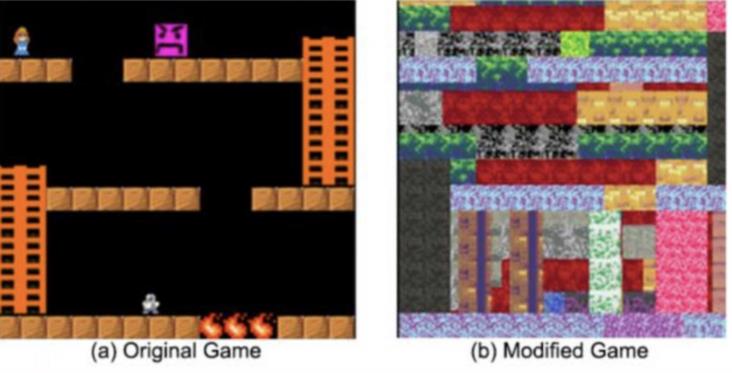 | 人脑看到左图时,会比较轻松想到通关方式,但是如果换成右图这种抽象的概念,里面的对象换成了嘿嘿的像素,我们就不知道这是什么鬼了。比如说代码里如果充斥着Z,X,C,V 这样的变量名,你可能就看懵了。 |
| 冗长的侦探推理 |  | 这种需要递归(or循环)去检查所有可能性最后找到解法的场景,人脑同样不擅长。 |
| 跟踪多个同时变化的过程 |  | 大脑是个单线程的CPU,不擅长左手画圆,右手画圈。 |
代码优化理论
了解人脑的优缺点后,写代码时就可以根据人脑的特点对应改善代码的可读性了。这里提取出三种理论:
- Align Models ,匹配模型:代码中的数据和算法模型 应和人脑中的 心智模型对应
- Shorten Process , 简短处理:写代码时应 缩短 “福尔摩斯探案集” 的流程长度,即不要写大段代码
- Isolate Process,隔离处理:写代码一个流程一个流程来处理,不要同时描述多个流程的演进过程
下面通过例子详细解释这三种模型:
Align Models
在代码中,模型无外乎就是数据结构与算法,而在人脑中,对应的是心智模型,所谓心智模型就是人脑对于一个物体 or 一件事情的想法,我们平时说话就是心智模型的外在表现。写代码时应把代码中的名词与现实名词对应起来,减少人脑从需求文档到代码的映射成本。比如对于“银行账户”这个名词,很多变量名都可以体现这个词,比如:bankAccount、bank_account、account、BankAccount、BA、bank_acc、item、row、record、model,编码中应统一使用和现实对象能链接上的变量名。
代码命名技巧
起变量名时候取其实际含义,没必要随便写个变量名然后在注释里面偷偷用功。
// bad
var d int // elapsed time in days
// good
var elapsedTimeInDays int // 全局使用起函数名 动词+名词结合,还要注意标识出你的自定义变量类型:
// bad
func getThem(theList [][]int) [][]int {
var list1 [][]int // list1是啥,不知道
for _, x := range theList {
if x[0] == 4 { // 4是啥,不知道
list1 = append(list1, x)
}
}
return list1
}
// good
type Cell []int // 标识[]int作用
func (cell Cell) isFlagged() bool { // 说明4的作用
return cell[0] == 4
}
func getFlaggedCells(gameBoard []Cell) []Cell { // 起有意义的变量名
var flaggedCells []Cell
for _, cell := range gameBoard {
if cell.isFlagged() {
flaggedCells = append(flaggedCells, cell)
}
}
return flaggedCells
}代码分解技巧
按照空间分解(Spatial Decomposition):下面这块代码都是与Page相关的逻辑,仔细观察可以根据page的空间分解代码:
// bad
// …then…and then … and then ... // 平铺直叙描述整个过程
func RenderPage(request *http.Request) map[string]interface{} {
page := map[string]interface{}{}
name := request.Form.Get("name")
page["name"] = name
urlPathName := strings.ToLower(name)
urlPathName = regexp.MustCompile(`[\'.]`).ReplaceAllString(
urlPathName, "")
urlPathName = regexp.MustCompile(`[^a-z0-9]+`).ReplaceAllString(
urlPathName, "-")
urlPathName = strings.Trim(urlPathName, "-")
page["url"] = "/biz/" + urlPathName
page["date_created"] = time.Now().In(time.UTC)
return page
}// good
// 按空间分解,这样的好处是可以集中精力到关注的功能上
var page = map[string]pageItem{
"name": pageName,
"url": pageUrl,
"date_created": pageDateCreated,
}
type pageItem func(*http.Request) interface{}
func pageName(request *http.Request) interface{} { // name 相关过程
return request.Form.Get("name")
}
func pageUrl(request *http.Request) interface{} { // URL 相关过程
name := request.Form.Get("name")
urlPathName := strings.ToLower(name)
urlPathName = regexp.MustCompile(`[\'.]`).ReplaceAllString(
urlPathName, "")
urlPathName = regexp.MustCompile(`[^a-z0-9]+`).ReplaceAllString(
urlPathName, "-")
urlPathName = strings.Trim(urlPathName, "-")
return "/biz/" + urlPathName
}
func pageDateCreated(request *http.Request) interface{} { // Date 相关过程
return time.Now().In(time.UTC)
}按照时间分解(Temporal Decomposition):下面这块代码把整个流程的算账和打印账单混写在一起,可以按照时间顺序对齐进行分解:
// bad
func (customer *Customer) statement() string {
totalAmount := float64(0)
frequentRenterPoints := 0
result := "Rental Record for " + customer.Name + "\\n"
for _, rental := range customer.rentals {
thisAmount := float64(0)
switch rental.PriceCode {
case REGULAR:
thisAmount += 2
case New_RELEASE:
thisAmount += rental.rent * 2
case CHILDREN:
thisAmount += 1.5
}
frequentRenterPoints += 1
