Tomcat多层容器的设计
Posted JavaEdge.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Tomcat多层容器的设计相关的知识,希望对你有一定的参考价值。
Tomcat的容器用来装载Servlet。那Tomcat的Servlet容器是如何设计的呢?
容器的层次结构
Tomcat设计了4种容器:Engine、Host、Context和Wrapper
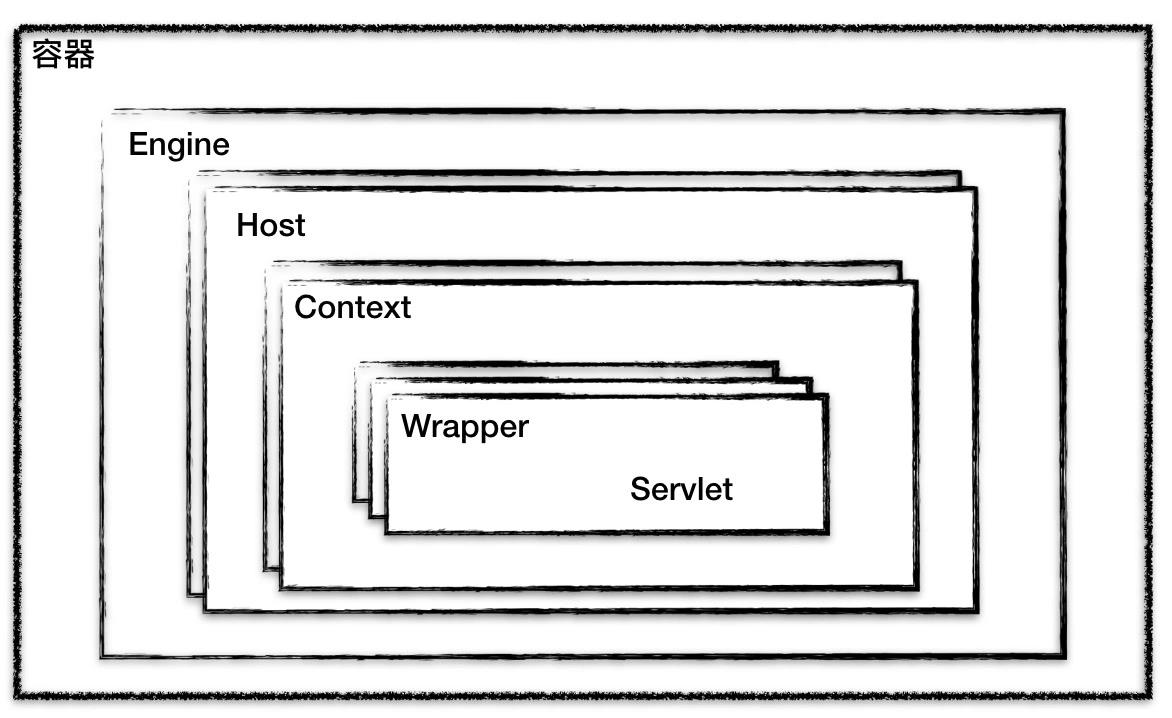
Tomcat通过这种分层,使得Servlet容器具有很好的灵活性。
- Context表示一个Web应用程序
- Wrapper表示一个Servlet,一个Web应用程序中可能会有多个Servlet
- Host代表一个虚拟主机,或一个站点,可以给Tomcat配置多个虚拟主机地址,而一个虚拟主机下可以部署多个Web应用程序
- Engine表示引擎,用来管理多个虚拟站点,一个Service最多只能有一个Engine
观察Tomcat的server.xml配置文件。Tomcat采用了组件化设计,最外层即是Server

这些容器具有父子关系,形成一个树形结构,Tomcat用组合模式来管理这些容器。
所有容器组件都实现Container接口,因此组合模式可以使得用户对
- 单容器对象
最底层的Wrapper - 组合容器对象
上面的Context、Host或者Engine
的使用具有一致性。
Container接口定义:
public interface Container extends Lifecycle {
public void setName(String name);
public Container getParent();
public void setParent(Container container);
public void addChild(Container child);
public void removeChild(Container child);
public Container findChild(String name);
}
请求定位Servlet的过程
搞这么多层次的容器,Tomcat是怎么确定请求是由哪个Wrapper容器里的Servlet来处理的呢?
