源码之HashMap
Posted 保护眼睛
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了源码之HashMap相关的知识,希望对你有一定的参考价值。
源码之HashMap
概述
HashMap 基于hashing的原理,通过put(Key,value)和 get(key)方法存储和获取对象
当存储对象的时候,将健值队传递给put(key,value)方法时,它调用键对象key的hashCode()方法来计算hashcode,然后找到bucket位置、来存储对象value
当获取对象的时候、也是先计算key的hashCode、找到数组中对应位置的bucket位置、然后通过key的equals()方法找到正确的键值对key -value ,然后返回值对象value
HashMap 使用链表的方式来解决碰撞的问题、当碰撞发生的时候,对象将会存储在链表的下一个节点中。Hash每个链表的节点中,存储键值对key - value 对象。也就是当两个不同的见对象key的hashCode相同的时候、它们会存储在同一个bucket位置的链表(JDK链表的长度大于8变为红黑树)中,取数据的时候可以通过键对象的key的equals() 方法来找到正确的键值对key - value。
JDK8之前的HashMap的底层数据结构:
table 数组 + 链表
JDK1.8中采用的时数组+ 链表 + 红黑树的结构来优化的,链表的长度大于 8 的同时满足HashMap中的元素的个数大于64则变为红黑树,长度小于6变为链表
散列表Hash Table 也叫哈希表,时根据关键码值(key,value)而直接进行访问的数据结构。也就是说,它通过关键码值映射到表中的一个位置来访问记录,以加快查找的速度。这个映射函数就叫做散列函数,存放记录的数组就叫做散列表。
hash表中可以存放元素的位置称为桶”bucket“
哈希冲突和解决方案
hash 冲突
也就是不同的key值产生相同的Hash地址,H(key1) = H(key2)
hash冲突的解决方案;
1.开放地址法
探测序列,查找一个空的单元插入。线性探测,在平方 伪随机
2.连地址法
对于相同的值,使用链表进行连接。使用数组存储每一个链表。这也是hashMap中采用的方法。
3.公共溢出区法
建立一个特殊的存储的空间、专门存放冲突的数据、这种的方法使用于数据和冲突比较少的情况
4.再散列法
准备若干个hash函数、如果使用第一个的hash函数发生了冲突的话,就使用第二个hash函数以此类推
JDK1.8部分源码解读
JDK1.7中的HashMap源码的核心的成员变量
1.Entry[] table 。这个Entry类型的数组存储了hashMap 的真正的数据
2.size 大小 代表了HashMap内存储了多少个键值对
3.capacity容量。实际上HashMap没有一个成员叫capacity,它是作为table这个数组的大小而 隐式存在
4.threshold阈值和loadFactor装载因子。threshold是通过capacity * loadFactor得到的。当 size超过threshold时(刚好相等时不会扩容),HashMap扩容会再次计算每个元素的哈希位置。
5.entrySet、keySet和values这三个都是一种视图,真正的数据都来自table。
JDK1.8的核心的成员变量
1.Node[] table。这个Node类型的数组存储了HashMap的真正数据 static class Node<K,V> implements Map.Entry<K,V> 。
2.size大小。代表HashMap内存储了多少个键值对。
3.capacity容量。实际上HashMap没有一个成员叫capacity,它是作为table这个数组的大小而隐式存在。
4.threshold阈值和loadFactor装载因子。threshold是通过capacity * loadFactor得到的。当size超过 threshold时(刚好相等时不会扩容),HashMap会扩容 哈希计算比之前有改进。
5.entrySet、keySet和values这三个都是一种视图,真正的数据都来自table。
6.TREEIFY_THRESHOLD 转换成红黑树的临界值,默认 8
7.UNTREEIFY_THRESHOLD 红黑树转换成链表的临界值,默认 6
8.MIN_TREEIFY_CAPACITY 最小树形化阈值 默认64
