Binder概述,快速了解Binder体系
Posted 冬天的毛毛雨
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Binder概述,快速了解Binder体系相关的知识,希望对你有一定的参考价值。
前言
众所周知,Binder是android系统中最主要的进程间通信套件,更具体一点,很多文章称之为Binder驱动,那为什么说它是一个驱动呢,驱动又是何物,让我们自底向上,从内核中的Binder来一步步揭开它的面纱。本文重点在帮助读者对于Binder系统有一个简略的了解,所以写得比较笼统,后续文章会详细分析。
Binder到底是什么
Android系统内核是Linux,每个进程有自己的虚拟地址空间,在32位系统下最大是4GB,其中3GB为用户空间,1GB为内核空间;每个进程用户空间相对独立,而内核空间是一样的,可以共享,如下图
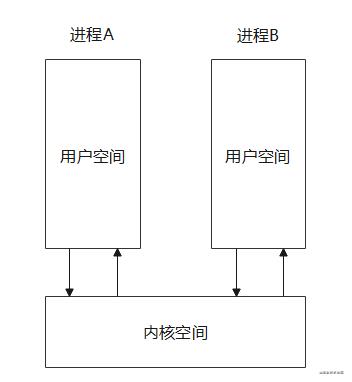
Linux驱动运行在内核空间,狭义上讲是系统用于控制硬件的中间程序,但是归根结底它只是一个程序一段代码,所以具体实现并不一定要和硬件有关。Binder就是将自己注册为一个misc类型的驱动,不涉及硬件操作,同时自身运行于内核中,所以可以当作不同进程间的桥梁实现IPC功能。
Linux最大的特点就是一切皆文件,驱动也不例外,所有驱动都会被挂载在文件系统dev目录下,Binder对应的目录是/dev/binder,注册驱动时将open release mmap等系统调用注册到Binder自己的函数,这样的话在用户空间就可以通过系统调用以访问文件的方式使用Binder。下面来粗略看一下相关代码。
device_initcall函数用于注册驱动,由系统调用
binder_init中调用misc_register注册一个名为binder的misc驱动,同时指定函数映射,将binder_open映射到系统调用open,这样就可以通过open("/dev/binder")来调用binder_open函数了
// 驱动函数映射
static const struct file_operations binder_fops = {
.owner = THIS_MODULE,
.poll = binder_poll,
.unlocked_ioctl = binder_ioctl,
.compat_ioctl = binder_ioctl,
.mmap = binder_mmap,
.open = binder_open,
.flush = binder_flush,
.release = binder_release,
};
// 注册驱动参数结构体
static struct miscdevice binder_miscdev = {
.minor = MISC_DYNAMIC_MINOR,
// 驱动名称
.name = "binder",
.fops = &binder_fops
};
static int binder_open(struct inode *nodp, struct file *filp){......}
static int binder_mmap(struct file *filp, struct vm_area_struct *vma){......}
static int __init binder_init(void)
{
int ret;
// 创建名为binder的单线程的工作队列
binder_deferred_workqueue = create_singlethread_workqueue("binder");
if (!binder_deferred_workqueue)
return -ENOMEM;
......
// 注册驱动,misc设备其实也就是特殊的字符设备
ret = misc_register(&binder_miscdev);
......
return ret;
}
// 驱动注册函数
device_initcall(binder_init);
Binder的简略通讯过程
一个进程如何通过binder和另一个进程通讯?最简单的流程如下
- 接收端进程开启一个专门的线程,通过系统调用在binder驱动(内核)中先注册此进程(创建保存一个bidner_proc),驱动为接收端进程创建一个任务队列(biner_proc.todo)
- 接收端线程开始无限循环,通过系统调用不停访问binder驱动,如果该进程对应的任务队列有任务则返回处理,否则阻塞该线程直到有新任务入队
- 发送端也通过系统调用访问,找到目标进程,将任务丢到目标进程的队列中,然后唤醒目标进程中休眠的线程处理该任务,即完成通讯
在Binder驱动中以binder_proc结构体代表一个进程,binder_thread代表一个线程,binder_proc.todo即为进程需要处理的来自其他进程的任务队列。
struct binder_proc {
// 存储所有binder_proc的链表
struct hlist_node proc_node;
// binder_thread红黑树
struct rb_root threads;
// binder_proc进程内的binder实体组成的红黑树
struct rb_root nodes;
......
