小白学习PyTorch教程十基于大型电影评论数据集训练第一个LSTM模型
Posted 刘润森!
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了小白学习PyTorch教程十基于大型电影评论数据集训练第一个LSTM模型相关的知识,希望对你有一定的参考价值。
@Author:Runsen
本博客对原始IMDB数据集进行预处理,建立一个简单的深层神经网络模型,对给定数据进行情感分析。
import numpy as np
# read data from text files
with open('reviews.txt', 'r') as f:
reviews = f.read()
with open('labels.txt', 'r') as f:
labels = f.read()
编码
在将数据输入深度学习模型之前,应该将其转换为数值,文本转换被称为编码,这涉及到每个字符转换成一个整数。在进行编码之前,需要清理数据。
有以下几个预处理步骤:
- 删除标点符号。
- 使用\\n作为分隔符拆分文本。
- 把所有的评论重新组合成一个大串。
from string import punctuation
# remove punctuation
reviews = reviews.lower()
text = ''.join([c for c in reviews if c not in punctuation])
print(punctuation) # !"#$%&'()*+,-./:;<=>?@[\\]^_`{|}~
# split by new lines and spaces
reviews_split = text.split('\\n')
text = ' '.join(reviews_split)
# create a list of words
words = text.split()
建立字典并对评论进行编码
创建一个字典,将词汇表中的单词映射为整数。然后通过这个字典,评论可以转换成整数,然后再传送到模型网络。
from collections import Counter
word_counts = Counter(words)
vocab = sorted(word_counts, key = word_counts.get, reverse = True)
vocab2idx = {vocab:idx for idx, vocab in enumerate(vocab, 1)}
print("Size of Vocabulary: ", len(vocab))
Size of Vocabulary: 74072
encoded_reviews = []
for review in reviews_split:
encoded_reviews.append([vocab2idx[vocab] for vocab in review.split()])
print("The number of reviews: ", len(encoded_reviews))
The number of reviews: 25001
对标签进行编码
Negative 和Positive应分别标记为0和1(整数)
splitted_labels = labels.split("\\n")
encoded_labels = np.array([
1 if label == "positive" else 0 for label in splitted_labels
])
删除异常值
应删除长度为0评论,然后,将对剩余的数据进行填充,保证所有数据具有相同的长度。
length_reviews = Counter([len(x) for x in encoded_reviews])
print("Zero-length reviews: ", length_reviews[0])
print("Maximum review length: ", max(length_reviews))
Zero-length reviews: 1
Maximum review length: 2514
# reviews with length 0
non_zero_idx = [i for i, review in enumerate(encoded_reviews) if len(review) != 0]
# Remove 0-length reviews
encoded_reviews = [encoded_reviews[i] for i in non_zero_idx]
encoded_labels = np.array([encoded_labels[i] for i in non_zero_idx])
填充序列
下面要处理很长和很短的评论,需要使用0填充短评论,使其适合特定的长度,
并将长评论剪切为seq_length的单词。这里设置seq_length=200
def text_padding(encoded_reviews, seq_length):
reviews = []
for review in encoded_reviews:
if len(review) >= seq_length:
reviews.append(review[:seq_length])
else:
reviews.append([0]*(seq_length-len(review)) + review)
return np.array(reviews)
