大数据集群环境搭建
Posted 赵广陆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据集群环境搭建相关的知识,希望对你有一定的参考价值。
目录
1. 设计一个规模合适的集群
- 目标
- 给定需求和数据规模, 能够设计一个合适的集群
- 步骤
- 资源预估
- 选择服务器
- 为服务器选择服务(角色)
1.1. 资源预估
明确需求
| 需求点 | 量 |
|---|---|
| 标签数量 | 150个 |
| 标签计算任务数量 | 150个 |
| 数据抽取相关任务数量 | 10个 |
| 最少支持并发任务数量 | 5个 |
| 日数据增量 | 260G |
如果一个Spark任务需要计算260G的数据, 需要260G的内存吗?
- 给出一段 Spark 代码
rdd1 = sc.readTextFile(...)
rdd2 = rdd1.map(...)
rdd3 = rdd2.flatMap(...)
- 分析执行策略, 简化的逻辑如下
rdd3 = rdd2.flatMap(...)
rdd3 = rdd1.map(...).flatMap(...)
rdd3 = sc.readTestFile(...).map(...).flatMap(...)
- 按照这个逻辑, 没有必要把所有的数据都加载出来, 再逐个数据集去计算
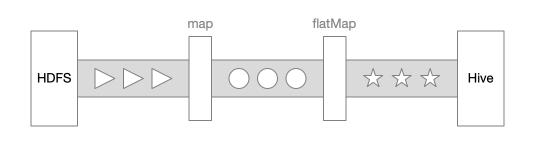
得出结论, 如果计算 260G 的数据, 可能和计算 60G 的数据, 所需要的内存一样, Spark 会逐个取数据, 逐个计算, 计算完成后抛弃, 再取下一条
真的是这样吗? 再看一段代码
- 给出一段Spark代码, 这段代码多了一个Shuffle算子
rdd1 = sc.readTextFile()
rdd2 = rdd1.map(...)
rdd3 = rdd2.flatMap(...)
rdd4 = rdd3.reduceByKey(...)
- 分析执行过程
rdd4 = sc.readTestFile(...).map(...).flatMap(...).reduceByKey(...)
- flatMap 出去的数据可能要汇总一下, 才能流入 reduceByKey

得出结论, 如果计算 260G 的数据, 和计算 60G 的数据, 所需要的内存确实不一样, 有 Shuffle 的情况下要稍微多一些才行
那么, 如何设计集群规模?
- Spark 这样启动
spark-submit \\
--class org.apache.spark.examples.SparkPi \\
--master yarn \\
--deploy-mode cluster \\
--executor-memory 16G \\
--executor-cores 4 \\
--executor-num 10 \\
--total-executor-cores 100 \\
http://path/to/examples.jar \\
1000
executor-memory,executor-cores,executor-num设置的原则executor-memory是executor-cores的 2-4 倍, 取决于 Spark 任务是否有很多计算- 通过
executor-num来控制整个 Job 的内存占用
所以, 可以得到如下表格
| 点 | 量 |
|---|---|
| Executor cores | 4 cores |
| Executor num | 10 |
| Executor memory | 16 G |
| Spark parallelism | 128 |
| Driver memory | 6 G |
| Total cores | exenum * execores = 40 |
| Total memory | exenum * exemem = 160 |
| Pre job needs | 40 core + 160 G |
| Cluster | (40, 160) * 5 * 1.2 = (240,1080) = 240 核心, 1080 G 内存 |
1.2. 选择服务器
假设公司很有钱, 选择在京东上买新的 Dell 服务器, 选择了一个比较好的机器如下
配置如下
| 类型 | 型号 | 容量 | 数量 |
|---|---|---|---|
| CPU | Intel 至强 E5-2690V4 | 14 cores | 2颗 |
| 内存 | Dell ECC DDR4 | 32 G | 4条(可扩展至24条) |
| 硬盘 | Dell SAS 3.5英寸 | 4 TB | 3块(可扩展至8块) |
所以, 单台服务器可以有 128G 内存, 28 cores, 那我们需要的集群数量如下
| 类型 | 数量 |
|---|---|
| Master | 3 |
| Worker | 10 |
| Edge | 2 (可 1U 低配) |
这样的话, 我们集群的总资源量就如下, 可以看到, 已经非常够用了
| 类型 | 大小 |
|---|---|
| CPU | 280 cores |
| 内存 | 1280 G |
| 硬盘 | 120 T |
1.3. 分配集群角色
按照如下方式分配是比较推荐的, 而且一般生产级别的大数据集群, 一定是要 HA 的
