史诗级干货长文集成学习算法
Posted ZSYL
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了史诗级干货长文集成学习算法相关的知识,希望对你有一定的参考价值。
集成学习算法
1. 集成学习算法简介
学习目标
- 了解什么是集成学习
- 知道机器学习中的两个核心任务
- 了解集成学习中的boosting和bagging
1.1 什么是集成学习
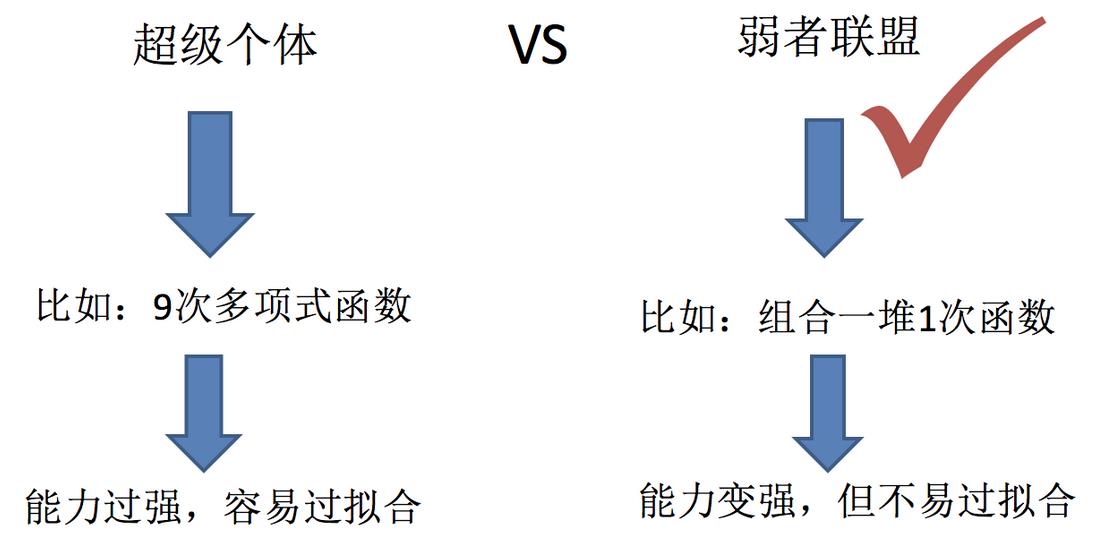
集成学习通过建立几个模型来解决单一预测问题。它的工作原理是生成多个分类器/模型,各自独立地学习和作出预测。这些预测最后结合成组合预测,因此优于任何一个单分类的做出预测。
1.2 复习:机器学习的两个核心任务
- 任务一:如何优化训练数据 —> 主要用于解决欠拟合问题
- 任务二:如何提升泛化性能 —> 主要用于解决过拟合问题
1.3 集成学习中boosting和Bagging
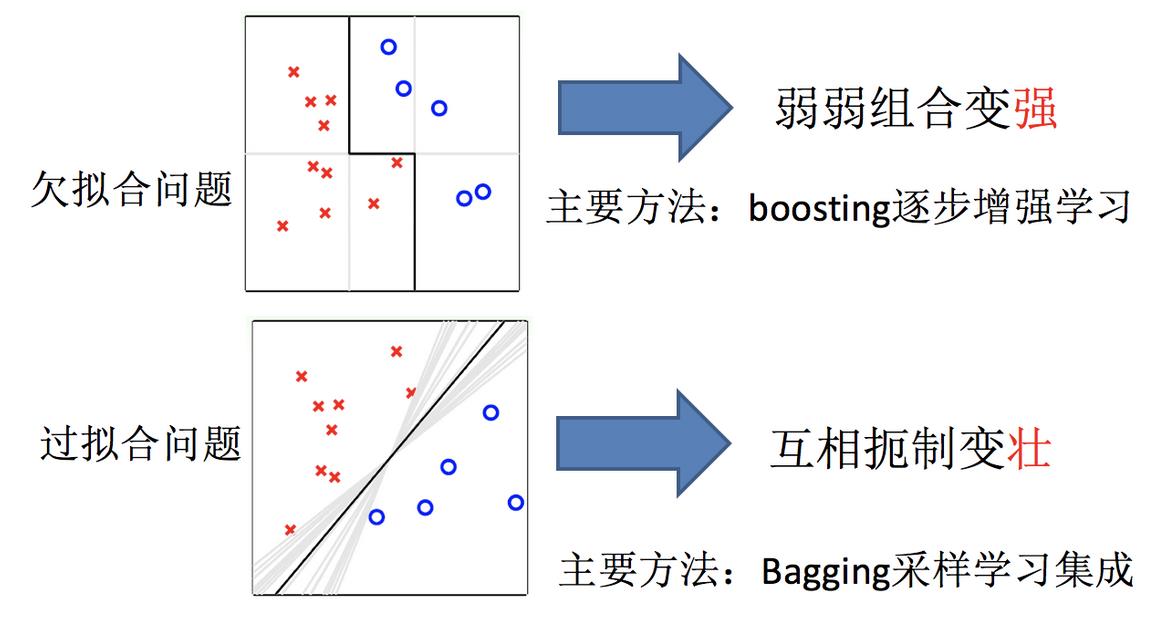
只要单分类器的表现不太差,集成学习的结果总是要好于单分类器的
1.4 小结
- 什么是集成学习
- 通过建立几个模型来解决单一预测问题
- 机器学习两个核心任务
- 1.解决欠拟合问题
- 弱弱组合变强
- boosting
- 2.解决过拟合问题
- 互相遏制变壮
- Bagging
- 1.解决欠拟合问题
2. Bagging和随机森林
学习目标
