许式伟:相比 Python,我们可能更需要 Go+
Posted 鸣飞
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了许式伟:相比 Python,我们可能更需要 Go+相关的知识,希望对你有一定的参考价值。
ECUG(Effective Cloud User Group,实效云计算用户组)主办的 2021 ECUG Con 于 2021 年 4 月 10 日 - 11 日在上海举办。会上,七牛云 CEO 许式伟以 “数据科学与 Go+” 为主题发表了主题分享,讲述了对数据科学变迁的理解,对新语言 Go+ 的设想和规划,并大胆指出数据科学正迎来爆发期,像字节跳动一样的新型公司只会越来越多。以下为演讲内容整理。

刚才在闲聊说 ECUG 变得越来越高大上,其实我也变得越来越像一个单纯的讲师。今年是 ECUG 社区的第 14 个年头,这场活动也是第 14 届 ECUG Con。其实这一届本来应该在去年办,但因为疫情延后了。
其实,我在 ECUG 一直贯彻的理念有两个:
第一,让自己持续地写代码。因为每一次来 ECUG 我都很紧张,不能什么都没有呀。所以这也是挺好的机会,能让自己持续留在技术一线;
另外,我每年分享的主题都有一定的延续性,呈现了我自己对未来思考的脉络。
去年开始,我在聊数据科学,前面有三年是聊在端上的一些实践。原因是我认为云计算的第一个时代应该是属于机器计算,也就是虚拟机;第二代就是云原生,我认为这是一场被称为“基础架构”的革命。也就是说,第一阶段是资源,第二阶段是基础架构。 第三个阶段,我的判断为应用计算,这会涉及前端和后端的协同。
从去年开始,我的分享转向了数据科学,一个很重要的因素和趋势是,数据时代的到来。尤其是 2017 年之后,数据大量地被数字化以后,在各行各业都会有涉及数据科学的广泛应用。
去年也是蛮巧的,我脑子一热就搞了一个语言出来。我以前搞过蛮多语言,受众也有一些。但是那个都很明确,从来没有想过有一天能够商业化。也许碰巧有一些公司用它来做商业化,但是基本上从出生那一刻开始,就不是冲着商业化去的。
2012 年我花了很多精力在布道 Go,因为当时作为一个初创公司,招人太难。一个比较好的招人逻辑就是让别人觉得你有趣,公司技术氛围很不错。Go+ 是我第一个认认真真希望能够把它商业化的语言,但目前宣传得还不多,1.0 还没发布。我想讲讲我自己对 Go+ 和数据科学的一个思考,为什么认为 Go+ 有商业化的机会。
我今天聊的话题大概有四个方面:
- 语言的发展
- 数据科学的发展
- Go+ 的设计理念
- Go+ 实现的迭代
语言的发展
首先,我们讲讲语言的发展,程序员对这个话题非常感兴趣。我把语言的发展史分为三个部分来说。
第一,静态语言的发展史。我选的是 TOP20 的语言,这个是根据现在最火的语言排行榜排名选的,前 20 名的语言我排了一下大概是这样的,最早发布的是 C,到现在其实还在排行榜前三的位置。第二是 C++,Objective-C、Java、C#、Go、Swift、Go+。我们可以看到一个比较有趣的现象,差不多每 6-8 年会出现一轮新的、具备影响力的静态语言,这是生产力迭代的表征。

第二,脚本语言的发展。你会发现它们非常不一样。最早是 Visual Basic,然后是 Python、php、javascript、Ruby,脚本语言是集中大爆发的,差不多全在 Java 出现的前后,来自 90 年代的前 5 个年头。这是非常有趣的一件事情,也是非常值得思考的,背后一定有一些内在的原因。

第三,数据科学相关语言的发展。但数据科学我选的是 TOP50,因为 TOP20 实在太少了。也蛮有意思的,最早的是 SQL,第二个 SAS,MATLAB、Python、R、Julia。Python 最早从来没想过自己会是数据科学语言,但最终变成了人工智能领域最火的语言。