}
Binder的一次拷贝
众所周知Binder的优势在于一次拷贝效率高,众多博客已经说烂了,那么什么是一次拷贝,如何实现,发生在哪里,这里尽量简单地解释一下。
上面已经说过,不同进程通过在内核中的Binder驱动来进行通讯,但是用户空间和内核空间是隔离开的,无法互相访问,他们之间传递数据需要借助copy_from_user和copy_to_user两个系统调用,把用户/内核空间内存中的数据拷贝到内核/用户空间的内存中,这样的话,如果两个进程需要进行一次单向通信则需要进行两次拷贝,如下图。
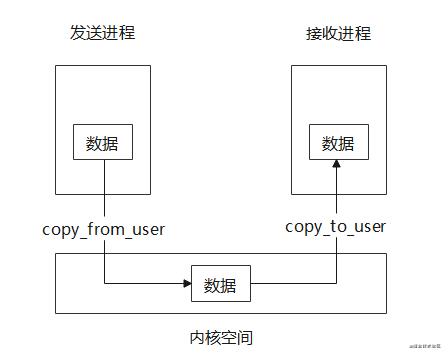
Binder单次通信只需要进行一次拷贝,因为它使用了内存映射,将一块物理内存(若干个物理页)分别映射到接收端用户空间和内核空间,达到用户空间和内核空间共享数据的目的。
发送端要向接收端发送数据时,内核直接通过copy_from_user将数据拷贝到内核空间映射区,此时由于共享物理内存,接收进程的内存映射区也就能拿到该数据了,如下图。
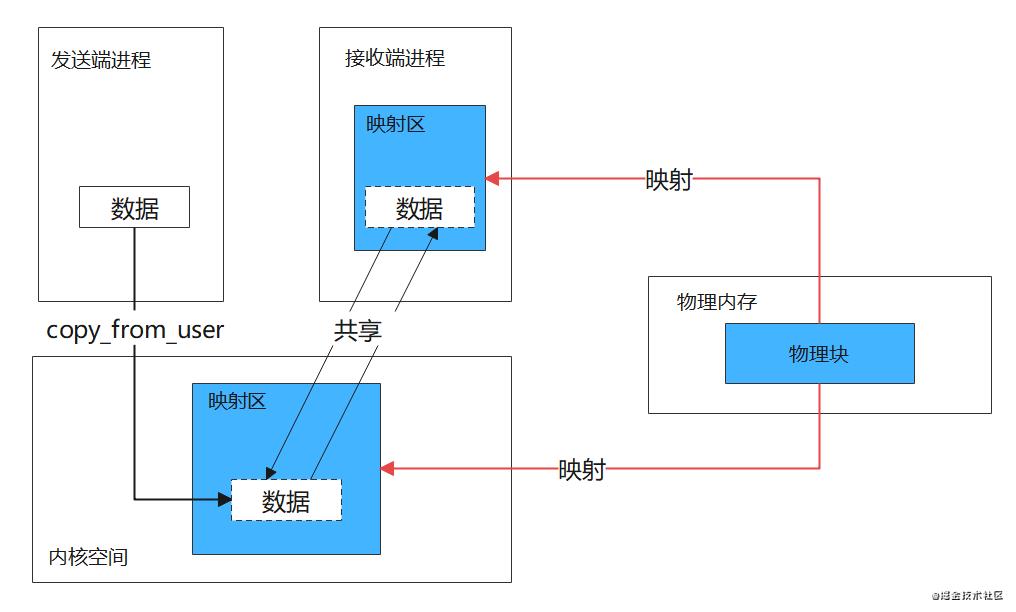
代码实现部分
用户空间通过mmap系统调用,调用到Binder驱动中binder_mmap函数进行内存映射,这部分代码比较难读,感兴趣的可以看一下。
binder_mmap创建binder_buffer,记录进程内存映射相关信息(用户空间映射地址,内核空间映射地址等)
static int binder_mmap(struct file *filp, struct vm_area_struct *vma)
{
int ret;
//内核虚拟空间
struct vm_struct *area;
struct binder_proc *proc = filp->private_data;
const char *failure_string;
// 每一次Binder传输数据时,都会先从Binder内存缓存区中分配一个binder_buffer来存储传输数据
struct binder_buffer *buffer;
if (proc->tsk != current)
return -EINVAL;
// 保证内存映射大小不超过4M
if ((vma->vm_end - vma->vm_start) > SZ_4M)
vma->vm_end = vma->vm_start + SZ_4M;
......
