论文赏析:极致性价比,非易失性内存在向量检索的应用
Posted Zilliz
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文赏析:极致性价比,非易失性内存在向量检索的应用相关的知识,希望对你有一定的参考价值。
HM-ANN: Efficient Billion-Point Nearest Neighbor Search on Heterogenous Memory 是一篇被2020年 Conference on Neural Information Processing Systems (NeurIPS 2020). 本文提出了一种基于图的相似性搜索的新型算法,称为HM-ANN。该算法在现代硬件设置中同时考虑了内存异质性和数据异质性。HM-ANN可以在单台机器上实现十亿级的相似性搜索,同时没有采用任何数据压缩技术。异质存储器(HM)代表了快速但小的DRAM和缓慢但大的PMem的组合。HM-ANN实现了低搜索延迟和高搜索精度,特别是在数据集无法装入单机有限DRAM的情况下。与最先进的近似近邻(ANN)搜索方案相比,该算法具有明显的优势。
动机
由于DRAM容量有限,ANN搜索算法在查询精度和查询延迟之间进行了基本的权衡。为了在DRAM中存储索引以实现快速查询,有必要限制数据点的数量或存储压缩的向量,这两者都会损害搜索的准确性。基于图形的索引(如HNSW)具有优越的查询运行时间性能和查询精度。然而,当在十亿规模的数据集上操作时,这些索引也会消耗TiB等级的DRAM。
还有其他的变通方法来避免让DRAM以原始格式存储十亿规模的数据集。当一个数据集太大,无法装入单台机器的DRAM时,就会使用数据压缩的方法,如对数据集的点进行乘积量化。但是,由于量化过程中精度的损失,这些索引在压缩数据集上的召回率通常很低。Subramanya等人[1]探索了利用固态硬盘SSD实现十亿级ANN搜索的方法,该方法称为Disk-ANN,其中原始数据集存储在SSD上,压缩后的表示方法存储在DRAM上。
Heterogeneous Memory的介绍
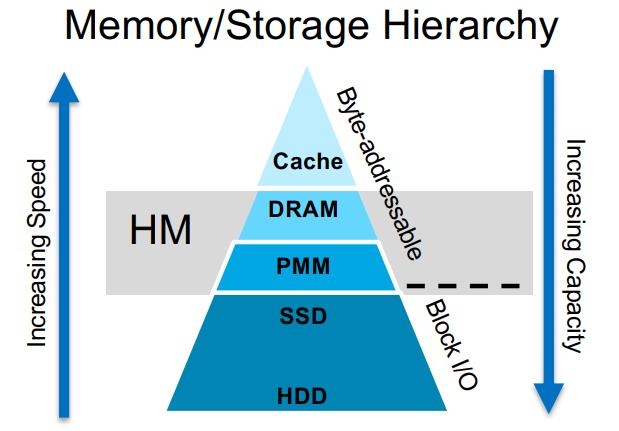
内存/存储的层次结构与HM
图片来源: http://nvmw.ucsd.edu/nvmw2021...