这里又存在一个很明显的特征:它的跨度跟静态语言一样大,所以数据科学发展其实是古老而漫长的,但发展得没有那么快。静态语言差不多每 6-8 年有一个迭代,但数据科学语言不是,中间跨度特别大。但我觉得现在正进入数据科学的加速期。
你可能会想,为什么我要分析语言发展史呢?有几个结论是关键。
首先,我认为脚本语言是特定历史阶段下的产物,长期来看,静态语言更有生命力。
第二,数据科学是计算机的最初需求,最早计算机就是用来做计算的。它历史悠久但进步缓慢,因为数据大爆发的时代一直没有到来。

数据科学的发展
聊完语言的发展,接下来我们谈谈数据科学的发展。数据科学也可以分为几个阶段,第一个阶段我叫做“原始时期”,也可以叫“数学软件时代”,这个时期基本上可归纳为两个特征,第一个是在有限领域里,最典型的是 BI(商业智能);第二个有限数据规模,典型就像 Excel,行列数都是非常有限的,其他的软件也基本上是这样的。
这个时期的数据科学特点是什么?首先它不是一个基础设施,实际上是数学应用软件,但能力非常全,很强大,包括了统计、预测、洞察、规划、决策等等。

第二个时期我叫做“数据科学的基建时期”,真正让数据科学成为了基础设施,最典型的代表是大数据的兴起。Map/Reduce 是 Google 2004 年发布的一篇论文,2006 年就出现了 Hadoop,2009 年出现了 Spark。我认为这算是大数据兴起的一个阶段,也是数据科学基础设施化的开始。这个时期跟刚才的数学软件不一样,是以大规模处理能力为先,并不是以功能强大为先,它的功能相对局限。

深度学习的兴起和大数据的兴起间隔时间比较长,深度学习 2015 年开始有 TensorFlow,2017 年开始有 Torch,这是两个知名度最高的深度学习框架,深度学习本质就是通过数据自动推导 y=F(x)中的 F 函数。我们平常通常都是程序员实现这个 F,但深度学习最核心的概念是如何让机器自动产生这个 F,来达成最佳曲线拟合。它其实是基于测量结果的自动计算。

假设今天没有牛顿三大定理,但我有一堆测量数据,理论上应该能够发现牛顿三大定理,这就是深度学习的核心逻辑。它跟大数据并不是相互取代的关系,而是一种能力的加强,更多其实是如何让大数据的能力更进一步,更强悍。
有种看法认为,今天经济发展背后科技的驱动因子其实核心就只有两个,一个是计算,另外一个是数据。
数据核心就是我们今天聊的数据科学,数据科学其实是到了一个新的范式,有一个词叫“第四范式”,中国有一个公司也叫第四范式,我们认为数据是更高阶的一种生产能力,它跟计算相比的话站在更高层次的维度。
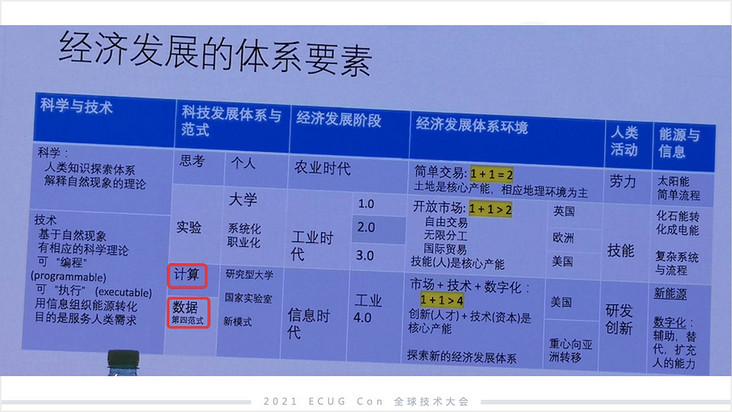
前面是数据科学的两个阶段,那么第三个阶段是什么?我觉得是数据科学的大爆发时期,也就是今天,用马云的话说是“DT 时代”。原始时期是在有限的领域,有限的数据规模下去做的一种能力。未来首先是全领域的,首先领域不局限于的商业智能( BI )这样的范畴,第二个是大规模的数据,第三个是随处可见,随处可见包括云、智能手机、嵌入式设备等,这些都会植入我们所谓的数据智能。

