java面试笔试题逻辑题,完整PDF
Posted 程序员DCS阿里
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了java面试笔试题逻辑题,完整PDF相关的知识,希望对你有一定的参考价值。
Redis主从复制
概念
Redis的主从复制概念和mysql的主从复制大概类似。一台主机master,一台从机slaver。master主机数据更新后根据配置和策略,自动同步到slaver从机,Master以写为主,Slave以读为主。
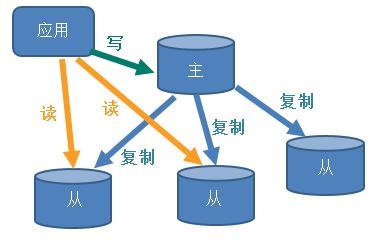
主要用途
-
读写分离:适用于读多写少的应用,增加多个从机,提高读的速度,提高程序并发 -
数据容灾恢复:从机复制主机的数据,相当于数据备份,如果主机数据丢失,那么可以通过从机存储的数据进行恢复。 -
高并发、高可用集群实现的基础:在高并发的场景下,就算主机挂了,从机可以进行主从切换,从机自动成为主机对外提供服务。
一主多从配置

环境准备
老哥太穷了,就用一台机器模拟三个机器。
-
第一步:将redis.conf复制3份,分别是redis6379.conf、redis6380.conf、redis6381.conf -
第二步:修改三个redis.conf文件里的port端口、pid文件名、日志文件名、rdb文件名 -
第三步:分别打开三个窗口模拟三台服务器,并开启redis服务。
查看当前3台机器主从角色
先用命令info replication看看3台机器目前的角色是什么。
# 三台机器都是这个状态
127.0.0.1:6379> info replication
# 角色是master主机
role:master
# 从机个数为0
connected_slaves:0
设置主从关系
这里注意,我们只设置从机就可以了,不用设置主机。我们选择6380和6381作为从机。6379作为主机。
# 6380 端口
127.0.0.1:6380> SLAVEOF 127.0.0.1 6379
# 6381 端口
127.0.0.1:6381> SLAVEOF 127.0.0.1 6379
# 6381 端口
127.0.0.1:6381> SLAVEOF 127.0.0.1 6379
再次查看3台机器目前角色
再次执行命令:info replication
# 主机
127.0.0.1:6379> info replication
role:master # 角色:主机
connected_slaves:2 #连接的从机个数,以及从机IP和端口
slave0:ip=127.0.0.1,port=6380,state=online,offset=98,lag=1
slave1:ip=127.0.0.1,port=6381,state=online,offset=98,lag=1
# 从机1
127.0.0.1:6380> info replication
role:slave # 角色:从机
master_host:127.0.0.1 # 主机的IP和端口
master_port:6379
# 从机2
127.0.0.1:6381> info replication
role:slave # 角色:从机
master_host:127.0.0.1 # 主机的IP和端口
master_port:6379
搭建成功,试验一把
-
全量复制:从机会把主机之前的数据全部都同步过来,大家可以在从机上get 某key试试。 -
增量复制:当主机新增数据时,从机会将该新增数据同步过来,大家可以在主机上执行命令set key value,然后在从机上get 该key,看是否能获取到。
读写分离
Redis的从机默认不允许进行写操作,大家可以在从机上执行命令set key value,会报错。
# 6380从机
127.0.0.1:6380> set k3 v3
(error) READONLY You can't write against a read only slave.
「呼,好累」,主从复制写的差不多了!!
主从复制原理
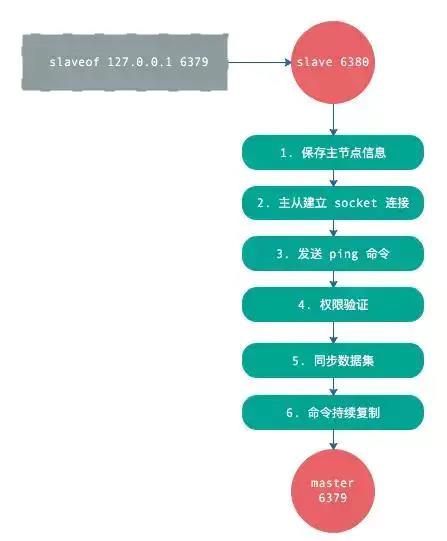
全量复制

**「①」**slave发送psync,由于是第一次复制,不知道master的runid,自然也不知道offset,所以发送psync ? -1
**「②」**master收到请求,发送master的runid和offset给从节点。
**「③」**从节点slave保存master的信息
**「④」**主节点bgsave保存rdb文件
**「⑤」**主机点发送rdb文件
并且在**「④」和「⑤」**的这个过程中产生的数据,会写到复制缓冲区repl_back_buffer之中去。
**「⑥」**主节点发送上面两个步骤产生的buffer到从节点slave
**「⑦」**从节点清空原来的数据,如果它之前有数据,那么久会清空数据
**「⑧」**从节点slave把rdb文件的数据装载进自身。
全量复制的开销
**「①」**bgsave时间
**「②」**rdb文件网络传输时间
**「③」**从节点清空数据的
**「④」**从节点加载rdb的时间
**「⑤」**可能的aof重写时间,这是针对从节点,例如开启了aof之后,从节点添加buffer数据时候,可能需要aof重写
基于上面的原因,有的情况下不适合使用全量复制,例如网络抖动之后,从节点只需要传送一部分数据,不需要传送全部数据,redis2.8之后实现了部分复制功能
部分复制

**「①」**假设发送网络抖动或者别的情况,暂时失去了连接
**「②」**这个时候,master还在继续往buffer里面写数据
**「③」**slave重新连接上了master
**「④」**slave向master发送自己的offset和runid
**「⑤」**master判断slave的offset是否在buffer的队列里面,如果是,那就返回continue给slave,否则需要进行全量复制(因为这说明已经错过了很多数据了)
**「⑥」**master发送从slave的offset开始到缓冲区队列结尾的数据给slave

总结
总的来说,面试是有套路的,一面基础,二面架构,三面个人。
最后,小编这里收集整理了一些资料,其中包括面试题(含答案)、书籍、视频等。希望也能帮助想进大厂的朋友,点击这里即可免费获取
获取](https://gitee.com/vip204888/java-p7)**
[外链图片转存中…(img-YYLz42nx-1626872766020)]
[外链图片转存中…(img-QqRwqlY9-1626872766020)]
[外链图片转存中…(img-pS9N72n1-1626872766021)]
以上是关于java面试笔试题逻辑题,完整PDF的主要内容,如果未能解决你的问题,请参考以下文章