《Python深度学习》第四章读书笔记
Posted Paul-Huang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《Python深度学习》第四章读书笔记相关的知识,希望对你有一定的参考价值。
第四章 机器学习基础
本章重点:处理机器学习问题的通用工作流程:
- 定义问题与要训练的数据。 收集这些数据,有需要的话用标签来标注数据。
- 选择衡量问题成功的指标。 你要在验证数据上监控哪些指标?
- 确定评估方法:留出验证? K 折验证?你应该将哪一部分数据用于验证?
- 开发第一个比基准更好的模型,即一个具有统计功效的模型。
- 开发过拟合的模型。
- 基于模型在验证数据上的性能来进行模型正则化与调节超参数。
4.1 机器学习的四个分支
4.1.1 监督学习
监督学习是目前最常见的机器学习类型。给定一组样本(通常由人工标注),它可以学会将输入数据映射到已知目标[也叫 标 注 ( a n n o t a t i o n ) \\color{red}标注(annotation) 标注(annotation)]。
监督学习主要包括分类和回归,更多的奇特变体,主要包括如下几种:
- 序列生成(sequence generation)。给定一张图像,预测描述图像的文字。序列生成有时可以被重新表示为一系列分类问题,比如反复预测序列中的单词或标记。
- 语法树预测(syntax tree prediction)。给定一个句子,预测其分解生成的语法树。
- 目标检测(object detection)。给定一张图像,在图中特定目标的周围画一个边界框。这个问题也可以表示为分类问题(给定多个候选边界框,对每个框内的目标进行分类)或分类与回归联合问题(用向量回归来预测边界框的坐标)。
- 图像分割(image segmentation)。给定一张图像,在特定物体上画一个像素级的掩模(mask)。
4.1.2 无监督学习
- 无监督学习是指在没有目标的情况下寻找输入数据的有趣变换,其目的在于数据可视化、数据压缩、数据去噪或更好地理解数据中的相关性。
- 为了更好地了解数据集,是解决监督学习问题之前的一个必要步骤。降维(dimensionality reduction)和聚类(clustering)都是众所周知的无监督学习方法。
4.1.3 自监督学习
- 自监督学习是 没 有 人 工 标 注 的 标 签 的 监 督 学 习 \\color{red}没有人工标注的标签的监督学习 没有人工标注的标签的监督学习。标签仍然存在(因为总要有什么东西来监督学习过程),但它们是从输入数据中生成的,通常是使用 启 发 式 算 法 生 成 \\color{red}启发式算法生成 启发式算法生成的。
- 常见的自监督学习
- 自编码器(autoencoder),其生成的目标就是未经修改的输入。
- 时序监督学习(temporally supervised learning),给定视频中过去的帧来预测下一帧,或者给定文本中前面的词来预测下一个词。
- 监督学习、自监督学习和无监督学习之间的区别有时很模糊,这三个类别更像是没有明确界限的连续体。
分类和回归术语表:
- 样 本 ( s a m p l e ) 或 输 入 ( i n p u t ) \\color{red}样本(sample)或输入(input) 样本(sample)或输入(input):进入模型的数据点。
- 预 测 ( p r e d i c t i o n ) 或 输 出 ( o u t p u t ) \\color{red}预测(prediction)或输出(output) 预测(prediction)或输出(output):从模型出来的结果。
- 目 标 ( t a r g e t ) \\color{red}目标(target) 目标(target):真实值。对于外部数据源,理想情况下,模型应该能够预测出目标。
- 预 测 误 差 ( p r e d i c t i o n e r r o r ) 或 损 失 值 ( l o s s v a l u e ) \\color{red}预测误差(prediction error)或损失值(loss value) 预测误差(predictionerror)或损失值(lossvalue):模型预测与目标之间的距离。
- 类 别 ( c l a s s ) \\color{red}类别(class) 类别(class):分类问题中供选择的一组标签。例如,对猫狗图像进行分类时,“狗”和“猫”就是两个类别。
- 标 签 ( l a b e l ) \\color{red}标签(label) 标签(label):分类问题中类别标注的具体例子。比如,如果 1234 号图像被标注为包含类别“狗”,那么“狗”就是 1234 号图像的标签。
- 真 值 ( g r o u n d − t r u t h ) 或 标 注 ( a n n o t a t i o n ) \\color{red}真值(ground-truth)或标注(annotation) 真值(ground−truth)或标注(annotation):数据集的所有目标,通常由人工收集。
- 二 分 类 ( b i n a r y c l a s s i f i c a t i o n ) \\color{red} 二分类(binary classification) 二分类(binaryclassification):一种分类任务,每个输入样本都应被划分到两个互斥的类别中。
- 多 分 类 ( m u l t i c l a s s c l a s s i f i c a t i o n ) \\color{red}多分类(multiclass classification) 多分类(multiclassclassification):一种分类任务,每个输入样本都应被划分到两个以上的类别中,比如手写数字分类。
- 多 标 签 分 类 ( m u l t i l a b e l c l a s s i f i c a t i o n ) \\color{red}多标签分类(multilabel classification) 多标签分类(multilabelclassification):一种分类任务,每个输入样本都可以分配多个标签。举个例子,如果一幅图像里可能既有猫又有狗,那么应该同时标注“猫”标签和“狗”标签。每幅图像的标签个数通常是可变的。
