一战《中国作物种质信息网》(再也不怕没有小麦数据源了)
Posted ZSYL
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一战《中国作物种质信息网》(再也不怕没有小麦数据源了)相关的知识,希望对你有一定的参考价值。
前言
最近项目需要获取小麦数据源,因此着手《中国作物种质信息网》的数据爬取。
link:https://www.cgris.net/default.asp#
分析
- 进入小麦专区后:link
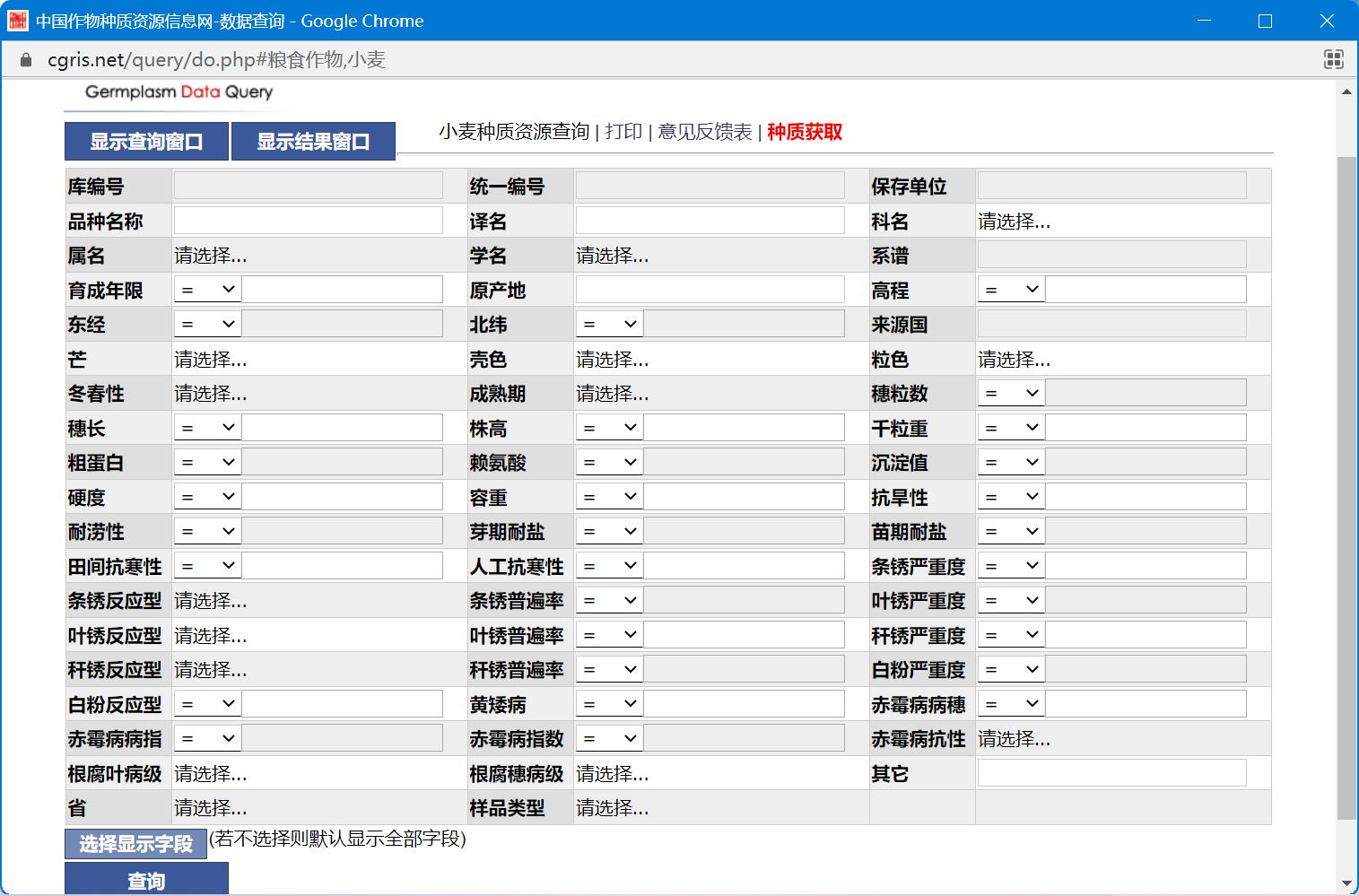
可以根据小麦相应字段进行指定查询 (若不选择则默认显示全部字段)
- 选择默认查询,则获得全部的小麦信息
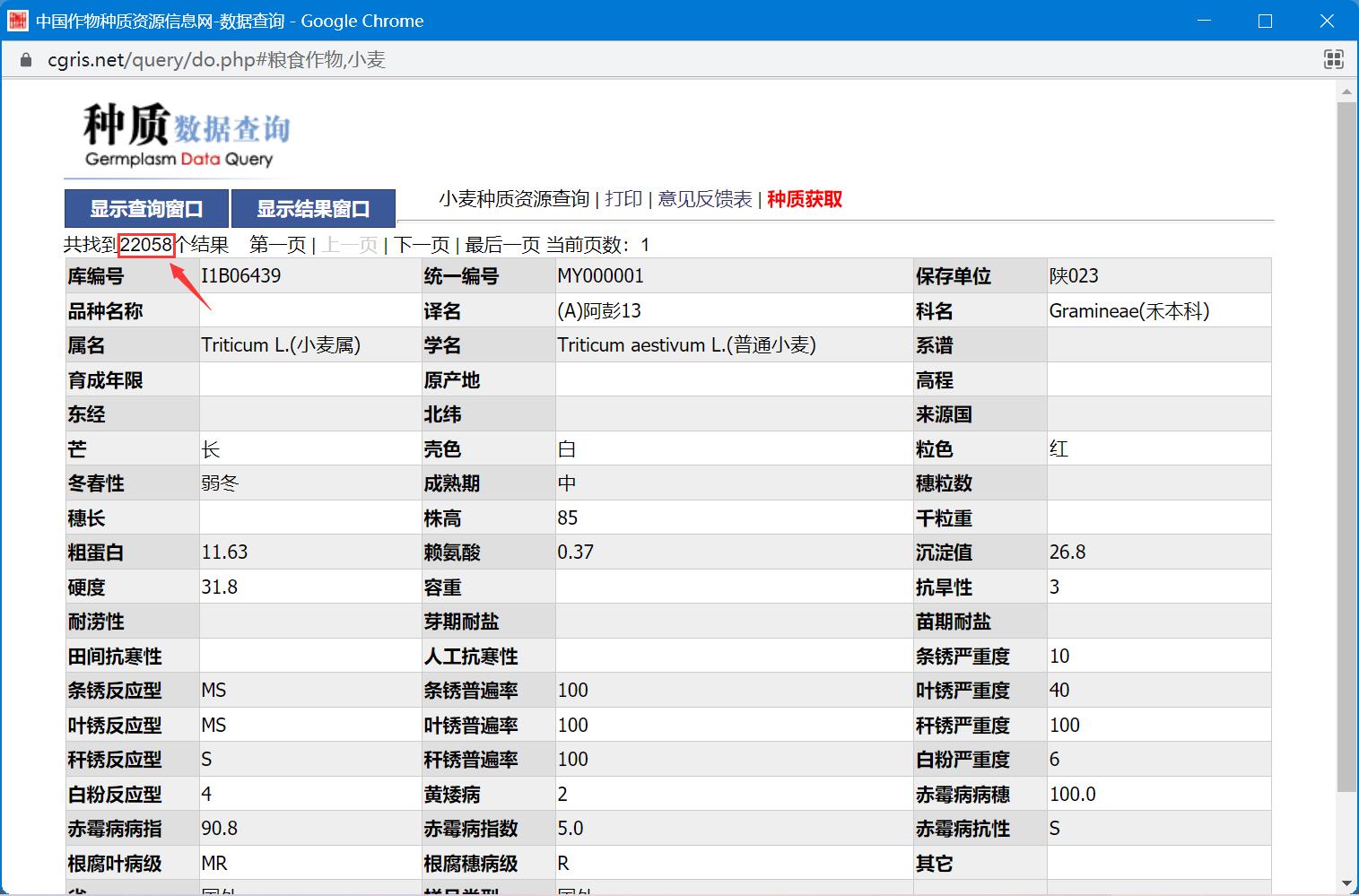
哇哦!
