❤️Spark的关键技术回顾,持续更新!推荐收藏加关注❤️
Posted Lansonli
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了❤️Spark的关键技术回顾,持续更新!推荐收藏加关注❤️相关的知识,希望对你有一定的参考价值。
目录
4、使用Spark-shell的方式也可以交互式写Spark代码?
12、RDD-DataSet和DataFrame的区别和联系?
16、SparkSQL中SQL风格全局Session和局部的Session的差别是什么?
18、[非常重要]SparkSQL如何执行SQL的,SQL的查询引擎
22、SparkStreaming和Kafka的整合,如何获取Offset,010整合
24、生产者生产数据过多,消费者SparkStreaming来不及消费,请问造成什么现象?
前言
2021大数据领域优质创作博客,带你从入门到精通,该博客每天更新,逐渐完善大数据各个知识体系的文章,帮助大家更高效学习。

Spark的关键技术回顾
一、Spark复习题回顾
1、Spark使用的版本
2.4.5版本,目前3.1.2为最新版本
集群环境:CDH版本是5.14.0这个版本
但由于spark对应的5.14.0的CDH版本的软件默认的版本是1.6.0同时阉割了SarkSQL,需要重新编译
原因: 因为Cloudera公司认为有了impala就不需要再使用sparkSQL的功能了,同时也是为了推广impala,所以直接阉割掉了sparkSQL的模块。
解决: 使用Apache的版本的spark来进行重新编译
2、Spark几种部署方式?
- Local(local[*],所有的cpu cores)
- StandAlone(Master-local)
- StandAloneHA(多个Master)
- Yarn(RS-NM) --client 模式和cluster 模式
3、Spark的提交任务的方式?
bin/spark-submit \\
--master local/spark:node01:7077/spark:node01:7077,node02:70777 \\
--deploy-mode client/cluster \\ #client指的是driver启动在本地,cluster指的是driver启动在Worker接点运行
--class application-main
--executor-memory 每个executor的内存,默认是1G
--total-executor-cores 所有executor总共的核数。仅仅在 mesos 或者 standalone 下使用
--executor-core 每个executor的核数。在yarn或者standalone下使用
--driver-memory Driver内存,默认 1G
--driver-cores Driver 的核数,默认是1。在 yarn 或者 standalone 下使用
--num-executors 启动的executor数量。默认为2。在 yarn 下使用
.....
jar包地址
参数1 参数2
4、使用Spark-shell的方式也可以交互式写Spark代码?
bin/spark-shell --master local --executor-core 2 --executor-memory 512m
5、你对RDD是怎么理解的?
(1)RDD是弹性分布式数据集
(2)RDD有五大属性:1-RDD是可分区的(0-1-2号分区) 2-RDD有作用函数(map) 3-RDD是依赖关系 4-对key-value的类型RDD的默认分区HashPartitoner 5-位置优先性
wordount的时候:
sc.textFile().flatmap().map().redyceByKey()
如何查看当前算子是什么分区器?函数rdd.partitioner
(3)RDD的宽依赖和窄依赖:根据父RDD有一个或多个子RDD对应,因为窄依赖可以在任务间并行,宽依赖会发生Shuffle,并不是所有的bykey算子都会产生shuffle?需要注意的是(1)分区器一致(2)分区个数一致
(4)RDD血缘关系linage:linage会记录当前RDD依赖于上一个RDD,如果一个RDD失效可以重建RDD,容错关键
(5)RDD的缓存:cache和persist,cache会将数据缓存在内存中,persist可以指定多种存储级别,cache底层调用的是persist
(6)RDD的检查点机制:Checkpoint会截断所有的血缘关系,而缓存会将血缘的关系全部保存在内存或磁盘中
6、Spark如何实现容错?
Spark会首先查看内存中是否已经cache或persist还原,否则查看linage是否checkpoint在hdfs中
根据依赖关系重建RDD
7、Spark共享变量?