Tomcat用Mapper组件完成这个任务。
Mapper就是将用户请求的URL定位到一个Servlet
工作原理
Mapper组件保存了Web应用的配置信息:容器组件与访问路径的映射关系,比如
- Host容器里配置的域名
- Context容器里的Web应用路径
- Wrapper容器里Servlet映射的路径
这些配置信息就是一个多层次的Map。
当一个请求到来时,Mapper组件通过解析请求URL里的域名和路径,再到自己保存的Map里去查找,就能定位到一个Servlet。
一个请求URL最后只会定位到一个Wrapper容器,即一个Servlet。
假如有一网购系统,有
- 面向B端管理人员的后台管理系统
- 面向C端用户的在线购物系统
这俩系统跑在同一Tomcat,为隔离它们的访问域名,配置两个虚拟域名:
- manage.shopping.com
管理人员通过该域名访问Tomcat去管理用户和商品,而用户管理和商品管理是两个单独的Web应用 - user.shopping.com
C端用户通过该域名去搜索商品和下订单,搜索功能和订单管理也是两个独立Web应用
这样部署,Tomcat会创建一个Service组件和一个Engine容器组件,在Engine容器下创建两个Host子容器,在每个Host容器下创建两个Context子容器。由于一个Web应用通常有多个Servlet,Tomcat还会在每个Context容器里创建多个Wrapper子容器。每个容器都有对应访问路径
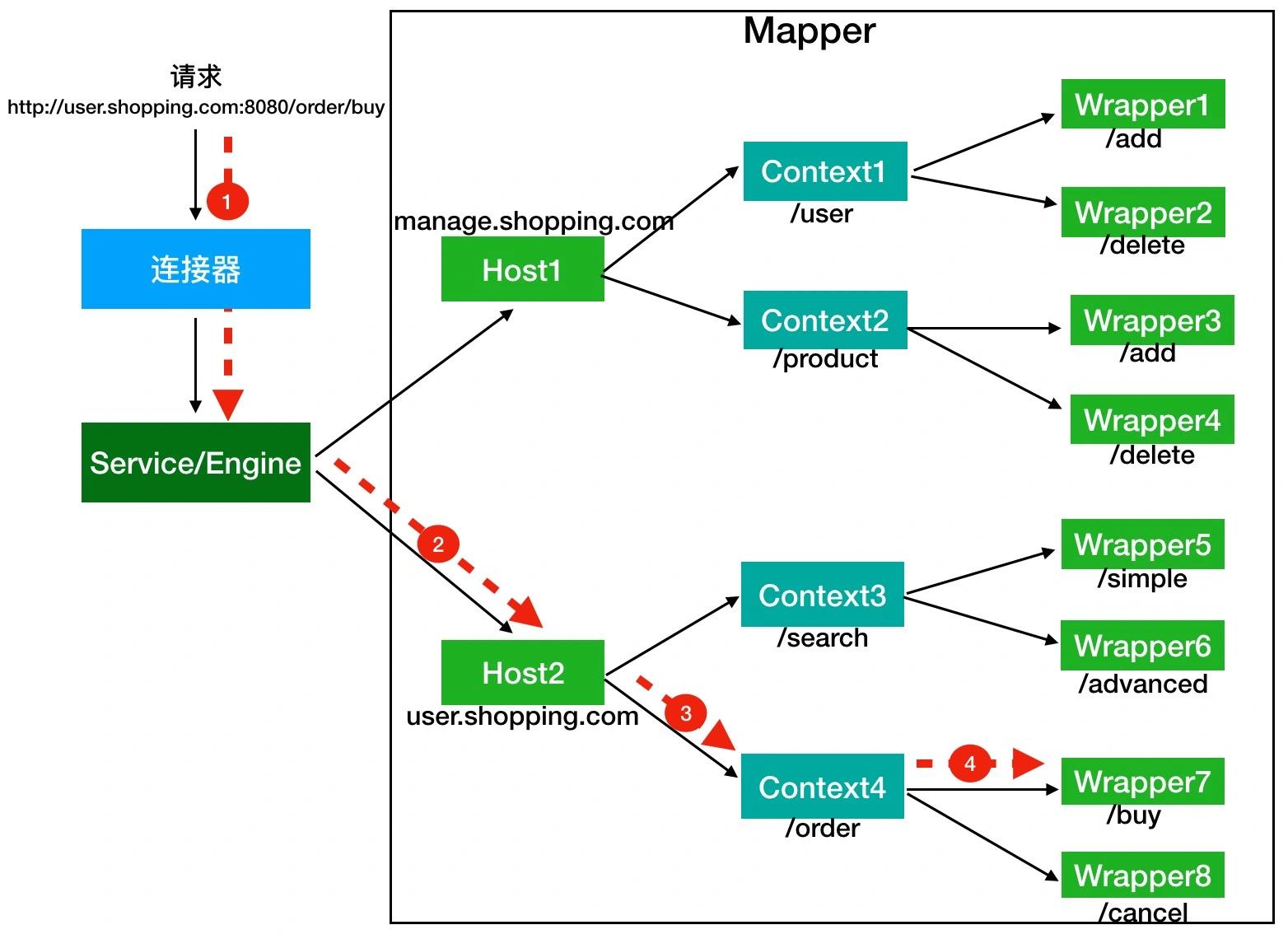
Tomcat如何将URL定位到一个Servlet呢?