totalAmount += thisAmount
}
result += strconv.FormatFloat(totalAmount,\'g\',10,64) + "\\n"
result += strconv.Itoa(frequentRenterPoints)
return result
}// good 逻辑分解后的代码
func statement(custom *Customer) string {
bill := calcBill(custom)
statement := bill.print()
return statement
}
type RentalBill struct {
rental Rental
amount float64
}
type Bill struct {
customer *Customer
rentals []RentalBill
totalAmount float64
frequentRenterPoints int
}
func calcBill(customer *Customer) Bill {
bill := Bill{}
for _, rental := range customer.rentals {
rentalBill := RentalBill{
rental: rental,
amount: calcAmount(rental),
}
bill.frequentRenterPoints += calcFrequentRenterPoints(rental)
bill.totalAmount += rentalBill.amount
bill.rentals = append(bill.rentals, rentalBill)
}
return bill
}
func (bill Bill) print() string {
result := "Rental Record for " + bill.customer.name + "(n"
for _, rental := range bill.rentals{
result += "\\t" + rental.movie.title + "\\t" +
strconv.FormatFloat(rental.amount, \'g\', 10, 64) + "\\n"
}
result += "Amount owed is " +
strconv.FormatFloat(bill.totalAmount, \'g\', 10, 64) + "\\n"
result += "You earned + " +
strconv.Itoa(bill.frequentRenterPoints) + "frequent renter points"
return result
}
func calcAmount(rental Rental) float64 {
thisAmount := float64(0)
switch rental.movie.priceCode {
case REGULAR:
thisAmount += 2
if rental.daysRented > 2 {
thisAmount += (float64(rental.daysRented) - 2) * 1.5
}
case NEW_RELEASE:
thisAmount += float64(rental.daysRented) * 3
case CHILDRENS:
thisAmount += 1.5
if rental.daysRented > 3 {
thisAmount += (float64(rental.daysRented) - 3) * 1.5
}
}
return thisAmount
}
func calcFrequentRenterPoints(rental Rental) int {
frequentRenterPoints := 1
switch rental.movie.priceCode {
case NEW_RELEASE:
if rental.daysRented > 1 {
frequentRenterPointst++
}
}
return frequentRenterPoints
}按层分解(Layer Decomposition):
// bad
func findSphericalClosest(lat float64, lng float64, locations []Location) *Location {
var closest *Location
closestDistance := math.MaxFloat64
for _, location := range locations {
latRad := radians(lat)
lngRad := radians(lng)
lng2Rad := radians(location.Lat)
lng2Rad := radians(location.Lng)
var dist = math.Acos(math.Sin(latRad) * math.Sin(lat2Rad) +
math.Cos(latRad) * math.Cos(lat2Rad) *
math.Cos(lng2Rad - lngRad)
)
if dist < closestDistance {
closest = &location
closestDistance = dist
}
}
return closet
}// good
type Location struct {
}
type compare func(left Location, right Location) int
func min(objects []Location, compare compare) *Location {
var min *Location
for _, object := range objects {
if min == nil {
min = &object
continue
}
if compare(object, *min) < 0 {
min = &object
}
}
return min
}
func findSphericalClosest(lat float64, lng float64, locations []Location) *Location {
isCloser := func(left Location, right Location) int {
leftDistance := rand.Int()
rightDistance := rand.Int()
if leftDistance < rightDistance {
return -1
} else {
return 0
}
}
closet := min(locations, isCloser)
return closet
}注释
注释不应重复代码的工作。应该去解释代码的模型和心智模型的映射关系,应说明为什么要使用这个代码模型,下面的例子就是反面教材:
// bad
/** the name. */
var name string
/** the version. */
var Version string
/** the info. */
var info string
// Find the Node in the given subtree, with the given name, using the given depth.