累加器
Spark提供的Accumulator,主要用于多个节点对一个变量进行共享性的操作。Accumulator只提供了累加的功能,即确提供了多个task对一个变量并行操作的功能。但是task只能对Accumulator进行累加操作,不能读取Accumulator的值,只有Driver程序可以读取Accumulator的值
(在driver端定义的变量在executor端拿到的是副本,exector执行完计算不会更新到driver)
广播变量
广播变量允许开发人员在每个节点(Worker or Executor)缓存只读变量,而不是在Task之间传递这些变量。使用广播变量能够高效地在集群每个节点创建大数据集的副本。同时Spark还使用高效的广播算法分发这些变量,从而减少通信的开销
(对于1M的数据,开启1000个maptask,当前的1M的数据会发送到所有的task中进行计算,会产生1G网络数据传输,引入广播变量将1M数据共享在Executor中而不是task中,task共享的是一个变量的副本,广播变量是只读的,不能再exectour端修改)
8、Spark的任务执行?
1-Spark一个Application拥有多个job,一个action操作会出发一个Job划分
2-Spark一个Job有多个Stages,发生shuffle操作触发一个Stage的划分
3-一个Stage有很多个tasksets,一个RDD的不同的分区就是代表的taskset,很多的taskset组成tasksets
4-一个taskset由很多个RDD的分区组成,一个RDD的分区的数据需要由一个task线程拉取执行,而不是进程
9、Spark的RDD的几种类型?
transformation和action类型
1)Transformation转换操作:返回一个新的RDD
所有Transformation函数都是Lazy,不会立即执行,需要Action函数触发
2)Action动作操作:返回值不是RDD(无返回值或返回其他的)
所有Action函数立即执行(Eager),比如count、first、collect、take等
10、Spark的Transformation算子有几类?
3类
单value:如mapValue,map,filter
双value:union,zip,distinct
key-value类型:reduceBykey(一定不属于Action算子),foldByKey
| 转换 | 含义 |
| map(func) | 返回一个新的RDD,该RDD由每一个输入元素经过func函数转换后组成 |
| filter(func) | 返回一个新的RDD,该RDD由经过func函数计算后返回值为true的输入元素组成 |
| flatMap(func) | 类似于map,但是每一个输入元素可以被映射为0或多个输出元素(所以func应该返回一个序列,而不是单一元素) |
| mapPartitions(func) | 类似于map,但独立地在RDD的每一个分片上运行,因此在类型为T的RDD上运行时,func的函数类型必须是Iterator[T] => Iterator[U] |
| mapPartitionsWithIndex(func) | 类似于mapPartitions,但func带有一个整数参数表示分片的索引值,因此在类型为T的RDD上运行时,func的函数类型必须是 (Int, Interator[T]) => Iterator[U] |
| sample(withReplacement, fraction, seed) | 根据fraction指定的比例对数据进行采样,可以选择是否使用随机数进行替换,seed用于指定随机数生成器种子 |
| union(otherDataset) | 对源RDD和参数RDD求并集后返回一个新的RDD |
| intersection(otherDataset) | 对源RDD和参数RDD求交集后返回一个新的RDD |
| distinct([numTasks])) | 对源RDD进行去重后返回一个新的RDD |
| groupByKey([numTasks]) | 在一个(K,V)的RDD上调用,返回一个(K, Iterator[V])的RDD |
| reduceByKey(func, [numTasks]) | 在一个(K,V)的RDD上调用,返回一个(K,V)的RDD,使用指定的reduce函数,将相同key的值聚合到一起,与groupByKey类似,reduce任务的个数可以通过第二个可选的参数来设置 |
| aggregateByKey(zeroValue)(seqOp, combOp, [numTasks]) | |
| sortByKey([ascending], [numTasks]) | 在一个(K,V)的RDD上调用,K必须实现Ordered接口,返回一个按照key进行排序的(K,V)的RDD |
| sortBy(func,[ascending], [numTasks]) | 与sortByKey类似,但是更灵活 |
| join(otherDataset, [numTasks]) | 在类型为(K,V)和(K,W)的RDD上调用,返回一个相同key对应的所有元素对在一起的(K,(V,W))的RDD |
| cogroup(otherDataset, [numTasks]) | 在类型为(K,V)和(K,W)的RDD上调用,返回一个(K,(Iterable<V>,Iterable<W>))类型的RDD |
| cartesian(otherDataset) | 笛卡尔积 |
| pipe(command, [envVars]) | 对rdd进行管道操作 |
| coalesce(numPartitions) | 减少 RDD 的分区数到指定值。在过滤大量数据之后,可以执行此操作 |
| repartition(numPartitions) | 重新给 RDD 分区 |
11、RDD创建的三种方法?
sc.textfile,sc.makerdd/paralleise,RDD之间的转换
12、RDD-DataSet和DataFrame的区别和联系?