22058条数据,够了够了!
- 检查页面源代码
发现里面没有我们需要的内容,可以猜测,该内容是服务器二次发送来的,而且可能是进行数据库的查询操作。
-
源代码没有数据,只能考虑数据抓包
-
F12 --> Network --> Fetch
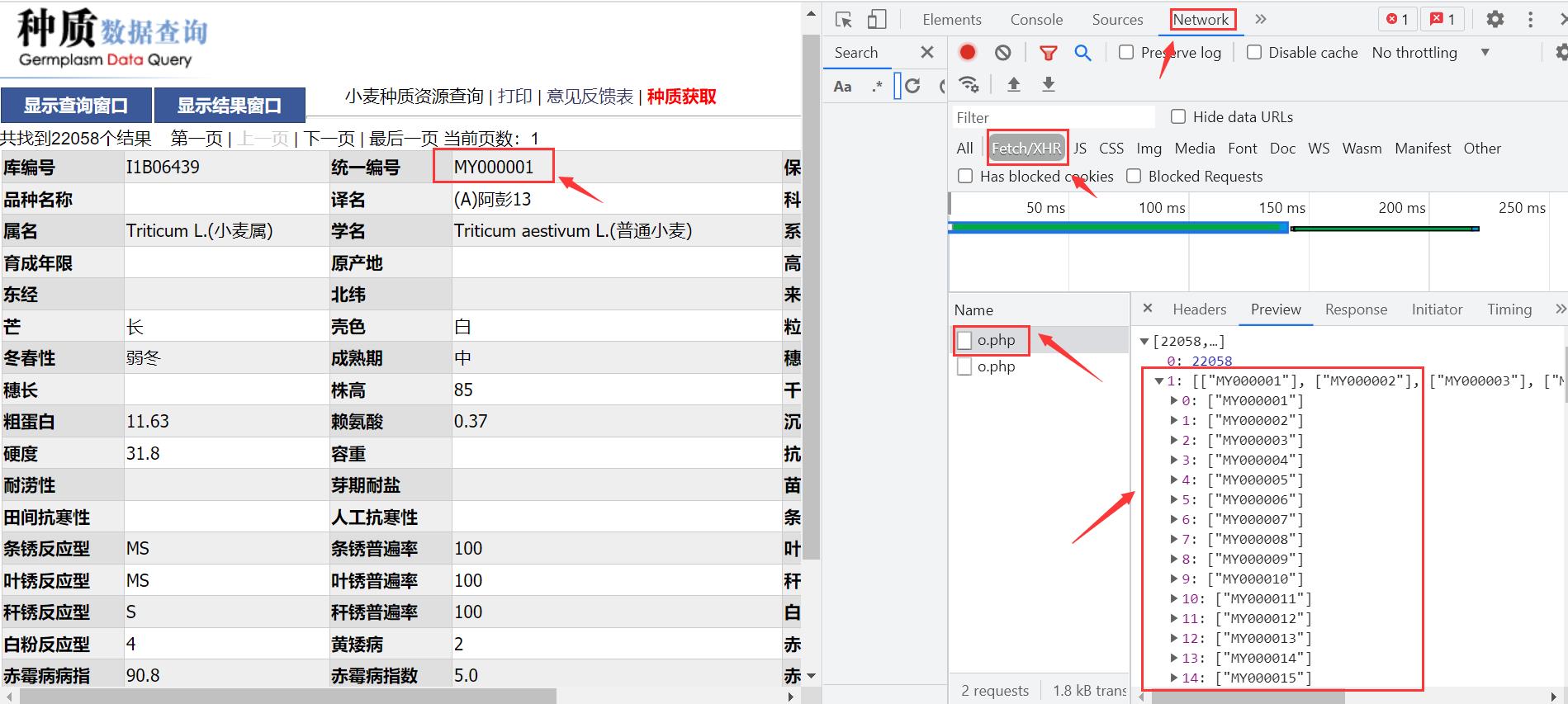
刷新之后,发现第一个数据包里面,好像与字段库编号对应。
- 查看下一个数据包
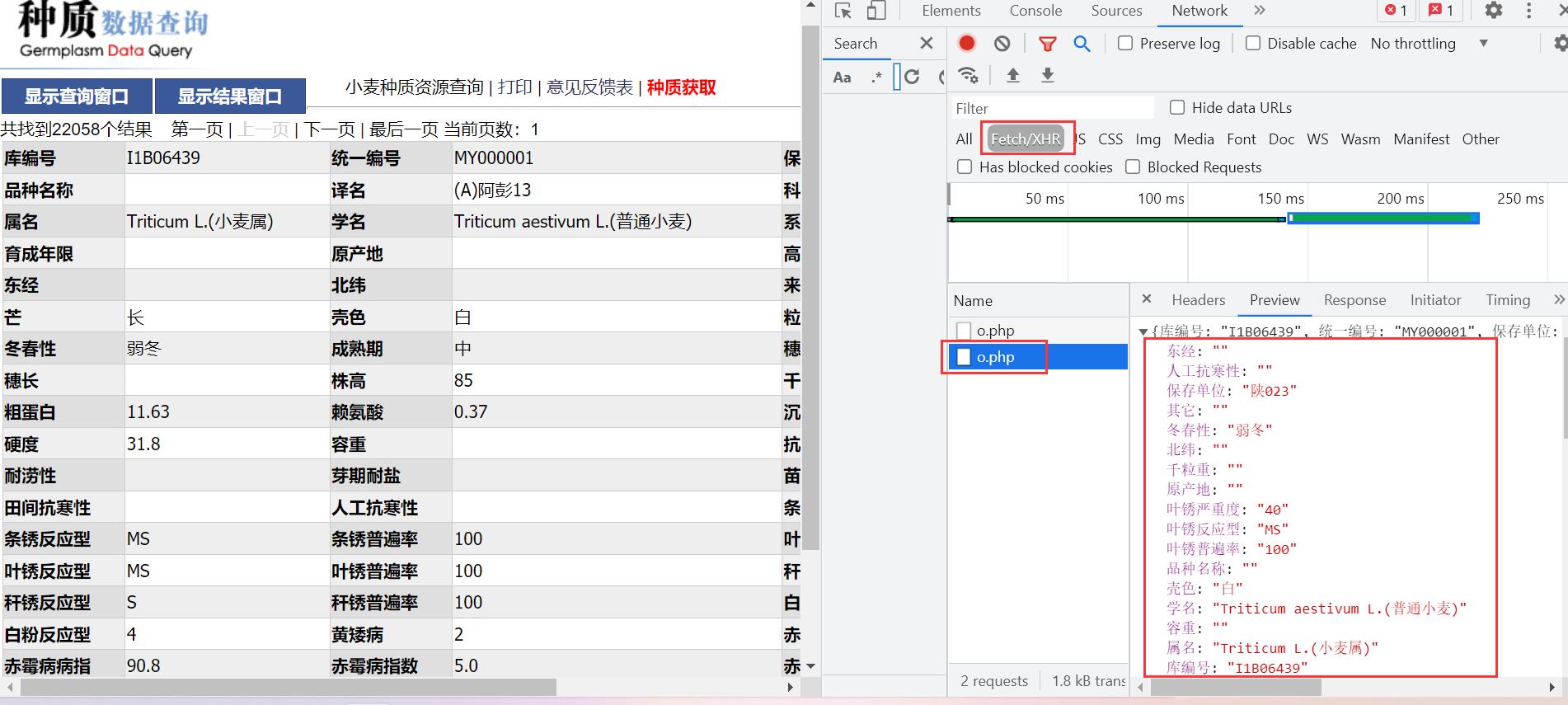
这不就是数据嘛!
