终于有大佬把软件测试的元素定位总结得这么通俗易懂了!
Posted 软件测试阿沐
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了终于有大佬把软件测试的元素定位总结得这么通俗易懂了!相关的知识,希望对你有一定的参考价值。
为什么要学习元素定位方式
1. 让程序操作指定元素,就必须先找到此元素;
2. 程序不像人类用眼睛直接定位到元素;
3. webDriver提供了八种定位元素的方式。
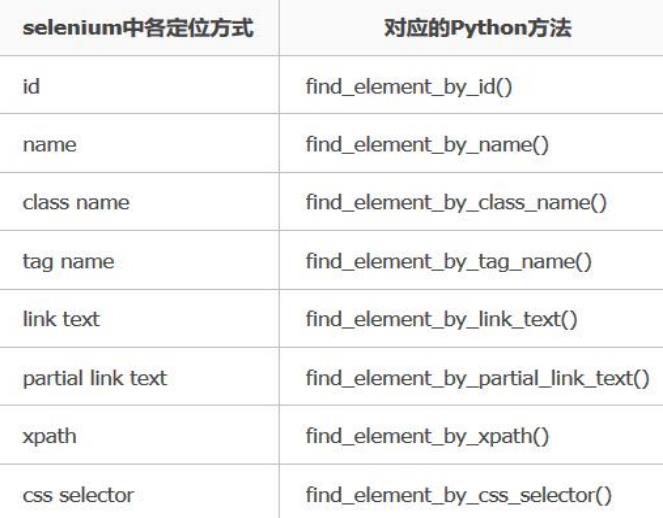
定位方式总结
1. id、
name
、
class_name
、
tag_name
:根据元素的标签或元素的属性来进行定位
2. link_text、
partial_link_text
:根据超链接的文本来进行定位(
a
标签)
3. xpath:为元素路径定位
4. css:为
css
选择器定位(样式定位)
1:id定位
前提:元素有
id
属性
id
定位方法:
find_element_by_id()
实现案例
-1
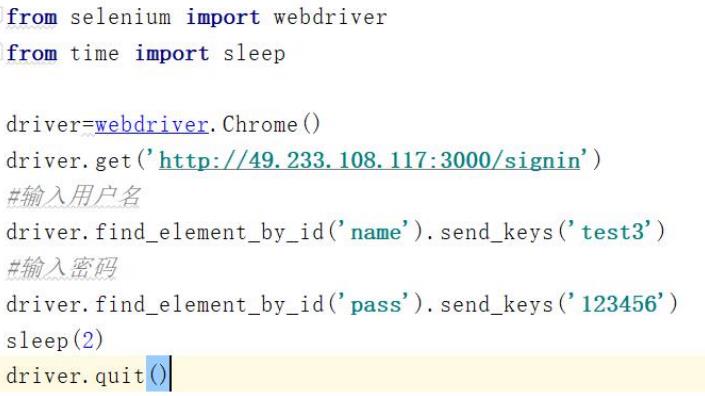
需求:打开论坛登录界面(
http://49.233.108.117:3000/signin
),通过
id
定位,输入用户 名和密码。
2:name定位
说明:
HTML
规定
name
属性来指定元素名称,
name
的属性值在当前文档中可以不是唯一
的,
name
定位就是根据
name
属性来定位
。
前提:元素有
name
属性
name
定位方法:
find_element_by_name()
实现案例
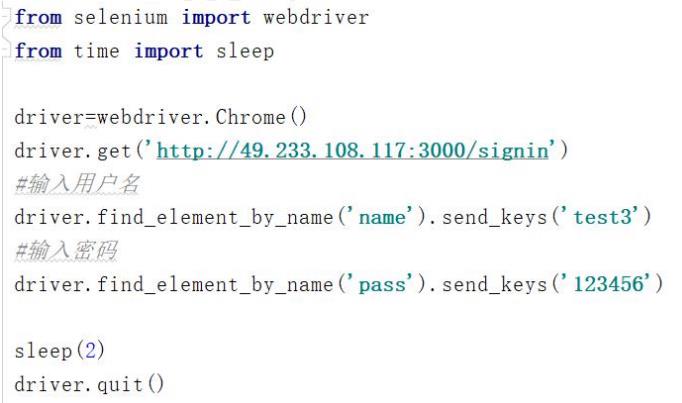
-2
需求:打开论坛登录界面(
http://49.233.108.117:3000/signin
),通过
name
定
位,输入用户名和密码。
3:class_name定位
说明:
HTML
规定
class