RDD+Scheme=DataFrame.as[]+泛型=DataSet.rdd=RDD,
DataFrame是弱类型的数据类型,在运行时候数据类型检查,
DataSet是强类型的数据类型,在编译时候进行类型检查
13、SparkSQL中查询一列的字段的方法有几种?
df.select(['id']),
df.select(col('id')),
df.select(colomns('id')),
df.select('id),
df.select($"")14、SparkSQL中的如何动态增加Schema?
查看DataFrame中Schema是什么,执行如下命令:
df.schema
Schema信息封装在StructType中,包含很多StructField对象,源码。
StructType 定义,是一个样例类,属性为StructField的数组
![]()
StructField 定义,同样是一个样例类,有四个属性,其中字段名称和类型为必填‘’
自定义Schema结构,官方提供的示例代码:

StructedType(StructedFileld(data,name,nullable)::Nil),
new StructedType().add(data,name,nullable).add()
15、SparkSQL中DSL和SQL风格差异?
DSL风格df.select,SQL风格需要注册一张临时表或试图进行展示
基于DSL分析
调用DataFrame/Dataset中API(函数)分析数据,其中函数包含RDD中转换函数和类似SQL语句函数,部分截图如下:
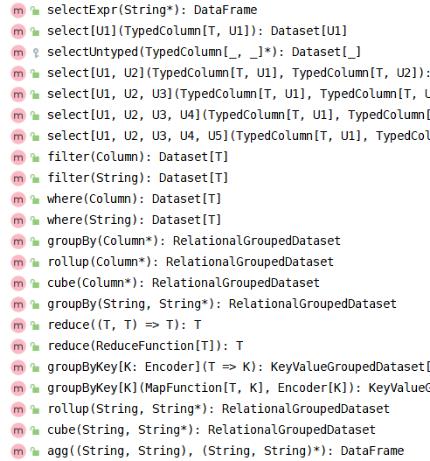
基于SQL分析
将Dataset/DataFrame注册为临时视图,编写SQL执行分析,分为两个步骤:
第一步、注册为临时视图
![]()
第二步、编写SQL,执行分析

16、SparkSQL中SQL风格全局Session和局部的Session的差别是什么?
全局的Session可以跨Session访问注册的临时试图或表,局部Session只能访问临时试图或表
17、SparkSQL整合Hive?