- 获取请求url及请求方式post
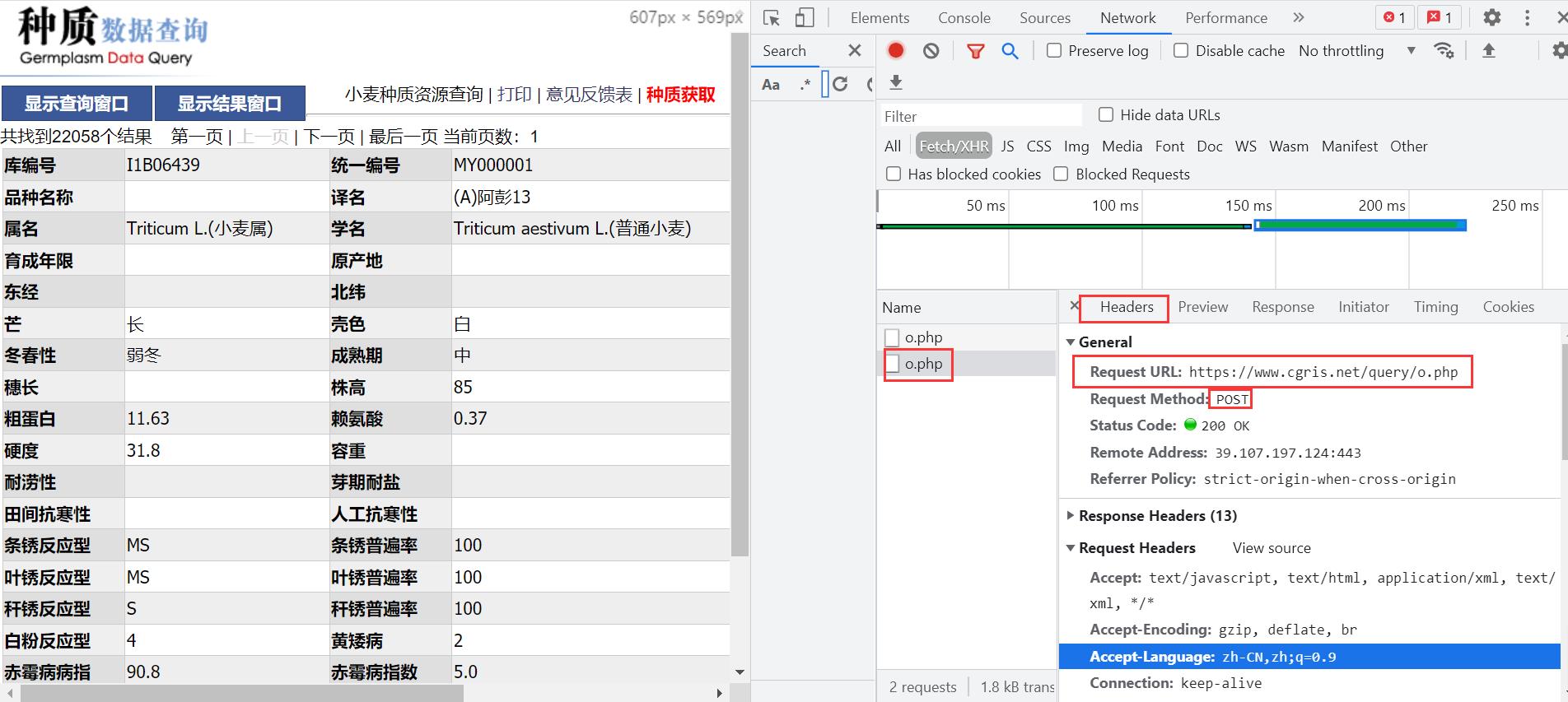
Request URL: https://www.cgris