func FindNodeInSubtree(subTree *Node, name string, depth *int) *Node {
}下面的例子是正面教材:
// Impose a reasonable limit - no human can read that much anyway
const MAX_RSS_SUBSCRIPTIONS = 1000
// Runtime is O(number_tags * average_tag_depth),
// so watch out for badly nested inputs.
func FixBrokenhtml(HTML string) string {
// ...
}Shorten Process
Shorten Process的意思是要缩短人脑“编译代码”的流程。应该避免写出像小白鼠走迷路一样又长又绕的代码。所谓又长又绕的代码表现在,跨表达式跟踪、跨多行函数跟踪、跨多个成员函数跟踪、跨多个文件跟踪、跨多个编译单元跟踪,甚至是跨多个代码仓库跟踪。
对应的手段可以有:引入变量、拆分函数、提早返回、缩小变量作用域,这些方法最终想达到的目的都是让大脑喘口气,不要一口气跟踪太久。同样来看一些具体的例子:
例子
下面的代码,多种复合条件组合在一起,你看了半天绕晕了可能也没看出到底什么情况下为true,什么情况为false。
// bad
func (rng *Range) overlapsWith(other *Range) bool {
return (rng.begin >= other.begin && rng.begin < other.end) ||
(rng.end > other.begin && rng.end <= other.end) ||
(rng.begin <= other.begin && rng.end >= other.end)
}但是把情况进行拆解,每种条件进行单独处理。这样逻辑就很清晰了。
// good
func (rng *Range) overlapsWith(other *Range) bool {
if other.end < rng.begin {
return false // they end before we begin
}
if other.begin >= rng.end {
return false // they begin after we end
}
return true // Only possibility left: they overlap
}再来看一个例子,一开始你写代码的时候,可能只有一个if ... else...,后来PM让加一下权限控制,于是你可以开心的在if里继续套一层if,补丁打完,开心收工,于是代码看起来像这样:
// bad 多层缩进的问题
func handleResult(reply *Reply, userResult int, permissionResult int) {
if userResult == SUCCESS {
if permissionResult != SUCCESS {
reply.WriteErrors("error reading permissions")
reply.Done()
return
}
reply.WriteErrors("")
} else {
reply.WriteErrors("User Result")
}
reply.Done()
}这种代码也比较好改,一般反向写if条件返回判否逻辑即可:
// good
func handleResult(reply *Reply, userResult int, permissionResult int) {
defer reply.Done()
if userResult != SUCCESS {
reply.WriteErrors("User Result")
return
}
if permissionResult != SUCCESS {
reply.WriteErrors("error reading permissions")
return
}
reply.WriteErrors("")
}这个例子的代码问题比较隐晦,它的问题是所有内容都放在了MooDriver这个对象中。
// bad
type MooDriver struct {
gradient Gradient
splines []Spline
}
func (driver *MooDriver) drive(reason string) {
driver.saturateGradient()
driver.reticulateSplines()
