论文泛读 GooLeNet:更深的卷积网络
Posted Real&Love
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文泛读 GooLeNet:更深的卷积网络相关的知识,希望对你有一定的参考价值。
【论文泛读】 GooLeNet:更深的卷积网络
文章目录
论文链接: Going deeper with convolutions
摘要 Abstract
我们在ImageNet大规模视觉识别挑战赛2014(ILSVRC14)上提出了一种代号为Inception的深度卷积神经网络结构,并在分类和检测上取得了新的最好结果。这个架构的主要特点是提高了网络内部计算资源的利用率。通过精心的手工设计,我们在增加了网络深度和广度的同时,保持了计算预算不变。为了优化质量,架构的设计以赫布理论和多尺度处理直觉为基础。我们在ILSVRC14提交中应用的一个特例被称为GoogLeNet,是一个22层的深度网络,其质量在分类和检测的背景下进行了评估。
GoogLeNet是2014 ILSVRC 比赛的冠军
Introduction 介绍
在当时几年中,深度学习不断兴起,目标分类能力和物体检测能力都不断的提高。
其中GoogLeNet 在 ILSVRC 2014 比赛中取得了冠军,并且它比当时两年前的冠军,也就是2012年的冠军AlexNet,是他的参数的 1 12 \\frac{1}{12} 121,参数少了很多,但是层数是比AlexNet多的,AlexNet的层数是8层,而GoogLeNet是22层
在这篇论文中,贯彻了"We need to go deeper"的思想,deep在这之中有两种不同的含义:
- 提出的“Inception module”引入了一种新层次的组织方式
- 在某种意义上更直接的增加了网络的深度
动机和思考
如果想要提高神经网络的性能,最直接的想法就是加深神经网络的深度和宽度,增加它的层数,提高每一层的神经元的个数
但是这种做法有两个缺陷
- 更大的尺寸意味着更大的参数,这样会使增大的网络更容易过拟合,特别是训练集的样本比较少的时候。