- 首先,根据协议和端口号选定Service和Engine
Tomcat的每个连接器都监听不同的端口,比如Tomcat默认的HTTP连接器监听8080端口、默认的AJP连接器监听8009端口。该URL访问8080端口,因此会被HTTP连接器接收,而一个连接器是属于一个Service组件的,这样Service组件就确定了。一个Service组件里除了有多个连接器,还有一个Engine容器,因此Service确定了,Engine也确定了。 - 根据域名选定Host。
Mapper组件通过URL中的域名去查找相应的Host容器,比如user.shopping.com,因此Mapper找到Host2容器。 - 根据URL路径找到Context组件
Host确定以后,Mapper根据URL的路径来匹配相应的Web应用的路径,比如例子中访问的是/order,因此找到了Context4这个Context容器。 - 最后,根据URL路径找到Wrapper(Servlet)
Context确定后,Mapper再根据web.xml中配置的Servlet映射路径来找到具体Wrapper和Servlet。
并非只有Servlet才会去处理请求,查找路径上的父子容器都会对请求做一些处理:
- 连接器中的Adapter会调用容器的Service方法执行Servlet
- 最先拿到请求的是Engine容器,Engine容器对请求做一些处理后,会把请求传给自己子容器Host继续处理,依次类推
- 最后这个请求会传给Wrapper容器,Wrapper会调用最终的Servlet来处理
这个调用过程使用的Pipeline-Valve管道,责任链模式,在一个请求处理的过程中有很多处理者依次对请求进行处理,每个处理者负责做自己相应的处理,处理完之后将再调用下一个处理者继续处理。
Valve表示一个处理点,比如权限认证和记录日志。
public interface Valve {
public Valve getNext();
public void setNext(Valve valve);
public void invoke(Request request, Response response)
}
由于Valve是一个处理点,因此invoke方法就是来处理请求的。
Pipeline接口:
public interface Pipeline extends Contained {
public void addValve(Valve valve);
public Valve getBasic();
public void setBasic(Valve valve);
public Valve getFirst();
}
所以Pipeline中维护了Valve链表,Valve可插入到Pipeline。
Pipeline中没有invoke方法,因为整个调用链的触发是Valve完成自己的处理后,调用getNext.invoke调用下一个Valve。
每个容器都有一个Pipeline对象,只要触发这个Pipeline的第一个Valve,这个容器里Pipeline中的Valve就都会被调用到。但不同容器的Pipeline如何链式触发?
