linux 正则表达式
Posted issue是fw
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了linux 正则表达式相关的知识,希望对你有一定的参考价值。
grep查找文件中的字符串
grep [-acinv] [--color=auto] '查找字符' filename
-a :将二进制文件以文本文件方式查找数据
-c :计算找到'查找文件'的次数
-i :忽略大小写不同
-n :顺便输出行号
-v :反向选择,显示出没有'查找部分'的那一行
--color=auto :把关键字部分加上颜色输出
这个命令比较简单,随便举个例子
grep -n 'o\\{2\\}' vvv.txt
表示从文件 v v v . t x t \\rm vvv.txt vvv.txt选出有两个 o o o的字符串,打印出来并显示行号
sed工具
sed [-nefr] [操作]
-n :安静模式.一般sed用法中,所有来自stdin的数据都会被列出到屏幕上.
但如果加入-n后,只有被sed特殊处理的那些行才会被列出来
-e :直接在命令行模式进行sed的操作编辑
-f :将sed的操作写在一个文件内,-f filename
-r :sed操作使用扩展正则表达式(默认为基础正则表达式)
-i :直接修改读取的文件内容而不是由屏幕输出
操作说明:
a :新增,a后面可接字符,这些字符会在新的一行出现
c :替换
d :删除
i :插入
p :打印
s :替换,用法为sed 's/被替换的字符/新的字符/g'
删除d
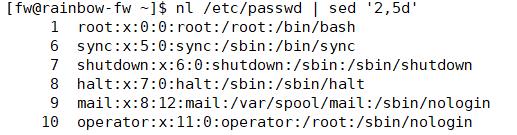
新增a

替换c

打印p
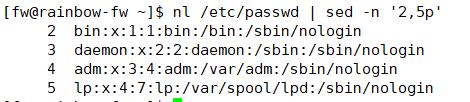
这里需要注意需要加上 − n -n −n选项
替换
sed 's/被替换的字符/新的字符/g'
一个结合 g r e p grep grep和 s e d sed sed的例子
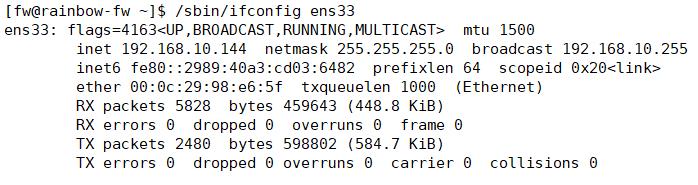
如图,这是这块网卡的信息,现在我们想提取第二行的 n e t m a s k netmask netmask信息怎么做?

大概意思是 g r e p grep grep先提取第二行,然后用 s e d sed sed替换掉前面为空,替换后面为空.
虽然有更简单的办法,不过这里只是为了做个练习emm
cut
-b:仅显示行中指定直接范围的内容;
-c:仅显示行中指定范围的字符;
-d:指定字段的分隔符,默认的字段分隔符为“TAB”,-d后面一般接自定义分割字符
-f:显示指定字段的内容,-f3就是表示展示第三个子段,-f2-4表示展示第2段和第3段和第4段
-n:与“-b”选项连用,不分割多字节字符;
比如
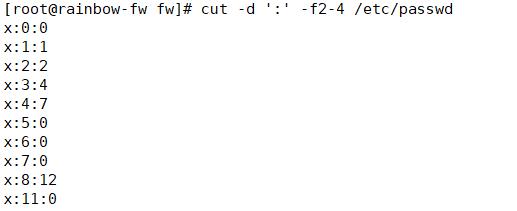
以上是关于linux 正则表达式的主要内容,如果未能解决你的问题,请参考以下文章