来指定元素的类名,
class
定位就是根据
class
属性来定位,
用法和
name,id
类似。
前提:元素有
class
属性
class_name
定位方法:
find_element_by_class_name()
实现案例
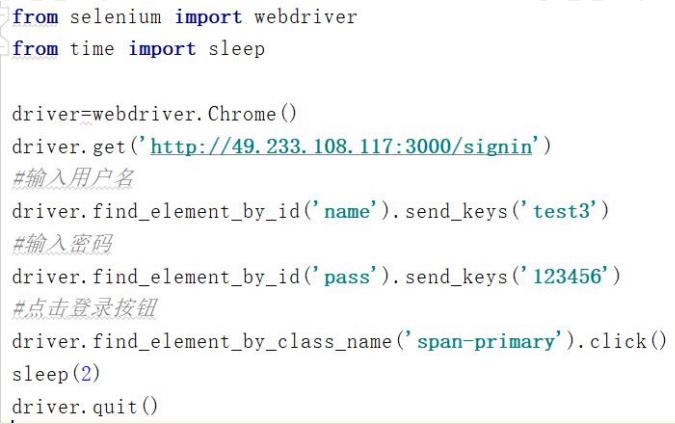
-3
需求:打开论坛登录界面(
http://49.233.108.117:3000/signin
),通过
class
定
位,输入用户名和密码,并点击登录。
4:tag_name定位
说明:
HTML
本质就是由不同的
tag(
标签
)
组成,而每个
tag
都是指同一类,所以
tag
定位效
率低,一般不建议使用;
tag_name
定位就是通过标签名来定位
。
tag_name
定位方法:
find_element_by_tag_name()
实现案例
-4
需求:打开论坛登录界面(
http://49.233.108.117:3000/signin
),通过
tag
定位,
输入用户名和密码。

5:link_text定位
说明:
link_text
定位于前面
4
个定位有所不同,它专门用来定位超链接文本
(
<a>
文本值
</a>
)
前提:
定位的元素是链接标签(
a
标签)
link_text
定位方法:
find_element_by_link_text()
实现案例
-5
需求:打开百度首页,通过
link_text(
链接文本
)
定位到
hao123
按钮,并进行点
击操作

6:partial_link_text定位
说明:
partial_link_text
定位是对
link_text
定位的补充,
partial_link_text
为模糊匹配;
link_text
为全部
匹配。
前提:
定位的元素是链接标签(
a
标签)
partial_link_text
定位方法:
find_element_by_partial_link_text()
通过传入
a
标签局部文本或全部文本来定位元素,要求输入的文本能够唯一找到这个元素