driver.diveForMoog(reason)
}比较好的方法是尽可能减少全局scope,而是使用上下文变量进行传递。
// good
type ExplicitDriver struct {
}
// 使用上下文传递
func (driver *MooDriver) drive(reason string) {
gradient := driver.saturateGradient()
splines := driver.reticulateSplines(gradient)
driver.diveForMoog(splines, reason)
}Isolate Process
人脑缺陷是不擅长同时跟踪多件事情,如果”同时跟踪“事物的多个变化过程,这不符合人脑的构造;但是如果把逻辑放在很多地方,这对大脑也不友好,因为大脑需要”东拼西凑“才能把一块逻辑看全。所以就有了一句很经典的废话,每个学计算机的大学生都听过。你的代码要做到高内聚,低耦合,这样就牛逼了!-_-|||,但是你要问说这话的人什么叫高内聚,低耦合呢,他可能就得琢磨琢磨了,下面来通过一些例子来琢磨一下。
首先先来玄学部分,如果你的代码写成下面这样,可读性就不会很高。

一般情况下,我们可以根据业务场景努力把代码修改成这样:

举几个例子,下面这段代码非常常见,里面version的含义是用户端上不同的版本需要做不同的逻辑处理。
func (query *Query) doQuery() {
if query.sdQuery != nil {
query.sdQuery.clearResultSet()
}
// version 5.2 control
if query.sd52 {
query.sdQuery = sdLoginSession.createQuery(SDQuery.OPEN_FOR_QUERY)
} else {
query.sdQuery = sdSession.createQuery(SDQuery.OPEN_FOR_QUERY)
}
query.executeQuery()
}这段代码的问题是由于版本差异多块代码流程逻辑Merge在了一起,造成逻辑中间有分叉现象。处理起来也很简单,封装一个adapter,把版本逻辑抽出一个interface,然后根据版本实现具体的逻辑。
再来看个例子,下面代码中根据expiry和maturity这样的产品逻辑不同 也会造成分叉现象,所以你的代码会写成这样:
// bad
type Loan struct {
start time.Time
expiry *time.Time
maturity *time.Time
rating int
}
func (loan *Loan) duration() float64 {
if loan.expiry == nil {
return float64(loan.maturity.Unix()-loan.start.Unix()) / 365 * 24 * float64(time.Hour)
} else if loan.maturity == nil {
return float64(loan.expiry.Unix()-loan.start.Unix()) / 365 * 24 * float64(time.Hour)
}
toExpiry := float64(loan.expiry.Unix() - loan.start.Unix())
fromExpiryToMaturity := float64(loan.maturity.Unix() - loan.expiry.Unix())
revolverDuration := toExpiry / 365 * 24 * float64(time.Hour)
termDuration := fromExpiryToMaturity / 365 * 24 * float64(time.Hour)
return revolverDuration + termDuration
}
func (loan *Loan) unusedPercentage() float64 {
if loan.expiry != nil && loan.maturity != nil {
if loan.rating > 4 {
return 0.95
} else {
return 0.50
}
} else if loan.maturity != nil {
return 1
} else if loan.expiry != nil {
if loan.rating > 4 {
return 0.75
} else {
return 0.25
}
}
panic("invalid loan")