.net/query/o.php
- 查看post请求的
Form Data
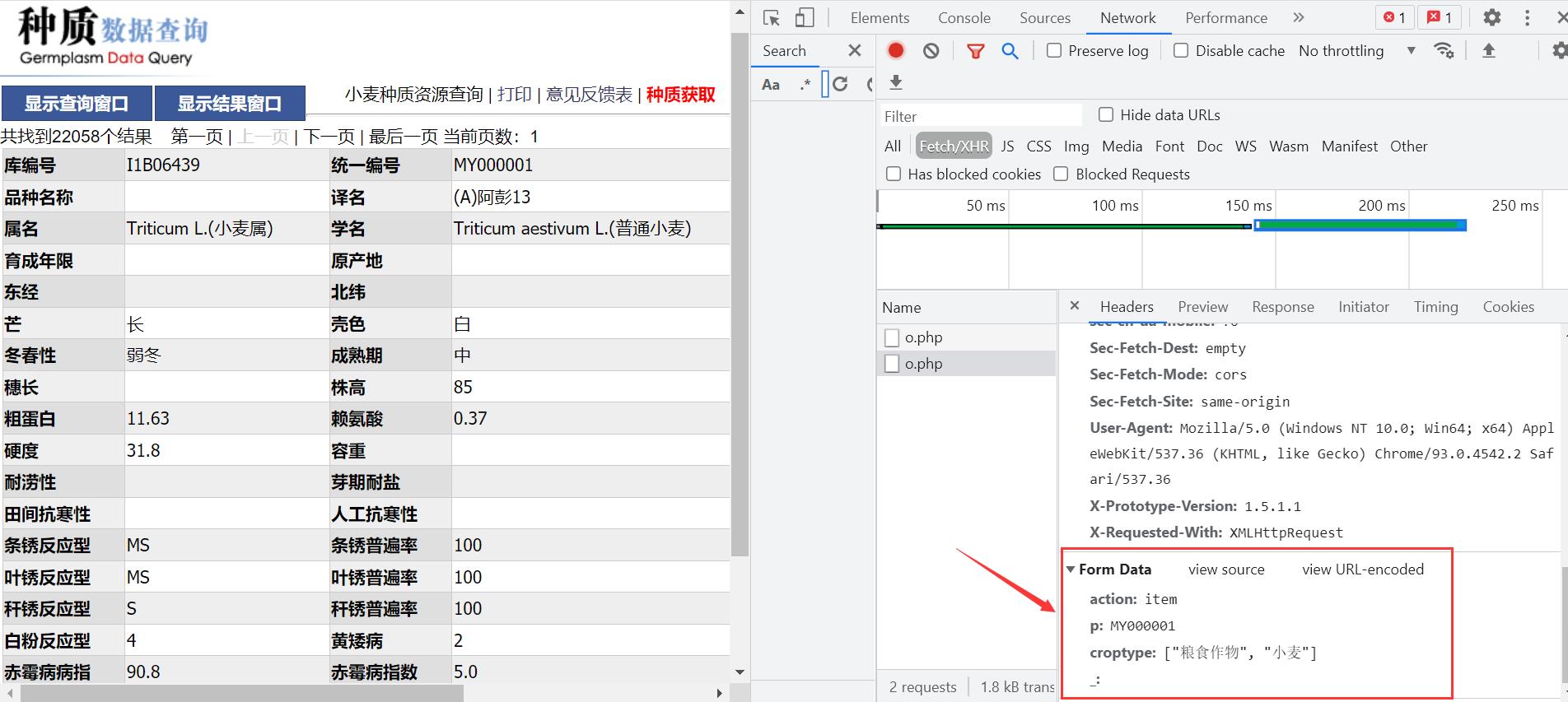
有了这些就上代码吧!
