编译器一文看懂程序编译结构
Posted 极智视界
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了编译器一文看懂程序编译结构相关的知识,希望对你有一定的参考价值。
本教程详细介绍了程序编译的生命历程,主要包括五个阶段:词法分析、语法分析、语义分析、代码优化和目标代码生成过程。
程序编译的功能是将高级语言编写的源程序翻译成等价的机器语言或汇编语言的目标程序。
下面用一个计算圆周长的例子进行讲解。
float r, l; // r 为半径
l = 2 * 3.14 * r;
1、词法分析
词法分析对构成源程序的字符串从左到右进行扫描和拆分,识别出一个个独立的单词,上述源程序通过词法分析分解出如下单词:
基本字 flaot
标识符 r, l
常数 2, 3.14
运算符 =, *
界符 ;, =
2、语法分析
语法分析是在词法分析的基础上,根据语法规则从单词符号串中识别出各种语法单位,如表达式、语句等,并进行语法检查,语法规则是语法单位的形成规则。
上述例程中,在词法分析后根据语法规则识别出 l = 2 * 3.14 * r 中,“ l ”为变量,符号串 “2 * 3.14 * r” 组合成表达式,由 变量 = 表达式 构成 赋值语句。
3、语义分析
定义一种语言除了要定义语法外,还需要对语言的各种语法单位赋予具体的语义。
语义分析 是先对每种语法单位进行静态的语义审查,然后分析其含义,并用另一种更接近目标语言的一种中间代码 或 直接用目标语言来描述这种语义。
上述例程中,赋值语句的语义为:计算赋值号右边表达式的值,并把它送到赋值号左边的变量所在的内存单元中。语义分析时,先检查赋值号右边表达式和左边变量的类型是否一致,然后再根据赋值语句的语义,对其进行翻译得到如下四元式中间代码:
(1) (* , 2 , 3.14 , T1)
(2) (* , T1 , r , T2)
(3) (= , T2 , - , l)
其中,T1,T2 是编译程序引进的临时变量,存放每条指令的运算结果,上述每条四元式所表达的语义为:
2 * 3.14 => T1
T1 * r => T2
T2 => l
4、代码优化
代码优化是将语义分析产生的中间代码进行优化,使代码更加高效。优化的规则有很多,如上程序中可将常量先计算出来,执行的时候就不需要 T1 的过程了(神经网络里 conv + bn 算子融合的过程也是这个理),经代码优化后的四元式如下:
(1) (* , 6.28 , r , T1)
(3) (= , T1 , - , l)
可以看到编译器把 2 * 3.14 的过程给你算好了,你在执行的时候就少了一个中间变量的计算和存储开销。
5、目标代码生成
目标代码生成是将中间代码变换成特定机器上的绝对指令代码或可重定位的指令代码或汇编指令代码。
在编译程序的各个阶段中都会涉及表格管理和错误处理。符号表数据结构可以为变量名字创建记录条目,来登记源程序中所提供的或在编译过程中所产生的这些信息,编译程序在工作过程中的各个阶段需要构造、查找、修改或存取有关表格中的信息,所以编译程序中必须有一组管理各种表格的程序。若编译程序只需要处理正确的程序,那么它的设计会非常简单,但现实程序员往往期望编译器足够聪明来帮我们查找错误。对于编译器的期望高了,从设计编译器的角度来说也就更加复杂了。
编译过程的这5个阶段分别由5个程序完成,分别为 词法分析程序、语法分析程序、语义分析程序、代码优化程序、目标代码生成程序,另外加上表格管理程序和错误处理程序组成,这些程序是程序编译过程的主要组成部分。
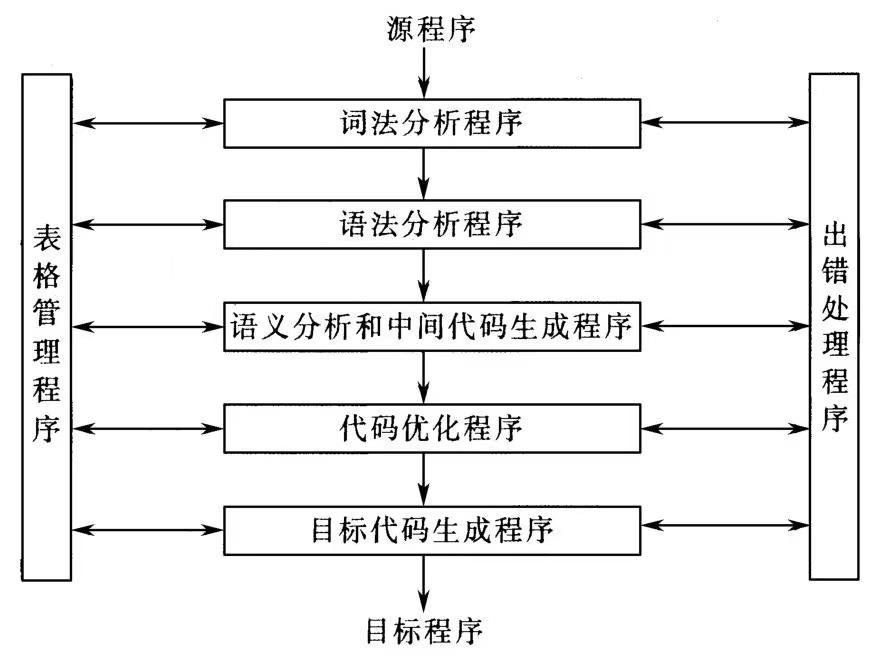
上图各阶段的关系只是逻辑关系,不一定是执行先后关系。实际可用不同的 pipeline 来组织上述各阶段,这依赖编译过程中对源程序扫描的遍数以及如何划分各遍扫描。多遍扫描的编译程序较一遍扫描的编译程序少占存储,遍数越多,可使各遍所完成的功能独立而单纯,但遍数多会增加输入输出开销,这将降低编译效率,遍数是个很难确定的超参。
就这样吧,收工~
扫描下方二维码即可关注我的微信公众号【极智视界】,获取更多AI经验分享,让我们用极致+极客的心态来迎接AI !

以上是关于编译器一文看懂程序编译结构的主要内容,如果未能解决你的问题,请参考以下文章