}解决多种产品逻辑的最佳实践是Strategy pattern,代码入下图,根据产品类型创建出不同的策略接口,然后分别实现duration和unusedPercentage这两个方法即可。
// good
type LoanApplication struct {
expiry *time.Time
maturity *time.Time
}
type CapitalStrategy interface {
duration() float64
unusedPercentage() float64
}
func createLoanStrategy(loanApplication LoanApplication) CapitalStrategy {
if loanApplication.expiry != nil && loanApplication.maturity != nil {
return createRCTL(loanApplication)
}
if loanApplication.expiry != nil {
return createRevolver(loanApplication)
}
if loanApplication.maturity != nil {
return createTermLoan
}
panic("invalid loan application")
}但是现实情况没有这么简单,因为不同事物在你眼中就是多进程多线程运行的,比如上面产品逻辑的例子,虽然通过一些设计模式把执行的逻辑隔离到了不同地方,但是代码中只要含有多种产品,代码在执行时还是会有一个产品选择的过程。逻辑发生在同一时间、同一空间,所以“自然而然”就需要写在了一起:
- 功能展示时,由于需要展示多种信息,会造成 concurrent process
- 写代码时,业务包括功能性和非功能性需求,也包括正常逻辑和异常逻辑处理
- 考虑运行效率时,为提高效率我们会考虑异步I/O、多线程/协程
- 考虑流程复用时,由于版本差异和产品策略也会造成merged concurrent process
对于多种功能杂糅在一起,比如上面的RenderPage函数,对应解法为不要把所有事情合在一起搞,把单块功能内聚,整体再耦合成为一个单元。
对于多个同步进行的I/O操作,可以通过协程把揉在一起的过程分开来:
// bad 两个I/O写到一起了
func sendToPlatforms() {
httpSend("bloomberg", func(err error) {
if err == nil {
increaseCounter("bloomberg_sent", func(err error) {
if err != nil {
log("failed to record counter", err)
}
})
} else {
log("failed to send to bloom berg", err)
}
})
ftpSend("reuters", func(err error) {
if err == DIRECTORY_NOT_FOUND {
httpSend("reuterHelp", err)
}
})
}对于这种并发的I/O场景,最佳解法就是给每个功能各自写一个计算函数,代码真正运行的时候是”同时“在运行,但是代码中是分开的。
//good 协程写法
func sendToPlatforms() {
go sendToBloomberg()
go sendToReuters()
}
func sendToBloomberg() {
err := httpSend("bloomberg")
if err != nil {
log("failed to send to bloom berg", err)
return
}
err := increaseCounter("bloomberg_sent")
if err != nil {
log("failed to record counter", err)
}
}
func sendToReuters() {
err := ftpSend("reuters")
if err == nil {
httpSend("reutersHelp", err)
}
}有时,逻辑必须要合并到一个Process里面,比如在买卖商品时必须要对参数做逻辑检查:
// bad
func buyProduct(req *http.Request) error {
err := checkAuth(req)
if err != nil {
return err
}
// ...
}
func sellProduct(req *http.Request) error {