- 标 量 回 归 ( s c a l a r r e g r e s s i o n ) \\color{red}标量回归(scalar regression) 标量回归(scalarregression):目标是连续标量值的任务。预测房价就是一个很好的例子,不同的目标价格形成一个连续的空间。
- 向 量 回 归 ( v e c t o r r e g r e s s i o n ) \\color{red}向量回归(vector regression) 向量回归(vectorregression):目标是一组连续值(比如一个连续向量)的任务。如果对多个值(比如图像边界框的坐标)进行回归,那就是向量回归。
- 小 批 量 ( m i n i − b a t c h ) 或 批 量 ( b a t c h ) \\color{red}小批量(mini-batch)或批量(batch) 小批量(mini−batch)或批量(batch):模型同时处理的一小部分样本(样本数通常为 8~128)。样本数通常取 2 的幂,这样便于 GPU 上的内存分配。训练时,小批量用来为模型权重计算一次梯度下降更新。
4.2 评估机器学习模型
本小节主要是:1)数据划分为训练集、验证集和测试集。2)如何衡量泛化能力。
4.2.1 训练集、验证集和测试集
- 评估模型的重点是将数据划分为三个集合:
训
练
集
、
验
证
集
和
测
试
集
\\color{red}训练集、验证集和测试集
训练集、验证集和测试集。
- 在 训 练 数 据 上 训 练 模 型 \\color{red}训练数据上训练模型 训练数据上训练模型,这个过程本质上是学习:在某个参数空间中寻找良好的模型配置。
- 在 验 证 数 据 上 评 估 模 型 \\color{red}验证数据上评估模型 验证数据上评估模型,验证是否过拟合,要防止信息泄露(information leak)。
- 找到最佳参数,在 测 试 数 据 上 最 后 测 试 一 次 \\color{red}测试数据上最后测试一次 测试数据上最后测试一次。
- 三种经典的评估方法:
-
简单的留出验证
缺点:如果可用的数据很少,那么可能验证集和测试集包含的样本就太少,从而无法在统计学上代表数据。
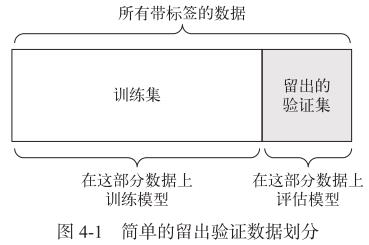
num_validation_samples = 10000 #通常需要打乱数据 np.random.shuffle(data) #定义验证集 validation_data = data[:num_validation_samples] data = data[num_validation_samples:] #定义训练集 training_data = data[:] model = get_model() #在训练数据上训练模型,并在验证数据上评估模型 model.train(training_data) validation_score = model.evaluate(validation_data) # 现在你可以调节模型、重新训练、评估,然后再次调节…… # 一旦调节好超参数,通常就在所有非测试数据上从头开始训练最终模型 model = get_model() model.train(np.concatenate([training_data, validation_data])) test_score = model.evaluate(test_data) -
K 折验证
- K 折验证(K-fold validation) 将数据划分为大小相同的 K K K个分区。对于每个分区 i i i ,在剩余的 K − 1 K-1 K−1个分区上训练模型,然后在分区 i i i上评估模型。最终分数等于 K K K个分数的平均值。
- 应用场景:对于不同的训练集 - 测试集划分,如果
模
型
性
能
的
变
化
很
大
\\color{red}模型性能的变化很大
模型性能的变化很大,那么这种方法很有用。
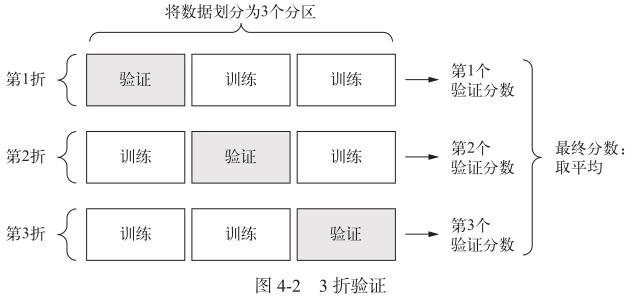
k = 4 num_validation_samples = len(data) // k np.random.shuffle(data) validation_scores = [] for fold in range(k): # 选择验证数据分区 validation_data = data[num_validation_samples * fold: num_validation_samples * (fold + 1)] #使用剩余数据作为训练数据。注意,+ 运算符是列表合并,不是求和 training_data = data[:num_validation_samples * fold] + data[num_validation_samples * (fold + 1):] # 创建一个全新的模型实例(未训练) model = get_model() model.train(training_data) validation_score = model.evaluate(validation_data) validation_scores.append(validation_score) # 最终验证分数:K 折验证分数的平均值 validation_score = np.average(validation_scores) # 在所有非测试数据上训练最终模型 model = get_model() model.train(data) test_score = model.evaluate(test_data) -
带有打乱数据的重复 K 折验证(iterated K-fold validation with shuffling)
- 如果可用的数据相对较少,而你又需要尽可能精确地评估模型,那么可以选择此方法。
- 具体做法是多次使用 K K K折验证,在每次将数据划分为 K K K个分区之前都先将数据打乱。最终分数是每次 K K K折验证分数的平均值。
- 这种方法一共要训练和评估
P
×
K
\\color{red}P×K
P×K个模型(
P
P
以上是关于《Python深度学习》第四章读书笔记的主要内容,如果未能解决你的问题,请参考以下文章
-