seq_length = 200
padded_reviews = text_padding(encoded_reviews, seq_length)
print(padded_reviews[:12, :12])
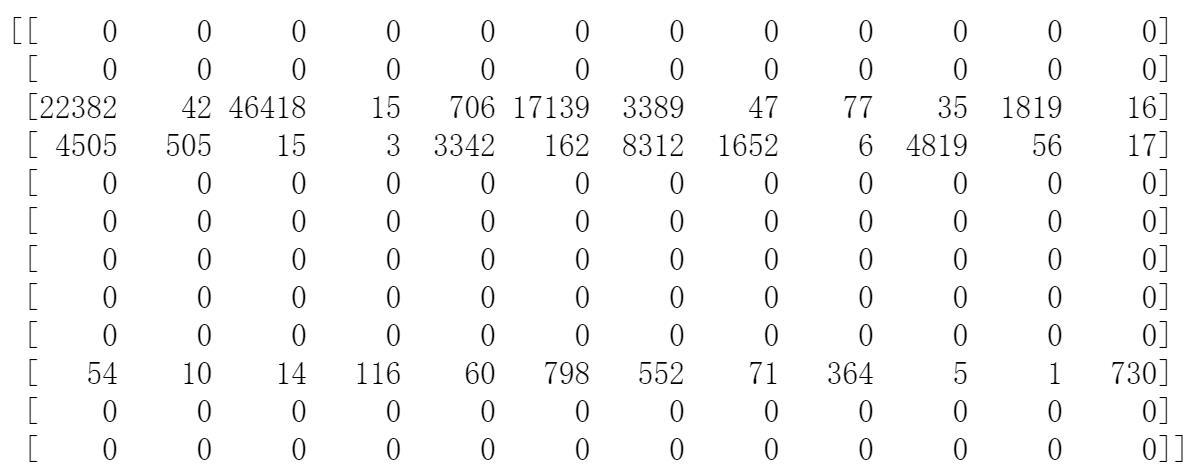
数据加载器
将数据按8:1:1的比例拆分为训练集、验证集和测试集,然后使用“TensorDataset”和“DataLoader”函数来处理评论和标签数据。
ratio = 0.8
train_length = int(len(padded_reviews) * ratio)
X_train = padded_reviews[:train_length]
y_train = encoded_labels[:train_length]
remaining_x = padded_reviews[train_length:]
remaining_y = encoded_labels[train_length:]
test_length = int(len(remaining_x)*0.5)
X_val = remaining_x[: test_length]
y_val = remaining_y[: test_length]
X_test = remaining_x[test_length :]
y_test = remaining_y[test_length :]
print("Feature shape of train review set: ", X_train.shape)
print("Feature shape of val review set: ", X_val.shape)
print("Feature shape of test review set: ", X_test.shape)

import torch
from torch.utils.data import TensorDataset, DataLoader
batch_size = 50
device = "cuda" if torch.cuda.is_available() else "cpu"
train_dataset = TensorDataset(torch.from_numpy(X_train).to(device), torch.from_numpy(y_train).to(device))
valid_dataset = TensorDataset(torch.from_numpy(X_val).to(device), torch.from_numpy(y_val).to(device))
test_dataset = TensorDataset(torch.from_numpy(X_test).to(device), torch.from_numpy(y_test).to(device))
train_loader = DataLoader(train_dataset, batch_size = batch_size, shuffle = True)
valid_loader = DataLoader(valid_dataset, batch_size = batch_size, shuffle = True)
test_loader = DataLoader(test_dataset, batch_size = batch_size, shuffle = True)
data_iter = iter(train_loader)
X_sample, y_sample = data_iter.next()
RNN模型的实现
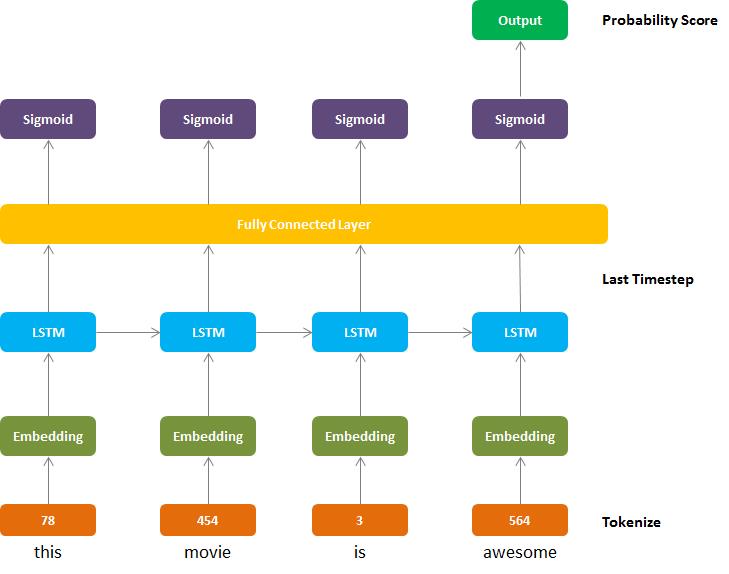
到目前为止,包括标记化在内的预处理已经完成。现在建立一个神经网络模型来预测评论的情绪。
-
首先,嵌入层将单词标记转换为特定大小。
-
第二,一个 LSTM层,由
hidden_size和num_layers定义。 -
第三,通过完全连接的层从LSTM层的输出映射期望的输出大小。
-
最后,sigmoid激活层以概率0到1的形式返回输出。
import torch.nn as nn
from torch.autograd import Variable
class Model(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim, output_dim, num_layers):
super(Model, self).__init__()
self.hidden_dim = hidden_dim
self.num_layers = num_layers
# embedding and LSTM
self.embedding = nn.Embedding(vocab_size, embedding_dim)
self.lstm = nn.LSTM(input_size = embedding_dim,
hidden_size = hidden_dim,
num_layers = num_layers,
batch_first = True,
dropout = 0.5,
bidirectional = False)
# 完连接层
self.fc = nn.Sequential(
nn.Dropout(0.5),
nn.Linear(hidden_dim, output_dim),
nn.Sigmoid()
)
