计算机视觉算法开发到应用实现
Posted 樵歌出林
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了计算机视觉算法开发到应用实现相关的知识,希望对你有一定的参考价值。
目录
1.简介概述
计算机视觉是使用计算机及相关设备对生物视觉的一种模拟,是人工智能领域的一个要部分,它主要任务是通过对采集的图片或视频进行处理以获得相应场景的信息。传统的计算机视觉系统的主要目标是从图像中提取特征,包括边缘检测、角点检测、基于颜色的分割等子任务。这种方法的主要问题是需要告诉系统在图像中寻找哪些特性。在实现中,算法性能差可以通过微调来解决,但是,这样的更改需要手工完成,并且针对特定的应用程序进行硬编码,这对高质量计算机视觉的实现造成了很大的障碍。当前,深度学习系统在处理一些相关子任务方面取得了重大进展。深度学习最大的不同之处在于,它不再通过精心编程的算法来搜索特定特征,而是训练深度学习系统内的神经网络。
2.目标检测
目标检测分为以下几个步骤:
1).训练分类器所需训练样本的创建:
训练样本包括正样本和负样本;其中正例样本是指待检目标样本(例如人脸或汽车等),负样本指其它不包含目标的任意图片(如背景等),所有的样本图片都被归一化为同样的尺寸大小(例如,20x20)。
2).特征提取
3).用训练样本来训练分类器:
确定模型,构建算法,用训练集优化参数。为了使分类检测准确率较好,训练样本一般都是成千上万的,然后每个样本又提取出了很多个特征,这样就产生了很多的的训练数据,所以训练的过程一般都很耗时的。
4).利用训练好的分类器进行目标检测:
一般的检测过程是这样的:用一个扫描子窗口在待检测的图像中不断的移位滑动,子窗口每到一个位置,就会计算出该区域的特征,然后用训练好的分类器对该特征进行筛选,判定该区域是否为目标。
5).学习和改进分类器
用交叉验证集来改进参数误差,用测试集来验证模型的正确性。
以下是神经网络目标检测的流程图:
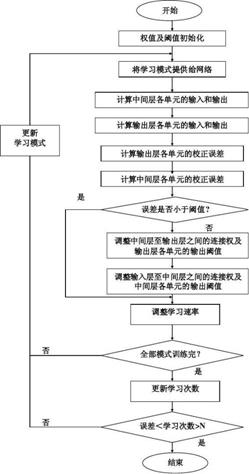
3.GPU应用
CUDA(Compute Unified Device Architecture)是由英伟达公司推出的 GPU 通用并行计 算平台。CUDA(Compute Unified Device Architecture)是由英伟达公司推出的 GPU 通用并行计 算平台。GPU 的强大计算能力得益于其多核的设计,目前一般民用 CPU 的核心数量在 4~8 核, 而同时期的桌面版GPU一般都拥有上千个计算核心,GPU可以作为CPU的协处理器与CPU 做并行计算。
此处就以五层神经网络为例:
在CUDA架构下,一个程序分为两个部分:host端和device端。host端是指在CPU上执行的部分,而device端则是在GPU上执行的部分。device端的程序又称为Kernel。通常host端程序会将数据准备好后,复制到显卡的内存中,再由GPU执行device端程序,完成后再由host端程序将结果从显卡的内存中取回。
GPU上神经网络前向传播算法基本过程是逐层计算各层的所有神经元的值。
输入层神经元值已知,其余每层有一个Kernel函数来计算该层的所有神经元的值,上述的神经网络需要4个Kernel函数。并行计算只能体现在一层中,不同层之间没有并行性。
首先将输入层的神经元值和每层的权值保存在5个数组中,并从host内存传递到device内存。由于每层的权值是不变的,所以可以将这些权值传递到device的常量内存中,由于常量内存有cache,这比放到全局内存的存取速度要快很多。在device中为第二到第五层的神经元值分配内存空间,第一个Kernel函数根据输入层的神经元值和权值计算第二层神经元值,第二个Kernel函数根据第二层的神经元值和权值计算第三层神经元值,如此往下,第四个Kernel函数计算出第五层即输出层的值,然后将该值从device内存传递到host内存。神经网络的连接体现在每个Kernel函数处理计算过程里。
卷积神经网络最主要也最耗时的操作在于感受野的卷积操作,为了能够提升效率,使用 CUDA 平台提供的深度学习库 CUDNN。CUDNN 库针对深度学习中常用的一些操作提供了一些 API 接口。这些接口结合 GPU 的硬件特性,在效率上都进行过深度的优化,是卷积神经网络在 GPU 上加速的核心。
此处以卷积神经网络在GPU实现为例:
- 卷积网络层结构设计:
卷积神经网络最主要的部分在于每层网络的设计,层采用继承派生的设计,卷积网络的所有层都继承自虚基类Layer,所有层都需要实现 6个虚函数,函数的名称参数和功能如下 所示:
setTopLayer(Layer*):关联当前层的差量输入与上一层的差量输出,仅在训练时需要
setBottomLayer(Layer*):关联当前层的输入和上一层的输出
createLayer():创建该层,主要完成内存分配和变量初始化的工作
cnnForward():该层网络的前馈运算
cnnBackward():该层网络的反馈运算
updateCoeff():根据反馈运算的差值更新权值、偏置参数 输入层、卷积层从 Layer虚基类派生。
输出层从卷积层派生,并且重写前馈和反馈操作 函数。采用这种设计结构,能够使得整个卷积神经网络变得易于管理,只需要将基类的指针保存在动态数组中,初始化时根据网络的层数,将第一层与最后一层分别使用输入层 与输出层来初始化,其余层使用卷积层来初始化即可。层的继承派生关系如图 1 所示。

2.使用API接口
前馈操作调用了一组函数 CUDNN 的接口函数,包括:cudnnConvolutionForward 、 cudnnAddTensor 和 cudnnActivationForward 。 其 中,cudnnConvolutionForward 主要完成感受野的卷积计算,该函数会根据输入图像描述符、滤波器描述符和卷积运算描述符来完成卷积运算。cudnnAddTensor 主要完成矩阵的相加,使用该函数为给每个感受野添加偏置。cudnnActivationForward 则是实现了激活函数,API 中提供了 Sigmoid、ReLu 和 Tanh 三种激活函数,在层初始化的时候可以根据需要进行设置。
反馈操作部分则相反,可以使用了 cudnnActivationBackward 、cudnnConvolutionBackwardData 、 cudnnConvolutionBackwardFilter 和 cudnnConvolutionBackwardBias 四个函数来完成反馈操作,前两个函数组合可以求得每一层 反向传播的数据误差,剩下两个函数将结合反向传播的数据误差和该层的输入数据分别求滤 波器系数误差和偏置误差。最后再通过 cudnnAddTensor 函数,将相应的误差系数和原始系 数求和即可完成权值更新。
以上是关于计算机视觉算法开发到应用实现的主要内容,如果未能解决你的问题,请参考以下文章