实现案例
-6
需求:打开百度新闻(
http://news.baidu.com/
),通过
partial_link_text
定位任何一条新闻, 并进行点击操作

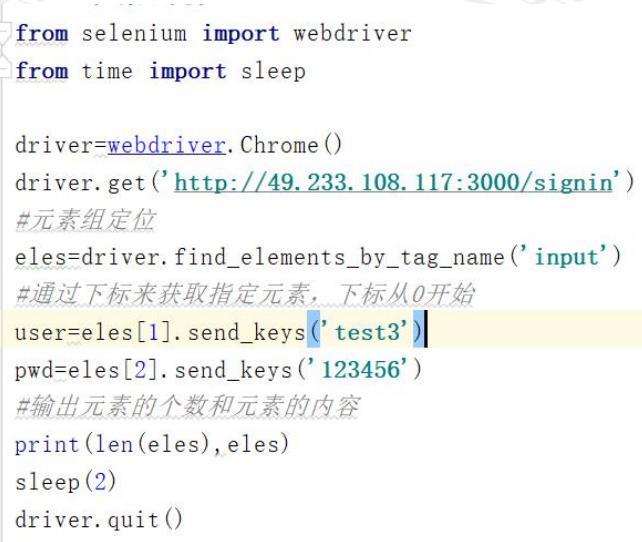
7:元素组定位
元素组定位方式:
find_elements_by_xxx
作用:
1. 查找返还定位所有符合条件的元素
2. 返还的定位元素格式为列表格式
说明:
列表数据格式的读取需要指定下标(下标从
0
开始)
案例要求:打开论坛登录界面
(
http://49.233.108.117:3000/signin
),通过元素组定位,
输入用户名和密码。
xpath和css定位
为什么要学习xpath和css定位
Ø
在实际项目中标签没有
id/name/class
属性
Ø
id/name/class
属性值为动态获取,随着刷新或加载而变化
Ø
xpath
、
css
定位可以解决以上两类问题
xpath定位
xpath概述:
1. xpath即为
xml path
的简称,它是一种用来确定
XML
文档中某部分位置的语言。
2. HTML可以看做是
XML
的一种实现,所以
selenium
用户可以使用这种强大的语言在
web
应用中来
定位元素
3. xpath为强大的语言,是因为它有非常灵活的定位策略。
定位方法:
find_element_by_xpath()
xpath定位策略(方式)
1. 路径定位--
绝对路径、相对路径
2. 利用元素属性定位
3. 层级与属性结合定位
4. 属性与逻辑定位结合
1:路径定位(绝对/相对路径)
绝对路径:从最外层元素到指定元素之间所有经过元素层级路径;如
/html/body/div/p[2]
提示:
1. 绝对路径是以/
开始
2. 通过浏览器查看元素属性,右击复制xpath
快速生成
相对路径:从第一个符合条件元素开始(一般配合属性来区分);如
//input[@id='kw']
提示:
1. 相对路径以//