这就意味着,今天移动互联网的兴起已经让很多公司非常牛,互联网的平民化或互联网应用的诞生,催生了 BAT。但是我们知道,现在新兴的、比较牛的公司,像字节跳动这种,其实不是互联网的成功,而是数据科学的成功。今天仍然不能说,数据科学是平民化的,它的门槛非常高。
但是我们看到,智能应用已经产生了,智能应用不会只局限于抖音这样一个局部领域的生产力放大,各行各业都会被数据智能,也就是刚刚我们提到的第四范式所影响。
数据和数据科学,一定会成为下一代生产力的支撑,今天产生了字节跳动、快手这样的新兴的公司,但他们只是一个开始,绝对不是结局。
在数据科学的原始时期,数据只是副产品。大家想象一下,在 BI 领域,数据只是一个副产品,只是用于后期的运营决策。
但是今天我们看到在大量的应用里,数据就是原材料。这是非常不一样的状态,这也是为什么,我把它叫做数据科学大爆发时期,这是我觉得今天为什么需要 Go+ 的原因,也是其背后的历史背景。

数据科学的未来一定是通用语言和数学软件的融合,从而完成真正意义上的数据科学的基础设施化。但在今天,数据科学的基础设施化还远没有完全完成,这是我自己的判断。

今天的 Python 已经很好了,为何需要 Go+?
当然很多人会有疑问:今天的 Python 已经很好了,在深度学习领域已经被非常广泛地使用,为什么 Python 还不够,需要 Go+?其实我是认为,Python 是成不了基础设施的,它是一个脚本语言,我认为仅仅是特定历史阶段的需要。
数据科学本身是一种算力革命,哪怕在芯片领域,数据也能干翻计算,这是 Nvidia 干翻 Intel 的核心原因。上层软件领域就更加如此,一定会有一个新的基础设施承载者需要出现。
算力本质上是一种计算密集型业务,Python 的背后是 C,只靠 Python 还是不行。今天是 C 和 Python 支撑了整个深度学习,但数据科学一定还要进一步下沉,下沉的结果是什么?

这是我们今天需要 Go+ 的原因!前面主要讲我自己为什么认为 Go+有商业化的机会。当然我所说的商业化不一定是赚钱,大家不要误会这一点,语言可能在大多数人心目中是一个不赚钱的东西,但是这不代表它不重要,它非常重要。
Go+ 的设计理念
聊完数据科学的发展,接下来我们聊聊 Go+ 的设计理念。Go+为什么是今天这个样子?计算背后要的是程序员,而数据科学背后要的是数据科学家或者叫分析师。这两个角色其实还是不一样的,虽然都是技术工作。我认为培养程序员是相对容易的,今天程序员的数量是非常庞大的,但数据科学家的数量相对较少,这也是为什么前几年深度学习兴起以后,所谓的 AI 工程师薪资被炒翻了,比程序员贵很多。其实就是因为数据科学家不容易找。
这个角色承载着技术和商业的连接,要找到同时具备两种能力的人是很难的。数据科学首先是一个技术工作,要的是技术能力,又要懂商业。今天仍然没有非常体系化的培养数据科学家的能力,没有这样一个体系方法论。

那么 Go+ 的核心理念又是什么呢?
第一个,我们试图用 Go+ 来统一程序员和数据科学家,让他们之间有共同话语,让双方能自然对话,我觉得这是 Go+ 最核心的一个思考点。Go+ 很重要的一个核心逻辑,是用一门语言让两个角色进行对话。

在这个基础上,我们延伸了一些设计逻辑。首先,Go+ 是一个静态语言,语法是完全兼容 Go 的;第二,形式上要比 Go 更像脚本,有更低的学习门槛。Go 虽然在静态语言里,可能学习门槛是低的,但还不够低,没有 Python 那么低;第三,很自然的,我们要做一个数据科学的语言,所以它必然要有更简洁的、数学运算上的语言文法支持;第四是双引擎,同时支持静态编译为可执行文件,也支持编译成字节码来解释执行。

为什么我们会选择语法完全兼容 Go 呢?首先我个人很坚定地认为,静态语言拥有更强的生命力,更能跨越历史的周期。大家也都很容易理解,语言是需要跨越周期的,语言的生命周期通常都非常长。我们不能很局限地说,当前在流行些什么东西,我就如何决定语言的设计,实际上我们要找到那些能够跨越周期的元素。