获取一页数据
# 获取一页的小麦数据
def getData(url, index):
# 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/93.0.4542.2 Safari/537.36',
'Referer': url # 防盗链
}
data = {
'action': 'item',
'p': f'MY0{index}',
'croptype': '["粮食作物", "小麦"]',
}
# 获取post请求对象
resp = requests.post(url, headers=headers, data=data)
多线程获取多页面
# 获取大小50的线程池
with ThreadPoolExecutor(3) as pool:
for i in range(1390, 2000):
pool.submit(getData, url=url, index='%05d'%i)
time.sleep(3)
存入CSV文件
# 获取csv文件
file = open('./wheat.csv', mode='a', encoding='utf-8', newline='')
# 建立一个字典写入对象,并指定列名fieldnames
csvWriter = csv.DictWriter(file, fieldnames=fieldnames)
# 写入表头
csvWriter.writeheader()
完整代码
# 爬取小麦数据
# MY0:14400
"""
action: item
p: MY014200
croptype: ["粮食作物", "小麦"]
_:
"""
'''
Referer: https://www.cgris.net/query/do.php
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4542.2 Safari/537.36
'''
import requests
import csv
from concurrent.futures import ThreadPoolExecutor
import time
# 设置表头
fieldnames = ['库编号', '统一编号', '保存单位', '品种名称', '译名', '科名', '属名', '学名', '系谱', '育成年限', '原产地', '高程', '东经', '北纬', '来源国',
'芒', '壳色', '粒色', '冬春性', '成熟期', '穗粒数', '穗长', '株高', '千粒重', '粗蛋白', '赖氨酸', '沉淀值', '硬度', '容重', '抗旱性',
'耐涝性', '芽期耐盐', '苗期耐盐', '田间抗寒性', '人工抗寒性', '条锈严重度', '条锈反应型', '条锈普遍率', '叶锈严重度', '叶锈反应型', '叶锈普遍率',
'秆锈严重度', '秆锈反应型', '秆锈普遍率', '白粉严重度', '白粉反应型', '黄矮病', '赤霉病病穗', '赤霉病病指', '赤霉病指数', '赤霉病抗性', '根腐叶病级',
'根腐穗病级', '其它', '省', '样品类型']
# 获取csv文件
file = open('./wheat.csv', mode='a', encoding='utf-8', newline='')
# 建立一个字典写入对象,并指定列名fieldnames
csvWriter = csv.DictWriter(file, fieldnames=fieldnames)
# 写入表头
csvWriter.writeheader()
# 获取一页的小麦数据
def getData(url, index):
# 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4542.2 Safari/537.36',
'Referer': url # 防盗链
}
data = {
'action': 'item',
'p': f'MY0{index}',
'croptype': '["粮食作物", "小麦"]',
}
# 获取post请求对象
resp = requests.post(url, headers=headers, data=data)
# 写入数据
csvWriter.writerow(resp.json())
print('库编号', data['p'], '爬取完毕!')
