OracleSQL Server和MySQL的隐式转换异同
Posted bisal
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了OracleSQL Server和MySQL的隐式转换异同相关的知识,希望对你有一定的参考价值。
这次的组内分享,选择了在不同数据库中的隐式转换这个话题。隐式转换是个老生常谈的问题了,不同的数据库,隐式转换的影响因素有所不同,我们通过一些例子来看一下。但是问题来了,如何避免隐式转换带来的负面影响?一方面是编程习惯的问题,另一方面就需要一些人肉/自动化的手段主动发现问题,如果两者都没有,就只能被动等着出问题,再找解决方案了。
1. Oracle的隐式转换
隐式转换的历史文章,
如下是官方文档,对显式转换和隐式转换的介绍,顾名思义,显式转换就是人为指定数据类型的转换关系,隐式转换则是数据库自动进行的类型转换,推荐前者,因为隐式转换,可能带来一些风险和隐患,例如隐式转换列不能用索引、隐式转换还受到系统参数、不同数据库版本实现功能差异的影响,

P.S.
https://docs.oracle.com/en/database/oracle/oracle-database/21/sqlrf/Data-Type-Comparison-Rules.html#GUID-98BE3A78-6E33-4181-B5CB-D96FD9DC1694
这是显式转换的矩阵,
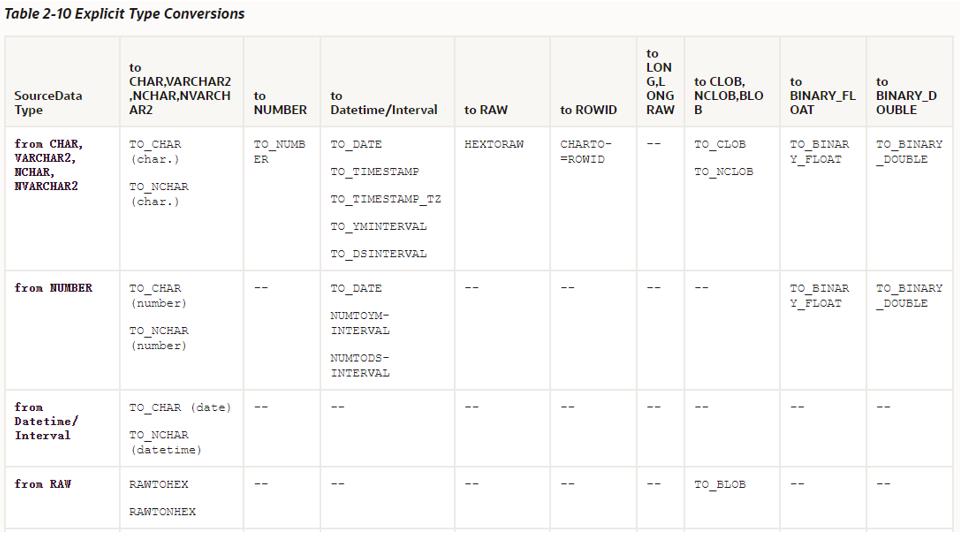
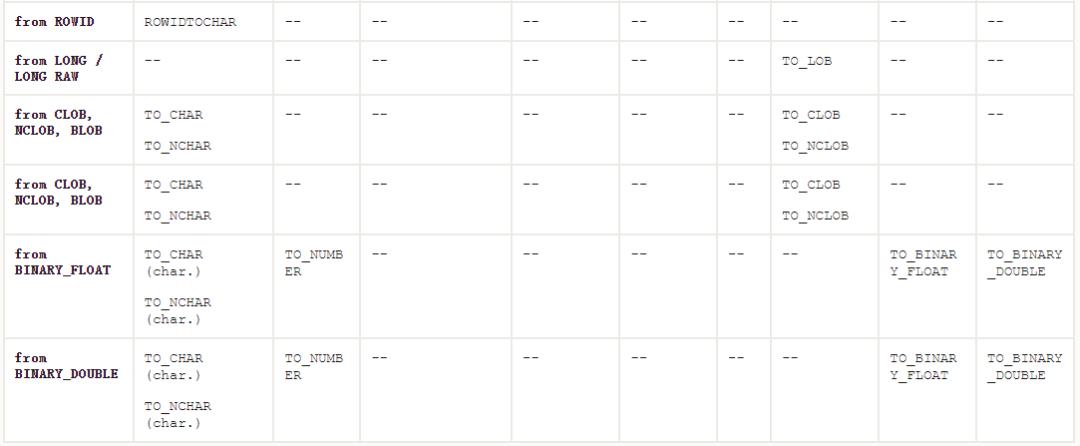
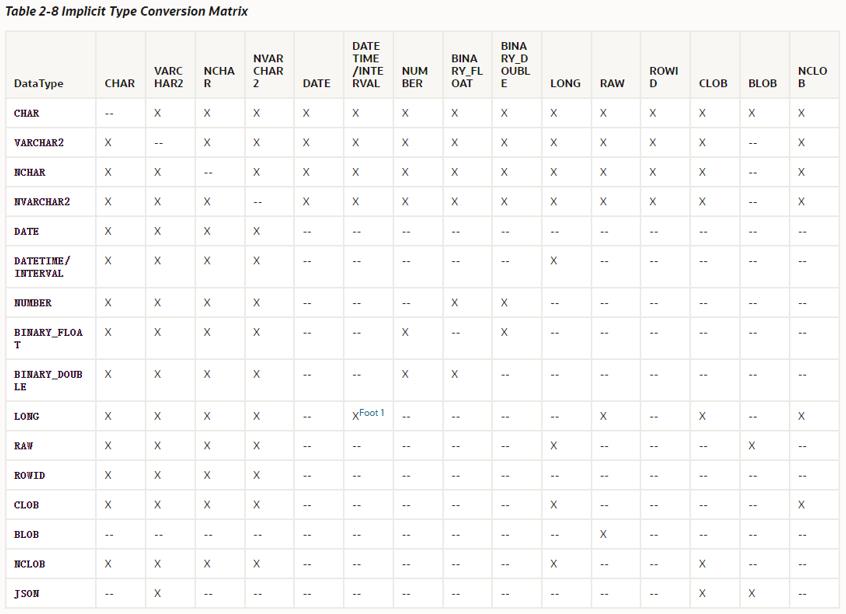
这是隐式转换的矩阵,
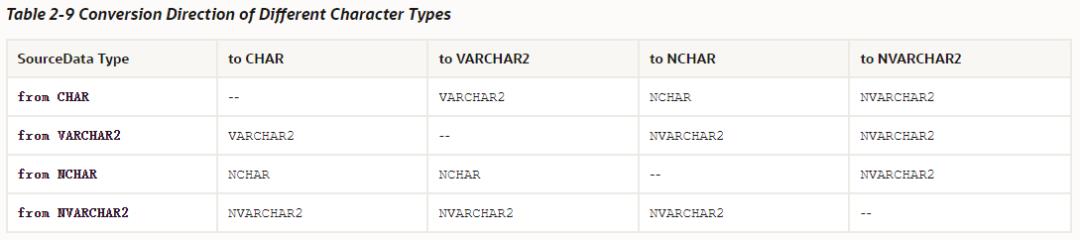
这是常用到的字符串类型之间的转换矩阵,
创建测试表,
SQL> desc t0
Name Null? Type
------------- -------- -----------------
ID VARCHAR2(1000)
SQL> select count(*) from t0;
COUNT(*)
----------
97112
SQL> create index idx_t0_01 on t0(id);
Index created.
测试场景1
构造where varchar2=number,
SQL> var x number;
SQL> exec :x := 1;
PL/SQL procedure successfully completed.
SQL> select * from t0 where id = :x
no rows selected
未使用索引,而是用了全表扫,