第二,为什么是 Go?我个人认为,在静态语言里,Go 的语法设计最为精简,学习门槛也是最低的,哪怕你以前没有学过静态语言,也很容易学会 Go。我们公司是最早招聘 Go 程序员的,但大部分招进来的人都不会 Go。我们用 Go 的时候,世界上真没多少人认为 Go 是未来的流行语言。我们自己实践的经验表明,Go 语言两周的学习基本上够了,是门槛非常低的一门静态语言。
但从数据科学语言来讲,Go 的门槛还不够低,Go+ 虽然完全兼容 Go,但我们希望它比 Go 的门槛还要有更低。所以它形式上要比 Go 更像脚本,因为脚本往往更容易理解。我们希望 Go+ 学习门槛和 Python 处于同一个层次。
去年 5、6 月份 Go+ 刚诞生,差不多 10 月份左右,我就开始让 13-14 岁,六年级到初一这个阶段的三个小孩尝试学习 Go+。这个实践证明,这个事情是可行的。他们能理解 Go+ 的设计,能够自如地使用 Go+ 写代码。这也证明了我们在 Go 的基础上做的所有简化的努力是非常划算的。

我这里简单列了一些 Go+ 的语法,当然不是全部,只是一些我认为还是相对比较简洁的表达。有理数 Python 里面没有,我们认为有理数在数据科学里,尤其在无损数值运算里,还是会非常常见。Go+ 内置了有理数的支持。当然 Map、Slice 基本上 Python 都有。
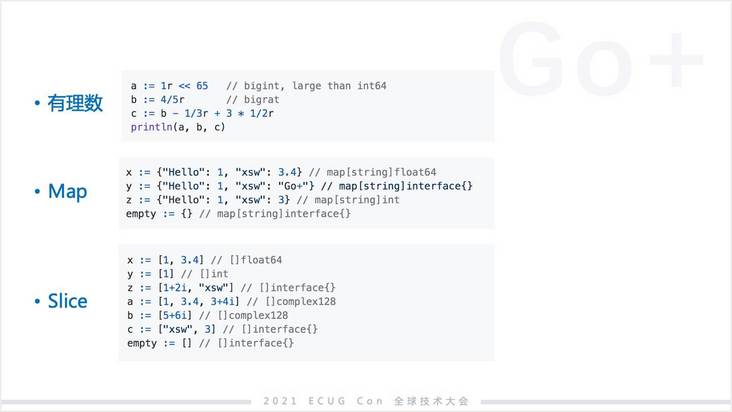
列表理解(List comprehesion)其实也是 Python 有的,但我们对列表理解的支持非常的完整,基本上理解了 Go+ 中 for 循环怎么写也就理解了列表理解。更多的还是数据科学的一些常规操作的简洁表达。以上是一个大概语法示意,如果有朋友没看过 Go+,希望可以大概对 Go+ 有个理解。

Go+ 非常有意思的一点,它是唯一一个选择了双引擎的语言,既支持静态编译,也支持可解析执行。
为什么要做双引擎呢?因为我认为程序员和数据科学家的诉求是不一样的,数据科学家喜欢单步执行,大家可以在心中回想一下你见过的数学软件,包括 SAS、MATLAB,数学软件交互都是单步执行的方式。
这并不是因为数据科学家懒。程序员理解程序逻辑是可以放在脑子里的,我们脑子里知道程序逻辑写得对不对。但数据科学家做计算的时候,不能知道计算结果对不对,因为人的计算能力比计算机弱太多了,所以一定要单步执行看到计算结果,才能知道自己下一步应该怎么办,这是数据科学家和程序员工作模式完全不同的一个点。
因为他是在做计算而不是在做一种程序逻辑,所以他很难不去做单步执行。
但当数据科学家建了一种模型,最终要使用了,这时他仍然希望最终交付的是最大化的执行效率,他一定不希望代码运行很慢,所以这个时候他就又需要静态编译执行,这也是为什么 Go+ 希望设计成双引擎,因为调试阶段和生产使用阶段,工作模式完全不一样。