if __name__ == '__main__':
# 访问地址
url = 'https://www.cgris.net/query/o.php'
# 获取大小50的线程池
with ThreadPoolExecutor(3) as pool:
for i in range(1390, 2000):
pool.submit(getData, url=url, index='%05d'%i)
time.sleep(3)
# 关闭文件流,确保数据正常写入
file.close()
结果展示
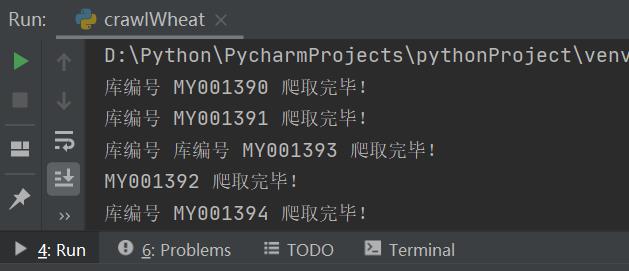
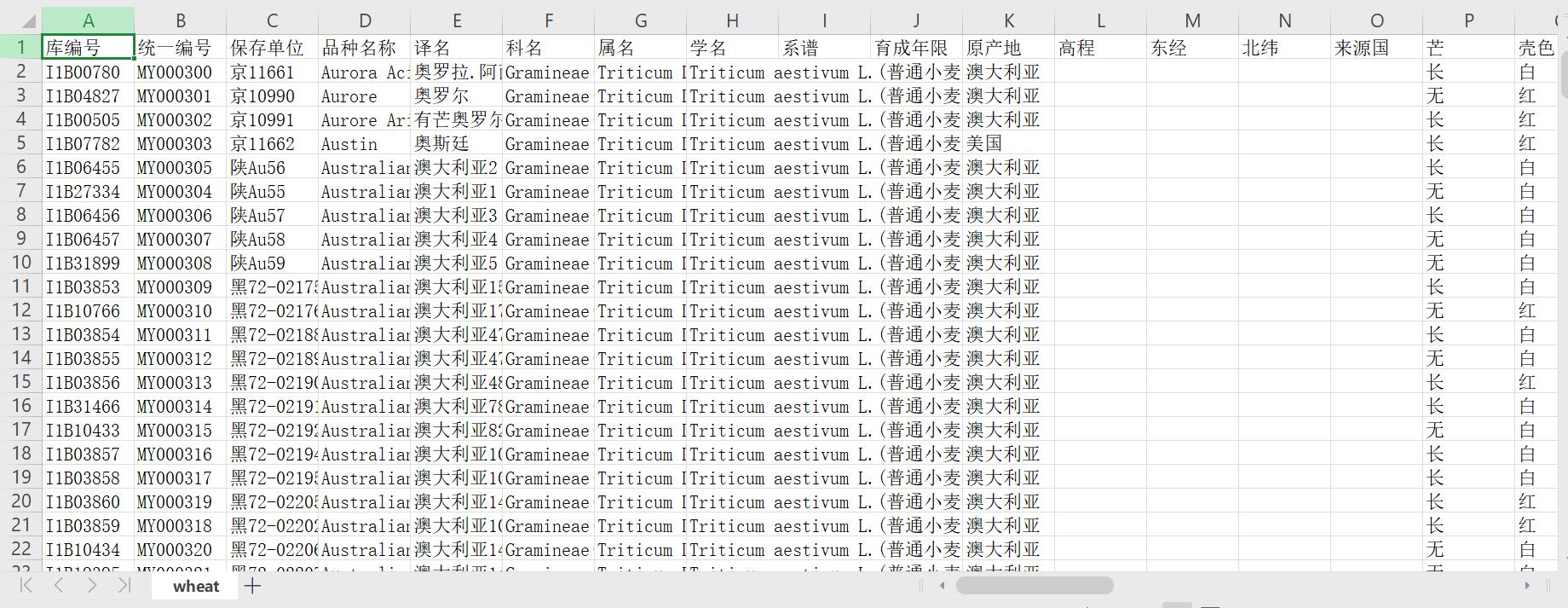
后序
不过请注意,实践时,你会发现数据下载特别缓慢,因为服务器的缘故吧,如果你开的线程数过多,或者同时请求次数过多,会导致服务器崩溃的,因此建议,线程尽量开少点,每个线程间 sleep() 几秒。
我刚开始就直接把服务器给搞崩了(负罪)o(╥﹏╥)o
正是因为这个原因,我要换其他方法,二战《中国作物种质信息网》
加油!
感谢!
努力!
以上是关于一战《中国作物种质信息网》(再也不怕没有小麦数据源了)的主要内容,如果未能解决你的问题,请参考以下文章