原因就是谓词条件显示对左值用了TO_NUMBER()函数,

测试场景2
构造where varchar2=varchar2,
SQL> var z varchar2(1000);
SQL> exec :z := 'a';
PL/SQL procedure successfully completed.
SQL> select * from t0 where id = :z;
no rows selected
此时选择了索引,


这是一些在Oracle中,常见的隐式转换,各位在开发过程中务必注意,
where varchar2=number -> where to_number(varchar2)=number
where varchar2=nvarchar2 -> where sys_op_c2c(varchar2)=nvarchar2
where date=timestamp -> where to_timestamp(date)=timestamp
2. SQL Server的隐式转换
这是官网给出的数据类型转换矩阵,

P.S.
https://docs.microsoft.com/zh-cn/sql/t-sql/data-types/data-type-conversion-database-engine?view=sql-server-ver15
《见识一下SQL Server隐式转换处理的不同》中介绍了一种SQL Server隐式转换的案例,和Oracle不同的是,SQL Server的隐式转换,还可能和排序规则相关。
测试场景1
创建一个SQL_Latin1_General_CP1_CI_AS排序规则的数据库,测试表如下,一个字段是varchar,一个字段是nvarchar,都创建了索引,
create table test(c1 nvarchar(200), c2 varchar(200));
insert into test(c1,c2) select cast(a.name as nvarchar(200)), a.name from master.dbo.spt_values a where a.number<10000;
create nonclustered index idx_test_01 on test(c1);
create nonclustered index idx_test_02 on test(c2);
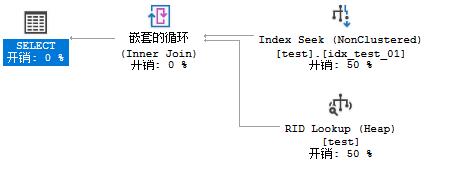
(1) 构造where nvarchar=varchar,
select * from test where c1='a';
此时选择了Index Seek,再回表的操作,
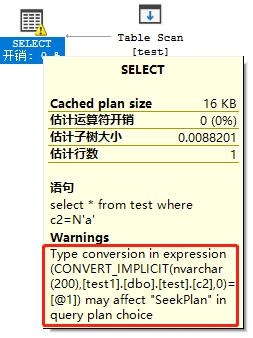
(2) 构造where varchar=nvarchar,
select * from test where c2=N'a';