def forward(self, token, hidden):
batch_size = token.size(0)
# embedding and lstm output
out = self.embedding(token.long())
out, hidden = self.lstm(out, hidden)
# stack up lstm outputs
out = out.contiguous().view(-1, self.hidden_dim)
# fully connected layer
out = self.fc(out)
# reshape to be batch_size first
out = out.view(batch_size, -1)
# get the last batch of labels
out = out[:, -1]
return out
def init_hidden(self, batch_size):
return (Variable(torch.zeros(self.num_layers, batch_size, self.hidden_dim).to(device)),
Variable(torch.zeros(self.num_layers, batch_size, self.hidden_dim).to(device)))
- vocab_size : 词汇量
- embedding_dim : 嵌入查找表中的列数
- hidden_dim : LSTM单元隐藏层中的单元数
- output_dim : 期望输出的大小
vocab_size = len(vocab)+1 # +1 for the 0 padding + our word tokens
embedding_dim = 400
hidden_dim = 256
output_dim = 1
num_layers = 2
model = Model(vocab_size, embedding_dim, hidden_dim, output_dim, num_layers).to(device)
model

训练
对于损失函数,BCELoss被用于二分类交叉熵损失,通过给出介于0和1之间的概率进行分类。使用Adam优化器,学习率为0.001
另外,torch.nn.utils.clip_grad_norm_(model.parameters(), clip = 5),防止了RNN中梯度的爆炸和消失问题clip是要剪裁最大值。
# Loss function and Optimizer
criterion = nn.BCELoss()
optimizer = torch.optim.Adam(model.parameters(), lr = 0.001)
for epoch in range(num_epochs):
model.train()
hidden = model.init_hidden(batch_size)
for i, (review, label) in enumerate(train_loader):
review, label = review.to(device), label.to(device)
# Initialize Optimizer
optimizer.zero_grad()
hidden = tuple([h.data for h in hidden])
# Feed Forward
output = model(review, hidden)
# Calculate the Loss
loss = criterion(output.squeeze(), label.float())
# Back Propagation
loss.backward()
# Prevent Exploding Gradient Problem
nn.utils.clip_grad_norm_(model.parameters(), 5)
# Update
optimizer.step()
train_losses.append(loss.item())
# Print Statistics
if (i+1) % 100 == 0:
### Evaluation ###
# initialize hidden state
val_h = model.init_hidden(batch_size)
val_losses = []
model.eval()
for review, label in valid_loader:
review, label = review.to(device), label.to(device)
val_h = tuple([h.data for h in val_h])
output = model(review, val_h)
val_loss = criterion(output.squeeze(), label.float())
val_losses.append(val_loss.item())
print("Epoch: {}/{} | Step {}, Train Loss {:.4f}, Val Loss {:.4f}".
format(epoch+1, num_epochs, i+1, np.mean(train_losses), np.mean(val_losses)))
以上是关于小白学习PyTorch教程十基于大型电影评论数据集训练第一个LSTM模型的主要内容,如果未能解决你的问题,请参考以下文章