开始
2. 通过浏览器查看元素属性,右击复制xpath
快速生成
2:利用元素属性
Ø
快速定位元素,利用元素唯一属性;
Ø
示例:
//*[@id='kw']
Ø
案例要求:打开论坛登录界面(
http://49.233.108.117:3000/signin
),通过
xpath
定位,输入用户名和密 码。

3:层级与属性结合
Ø
要找到的元素没有属性,但是它的父级有;
Ø
示例:
//*[@id='p1']/input
4:属性与逻辑结合
Ø
解决元素之间相同属性重名问题 ;
Ø
示例:
//*[@id='telA' and @class='telA']
css定位
Ø css概述:
1. css(Cascading Style Sheets)是一种语言,它用来描述
HTML
和
XML
的元素显示样式。
2. css语言中有
css
选择器,在
selenium
中也可以使用这种选择器来进行元素定位
3. css定位方式比
xpath
快,而且
css
的语法也非常强大,所以非常推荐这种方式定位
Ø
定位方法:
find_element_by_css_selector()
Ø css定位策略(方式)
1. id选择器
2. class选择器
3. 元素选择器
4. 属性选择器
5. 层级选择器
1:id选择器
Ø
根据元素
id
属性来选择
Ø
格式:
#id
属性值
如:
#userA(
选择
id
属性值为
userA
的所有元素
)
Ø
案例要求:打开论坛登录界面(
http://49.233.108.117:3000/signin
),通过
css
定位,输入用户名和密 码。

2:class选择器
Ø
根据元素
class
属性来选择
Ø
格式:
.class
属性值
如:
.telA(
选择
class
属性值为
telA
的所有元素
)
3:元素选择器
Ø
根据元素标签名来选择
Ø
格式:
element
如:
input(
选择所有
input
元素
)
4:属性选择器
Ø
根据元素的属性名和值来选择
Ø
格式:
[attribute=value]
如:
[type='password'](
选择所有
type
属性为
password
的值
)
Ø
打开论坛登录界面(
http://49.233.108.117:3000/signin
),通过定位,输入用户名和密码。
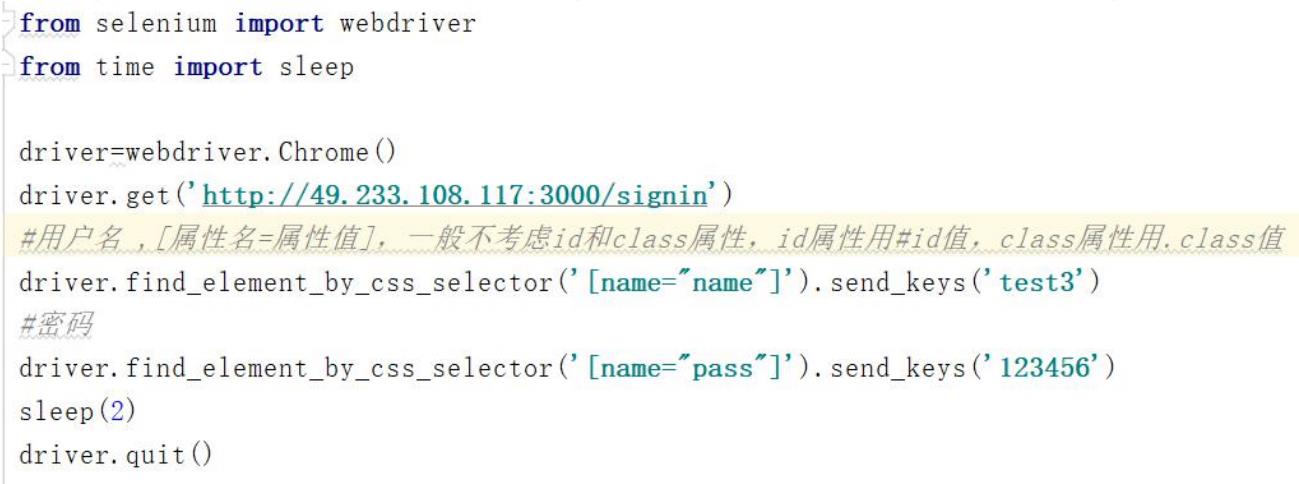
5:层级选择器
Ø
根据元素的父子关系来选择
Ø
格式:
element>element
如:
p>input(
返还所有
p
元素下所有的
input
元素
)
Ø
提示:
>
可以用空格代替,如
p input
或者
p [type='password']
总结

另一种定位-By
Ø
导入
By
类
•
导包:
from selenium.webdriver.comm.by import By
Ø
By
类的方法:
•
find_element(By.ID,'userA')
•
需要两个参数,第一个参数为定位的类型,由
By
提供,第二个参数为定位的具体方式。
下拉列表定位
下拉列表定位
Ø
下拉列表常见的前端表现形式:
Select+Option
和
ul+li
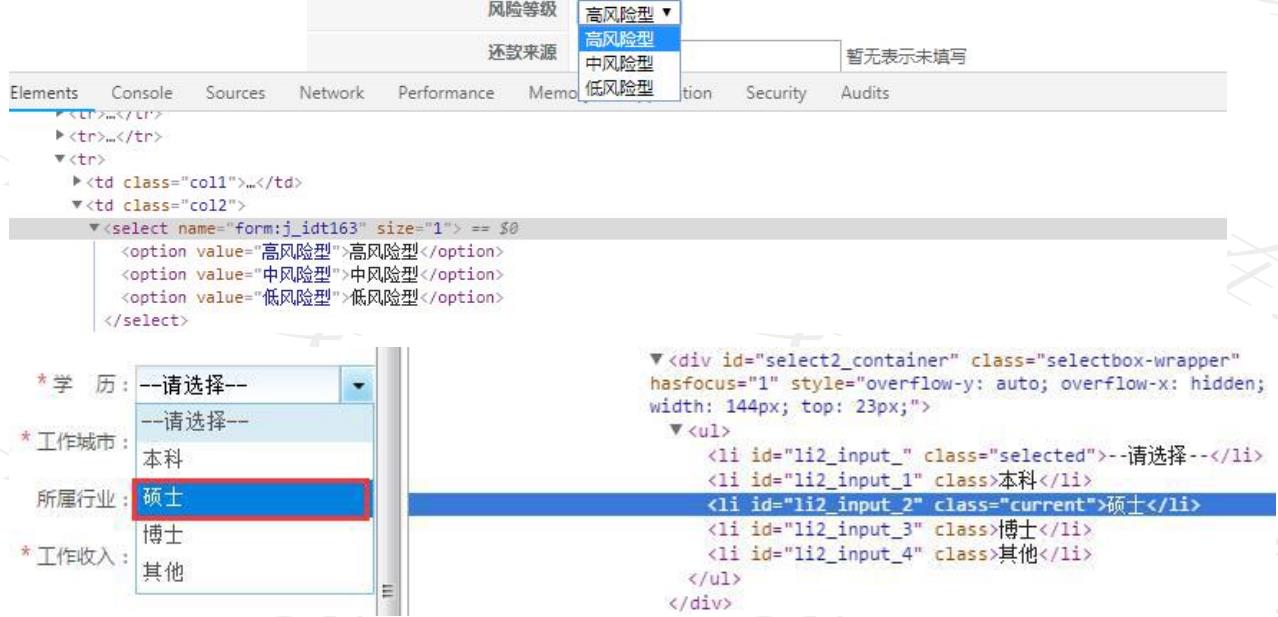
Select类型的下拉框
Ø
案例
1
:
http://127.0.0.1:5000/signin
进行登录操作,再定位
select
选项中的内容
Ø
12306
订票,
url
:
https://kyfw.12306.cn/otn/leftTicket/init?linktypeid=dc
Ø
操作流程:打开网址
--
对发车时间进行切换
Ø 步骤
1. 导包:
from selenium.webdriver.support.ui import Select
2. 定位Select
元素
3. 定位option
选项:通过调用
Select
的方法来进行定位选项
:
select_by_value()
、
select_by_index()
、