- 知道Bagging集成原理
- 知道随机森林构造过程
- 知道RandomForestClassifier的使用
- 了解baggind集成的优点
2.1 Bagging集成原理
目标:把下面的圈和方块进行分类
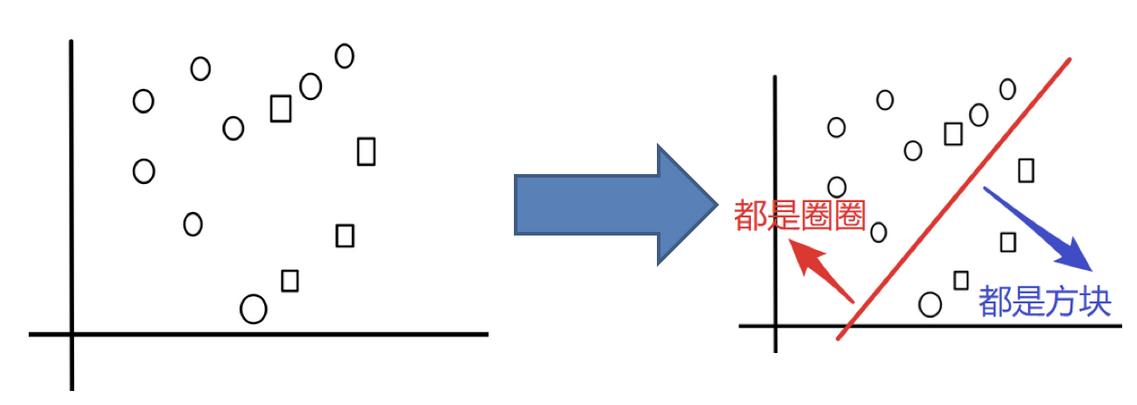
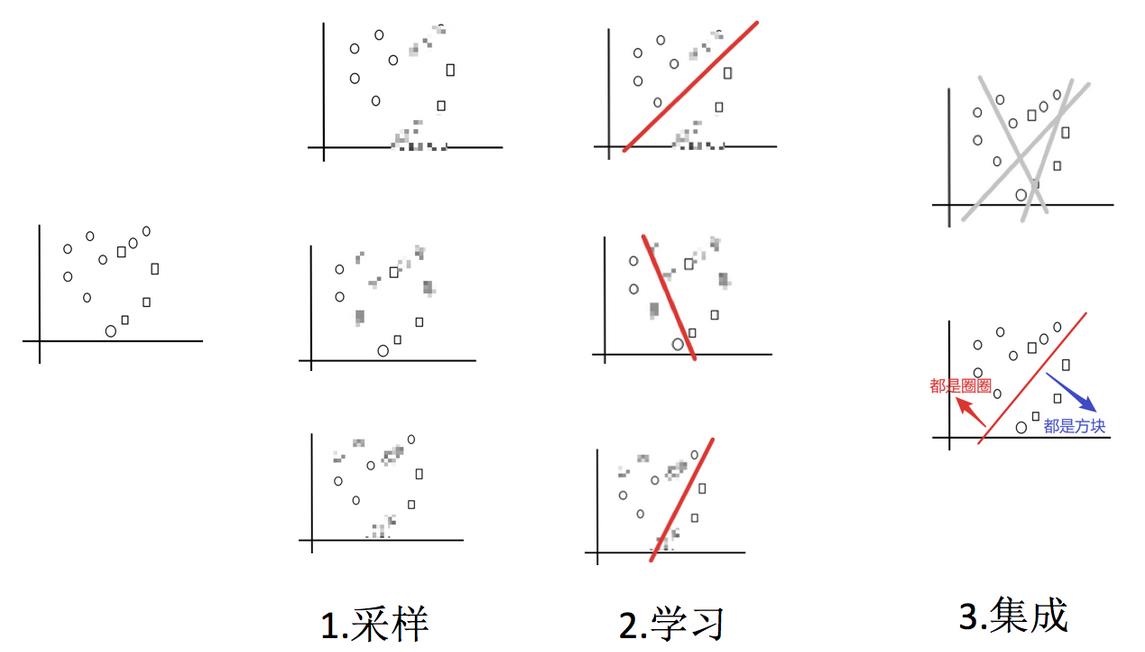
实现过程:
1.采样不同数据集
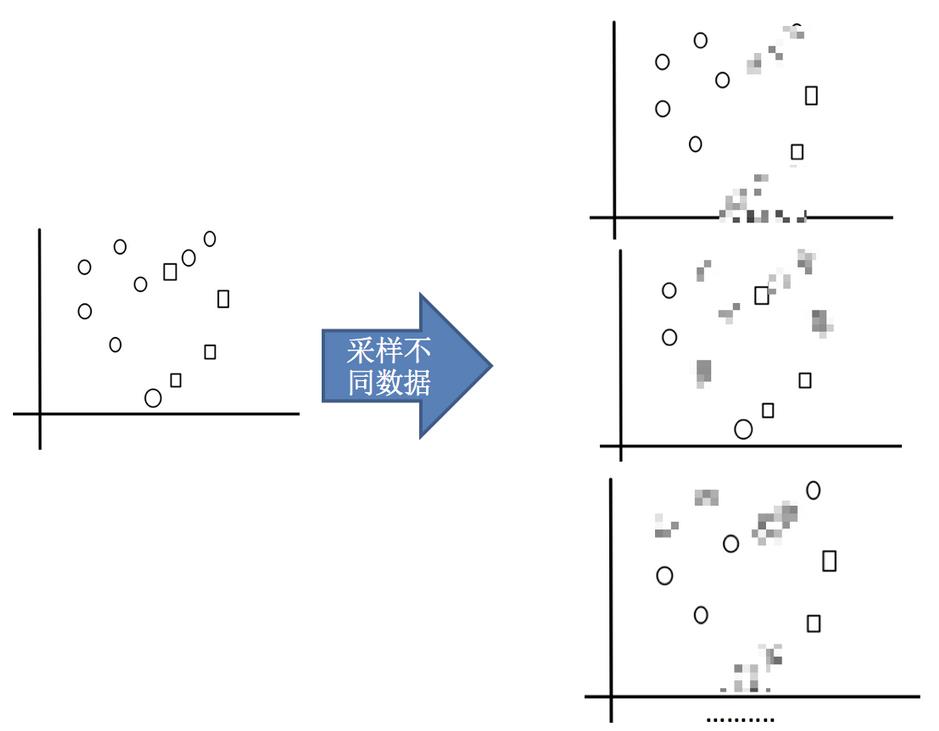
2.训练分类器
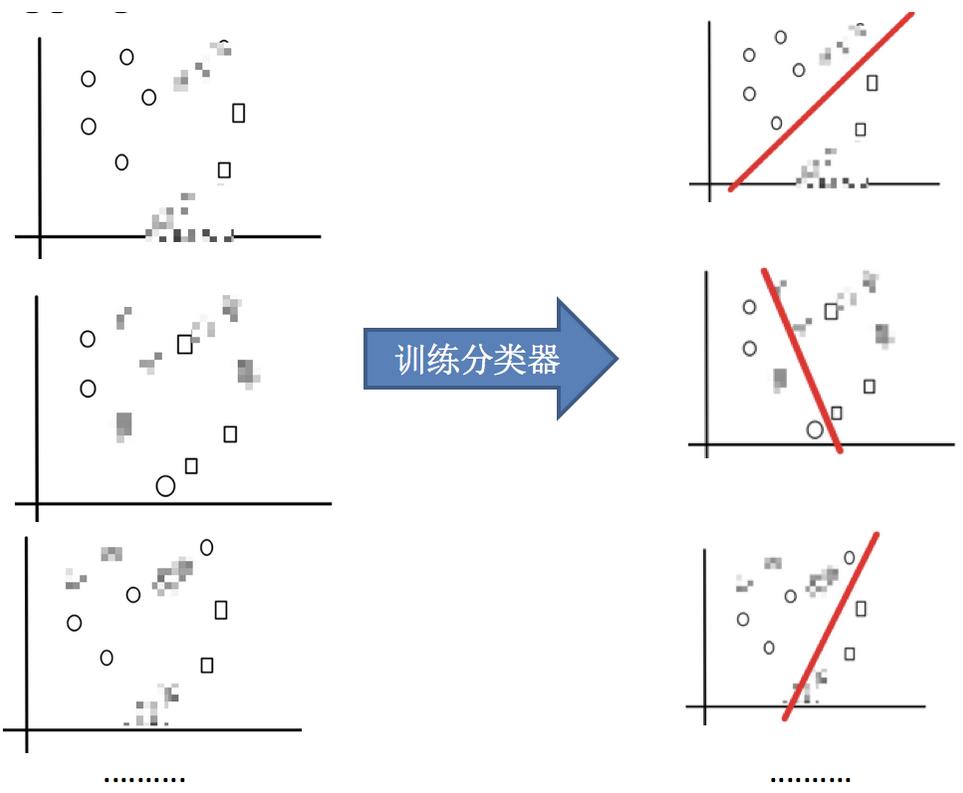
3.平权投票,获取最终结果
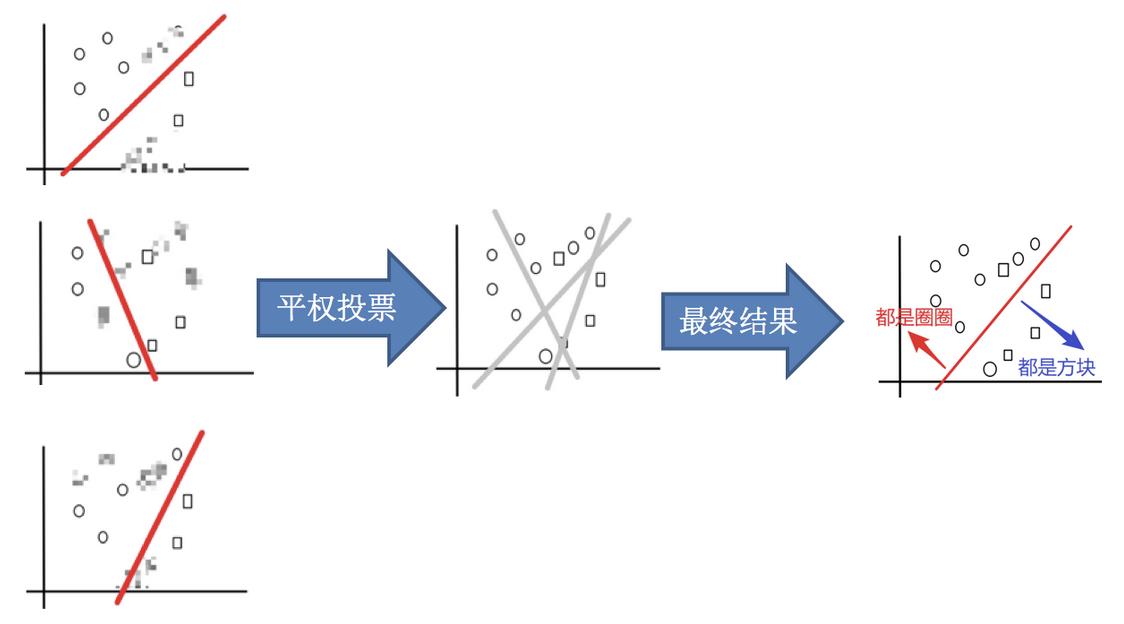
4.主要实现过程小结
2.2 随机森林构造过程
在机器学习中,随机森林是一个包含多个决策树的分类器,并且其输出的类别是由个别树输出的类别的众数而定。
随机森林 = Bagging + 决策树
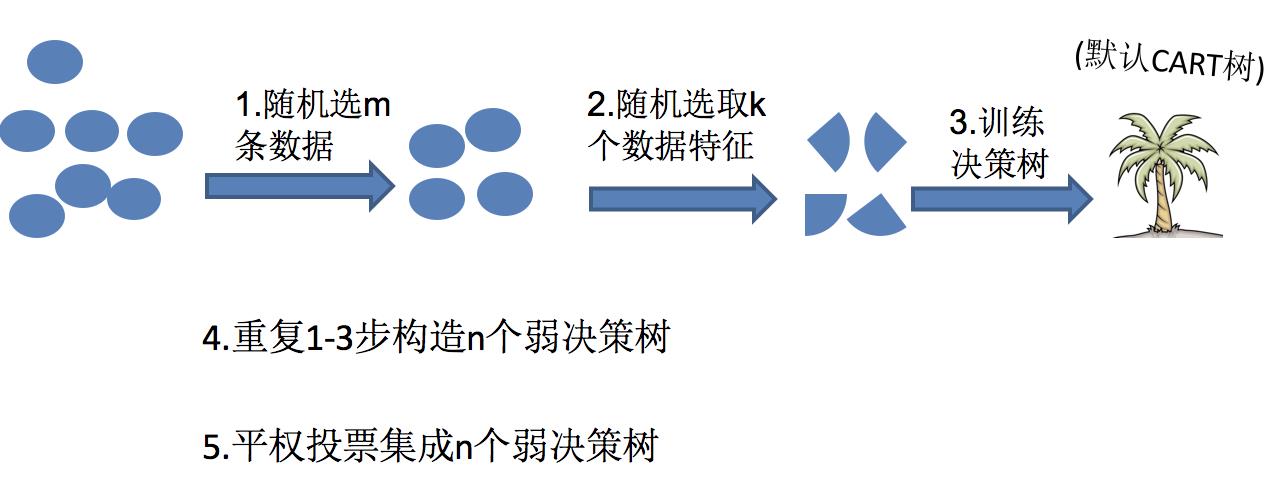
例如, 如果你训练了5个树, 其中有4个树的结果是True, 1个树的结果是False, 那么最终投票结果就是True
随机森林够造过程中的关键步骤(M表示特征数目):
1)一次随机选出一个样本,有放回的抽样,重复N次(有可能出现重复的样本)
2) 随机去选出m个特征, m <<M,建立决策树
思考
- 1.为什么要随机抽样训练集?
