Quasar:Resource-Efficient and Qos-Aware Cluster Management
Posted 银灯玉箫
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Quasar:Resource-Efficient and Qos-Aware Cluster Management相关的知识,希望对你有一定的参考价值。
我的论文笔记框架(Markdown格式)
Quasar:Resource-Efficient and Qos-Aware Cluster Management
{2014}, {Christina}, {ASPLOS}
Summary
写完笔记之后最后填,概述文章的内容,以后查阅笔记的时候先看这一段。注:写文章summary切记需要通过自己的思考,用自己的语言描述。忌讳直接Ctrl + c原文。
Research Objective(s)
Background / Problem Statement:
Method(s)
作者解决问题的方法/算法是什么?是否基于前人的方法?基于了哪些?
In Paragon, collaborative filtering was used to quickly classfiy worklaods with respect to interference and heterogeneity. A few applications are profiled exhaustively offline to derive their performance on different servers and with varying amounts of interference. An incoming application is profiled for one mintue on two of the many server configurations, with and without interferences in two shared resources. SVD and PQ-reconstruction are used to accurately estimate the performance of the workload on the remaining server configurations and with the interference on the remaining types of resources. Paragon showed that collaborative filtering can quickly and accurately classify unknown applications with respect to tens of server configurations and tens of sources of interfernces.
The classfication engine in Quasar extends the one in Paragon in two ways. First, it uses collaborative filtering to estimate the impact of resource scale-out(more servers) and scale-up (more resources per server) on application performance. These additional classfications are necessary for resource allocation. Second, it tailors classifications to differnt workload types. This is necessary because differnt types for workloads have different constraints and allocation knobs.
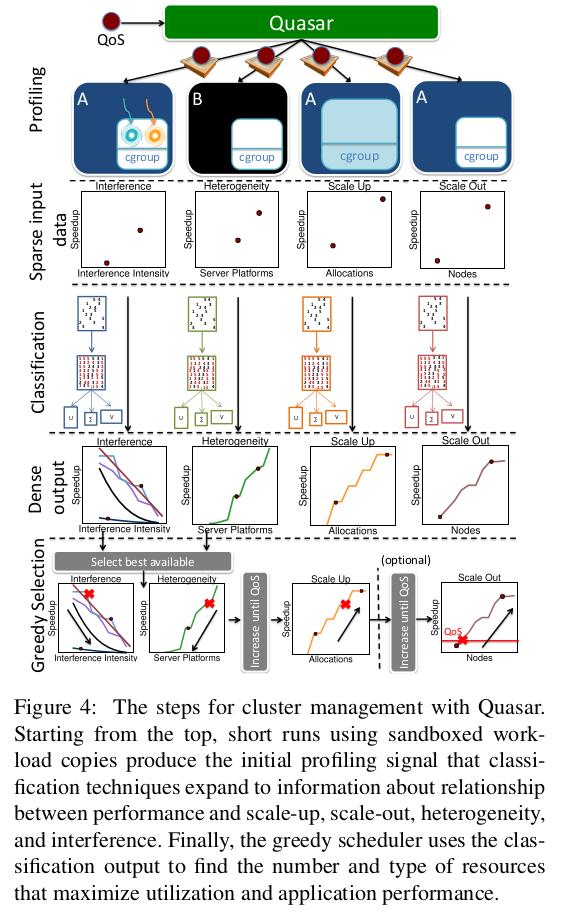
scale-up classfication
Profiling collects performance measurements in the format of each application’s performance goal(e.g. expected completion time or QPS) and inserts them into a matrix A with workloads as rows and scale-up configurations as columns. A configuration include compute, memory, and storage allocations or the values of the framework parameters for a workload like Hadoop. To constrain the number of columns, we quantize the vectors to integer multiples of cores and blocks of memory and storage. This may result into somewhat suboptimal decicsions, but the deviations are small in practice. Classfication using SVD and PQ-reconstruction then derive the workload’s performance across all scale-up allocations.
Heterogeneity classfication
This classfication requires one more profiling run on a different and randomly-chosen server type using the same workload parameters and for the same duration as a scale-up run. Collaborative filtering estimates workload performance across all other server types.
Interference classfication
This classification quantifies the sensitivity of the workload to interference caused and tolerated in various shared resources, including the CPU, cache hierarchy, memory capacity and bandwidth, and storage and network bandwidth. This classfication does not require an extra profiling run. Instead, it leverages the first copy of the scale-up classification to inject, one at a time, two microbenchmarks that create contention in a specific shared resource[19]. Once the microbenchmark is injected, Quasar tunes up its intensity until the workload performance drops below an acceptable level of QoS(typically 5%). This point is recorded as the workload’s sensitivity to this type of interference in a new row in the corresponding matrix A. The columns of the matrix are the different sources of interferences. Classification is then applied to derive the sensitivities to the remaining sources of interferences.
3.3 Greedy Allocation Assignment
The classification output is given to a greedy scheduler that jointly determines the amount, type, and exact set of allocated resources. The scheduler’s objective is to allocate the least amount of resources needed to satisfy a workloads’s performance target. This greatly reduces the space the scheduler traverse, allowing it to examine higher quality resources first, as smaller quantities of them will meet the performance constraint. This approach also scales well to many servers.
The scheduler uses the classfication output, to first rank the available severs by decreasing resource quality, i.e., high performing platforms with minimal interference first. Next, it sizes the allocation based on available resources until the performance constraint is met. Fir example, is a webserver must meet a throughput of 100K QPS with 10msec 9 9 t h 99_{th} 99th percentile latency and the highest-ranked servers can achieve at most 20K QPS, the workload would need five servers to meet the constraints. If the number of highest-ranked servers available is not sufficient, the scheduler will also allocate lower-randked servers and increase their number. The feedback between allocation and assignment ensures that the amount and quality of resources are accounted for jointly. When sizing the allocation, the algorithm first increases the per-node resource(scale-up) to better pack work in few servers, and then distributes the load across machines(scale-out). Nevertheless, alternative heuristics can be used based on workload’s locality properties or to address fault tolerance concerns.
The greedy algorithm has O ( M ∗ l o g M + S ) O(M*logM + S) O(M∗logM+S) complexity**, where the first** component accounts for the sorting overhead and the second for the examination of the top S S S servers, and in practice takes a few msec to determine an allocation/assignment even for systems with thousands of servers. Despite tis greedy nature, we show in Section 6 that the decision quality is quite high, leading to both high workload performance and high resource utilization.
4.1 Dynamic Adaptation
Some workloads change behavior during their runtime, either due to phase changes or due to variation in user traffic. Quasar detects such changes and adjusts resource allocation and/or assignement to perserve the performance contraints.
Phase detection
Quasar continuously monitors the performance of all active workloads in the cluster. If a workload runs below its performance constraint, it either went through a phase change or was incorrectly classified or assigned. In any case, Quasar reclassifies the application at current state and adjusts its resources ad needed.
Evaluation
作者如何评估自己的方法?实验的setup是什么样的?感兴趣实验数据和结果有哪些?有没有问题或者可以借鉴的地方?
Conclusion
作者给出了哪些结论?哪些是strong conclusions, 哪些又是weak的conclusions(即作者并没有通过实验提供evidence,只在discussion中提到;或实验的数据并没有给出充分的evidence)?
以上是关于Quasar:Resource-Efficient and Qos-Aware Cluster Management的主要内容,如果未能解决你的问题,请参考以下文章