select_by_visible_text()
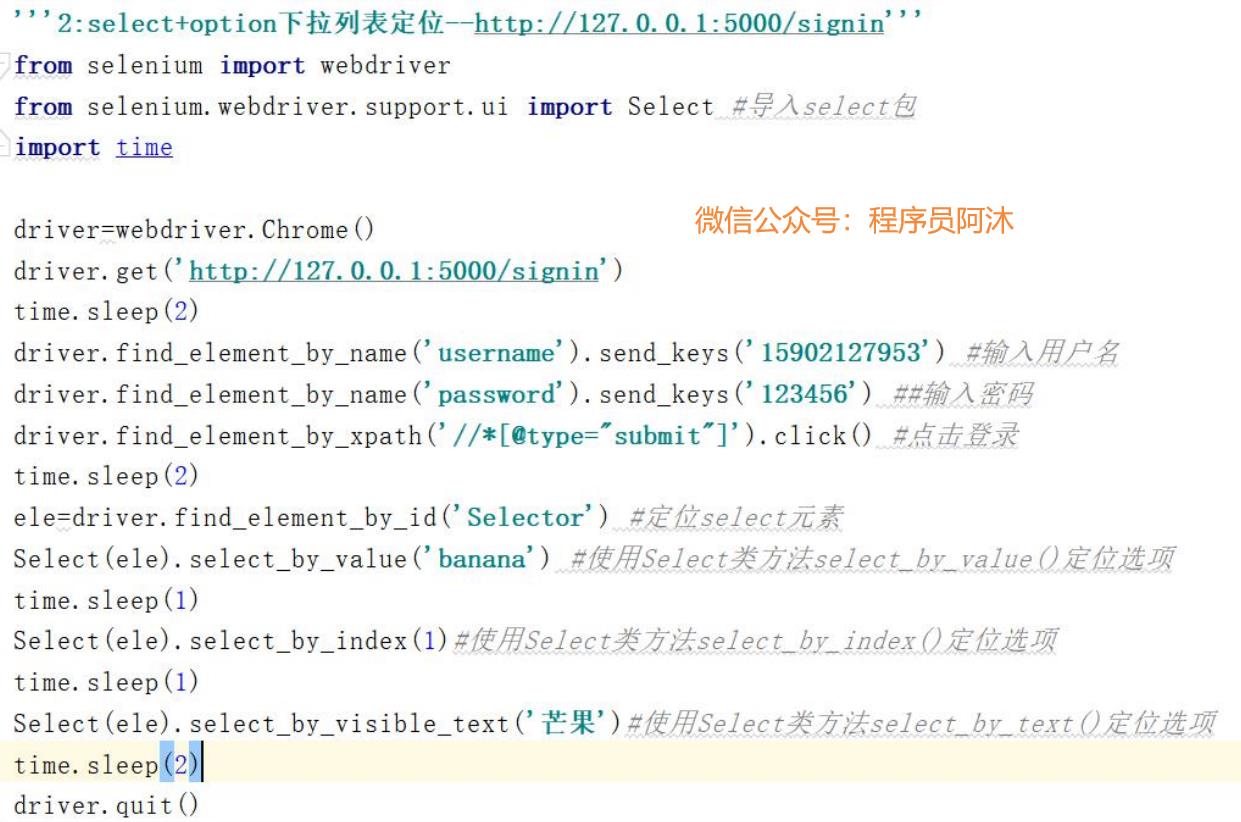
ul+li类型的下拉框
Ø
定位非
<select>
标签的下拉菜单中的选项,需要两个步骤,
先定位到下拉菜单,再对其中
的选项进行定位。
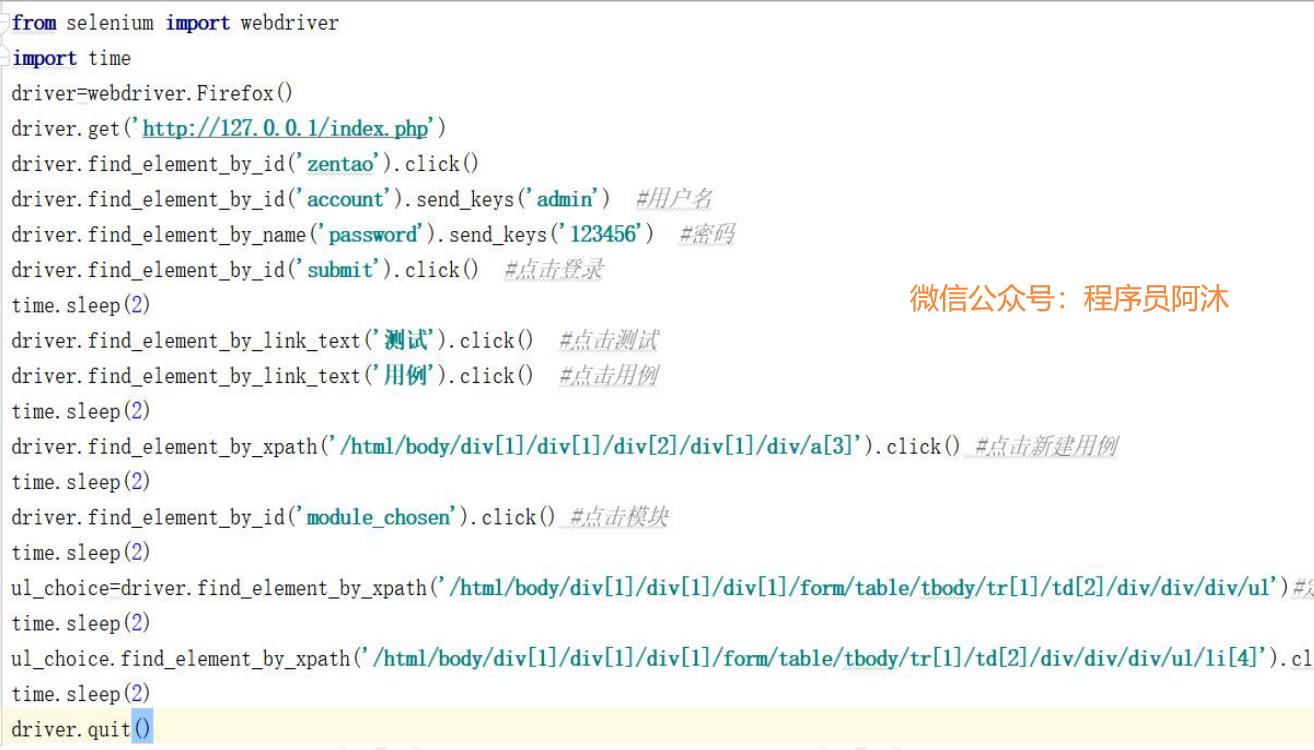
解题思路:
1. 先定位到ul
,并且将定位到的值赋给变量
a
a=driver.find_element_by_id("ul
的
id")
2. 再用变量a
去找到
li
a.find_element_by_id("li
的
id").click()
元素常用属性
webElement常用属性与方法
Ø
定位到元素后,除了对元素进行操作,还可以获取元素的一些属性信息。常见的属性信息:
1. 获取元素的尺寸:
ele.size
2. 获取元素的坐标:
ele.location
3. 获取元素的文本内容:
ele.text
text
是存在在一对
a
标签、
p
标签或
div
标签中的文本内容,如果 是标签中的value
值,是不能通过这种方式来获取到的。
4. 获取元素的属性值:
ele.get_attribut(
属性名
)
通过传入不同的属性名来获取对应的属性值
5. 获取页面的url
:
driver.current_url
对
url
获取再进行判断,是一种常用的检查方式
6. 获取页面的title
:
driver.title
对
title
获取再进行判断,也还是一种常用的检查方式
微信搜一搜【程序员阿沐】关注这个文绉绉的程序员,关注后主页点击【领取资料】有我准备的一线大厂面试资料和简历模板,希望大家都能找到心仪的工作,学习是一条时而郁郁寡欢,时而开怀大笑的路,加油。如果你通过努力成功进入到了心仪的公司,一定不要懈怠放松,职场成长和新技术学习一样,不进则退。如果有幸我们江湖再见!
以上是关于终于有大佬把软件测试的元素定位总结得这么通俗易懂了!的主要内容,如果未能解决你的问题,请参考以下文章