- 如果不进行随机抽样,每棵树的训练集都一样,那么最终训练出的树分类结果也是完全一样的
- 2.为什么要有放回地抽样?
- 如果不是有放回的抽样,那么每棵树的训练样本都是不同的,都是没有交集的,这样每棵树都是“有偏的”,都是绝对“片面的”(当然这样说可能不对),也就是说每棵树训练出来都是有很大的差异的;而随机森林最后分类取决于多棵树(弱分类器)的投票表决。
2.3 随机森林api介绍
- sklearn.ensemble.RandomForestClassifier(n_estimators=10, criterion=’gini’, max_depth=None, bootstrap=True, random_state=None, min_samples_split=2)
- n_estimators:integer,optional(default = 10)森林里的树木数量120,200,300,500,800,1200
- Criterion:string,可选(default =“gini”)分割特征的测量方法
- max_depth:integer或None,可选(默认=无)树的最大深度 5,8,15,25,30
- max_features="auto”,每个决策树的最大特征数量
- If “auto”, then max_features=sqrt(n_features).
- If “sqrt”, then max_features=sqrt(n_features)(same as “auto”).
- If “log2”, then max_features=log2(n_features).
- If None, then max_features=n_features.
- bootstrap:boolean,optional(default = True)是否在构建树时使用放回抽样
- min_samples_split:节点划分最少样本数
- min_samples_leaf:叶子节点的最小样本数
- 超参数:n_estimator, max_depth, min_samples_split,min_samples_leaf
2.4 随机森林预测案例
1. 实例化随机森林
# 随机森林去进行预测
rf = RandomForestClassifier()
2. 定义超参数的选择列表
param = {"n_estimators": [120,200,300,500,800,1200], "max_depth": [5, 8, 15, 25, 30]}
3. 使用GridSearchCV进行网格搜索
# 超参数调优
gc = GridSearchCV(rf, param_grid=param, cv=2)
gc.fit(x_train, y_train)
print("随机森林预测的准确率为:", gc.score(x_test, y_test))
注意
- 随机森林的建立过程
- 树的深度、树的个数等需要进行超参数调优
2.5 bagging集成优点
Bagging + 决策树/线性回归/逻辑回归/深度学习… = bagging集成学习方法
经过上面方式组成的集成学习方法:
-
均可在原有算法上提高约2%左右的泛化正确率
-
简单, 方便, 通用
2.6 小结
- bagging集成过程
- 1.采样 — 从所有样本里面,采样一部分
- 2.学习 — 训练弱学习器
- 3.集成 — 使用平权投票
- 随机森林介绍
- 随机森林定义
- 随机森林 = Bagging + 决策树
- 流程:
- 1.随机选取m条数据
- 2.随机选取k个特征
- 3.训练决策树
- 4.重复1-3
- 5.对上面的若决策树进行平权投票
- 注意:
- 1.随机选取样本,且是有放回的抽取
- 2.选取特征的时候吗,选择m<<M
- M是所有的特征数
- api