// 采用IOREMAP方式,分配一个连续的内核虚拟空间,与用户进程虚拟空间大小一致
// vma是从用户空间传过来的虚拟空间结构体
area = get_vm_area(vma->vm_end - vma->vm_start, VM_IOREMAP);
if (area == NULL) {
ret = -ENOMEM;
failure_string = "get_vm_area";
goto err_get_vm_area_failed;
}
// 指向内核虚拟空间的地址
proc->buffer = area->addr;
// 用户虚拟空间起始地址 - 内核虚拟空间起始地址
proc->user_buffer_offset = vma->vm_start - (uintptr_t)proc->buffer;
......
// 分配物理页的指针数组,数组大小为vma的等效page个数
proc->pages = kzalloc(sizeof(proc->pages[0]) * ((vma->vm_end - vma->vm_start) / PAGE_SIZE), GFP_KERNEL);
if (proc->pages == NULL) {
ret = -ENOMEM;
failure_string = "alloc page array";
goto err_alloc_pages_failed;
}
proc->buffer_size = vma->vm_end - vma->vm_start;
vma->vm_ops = &binder_vm_ops;
vma->vm_private_data = proc;
// 分配物理页面,同时映射到内核空间和进程空间,先分配1个物理页
if (binder_update_page_range(proc, 1, proc->buffer, proc->buffer + PAGE_SIZE, vma)) {
ret = -ENOMEM;
failure_string = "alloc small buf";
goto err_alloc_small_buf_failed;
}
buffer = proc->buffer;
// buffer插入链表
INIT_LIST_HEAD(&proc->buffers);
list_add(&buffer->entry, &proc->buffers);
buffer->free = 1;
binder_insert_free_buffer(proc, buffer);
// oneway异步可用大小为总空间的一半
proc->free_async_space = proc->buffer_size / 2;
barrier();
proc->files = get_files_struct(current);
proc->vma = vma;
proc->vma_vm_mm = vma->vm_mm;
/*pr_info("binder_mmap: %d %lx-%lx maps %p\\n",
proc->pid, vma->vm_start, vma->vm_end, proc->buffer);*/
return 0;
}
binder_update_page_range 函数为映射地址分配物理页,这里先分配一个物理页(4KB),然后将这个物理页同时映射到用户空间地址和内存空间地址
static int binder_update_page_range(struct binder_proc *proc, int allocate,
void *start, void *end,
struct vm_area_struct *vma)
{
// 内核映射区起始地址
void *page_addr;
// 用户映射区起始地址
unsigned long user_page_addr;
struct page **page;
// 内存结构体
struct mm_struct *mm;
if (end <= start)
return 0;
......