我们看到执行计划中提醒表达式列出现了类型转换,这会影响执行计划选择“SeekPlan”,执行了CONVERT_IMPLICIT函数的列就是左值c2,强制转换为nvarchar,“SeekPlan”的执行计划,我理解就是Oracle中的Index Unique Scan或Index Range Scan,而且当前确实选择了全表扫描,Table Scan,这就是隐式转换,导致不能使用索引的场景,
测试场景2
创建一个Latin1_General_CP1_CI_AS排序规则的数据库,和场景1相同,测试表如下,一个字段是varchar,一个字段是nvarchar,都创建了索引,
create table test(c1 nvarchar(200), c2 varchar(200));
insert into test(c1,c2) select cast(a.name as nvarchar(200)), a.name from master.dbo.spt_values a where a.number<10000;
create nonclustered index idx_test_01 on test(c1);
create nonclustered index idx_test_02 on test(c2);
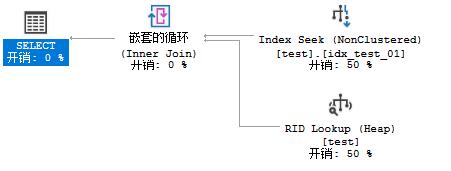
(1) 构造where nvarchar=varchar,
select * from test where c1='a';
效果和场景1是相同的,此时选择了Index Seek,再回表的操作,
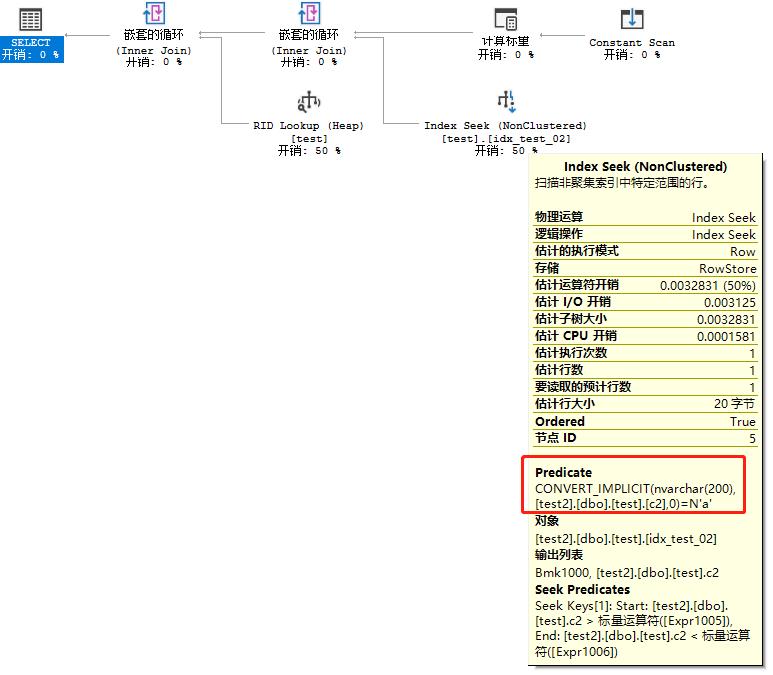
(2) 构造where varchar=nvarchar,
select * from test where c2=N'a';
这时就可以看出一些不同了,场景1中相同语句,因为隐式转换,导致用了Table Scan,而此处,虽然谓词提示CONVERT_IMPLICIT(c2),但未作为Warning,而且执行计划还是使用的Index Seek,路径上和场景1稍有不同,
Jonathan Kehayias在这篇文章中,提到了SQL_Latin1_General_CP1_CI_AS和Latin1_General_CP1_CI_AS这两种排序规则不同数据类型的转换关系。
P.S.
https://www.sqlskills.com/blogs/jonathan/implicit-conversions-that-cause-index-scans/
(1) SQL_Latin_General_CP1_CI_AS排序规则
varchar到nvarchar的隐式转换,是黄色的,意思是Causes Scan,即忽略索引,
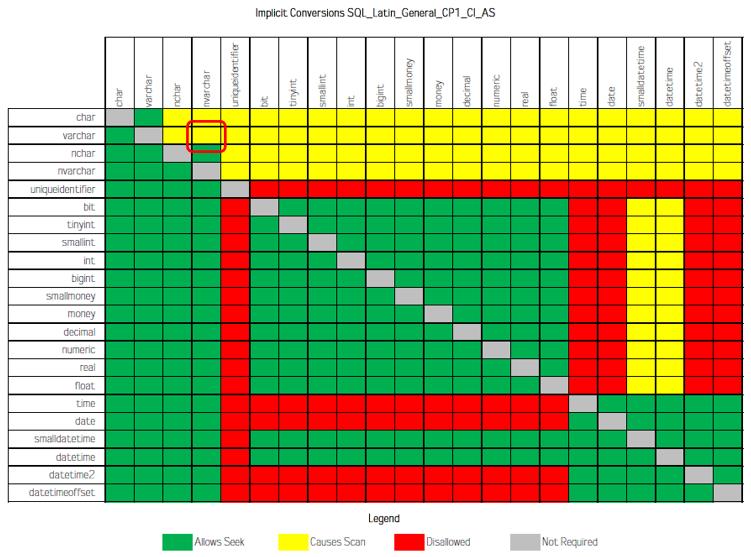
(2) Latin_General_CI_AS排序规则
varchar到nvarchar的隐式转换,是绿色的,允许用Seek,

由此看出,SQL Server中不同的排序规则对隐式转换的影响可能是不同的,但是SQL Server中有非常多的排序规则,这就比较尴尬了,难道你能列举出所有排序规则对应的隐式转换的影响?