比如Engine中Pipeline需要调用下层容器Host中的Pipeline。
Pipeline有个getBasic方法。这个BasicValve处于Valve链尾,负责调用下层容器的Pipeline里的第一个Valve。
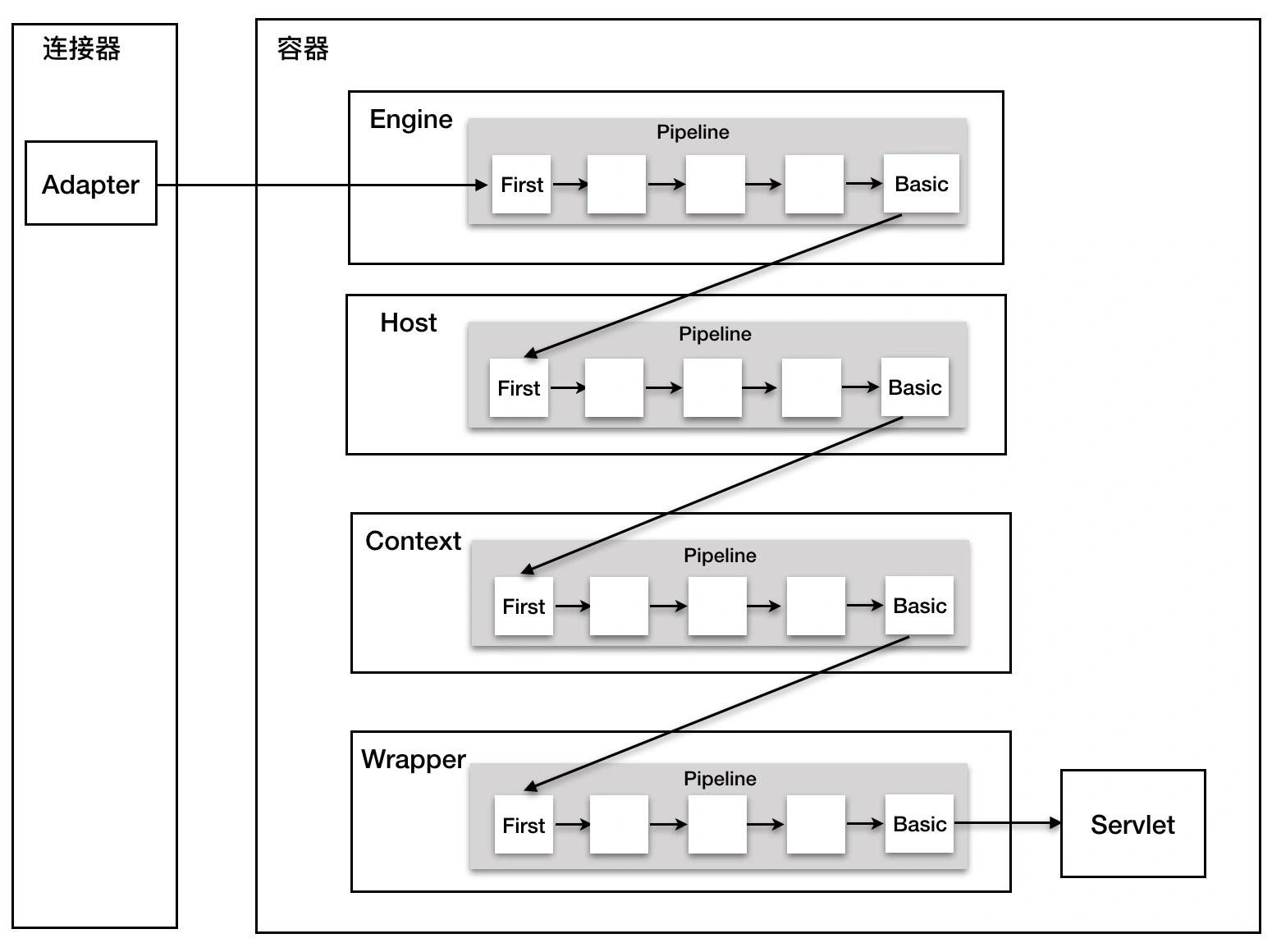
整个调用过程由连接器中的Adapter触发的,它会调用Engine的第一个Valve:
 Wrapper容器的最后一个Valve会创建一个Filter链,并调用doFilter方法,最终会调到Servlet的service方法。
Wrapper容器的最后一个Valve会创建一个Filter链,并调用doFilter方法,最终会调到Servlet的service方法。
Valve和Filter有什么区别呢?
- Valve是Tomcat的私有机制,与Tomcat紧耦合。Servlet API是公有标准,所有Web容器包括Jetty都支持Filter
- Valve工作在Web容器级别,拦截所有应用的请求。Servlet Filter工作在应用级别,只拦截某个Web应用的所有请求。若想做整个Web容器的拦截器,必须使用Valve。
以上是关于Tomcat多层容器的设计的主要内容,如果未能解决你的问题,请参考以下文章
在Tomcat的安装目录下conf目录下的server.xml文件中增加一个xml代码片段,该代码片段中每个属性的含义与用途