Heterogeneous memory (HM) 代表了快速但小的DRAM和慢速但大的PMem的组合。DRAM是每个现代服务器中都能找到的硬件,其访问速度相对较快。新的PMem技术,如英特尔® Optane™DC Persistent Memory Modules,弥补了基于 NAND-based flash(SSD)和DRAM之间的差距,消除了I/O瓶颈。PMem像SSD一样可以在断电情况下持久化数据,又像DRAM一样可由CPU直接对每一个Byte寻址。Renen等人[2]发现,在配置的实验环境中,PMem的读取带宽比DRAM低2.6倍,而写入带宽低7.5倍。
HM-ANN 的设计
HM-ANN是一种准确而快速的十亿级ANN搜索算法,在单机上运行时无需压缩。HM-ANN的设计概括了HNSW的思想,其分层结构自然适合HM。HNSW由多层组成: 只有第0层包含整个数据集,其余每一层都包含其正下方那一层的一个子集。
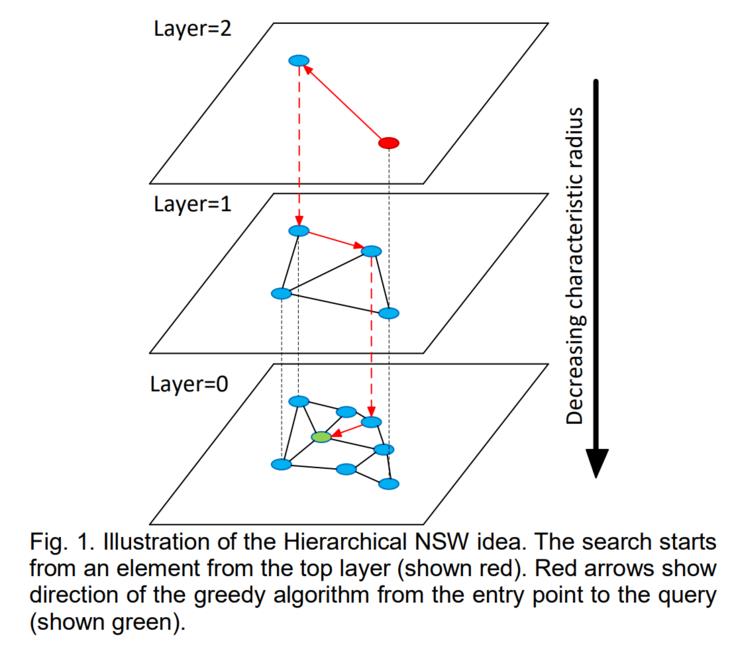
一个 3 层 HNSW 的例子
图片来源: https://arxiv.org/pdf/1603.09...
上层的元素,只包括数据集的子集,消耗了整个存储消耗的一小部分。这一现象使它们非常合适去被放置在DRAM中。这样一来,HM-ANN上的大部分搜索都会发生在上层,这就最大限度地利用了DRAM的快速访问特性。然而,在HNSW中大多数搜索发生在底层。
最底层承载着整个数据集,这使得它适合被放在PMem中。 由于访问第0层的速度较慢,最好是每个查询只访问一小部分,并降低访问频率。
图构建算法
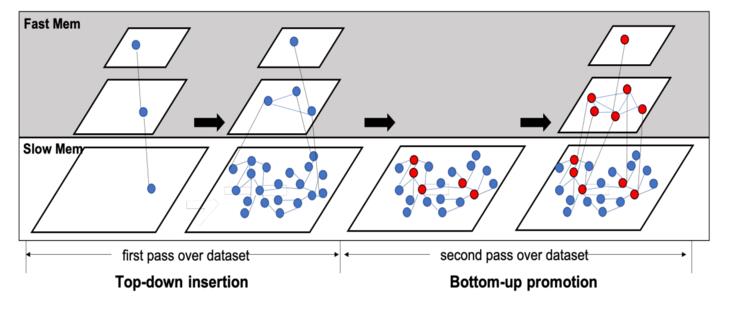
HM-ANN的索引构造例子
图片来源: http://nvmw.ucsd.edu/nvmw2021...