3. MySQL的隐式转换
mysql的官方文档,同样强调了“For comparisons of a string column with a number, MySQL cannot use an index on the column to look up the value quickly.”,

P.S.
https://dev.mysql.com/doc/refman/5.7/en/type-conversion.html?spm=5176.100239.blogcont47339.5.1FTben
译文如下,
1. 两个参数至少有一个是 NULL 时,比较的结果也是 NULL,例外是使用 <=> 对两个 NULL 做比较时会返回 1,这两种情况都不需要做类型转换。
2. 两个参数都是字符串,会按照字符串来比较,不做类型转换。
3. 两个参数都是整数,按照整数来比较,不做类型转换。
4. 十六进制的值和非数字做比较时,会被当做二进制串。
5. 有一个参数是 TIMESTAMP 或 DATETIME,并且另外一个参数是常量,常量会被转换为 timestamp。
6. 有一个参数是 decimal 类型,如果另外一个参数是 decimal 或者整数,会将整数转换为 decimal 后进行比较,如果另外一个参数是浮点数,则会把 decimal 转换为浮点数进行比较。
7. 所有其他情况下,两个参数都会被转换为浮点数再进行比较。
数值型和字符串型之间的隐式转换,可以参考如下,
MySQL中隐式转换,还可能和字符集校对规则相关,
CREATE TABLE test1 (
ID varchar(64) COLLATE utf8_bin NOT NULL,
TASK_ID varchar(64) COLLATE utf8_bin DEFAULT NULL,
TEXT varchar(4000) COLLATE utf8_bin DEFAULT NULL,
PRIMARY KEY (ID)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin;
CREATE TABLE test2 (
ID int not null auto_increment,
TASK_ID varchar(64) DEFAULT NULL,
TEXT varchar(4000) DEFAULT NULL,
PRIMARY KEY (ID),
unique key unique_test2 (task_id) using btree
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
如下例子中,字符集校对规则有所区别,
explain select * from test1, test2 where test1.task_id=test2.task_id;
没使用上索引,

MySQL源代码中,能看到确实用到了字符集校对规则,

但是能在SQL层面指定字符集校对规则,
explain select * from test1, test2 where test1.task_id COLLATE utf8_general_ci=test2.task_id;
此时就可以用到索引了,

MySQL的隐式转换,还和字符集相关,
CREATE TABLE test3 (
ID int not null auto_increment,
TASK_ID varchar(64) DEFAULT NULL,
TEXT varchar(4000) DEFAULT NULL,
PRIMARY KEY (ID)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE test4 (
ID int not null auto_increment,
TASK_ID varchar(64) DEFAULT NULL,
TEXT varchar(4000) DEFAULT NULL,
PRIMARY KEY (ID),
unique key unique_test2 (task_id) using btree
) ENGINE=InnoDB DEFAULT CHARSET=gbk;
确实索引不可用,
explain select * from test3, test4 where test3.task_id=test4.task_id;
但是不太清楚,能否在SQL层面指定字符集解决这个问题?

上面说了这么多,其实我们也都知道隐式转换的风险,而且不同数据库,隐式转换的影响因素还不多,更增加了难度,与其冒着风险,找各种的补救,不如从源头控制,避免隐式转换,对一些常规类型(字符串、数值、日期等),结合业务需求,定义合适的字段类型,程序中的变量、SQL写法等,与定义类型保持一致,就可以解决大部分隐式转换的问题。退而求其次,如果不能做到规范的设计和开发,至少在开发测试的阶段,通过工具或人肉,检索下当前系统中用了全表扫描的语句,再根据字段是否存在索引、where条件两侧的数据类型等,判断是否因为书写不当造成了隐式转换。
近期更新的文章:
文章分类和索引:
以上是关于OracleSQL Server和MySQL的隐式转换异同的主要内容,如果未能解决你的问题,请参考以下文章