| Master 1-2 | Master 3 | Work 1-10 | Gateway | Utility 1 | |
|---|---|---|---|---|---|
| NameNode | ✔️ | ||||
| JournalNode | ✔️ | ✔️ | |||
| FailoverController | ✔️ | ||||
| ResourceManager | ✔️ | ||||
| HMaster | ✔️ | ✔️ | |||
| Zookeeper | ✔️ | ✔️ | |||
| JobHistory | ✔️ | ||||
| SparkHistory | ✔️ | ||||
| DataNode | ✔️ | ||||
| NodeManager | ✔️ | ||||
| HRegionsServer | ✔️ | ||||
| Hue | ✔️ | ||||
| Oozie | ✔️ | ||||
| HiveServer2 | ✔️ | ||||
| Flume | ✔️ | ||||
| 用户画像系统 | ✔️ | ||||
| ClouderaManager | ✔️ | ||||
| ManagementService | ✔️ | ||||
| HiveMetastore | ✔️ |
2. 部署和管理集群的工具
- 目标
- 理解 Hadoop 发型版的历史和作用
- 步骤
- Hadoop 的发展历程
- 部署和管理 Hadoop 集群并不简单
- 三种工具的部署方式
2.1. Hadoop 的发展历程
- 阶段一: 三篇论文
- GFS, 2003, 存储大量数据
- MapReduce, 2004, 使得大量数据可以被计算
- BigTable, 2006, 使得大量数据可以被及时访问
- 阶段二: Hadoop
- DougCutting 在 2002 年创业做了 Lucene, 遇到了性能问题, 无法索引全网的数据
- Google 发布了 GFS 以后, DougCutting 把 Lucene 的底层实现改为类似 GFS 的形式
- 2006 年 DougCutting 投靠了 Yahoo!, 带去了 Lucene, 抽出底层的存储和计算, 变为子项目 Hadoop
- 从 2006 年开始, Yahoo! 把多个业务迁移到 Hadoop 中, 这个时代 Hadoop 才进入高速发展期
所以, Hadoop 是 Yahoo! 一个半内部的项目, 不是商业产品, 其部署和运维都需要专业的团队
2.2. 部署和管理 Hadoop 的集群并不简单
想要部署和运维 Hadoop 的集群有一些难点如下
- Hadoop 是一个大规模的分布式工具, 想要在 4000 个节点上安装无疑非常困难
- 而想要保证几千个节点上的 Hadoop 都正常运行, 无疑更加困难
所以, 第一个发现这个问题的人并不是我们, 而是 Cloudera 的老板
- 2008 年的时候, 一个 Google 的工程师负责和另外一家公司一起合作搞项目, 在部署 Hadoop 的时候, 发现这玩意太难部署了, 于是出来创业, 创办了 Cloudera
- 2011 年的时候, 原 Yahoo! 的 Hadoop 团队独立出来, 创办了一家公司, 叫做 Hortonworks
而 Hortonworks 和 Cloudera 所负责的事情大致如下
- 帮助社区改进 Hadoop 和周边工具, 并提供发行版, 类似于 RedHat 和 Linux 的关系
- 帮助客户部署 Hadoop 集群
- 提供工具帮助客户管理 Hadoop 集群
但是他们的产品又是不同的, 如下
- Hortonworks
- Ambari, 集群管理和监控
- HDP, Hadoop 发行版
- Cloudera
- Cloudera Manager, 简称 CM, 集群管理和监控
- CDH, Hadoop 发行版
所以, 现在如果想要部署一个 Hadoop 的集群, 我们大致有三种选择
- 直接部署 Hadoop 开源版本, 简称 Apache 版本
- 部署 HDP 和 Ambari
- 部署 CDH 和 CM
2.3. 三种工具的部署方式
一 : 想要部署 Apache 版本的工具是最难的
-
要为所有节点配置环境, 例如关闭防火墙之类的
-
要在所有节点中安装 Hadoop, Hive, HBase, Spark 等
二 : 想要部署 CDH 集群, 其实也并不容易, 因为 CM 是主从结构的, 分为如下两个部分
- Cloudera Manager Server, 简称 SCM
- Cloudera Manager Agents, 简称 SCM Agents
所以, 我们需要做如下这件事
- 要为所有节点配置环境, 例如关闭防火墙之类的
- 要为所有节点安装 Agents
- 要在主节点安装 SCM
- 访问 SCM 部署 CDH 集群
三 : 想要部署 HDP 的集群, 理论上比 CM 更难一些
- 要为所有节点配置环境, 例如关闭防火墙之类的
- 要为所有节点安装 Ambari Agents
- 要在主节点安装 Ambari Server
- 访问 Ambari Server 建立集群
四 : 大家有没有发现, 这三种部署方式都有一个事情要做
- 在所有节点执行 xxx 命令
想象一下, 4000 个节点, 你准备怎么处理?