sklearn.ensemble.RandomForestClassifier()
- 随机森林定义
- Bagging + 决策树/线性回归/逻辑回归/深度学习… = bagging集成学习方法
- bagging的优点
- 1.均可在原有算法上提高约2%左右的泛化正确率
- 2.简单, 方便, 通用
3. 包外估计 (Out-of-Bag Estimate)
在随机森林构造过程中,如果进行有放回的抽样,我们会发现,总是有⼀部分样本我们选不到。
- 这部分数据,占整体数据的比重有多大呢?
- 这部分数据有什么用呢?
3.1 包外估计的定义
随机森林的 Bagging 过程,对于每⼀颗训练出的决策树 g ,与数据集 D 有如下关系:
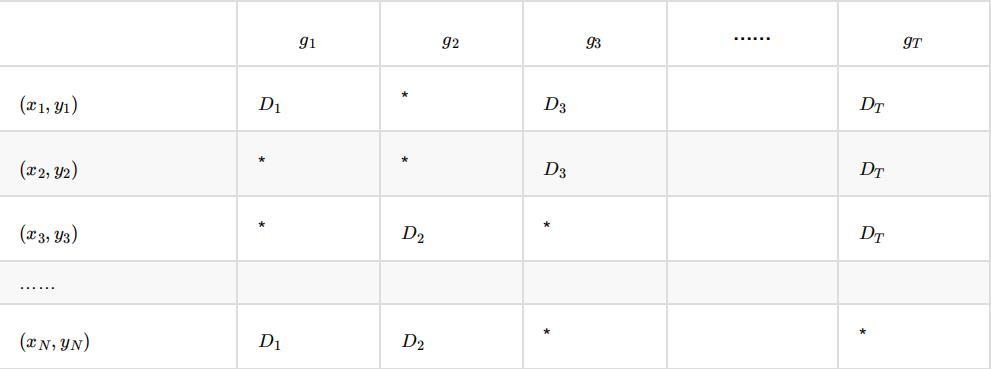
对于星号的部分,即是没有选择到的数据,称之为 Out-of-bag(OOB)数据,当数据⾜够多,对于任意⼀组数据 (x , y ) 是包外数据的概率为:
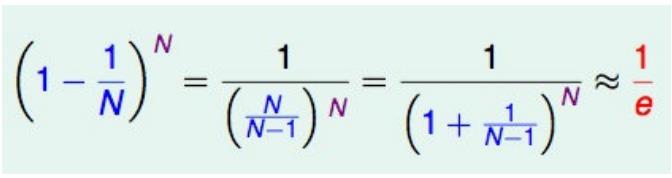
由于基分类器是构建在训练样本的⾃助抽样集上的,只有约 63.2% 原样本集出现在中,⽽剩余的 36.8% 的数据作为包 外数据,可以⽤于基分类器的验证集。
经验证,包外估计是对集成分类器泛化误差的无偏估计. 在随机森林算法中数据集属性的重要性、分类器集强度和分类器间相关性计算都依赖于袋外数据。
3.2 包外估计的用途
- 当基学习器是决策树时,可使⽤包外样本来辅助剪枝 ,或用于估计决策树中各结点的后验概率以辅助对零训练样本结点的处理;
- 当基学习器是神经网络时,可使用包外样本来辅助早期停止以减小过拟合 。
4. otto案例介绍
otto案例介绍 – Otto Group Product Classification Challenge
请参考:【机器学习】otto案例介绍
5. Boosting
学习目标
- 知道boosting集成原理和实现过程
- 知道bagging和boosting集成的区别
- 知道AdaBoost集成原理
5.1 什么是boosting

随着学习的积累从弱到强
简而言之:每新加入一个弱学习器,整体能力就会得到提升
代表算法:Adaboost,GBDT,XGBoost,LightGBM
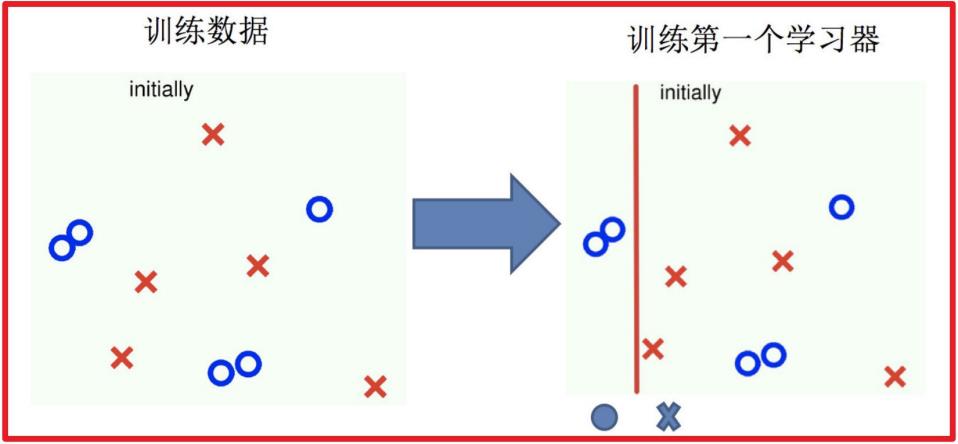
5.2 实现过程
1.训练第⼀个学习器
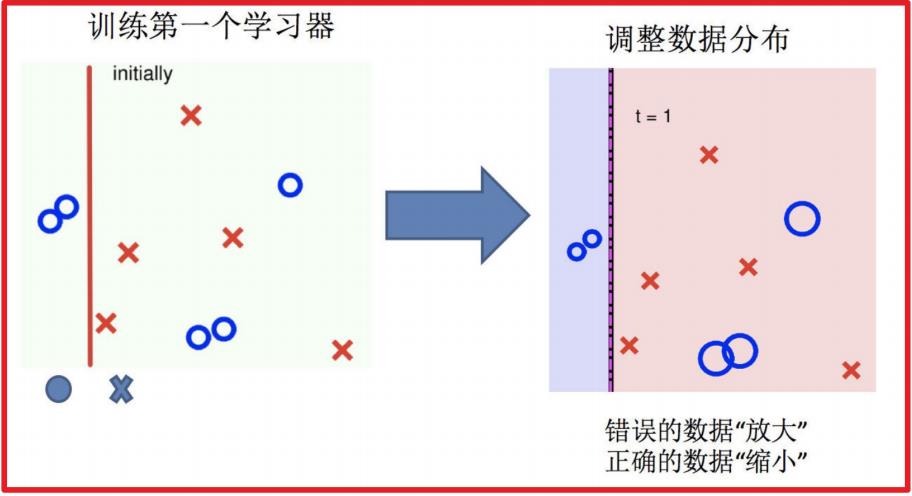
2.调整数据分布
3.训练第二个学习器
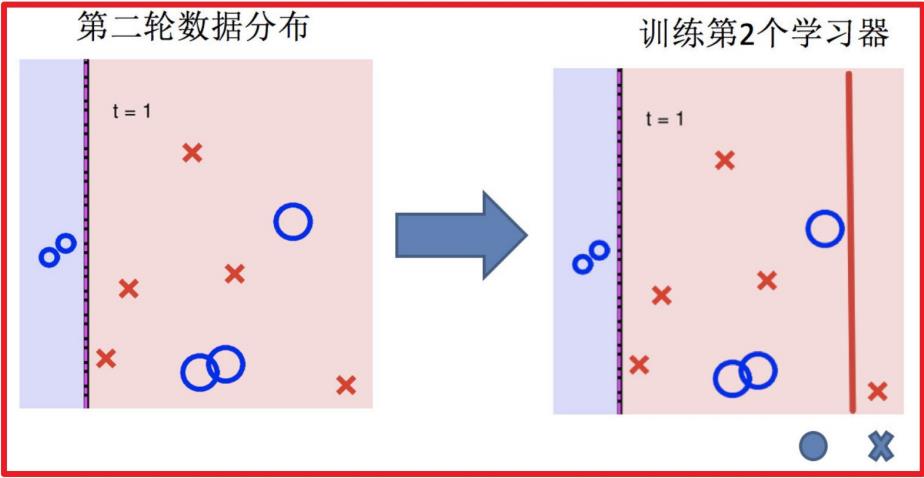
4.再次调整数据分布
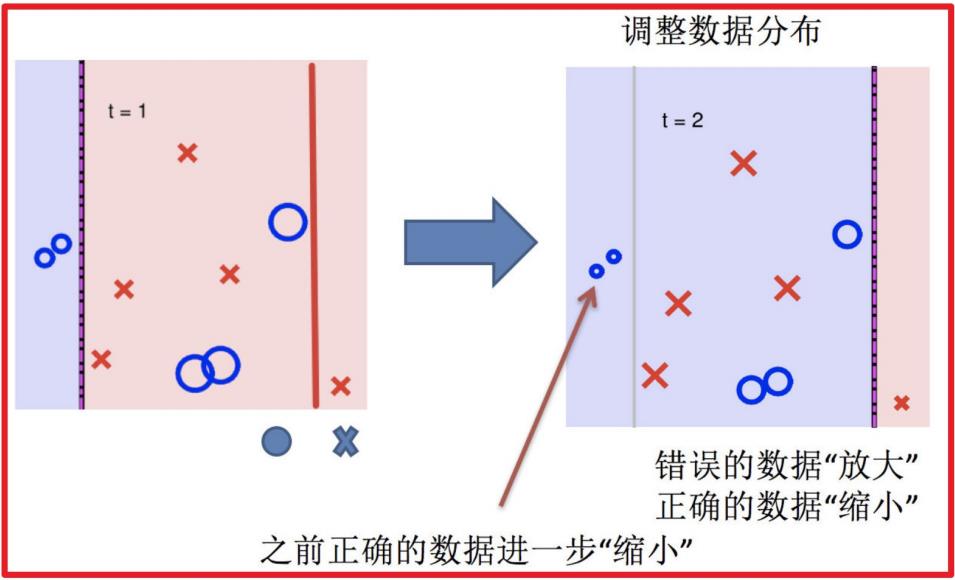
5.依次训练学习器,调整数据分布
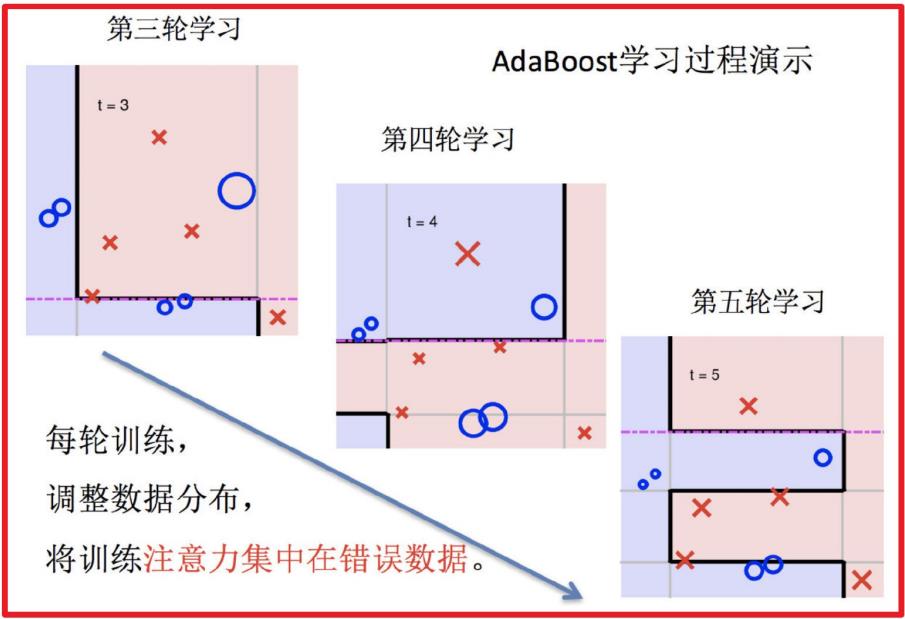
6.整体过程实现
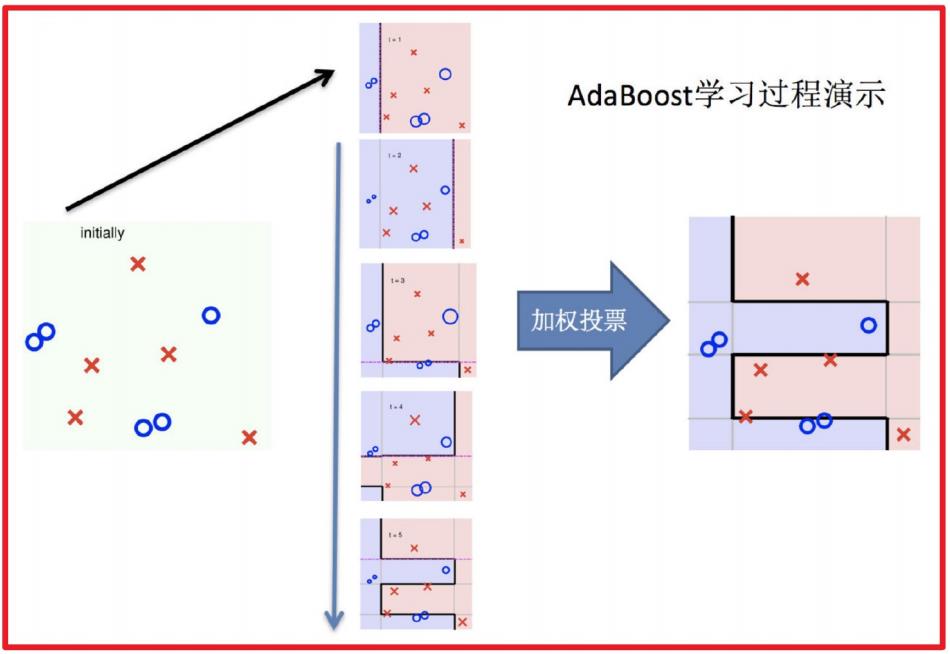
5.3 bagging集成与boosting集成的区别
- 区别⼀:数据方面
- Bagging:对数据进行采样训练;
- Boosting:根据前⼀轮学习结果调整数据的重要性。
- 区别二:投票方面
- Bagging:所有学习器平权投票;
- Boosting:对学习器进行加权投票。
- 区别三:学习顺序
- Bagging的学习是并行的,每个学习器没有依赖关系;
- Boosting学习是串行,学习有先后顺序。
- 区别四:主要作用
- Bagging主要用于提高泛化性能(解决过拟合,也可以说降低方差)
- Boosting主要用于提高训练精度 (解决欠拟合,也可以说降低偏差)
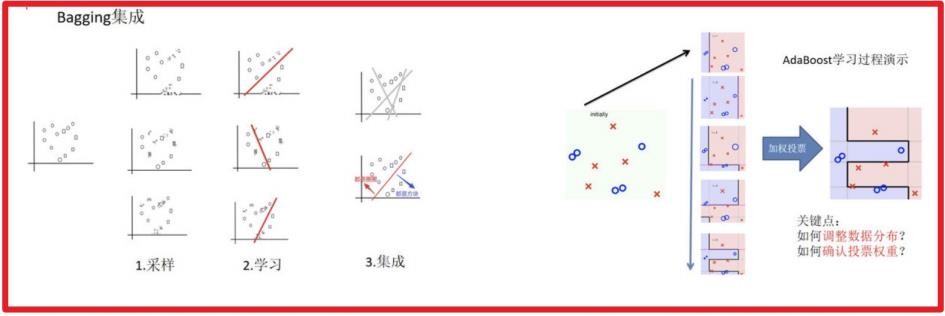
6. AdaBoost介绍