SparkSQL除了引用Hive的元数据的信息之外,其他的Hive部分都没有耦合
Spark引擎替代了HIve的执行引擎,可以在SPark程序中使用HIve的语法完成SQ的分析
第一步:将hive-site.xml拷贝到spark安装路径conf目录
第二步:将mysql的连接驱动包拷贝到spark的jars目录下
第三步:Hive开启MetaStore服务
第四步:测试Sparksql整合Hive是否成功
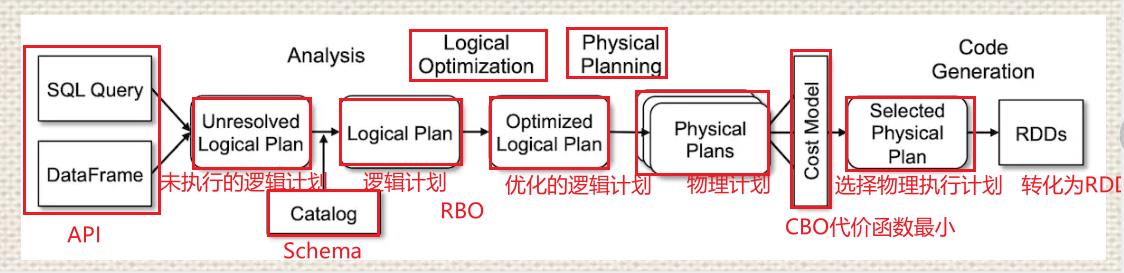
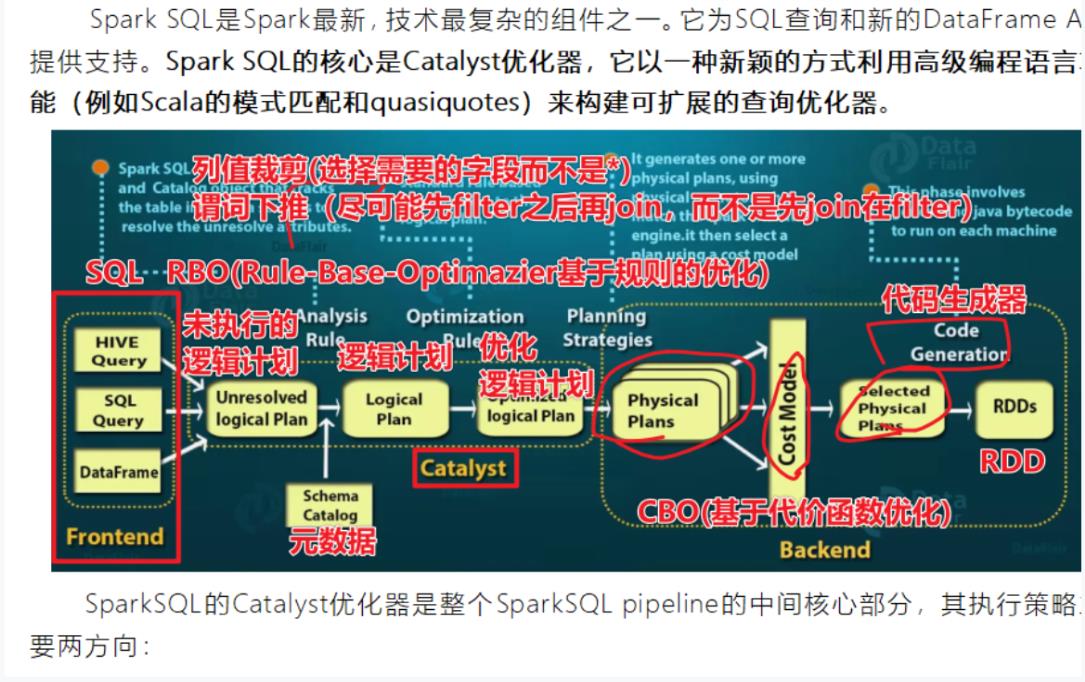
18、[非常重要]SparkSQL如何执行SQL的,SQL的查询引擎
基于规则优化(Rule-based optimization, RBO----过滤下推,常量折叠)-逻辑执行计划中,进行逻辑计划优化
基于代价优化(Cost-based optimization, CBO)----物理执行计划中选择最优物理执行计划

19、SparkStreaming几种编程模式?
有状态(updateStateByKey\\mapState)、无状态(reduceByKey)、窗口操作(windows,reduceByKeyANdWIndows)
20、对于DStream如何使用RDD的方法?
(transform)
21、SparkStreaming的有状态的几种形式?