err := checkAuth(req)
if err != nil {
return err
}
// ...
}这种头部有公共逻辑经典解法是写个Decorator单独处理权限校验逻辑,然后wrapper一下正式逻辑即可:
// good 装饰器写法
func init() {
buyProduct = checkAuthDecorator(buyProduct)
sellProduct = checkAuthDecorator(sellProduct)
}
func checkAuthDecorator(f func(req *http.Request) error) func(req *http.Request) error {
return func(req *http.Request) error {
err := checkAuth(req)
if err != nil {
return err
}
return f(req)
}
}
var buyProduct = func(req *http.Request) error {
// ...
}
var sellProduct = func(req *http.Request) error {
// ...
}此时你的代码会想这样:
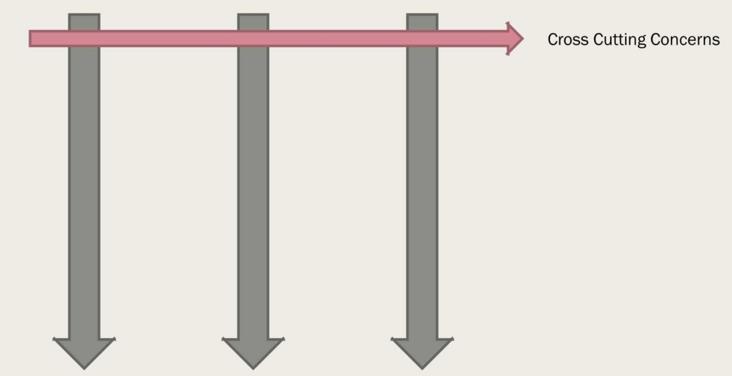
当然公共逻辑不仅仅存在于头部,仔细思考一下所谓的strategy、Template pattern,他们是在逻辑的其他地方去做这样的逻辑处理。
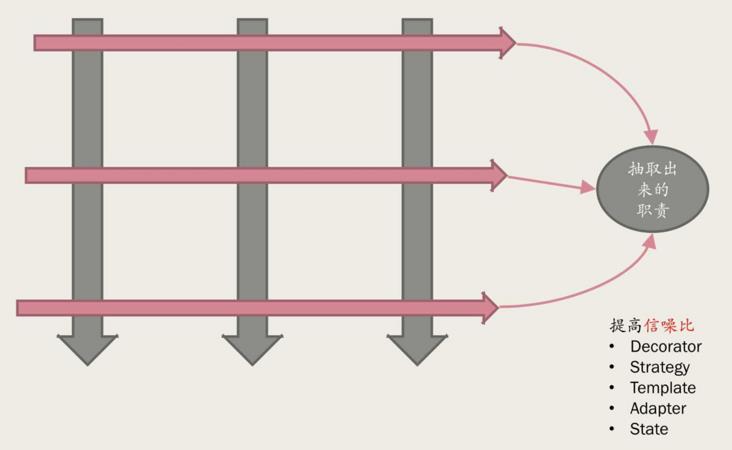
这块有一个新的概念叫:信噪比。信噪比是一个相对概念,信息,对我有用的;噪音,对我没用的。代码应把什么逻辑写在一起,不仅取决于读者是谁,还取决于这个读者当时希望完成什么目标。
比如下面这段C++和Python代码:
void sendMessage(const Message &msg) const {...}

def sendMessage(msg):如果你现在要做业务开发,你可能会觉得Python代码读起来很简洁;但是如果你现在要做一些性能优化的工作,C++代码显然能给你带来更多信息。
再比如下面这段代码,从业务逻辑上讲,这段开发看起来非常清晰,就是去遍历书本获取Publisher。
for _, book := range books {
book.getPublisher()
}但是如果你看了线上打了如下的SQL日志,你懵逼了,心想这个OOM真**,真就是一行一行执行SQL,这行代码可能会引起DB报警,让你的DBA同事半夜起来修DB。
SELECT * FROM Pubisher WHERE PublisherId = book.publisher_id
SELECT * FROM Pubisher WHERE PublisherId = book.publisher_id
SELECT * FROM Pubisher WHERE PublisherId = book.publisher_id
SELECT * FROM Pubisher WHERE PublisherId = book.publisher_id
SELECT * FROM Pubisher WHERE PublisherId = book.publisher_id所以如果代码改成这样,你可能就会更加明白这块代码其实是在循环调用实体。
for _, book := range books {
loadEntity("publisher", book.publisher_id)
}总结一下:
优先尝试给每 个Process一个自己的函数,不要合并到一起来算
- 尝试界面拆成组件
- 尝试把订单拆成多个单据,独立跟踪多个流程
- 尝试用协程而不是回调来表达concurrent i/o
如果不得不在一个Process中处理多个相对独立的事情
- 尝试复制一份代码,而不是复用同一个Process
- 尝试显式插入: state/ adapter/ strategy/template/ visitor/ observer
- 尝试隐式插入: decorator/aop
- 提高信噪比是相对于具体目标的,提高了一个目标的信噪比,就降低了另外一个目标的信噪比
3.总结
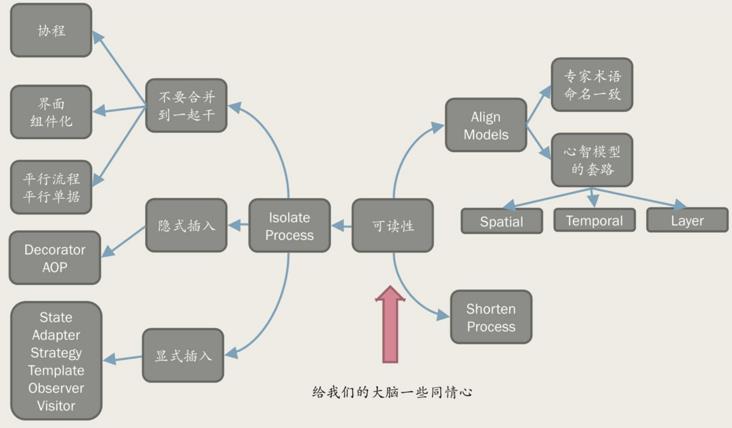
当我们吐槽这块代码可读性太差时,不要把可读性差的原因简单归结为注释不够 或者不OO,而是可以从人脑特性出发,根据下面的图片去找到代码问题,然后试着改进它(跑了几年的老代码还是算了,别改一行线上全炸了: )
以上是关于如何提高代码的可读性 学习笔记的主要内容,如果未能解决你的问题,请参考以下文章