6.1 构造过程细节
- 步骤⼀:初始化训练数据权重相等,训练第⼀个学习器。
该假设每个训练样本在基分类器的学习中作⽤相同,这⼀假设可以保证第⼀步能够在原始数据上学习基 本分类器H (x)
- 步骤二:AdaBoost反复学习基本分类器,在每⼀轮m = 1, 2, …, M顺次的执行下列操作:

- 步骤三:对m个学习器进行加权投票
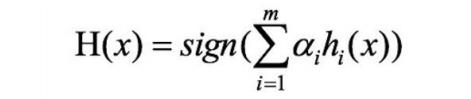
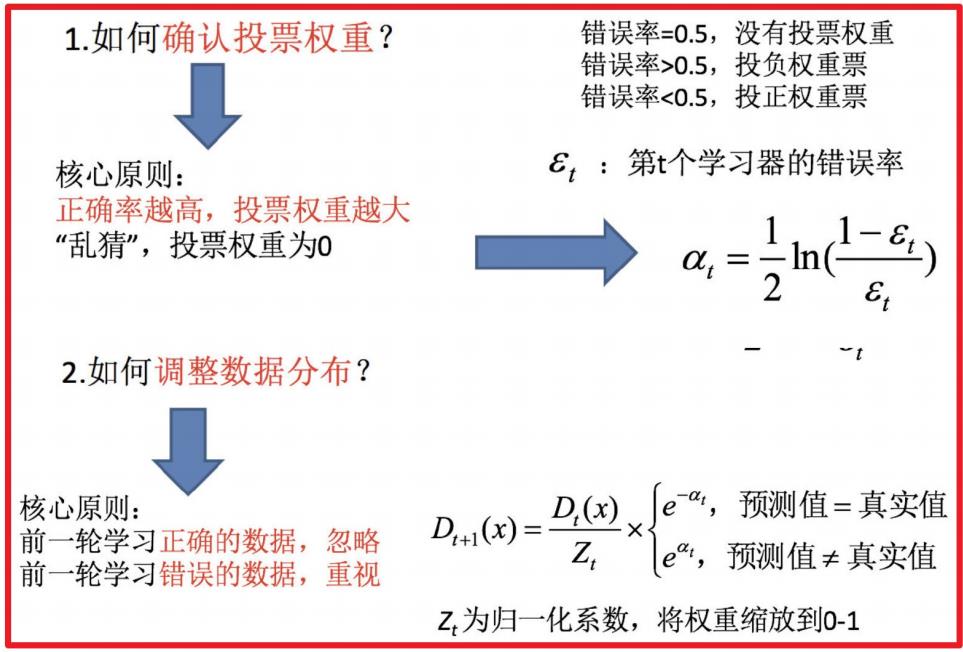
6.2 关键点剖析
如何确认投票权重?
如何调整数据分布?
6.3 案例
给定下面这张训练数据表所示的数据,假设弱分类器由xv产⽣,其阈值v使该分类器在训练数据集上的分类误差率最低,试用Adaboost算法学习⼀个强分类器。

问题解答:
- 步骤一:初始化训练数据权重相等,训练第⼀个学习器:
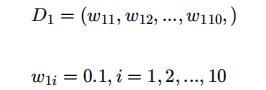
- 步骤二:AdaBoost反复学习基本分类器,在每⼀轮m = 1, 2, …, M顺次的执行下列操作:
当m=1的时候:
(a)在权值分布为D1的训练数据上,阈值v取2.5时分类误差率最低,故基本分类器为:
6,7,8被分错
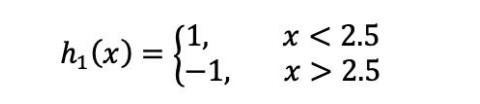


当m=3的时候:
(a)在权值分布为D 的训练数据上,阈值v取5.5时分类误差率最低,故基本分类器为:
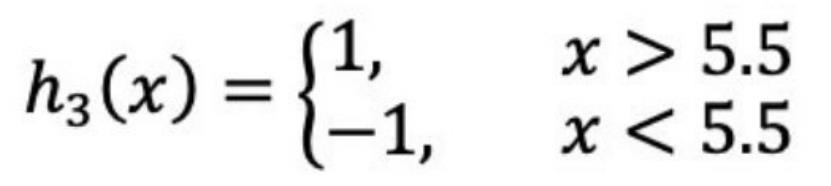

6.4 api介绍
from sklearn.ensemble import AdaBoostClassifier
api链接:https://scikitlearn.org/stable/modules/generated/sklearn.ensemble.AdaBoostClassifier.html#sklearn.ensemble.AdaBoost Classifier
6.5 小结
-
什么是Boosting
- 随着学习的积累从弱到强
- 代表算法:Adaboost,GBDT,XGBoost,LightGBM
-
bagging和boosting的区别
-
区别⼀:数据方面
- Bagging:对数据进⾏采样训练;
- Boosting:根据前⼀轮学习结果调整数据的重要性。
-
区别⼆:投票方面
- Bagging:所有学习器平权投票;
- Boosting:对学习器进⾏加权投票。
-
区别三:学习顺序
- Bagging的学习是并行的,每个学习器没有依赖关系;
- Boosting学习是串行的,学习有先后顺序。
-
区别四:主要作用
- Bagging主要用于提高泛化性能(解决过拟合,也可以说降低⽅差)
- Boosting主要⽤于提高训练精度 (解决欠拟合,也可以说降低偏差)
-
AdaBoost构造过程
- 步骤⼀:初始化训练数据权重相等,训练第⼀个学习器;
- 步骤⼆:AdaBoost反复学习基本分类器;
- 步骤三:对m个学习器进行加权投票
7. GBDT介绍
梯度提升决策树(GBDT Gradient Boosting Decision Tree) 是一种迭代的决策树算法,该算法由多棵决策树组成,所有树的结论累加起来做最终答案。它在被提出之初就被认为是泛化能力(generalization)较强的算法。近些年更因为被用于搜索排序的机器学习模型而引起大家关注。
GBDT = 梯度下降 + Boosting + 决策树
GBDT 的全称是 Gradient Boosting Decision Tree,梯度提升树,在传统机器学习算法中,GBDT算的上TOP3的算法。 想要理解GBDT的真正意义,那就必须理解GBDT中的Gradient Boosting 和Decision Tree分别是什么?