HM-ANN构造的关键思想是构建高质量的上层,以便为第0层的搜索提供更好的导航指导能力。因此,大多数内存访问发生在DRAM中,所以PMem中的访问则被减少。为了实现这一点,HM-ANN的构建算法有一个自上而下的selection阶段和一个自下而上的promotion阶段。
自上而下的插入阶段建立了一个navigable small-world graph,因为最底层是放在PMem上的。
自下而上的促进阶段从底层promote pivot点,以形成放置在DRAM上的上层,而不会失去很多准确性。如果在第1层创建了第0层元素的高质量投影,那么第0层的搜索只需几跳就能找到查询的准确近邻。
HM-ANN没有使用HNSW的random selection for promotion,而是使用高度推广策略high-degree promotion strategy,将第0层中度数最高的元素推广到第1层。对于更高的层,HM-ANN根据 promotion rate将高度数节点推广到上层。
HM-ANN将更多的节点从第0层promote到第1层,并为第1层的每个元素设置更大的最大邻居数。上层节点的数量是由可用的DRAM空间决定的。由于第0层不存储在DRAM中,因此使存储在DRAM中的每一层更密集,可以提高搜索质量。
图搜索算法
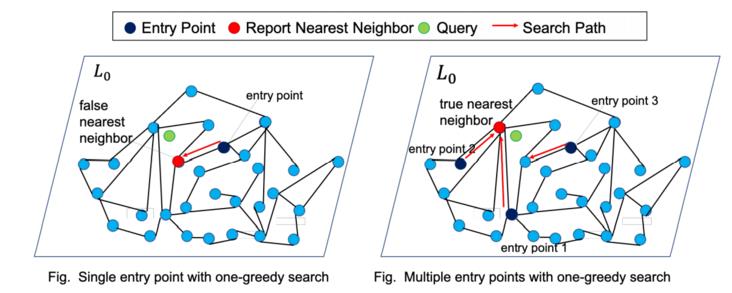
HM-ANN的索引搜索例子
图片来源: http://nvmw.ucsd.edu/nvmw2021...
该搜索算法由两个阶段组成: fast memory search 与 parallel layer-0 search with prefetching.
Fast memory search
与HNSW相同,DRAM中的搜索从最顶层的入口点开始,然后从顶层到第2层执行1-greedy search。为了缩小第0层的搜索空间,HM-ANN在第1层进行搜索,搜索预算为 efSearchL1,这限制了第1层的candidate list的大小。HNSW只使用一个entry point,但在HM-ANN中,第0层和第1层之间的关系比任何其他两层之间处理得更加特别。
Parallel layer-0 search with prefetching
在底层,HM-ANN将上述来自搜索第1层的candidates均匀分开,并将其视为entry points,以执行parallel multi-start 1-greedy search with threads。每次搜索出来的top candidates被收集起来,以找到best candidates。众所周知,从第1层下到第0层正好是进入PMem。 并行搜索隐藏了PMem的延迟,并充分利用内存带宽,在不增加搜索时间的情况下提高搜索质量。
HM-ANN在DRAM中实现了一个software-managed buffer,在DRAM访问发生之前从PMem中prefetch数据。当搜索第1层时,HM-ANN异步地将 efSearchL1中的那些candidates的邻居元素及其在第1层的连接从PMem复制到buffer。当第0层的搜索发生时,一部分数据已经在DRAM中被prefetched了,这就隐藏了访问PMem的延迟,导致了更短的查询时间。这与HM-ANN的设计目标相吻合,即大部分内存访问发生在DRAM中,而PMem中的内存访问被减少。
性能测试
在HM-ANN这个论文中,对这个新索引算法进行了广泛的评估。所有的实验都是在一台装有Intel Xeon Gold 6252 CPU@2.3GHz 的机器上进行的。它使用DDR4(96GB)作为快速内存,Optane DC PMM(1.5TB)作为慢速内存。对五个数据集进行了评估。BIGANN、DEEP1B、SIFT1M、DEEP1M和GIST1M。对于十亿规模的测试,包括以下方案:基于十亿规模量化的方法(IMI+OPQ和L&C),以及非压缩的方法(HNSW和NSG)。
十亿规模的算法比较
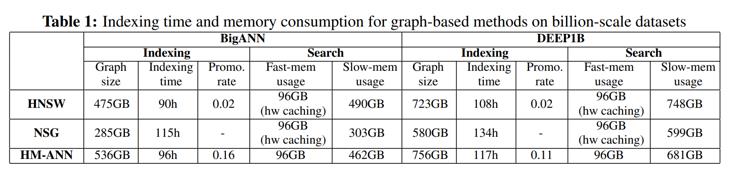
在Table 1中,比较了不同的基于图的索引的索引时间和内存消耗。HNSW在建立索引时速度最快,HM-ANN比HNSW多需要8%的时间。在总体存储使用方面,HM-ANN索引比HSNW大5-13%,因为它将更多的节点从第0层推广到第1层。