// 循环分配所有物理页,并分别建立用户空间和内核空间对该物理页的映射
for (page_addr = start; page_addr < end; page_addr += PAGE_SIZE) {
int ret;
page = &proc->pages[(page_addr - proc->buffer) / PAGE_SIZE];
BUG_ON(*page);
// 分配一页物理内存
*page = alloc_page(GFP_KERNEL | __GFP_HIGHMEM | __GFP_ZERO);
if (*page == NULL) {
pr_err("%d: binder_alloc_buf failed for page at %p\\n",
proc->pid, page_addr);
goto err_alloc_page_failed;
}
// 物理内存映射到内核虚拟空间
ret = map_kernel_range_noflush((unsigned long)page_addr,
PAGE_SIZE, PAGE_KERNEL, page);
flush_cache_vmap((unsigned long)page_addr,
// 用户空间地址 = 内核地址+偏移
user_page_addr =
(uintptr_t)page_addr + proc->user_buffer_offset;
// 物理空间映射到用户虚拟空间
ret = vm_insert_page(vma, user_page_addr, page[0]);
}
}
binder_mmap函数中调用binder_update_page_range只为映射区分配了一个物理页的空间,在Binder开始通讯时,会再通过binder_alloc_buf函数分配更多物理页,这是后话了。
Binder套件架构
内核层的Binder驱动已经提供了IPC功能,不过还需要在framework native层提供一些对于驱动层的调用封装,使framework开发者更易于使用,由此封装出了native Binder;同时,由于framework native层是c/c++语言实现,对于应用开发者,需要更加方便的Java层的封装,衍生出Java Binder;最后在此之上,为了减少重复代码的编写和规范接口,在Java Binder的基础上又封装出了AIDL。经过层层封装,在使用者使用AIDL时对于Binder基本上是无感知的。
这里贴一张架构图。
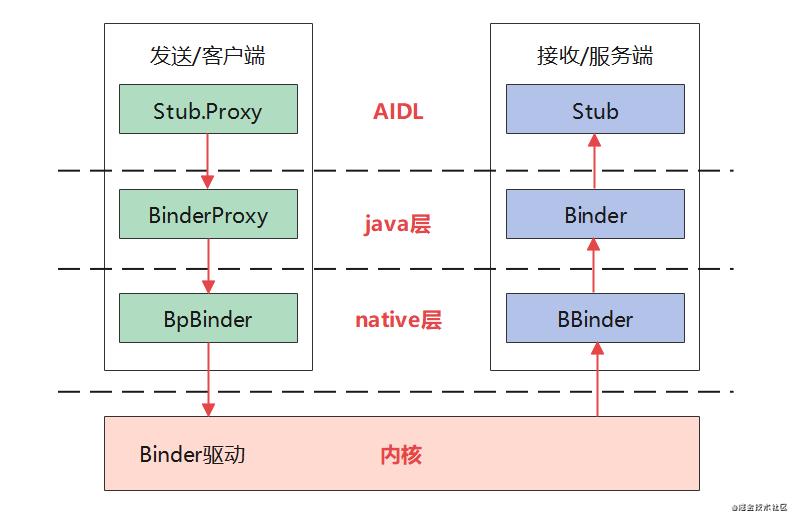
Native层:BpBinder代表服务端Binder的一个代理,内部有一个成员mHandle就是服务端Binder在驱动层的句柄,客户端通过调用BpBinder::transact传入该句柄,经过驱动层和服务端BBinder产生会话,最后服务端会调用到BBinder::onTransact。在这里两者之间通过约定好的code来标识会话内容。
Java层:Java层是对native层的封装,本质没有什么区别,。
AIDL:AIDL生成的代码对于Binder进行了进一步封装,<接口>.Stub对应服务端Binder,<接口>.Stub.Proxy标识客户端,内部持有一个mRemote实例(BinderProxy),aidl根据定义的接口方法生成若干个TRANSACTION_<函数名> code常量,两端Binder通过这些code标识解析参数,调用相应接口方法。换言之AIDL就是对BinderProxy.transact和Binder.onTransact进行了封装,使用者不必再自己定义每次通讯的code以及参数解析。
后记
本篇文章主要为不了解Binder体系的读者提供一个笼统的认识,接下来的文章会从AIDL远程服务开始层层向下分析整个IPC过程,所以如果想要更深一步了解Binder,本文作为前置知识也比较重要。
最后
小编学习提升时,顺带从网上收集整理了一些 Android 开发相关的学习文档、面试题、Android 核心笔记等等文档,希望能帮助到大家学习提升,如有需要参考的可以直接去我 CodeChina地址:https://codechina.csdn.net/u012165769/Android-T3 访问查阅。


以上是关于Binder概述,快速了解Binder体系的主要内容,如果未能解决你的问题,请参考以下文章