7.1 Decision Tree:CART回归树

7.1.1 回归树生成算法

7.1.2 Gradient Boosting: 拟合负梯度

提升树算法:




7.1.3 梯度的概念
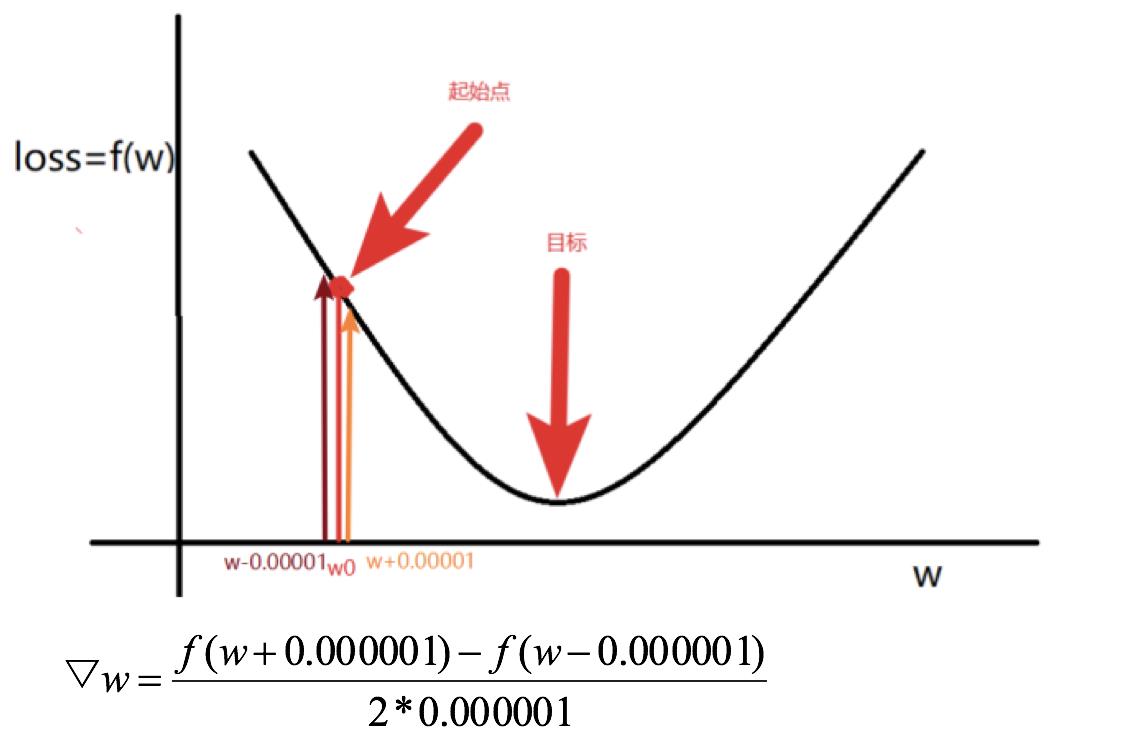
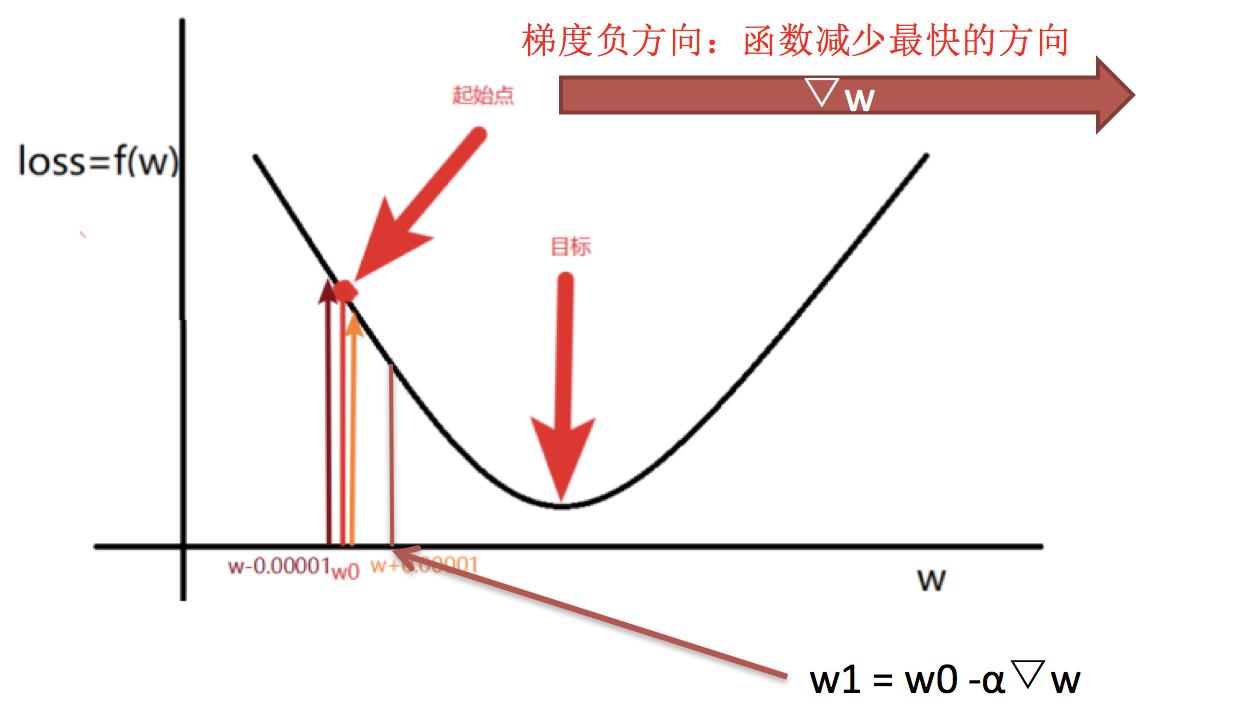
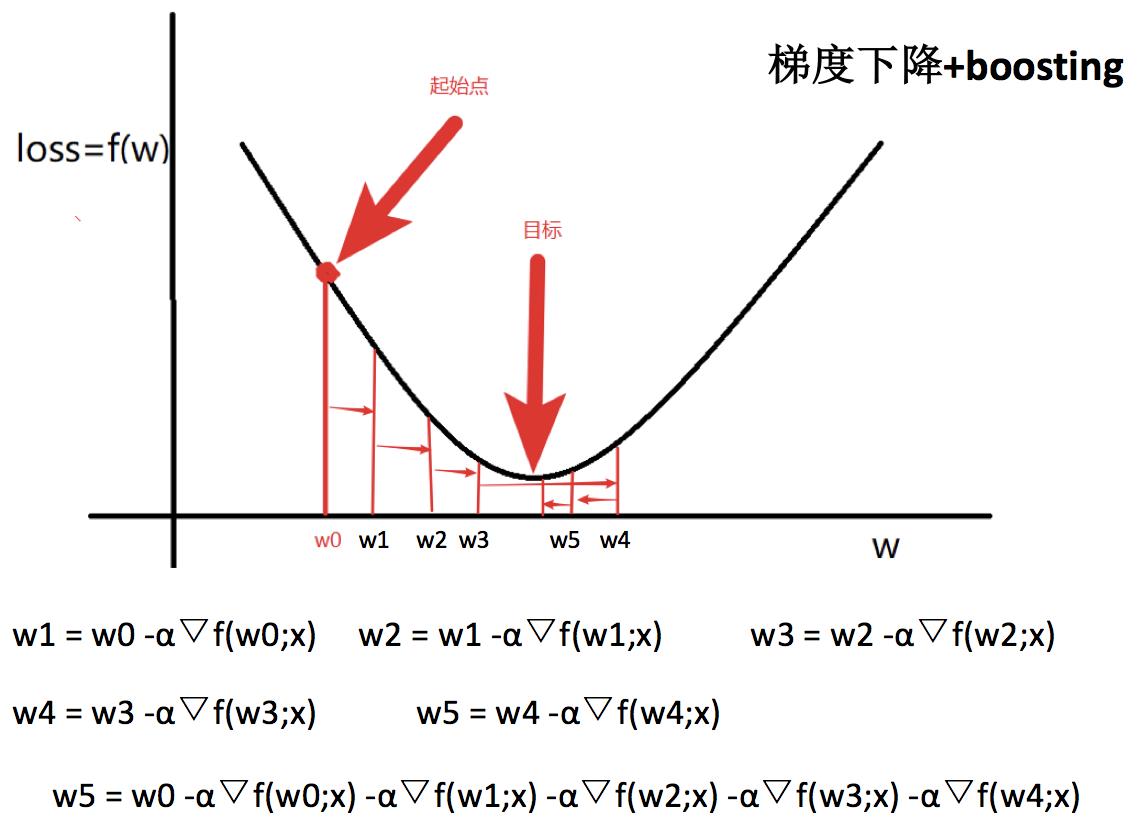
7.2 GBDT算法原理
上面两节分别将Decision Tree和Gradient Boosting介绍完了,下面将这两部分组合在⼀起就是我们的GBDT了。
GBDT算法:

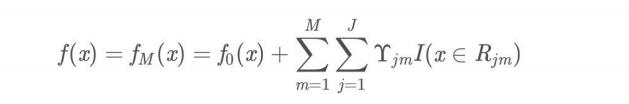
7.3 GBDT执行流程
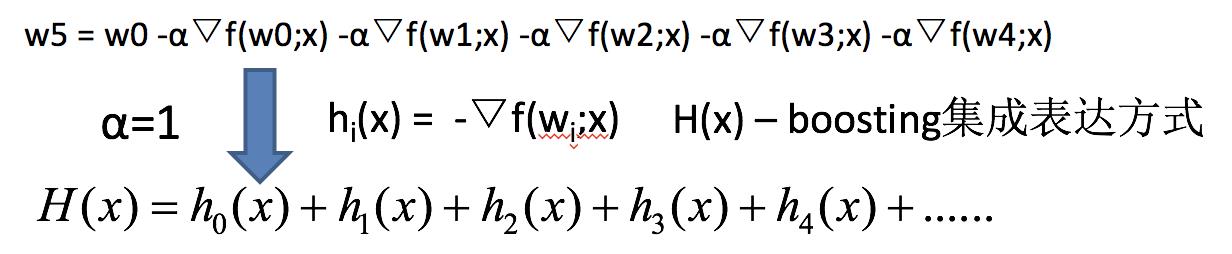
如果上式中的hi(x)=决策树模型,则上式就变为:
GBDT = 梯度下降 + Boosting + 决策树
7.4 案例
预测编号5的身高:
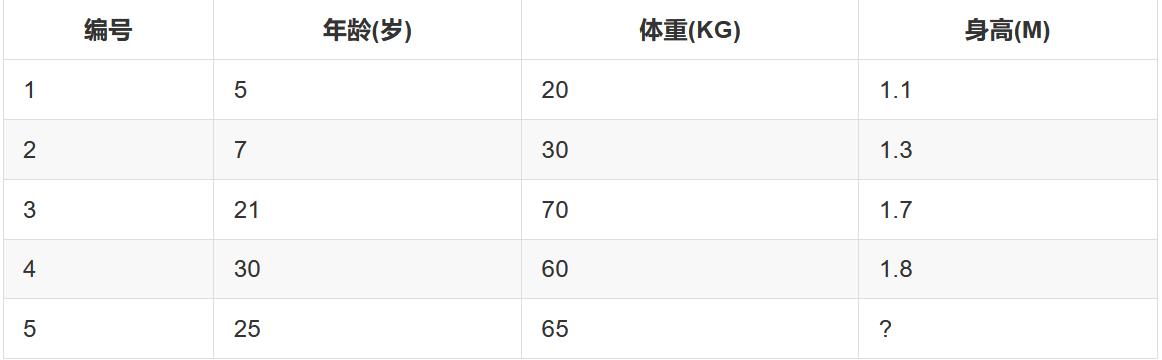
第一步:计算损失函数,并求出第一个预测值:

第二步:求解划分点
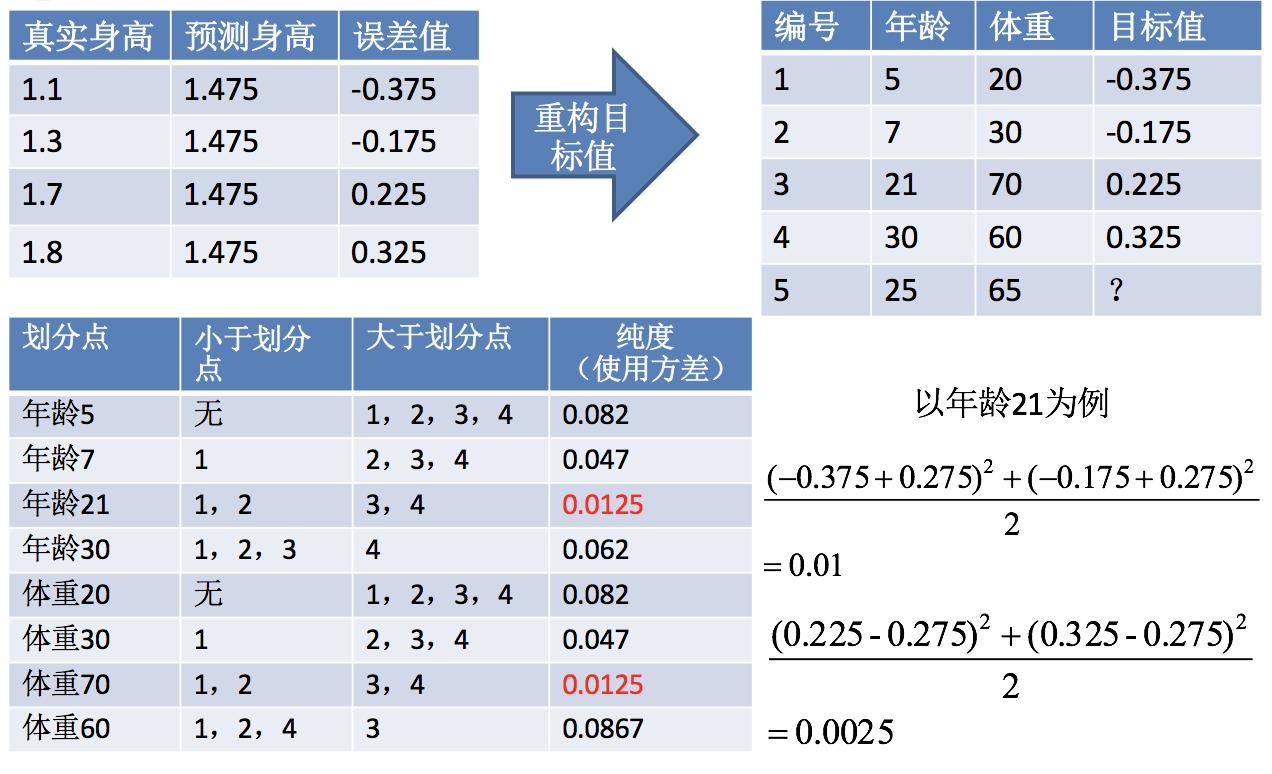
得出:年龄21为划分点的方差=0.01+0.0025=0.0125
第三步:通过调整后目标值,求解得出h1(x)
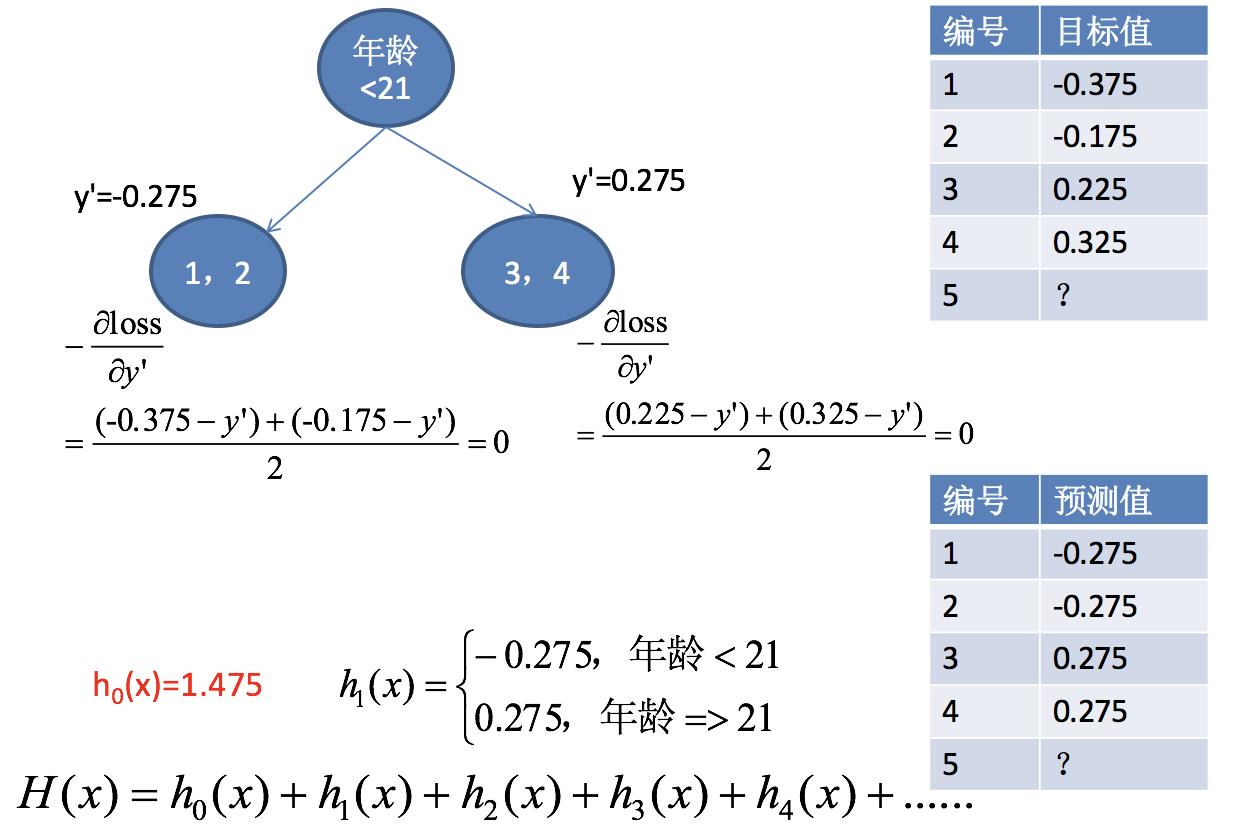
第四步:求解h2(x)
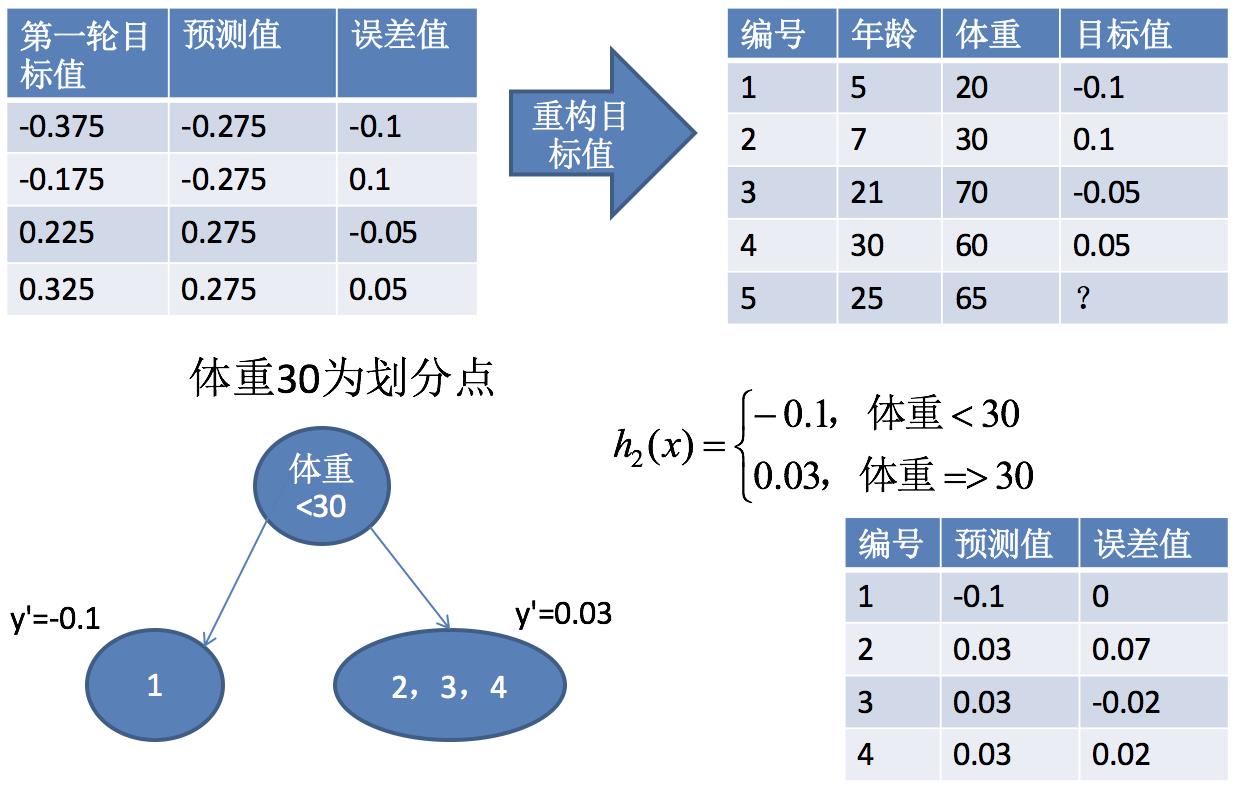
得出结果:

编号5身高 = 1.475 + 0.03 + 0.275 = 1.78
7.5 GBDT主要执行思想
1.使用梯度下降法优化代价函数;
2.使用一层决策树作为弱学习器,负梯度作为目标值;
3.利用boosting思想进行集成。
8. XGBoost

9. 什么是泰勒展开式
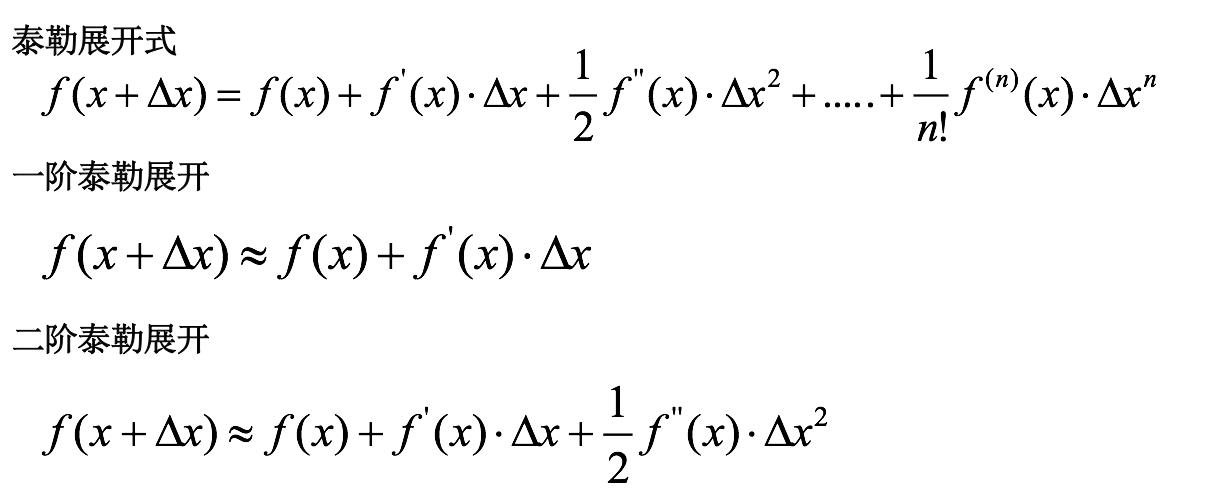
泰勒展开越多,计算结果越精确
小结
- boosting集成原理
- 随着学习的积累从弱到强
- 实现过程
- 1.初始化训练数据权重,初始权重是相等的
- 2.通过这个学习器,计算错误率
- 3.计算这个学习器的投票权重
- 4.对每个样本进行重新赋权
- 5.重复前面1-4
- 6.对构建后的最后的学习器进加权投票
- bagging集成与boosting集成的区别:
- 数据方面:
- bagging:重新采样
- boosting:对数据进行权重调整
- 投票方面:
- bagging:平权
- boosting:加权
- 学习顺序方面:
- bagging:并行
- boosting:串行
- 主要作用:
- bagging:过拟合
- boosting:欠拟合
- 数据方面:
- 梯度提升决策树(GBDT Gradient Boosting Decision Tree)
- GBDT = 梯度下降 + Boosting + 决策树
- XGBoost
- XGBoost= 二阶泰勒展开+boosting+决策树+正则化
以上是关于史诗级干货长文集成学习算法的主要内容,如果未能解决你的问题,请参考以下文章