在Figure 1中,对不同索引的查询性能进行了分析。图1(a)和(b)显示,HM-ANN在1毫秒内取得了>95%的top-1召回率。图1(c)和(d)显示,HM-ANN在4毫秒内获得了>90%的top-100召回率。与其他所有方法相比,HM-ANN提供了更好的latency-recall性能。
百万规模的算法比较
在Figure 2中,不同索引的查询性能在纯DRAM环境下进行了分析。HNSW、NSG和HM-ANN是用一个适合DRAM容量的300万规模的数据集进行评估的。HM-ANN仍然取得了比HNSW更好的查询性能。原因是,当它们都旨在实现99%的召回率目标时,HM-ANN的距离计算总数(平均850次/查询)要少于HNSW(平均900次/查询)。
High-degree promotion的效果
在Figure 3中,random promotion和high-degree promotion strategies在同一配置下进行了比较。high-degree promotion strategies的效果优于baseline。在达到95%、99%和99.5%的召回率目标时,high-degree promotion strategies 的表现比random promotion快1.8倍、4.3倍和3.9倍。
内存管理技术的性能
Figure 5包含了HNSW和HM-ANN之间的一系列步骤,以显示HM-ANN的每项优化对其改进的贡献。BP代表索引构建中自下而上的promotion,PL0代表Parallel layer-0 search,DP代表从PMem到DRAM的数据prefetching。每走一步,HM-ANN的搜索性能都会被进一步推高。
结论
一种新的基于图的索引和搜索算法,称为HM-ANN,将基于图的ANN搜索算法的分层设计与HM中的快慢内存异质性进行了映射。评估表明,HM-ANN是一种新的最先进的适用于十亿数据集的索引。
在学术界和工业界中,在PMem上建立索引正变得越来越流行。为了减轻DRAM的压力,Disk-ANN[1]是一个建立在SSD上的索引,但是SSD吞吐量明显低于PMem。 然而,建立HM-ANN仍然需要几天时间,这与Disk-ANN的构建时间没有数量级的区别。我们相信,通过更仔细地利用PMem的特性(例如,意识到PMem的粒度为256字节),以及使用指令bypass cache lines,是可以优化HM-ANN的索引时间。我们还预计,将来会提出更多的持久存储设备的方法。
参考资料
[1] Suhas Jayaram Subramanya and Devvrit and Rohan Kadekodi and Ravishankar Krishaswamy and Ravishankar Krishaswamy: DiskANN: Fast Accurate Billion-point Nearest Neighbor Search on a Single Node, NIPS, 2019
(https://www.microsoft.com/en-...)
(https://papers.nips.cc/paper/...)
[2] Alexander van Renen and Lukas Vogel and Viktor Leis and Thomas Neumann and Alfons Kemper: Persistent Memory I/O Primitives, CoRR & DaMoN, 2019
(https://dl.acm.org/doi/abs/10...)
(https://arxiv.org/abs/1904.01614)
作者:罗济高,Zilliz 实习研究员,本科毕业于慕尼黑工业大学,目前是该校数据工程与分析专业研究生在读。兴趣领域包含关系数据库与性能分析,喜欢研究关系数据库內核,对数据库各个子领域的进展拥有高度好奇心。他的 Github 账号是 https://github.com/cakebytheo...,博客地址是 https://cakebytheoceanluo.git...
以上是关于论文赏析:极致性价比,非易失性内存在向量检索的应用的主要内容,如果未能解决你的问题,请参考以下文章