- 更大的网络尺寸会增大计算量,耗费大量的计算资源
Inception 模型
在论文中,提出了Inception模型,在模型中,用了1x1,3x3,5x5的卷积层,这是为了方便,而不是必要的,因为用这样的模型,我们在块填充padding的时候会比较方便而不需要考虑太多的操作。
并且对于Inception来说,它与VGG的不同在于,VGG是串行的网络层,Inception是并行的网络层,用不同尺寸的卷积层可以用来提取不同尺度特征
每个卷积层提取不同尺度的特征后,会将其合并起来,如下图所示
由于很多优秀的神经网络都用了池化下采样,所以这里也加了一个池化层,注意这里会保证每一个卷积层的输出都是相同的,所以才能进行一个合并的操作
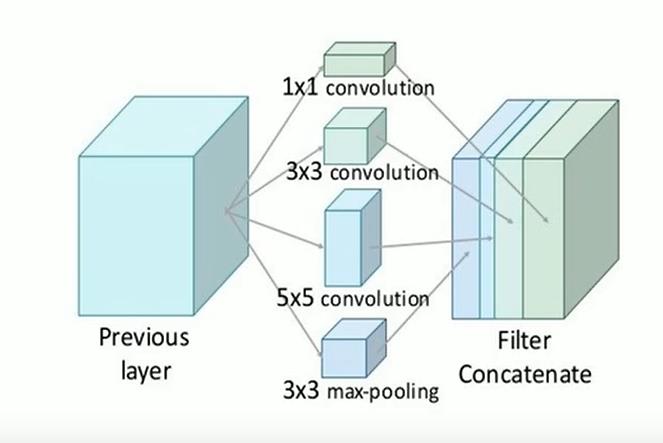
1x1卷积核 改进Inception
对于原始Inception来说,我们用了1x1卷积层来改进,得到一个新的Inception
这样的好处有
- 减小了计算量
- 训练参数减小
- 同时也增加了深度和非线性
通俗一点说,就是降维了,并且我们会加ReLU激活函数,增加了神经网络的非线性。
对于1x1卷积核来说,他的计算其实与全连接层是没有任何区别的,但是它不仅增加了非线性并且对我们的神经网络进行了降维,减少了我们的参数,是很有用的,在许多神经网络中,我们都可以看到1x1卷积核的影子
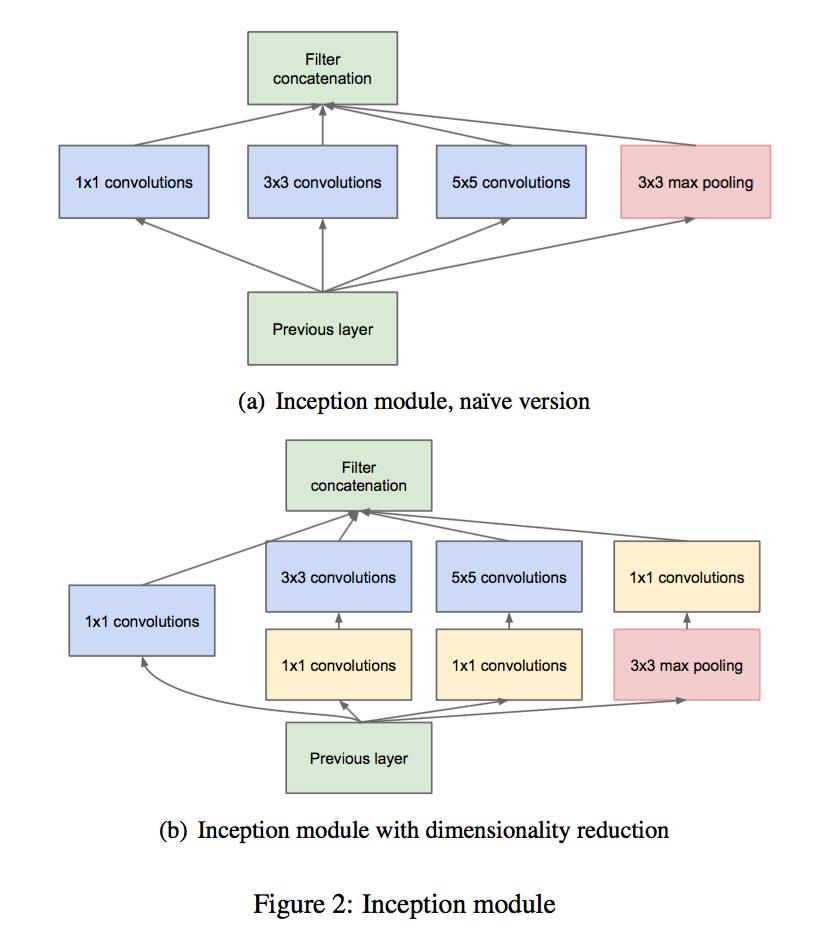
GoogLeNet
这里顺便提一下,GoogLeNet的名字是作者为了致敬LetNet (开山之作)而取的,而不是因为是Google,所以才是GoogLeNet
在论文中的,给出了GoogLeNet的架构
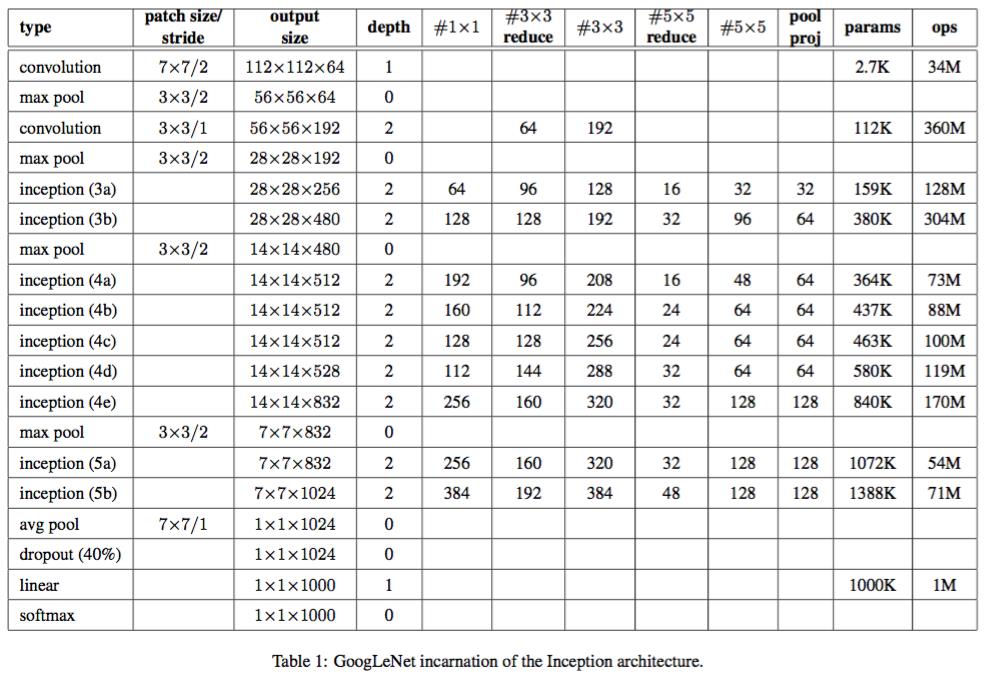
我们可以看到,一共有22层,在我们的GoogLeNet中有很多Inception层,然后会对其进行Maxpool最大池化
在论文中,作者发现将全连接层改为平均池化层,提高了大约top-1 0.6%的准确率,除此之外Dropout也是必不可少的。