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
static final int MAXIMUM_CAPACITY = 1 << 30;
static final float DEFAULT_LOAD_FACTOR = 0.75f;
static final int TREEIFY_THRESHOLD = 8;
static final int UNTREEIFY_THRESHOLD = 6;
static final int MIN_TREEIFY_CAPACITY = 64;
JDK中的HashMap为什么到8 转为红黑树 到6的时候转为链表
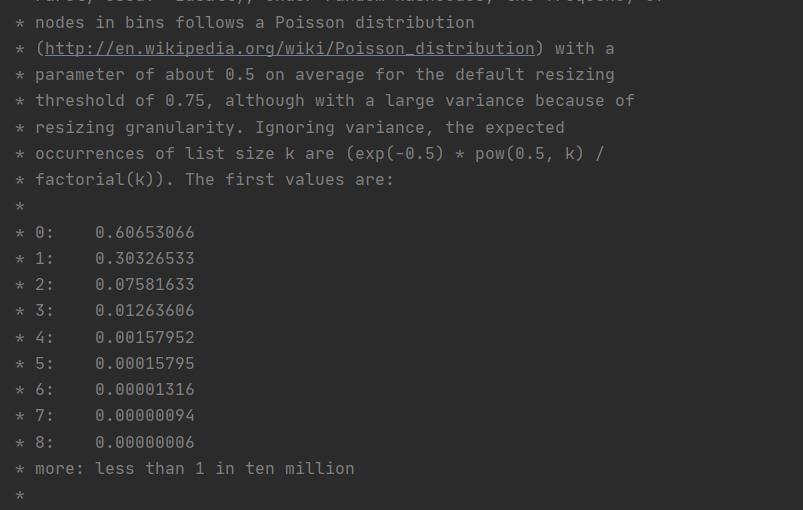
TreeNode(红黑树中)占用空间是普通Node(链表中)的两倍,为了时间和空间的权衡。
节点的分布频率会遵循泊松分布,链表长度达到8个元素的概率为0.00000006。
若是 7,则当极端情况下(频繁插入和删除的都是同一个哈希桶)对一个链表长度为 8 的的哈希桶进行 频繁的删除和插入,同样也会导致频繁的树化<=>非树化。
JDK1.8中的put()方法
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)//初始化判断
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)// 头节点是null,得到的i的值永远是小于 n - 1 的值,保证了下标的合法性
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;// 替换
else if (p instanceof TreeNode)// 是红黑树
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);// 一直遍历到链表尾部 添加
if (binCount >= TREEIFY_THRESHOLD - 1) // 变红黑树
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
// 大于阈值则扩容
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
1.首先判断table成员是否初始化,如果没有,则调用resize
2.通过传入键值对的key的hashCode和容量,马上得到了该映射所在的table数组下标。并通过 数组的取下标操作,得到该哈希桶的头节点。
3.如果没有发生哈希碰撞(头节点为null),那么直接执行新增操作。
4.如果发生了哈希碰撞(头节点不为null),那么分为两种情况: 1. 如果与桶内某个元素==返回true,或者equals判断相同,执行替换操作。 2. 如果与桶内所有元素判断都不相等,执行新增操作 ,可能是链表也可能是红黑树的插入。
5.链表新增操作后 会有两个判断: 1. 如果哈希桶是单链表结构,且桶内节点数量超过了TREEIFY_THRESHOLD(8),且size大于等于了 MIN_TREEIFY_CAPACITY(64),那么将该哈希桶转换为红黑树结构。 2. 如果新增后size大于了threshold,那么调用resize。
获取数据的get方法
public V get(Object key) {
Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
/**
* Implements Map.get and related methods.
*
* @param hash hash for key
* @param key the key
* @return the node, or null if none
*/
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
1.调用key的hashcode方法,根据返回值定位到map里数组对应的下标
2.判断这个数组下标对应的头节点是不是为null,如果是,返回null
3.如果头节点不是null ,判断这个引用对应对象的key值的equals方法,跟查询的key值对比, 判断是否为true,如果是则返回这个对象的value值,否则继续遍历下一个节点。
4.如果遍历完map中的所有节点都无法满足上面的判断 则返回null
以上是关于源码之HashMap的主要内容,如果未能解决你的问题,请参考以下文章