Go+ 实现上的迭代
聊完 Go+ 的设计理念,我们进入最后一个 session,Go+ 实现上的迭代。当前 Go+ 做到了什么份上?Go+ 虽然还没有推出 1.0 版本,但是语法目前支持百分之六七十肯定有了,语法完成度还是不错的。
Go+ 的源代码,通过扫描器转成一个 Go+ 的 Token,再通过一个 parser 变成 Go+ 的抽象的语法数,常见语言都是这么干的。Go+ 的抽象语法树转化后有两个分支,一个生成 Go 的代码从而使其可以静态编译,另外一个分支生成字节码解析执行,分支的多态是通过引入了一个叫执行规范(exec.spec)的东西,其实就是一个抽象的接口。

当前,我个人在迭代的过程中发现了一个问题,对一个初步加入 Go+ 团队的人来说,是需要一段时间熟悉整个业务的。Go+ 执行规范的部分,其实是一种抽象的 SAX 接口,也就是基于事件驱动,我有一个事件发送给接受方,接受方按自己的需要处理这个事件,这在文本处理里面比较常见。
我们之前设计的接口基本上是用事件驱动的模式来把不同组件连接起来。编译器把抽象语法数解析完发出一些事件,这些事件被两个代码生成的模块接收,按照自己的需求去干活。这个模式代码还是有点难理解,尤其是编译器里面又做一些复杂的事情,让代码比较难理解。大家如果了解过 Go 背后的实现逻辑,类型推导在 Go 里面比较复杂,其实我们编译器的复杂性大部分是由类型推导导致的。
我当前在试图重构这个逻辑,想把执行规范部分变得不再是一个抽象的接口,而是一个标准实现的 DOM,这个 DOM 本身包含了类型推导的能力,从而使得编译器相对比较简单。讲实现我今天没法讲的特别细,后面有机会再展开。

下面我想讲一下 Go+ 下一步做的重心是什么。
首先,最核心的逻辑,还是希望今年能够发布 1.0 版本,而 1.0 版本最重要的事情是把用户的使用范式做最大化的确认,1.0 以后我希望和 Go 差不多,后面的语法变更是比较少的。当前最重要的工作,是明确 Go+ 需要哪些最核心的语法,并且在 1.0 版本就尽量去支持,除非有一些特定的考量比如说像 Go 的范型这种特别复杂的语法特性,留到后续的版本去支持。Go+ 也是类似的,我们可能会放弃一些特别复杂的语法特性,但是基本上尽可能把大部分我们需要的语法特性在 1.0 版本里确定下来。
Go+ 1.0 我们会先进行单引擎的迭代,先做好静态编译的引擎,等 1.0 发布以后再迭代脚本的引擎。这也是基于上面我们说的用户的使用范式优先的理念下的一个决策。

最后,我们希望用商业化的方式来运作 Go+,也会招聘 Go+ 的团队成员,欢迎大家加入 Go+ 团队!
我认为 Go+的核心是首先统一了程序员和数据科学家的语言,让双方能够自然对话。另外我非常坚定地相信 Go+ 会是数据科学的下一个变革,我自己非常兴奋能够做这样一件事情,也非常欢迎认可这件事的人加入我们。

这是联系我们的方法,第一个是项目的地址(https://github.com/goplus),第二个投简历的邮箱(jobs@qiniu.com),第三个是我推特的地址(@xushiwei)。
本文作者许式伟是七牛云创始人兼 CEO,Go 语言大中华区首席布道师,Go+ 语言创造者,ECUG 社区发起人。他曾就职于金山、盛大,在搜索和分布式存储相关技术领域有十几年的研发经验。在金山,他以首席架构师的身份主导了 WPS Office 2005 的架构设计和开发。在创立金山实验室后,作为技术总监主导了分布式存储开发,后加入盛大创新院,并成功推出“盛大网盘”和“盛大云”。许式伟在 2020 年被评选为《2020 中国开源先锋 33 人之心尖上的开源人物》。

以上是关于许式伟:相比 Python,我们可能更需要 Go+的主要内容,如果未能解决你的问题,请参考以下文章
追踪报道!Go+ 1.0 发布会有哪些大佬和精彩话题?嘿嘿嘿