在深度比较大的网络中,有效传播梯度反向通过所有层的能力是一个问题。所以GoogLeNet在训练阶段运用了两个辅助分类器,这样的话,在较低的阶段中,可以克服梯度消失的问题,这些分类器采用较小卷积网络的形式,放置在Inception (4a)和Inception (4b)模块的输出之上。在训练期间,它们的损失以折扣权重(辅助分类器损失的权重是0.3)加到网络的整个损失上。在预测的时候,这些辅助分类器就会被抛弃
包括辅助分类器在内的附加网络的具体结构如下:
- 一个滤波器大小5×5,步长为3的平均池化层,导致(4a)阶段的输出为4×4×512,(4d)的输出为4×4×528。
- 具有128个滤波器的1×1卷积,用于降维和修正线性激活。
- 一个全连接层,具有1024个单元和修正线性激活。
- 丢弃70%输出的Dropout。
- 使用带有softmax损失的线性层作为分类器(作为主分类器预测同样的1000类,但在预测时移除)。
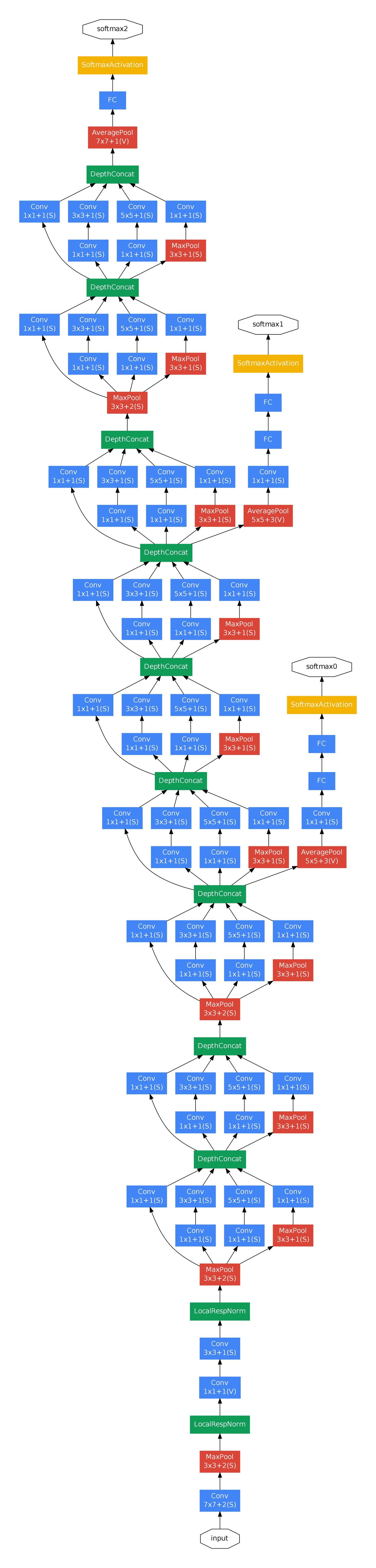
训练策略
在论文中,作者用了SGD+动量法,动量设为0.9,学习策略设置为每8个epoch会减小4%
ILSVRC 2014 设置和结果
-
在比赛中,首先最后的GoogLeNet是集成了七个版本的GoogLeNet得到的,它们都具有相同的超参数,为什么会不同呢,其实是因为,虽然我们的数据集是相同的,但是我们的数据集是被打乱的,说的更简单一点就是shuffle=True,所以就有可能导致我们的网络可能会有一些细微的不同
-
在训练时,作者还用了数据增强的方法,对每一张图片都进行裁剪,取样,镜像等操作,并且会将图像归一化为四个尺度,取不同的方块,最后一张图片可以得到144裁剪后的图片,然后再对其进行测试训练。
-
作者还尝试softmax概率在多个裁剪图像上和所有单个分类器上进行平均,然后获得最终预测。在我们的实验中,我们分析了验证数据的替代方法,例如裁剪图像上的最大池化和分类器的平均,但是它们比简单平均池化的性能略逊。
参考
以上是关于论文泛读 GooLeNet:更深的卷积网络的主要内容,如果未能解决你的问题,请参考以下文章