updateStateByKey\\mapState
22、SparkStreaming和Kafka的整合,如何获取Offset,010整合
KafkaUtils.createdirctstream(SSC,Kafka的parititon和Spark的eceutor是否在一个节点,Consumer.subscribe(Array(kafkatopic),params))
获取Offset:StreamData.asInstanceOf[HasOffSetRanges].offsetRanges
提交Offset:StreamData.asInstanceOf[CancommitOffSetRanges].async(offSetRanges)
#http://spark.apache.org/docs/latest/streaming-kafka-0-10-integration.html
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "localhost:9092,anotherhost:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "use_a_separate_group_id_for_each_stream",
"auto.offset.reset" -> "latest",
"enable.auto.commit" -> (false: java.lang.Boolean)
)
val topics = Array("topicA", "topicB")
val stream = KafkaUtils.createDirectStream[String, String](
streamingContext,
PreferConsistent,
Subscribe[String, String](topics, kafkaParams)
)
stream.map(record => (record.key, record.value))
stream.foreachRDD { rdd =>
val offsetRanges = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
// some time later, after outputs have completed
stream.asInstanceOf[CanCommitOffsets].commitAsync(offsetRanges)
}package cn.it.sparkstreaming.kafka
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* DESC:
* 1-导入有kafka和spark整合的Jar包
* 2-调用streamingCOntext
* 3-KafkaUtils.creatDriectlyStream的方法直接连接Kafka集群的分区
* 4-获取record记录中的value的值
* 5-根据value进行累加求和wordcount
* 6-ssc.statrt
* 7-ssc.awaitTermination
* 8-ssc.stop(true,true)
*/
object _01SparkStreamingKafkaAuto {
def updateFunc(curentValue: Seq[Int], histouryValue: Option[Int]): Option[Int] = {
val sum: Int = curentValue.sum + histouryValue.getOrElse(0)
Option(sum)
}
val kafkaParams = Map[String, Object](
"bootstrap.servers" -> "node1:9092",
"key.deserializer" -> classOf[StringDeserializer],
"value.deserializer" -> classOf[StringDeserializer],
"group.id" -> "spark_group",
//offset的偏移量自动设置为最新偏移量,有几种设置偏移量的方法
// //这里的auto.offset.reset代表的是自动重置offset为latest就表示的是最新的偏移量,如果没有偏移从最新的位置开始
"auto.offset.reset" -> "latest",
//是否自动提交,这里设置为自动提交,提交到kafka指导的__consumertopic中,有kafka自己维护,如果设置为false可以使用ckeckpoint或者是将offset存入mysql
// //这里如果是false手动提交,默认由SparkStreaming提交到checkpoint中,在这里也可以根据用户或程序员将offset偏移量提交到mysql或redis中
"enable.auto.commit" -> (true: java.lang.Boolean),
//自动设置提交的时间
"auto.commit.interval.ms" -> "1000"
)
def main(args: Array[String]): Unit = {
//1-导入有kafka和spark整合的Jar包
//2-调用streamingCOntext
val ssc: StreamingContext = {
val conf: SparkConf = new SparkConf().setAppName(this.getClass.getSimpleName.stripSuffix("$")).setMaster("local[*]")
val ssc = new StreamingContext(conf, Seconds(5))
ssc
}
ssc.checkpoint("data/baseoutput/cck3")
//3-KafkaUtils.creatDriectlyStream的方法直接连接Kafka集群的分区
//ssc: StreamingContext,
//locationStrategy: LocationStrategy,
//consumerStrategy: ConsumerStrategy[K, V]
val streamRDD: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream[String, String](ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](Array("spark_kafka"), kafkaParams))
//4-获取record记录中的value的值
val mapValue: DStream[String] = streamRDD.map(_.value())
//5-根据value进行累加求和wordcount
val resultRDD: DStream[(String, Int)] = mapValue
.flatMap(_.split("\\\\s+"))
.map((_, 1))
.updateStateByKey(updateFunc)
resultRDD.print()
//6-ssc.statrt
ssc.start()
//7-ssc.awaitTermination
ssc.awaitTermination()
//8-ssc.stop(true,true)
ssc.stop(true, true)
}
}结构化流整合kafka
package cn.it.structedstreaming.kafka
import org.apache.spark.SparkConf
import org.apache.spark.sql.streaming.{OutputMode, StreamingQuery, Trigger}
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
/**
* DESC:
* * 1-准备上下文环境
* * 2-读取Kafka的数据
* * 3-将Kafka的数据转化,实现单词统计技术
* * 4-将得到结果写入控制台
* * 5.query.awaitTermination
* * 6-query.stop
*/
object _01KafkaSourceWordcount {
def main(args: Array[String]): Unit = {
//1-准备上下文环境
val conf: SparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[*]")
val spark: SparkSession = SparkSession
.builder()
.config(conf)
.config("spark.sql.shuffle.partitions", "4")
.getOrCreate()
//spark.sparkContext.setLogLevel("WARN")
import spark.implicits._
//2-读取Kafka的数据
val streamDF: DataFrame = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "node1:9092")
.option("subscribe", "wordstopic")
.load()
//streamDF.printSchema()
//root
// |-- key: binary (nullable = true)
// |-- value: binary (nullable = true)
// |-- topic: string (nullable = true)
// |-- partition: integer (nullable = true)
// |-- offset: long (nullable = true)
// |-- timestamp: timestamp (nullable = true)
// |-- timestampType: integer (nullable = true)
//3-将Kafka的数据转化,实现单词统计技术
val result: Dataset[Row] = streamDF
.selectExpr("cast (value as string)") //因为kafka得到的数据是binary类型的数据需要使用cast转换
.as[String]
.flatMap(x => x.split("\\\\s+")) // |-- value: string (nullable = true)
.groupBy($"value")
.count()
.orderBy('count.desc)
//.groupBy("value")
//4-将得到结果写入控制台
val query: StreamingQuery = result
.writeStream
.format("console")
.outputMode(OutputMode.Complete())
.trigger(Trigger.ProcessingTime(0))
.option("numRows", 10)
.option("truncate", false)
.start()
//5.query.awaitTermination
query.awaitTermination()
//6-query.stop
query.stop()
}
}23、SparkStreaming有两个时间?
Spark Streaming接收器接收到的数据在存储到Spark中之前的时间间隔被分成数据块。 最低建议-50毫秒。
一个时间是接收器接受数据的时间--默认是200ms,数据到来每隔200ms获取一次数据,合并数据形成DStream
一个时间是SParkStreaming获取到数据后处理时间--StreamingContext(sc,Second(5)),这才是SparkStreaming批处理时间
24、生产者生产数据过多,消费者SparkStreaming来不及消费,请问造成什么现象?
背压,或反压
SparkStreaming反压
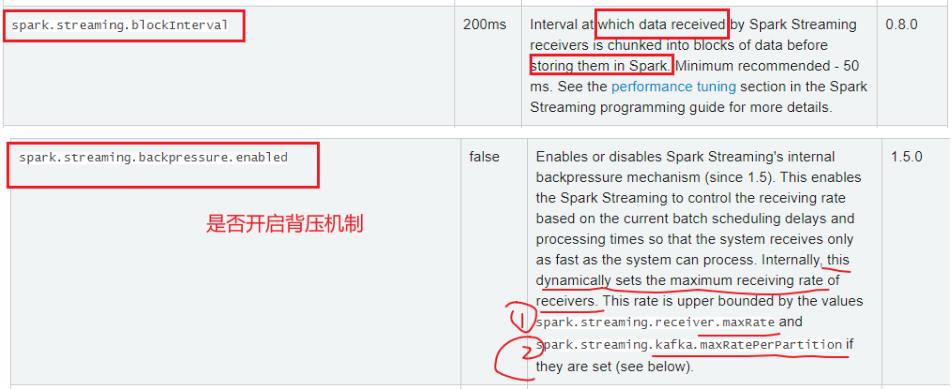
在SParkStreaming中是默认关闭,在Flink中是默认开启的,背压在SParkStreaing中自动动态的根据接收器接受最大速率和kafka的topic的分区的个数确定
- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢大数据系列文章会每天更新,停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨
以上是关于❤️Spark的关键技术回顾,持续更新!推荐收藏加关注❤️的主要内容,如果未能解决你的问题,请参考以下文章
❤️让人心跳加速的陌陌案例,大数据必需学会的基础案例!❤️ 推荐收藏
❤️让人心跳加速的陌陌案例,大数据必需学会的基础案例!❤️ 推荐收藏
2021最全算法和数据结构学习路线——java大厂面试必备❤️持续更新,建议收藏
❤️手撕这十道HiveSQL题还不能吊打面试官,却能保你不被吊打❤️推荐收藏