- 使用自动化运维工具, 自动的在所有节点执行相同的操作
例如, 在 4000 个节点中执行同样的 Shell 脚本, 无论怎么做, 其实都挺折腾的, 不是吗?
五 : 那为什么我们不能直接使用 Apache 版本的工具, 使用 Shell 脚本去安装呢?
- 集群部署出来以后, 可能会出错, 如何运维
- 集群部署出来以后, 可能配置文件要修改, 难道再在所有节点修改一遍吗?
- 集群部署出来以后, 我不知道它出错没, 需要监控
而上述这些功能, Ambari 和 SCM 都提供了, 所以我们当时的生产环境中, 运行的是 Cloudera Manager
3. 自动创建虚拟机
- 目标
- 能够通过自动化的方式创建虚拟机
- 步骤
- 什么是 Vagrant
- 安装 Vagrant 和概念介绍
- 使用 Vagrant 构建一个虚拟机集群
3.1. 什么是 Vagrant
从现在就开始要搭建一个测试集群了, 回顾前面的课程, 先来说说虚拟机的痛点
- 安装麻烦
- 建立虚拟机的时候, 我的网段好像写错了, 和别人的 IP 不一样, 总是操作失误
- 虚拟机弄好以后, 还需要安装操作系统, 步骤那么多, 怎么可能不出错呢, 老师你肯定没讲清楚
- WC, 虚拟机终于装好了!! 什么? 还需要安装 Hadoop, 几十个步骤!!!
- 工程和环境分离
- 唉, 又要学习新项目了, 又要折腾环境, 算了, 请一天假放松放松
- 分发困难
- 为啥老师发给我的虚拟机我运行不起来? 这是为什么!!!
- 可能因为你和老师的环境不同. 什么!? 又是环境不同!!!
卒😩
为了解决这些问题, 本项目中为大家引入 Vagrant
- Vagrant 可以通过一个脚本配置虚拟机的参数
- Vagrant 可以帮助我们自动创建一个虚拟机
- Vagrant 可以帮助我们自动安装操作系统
- Vagrant 可以帮助我们配置网络
- Vagrant 可以帮助我们把文件拷贝到创建好的虚拟机上
- Vagrant 可以在创建虚拟机后, 执行我们制定的自动化脚本, 安装服务
- 我们可以使用 Vagrant 的命令登录到虚拟机中
- 我们可以使用 Vagrant 的命令开启或者关闭虚拟机
大家想一下, 如果我们可以通过 Vagrant, 使用一个配置文件来创建虚拟机, 是不是就能做到如下事情
- 创建一个项目, 顺手写一个脚本, 需要运行项目的时候, 让同事执行脚本即可
- 虚拟机中的程序版本变化了, 修改一下脚本, 同事重新运行一下脚本即可同步环境变动
- 再也不用担心虚拟机关闭以后再也打不开, 重新运行一下就好, 也就一分钟
所以, 不仅仅是为了让大家学习, 很多企业中也使用 Vagrant 构建测试环境, 保证每个人的环境一致
3.2. 安装 Vagrant 和概念介绍
安装步骤如下
- 下载 VirtualBox, 因为 VMWare 是收费的, Vagrant 不允许我们使用破解版, 有版权问题
- 安装 VirtualBox
- 下载 Vagrant, 地址是
https://releases.hashicorp.com/vagrant/2.2.7/vagrant_2.2.7_x86_64.msi - 安装 Vagrant
- 考虑到大家网络比较慢, 已经将下载过的 Vagrant 相关的安装包放在了
Files/Setup中
Vagrant 中的概念
作用: 帮助我们管理虚拟机, 自动化的创建虚拟机, 自动化的初始化虚拟机, 提供了命令帮助我们管理虚拟机
- Vagrantfile, 这个文件是虚拟机的配置文件
vagrant up, 使用这个命令, 即可创建一个符合 Vagrantfile 配置的虚拟机- Provision, 当 Vagrant 建立虚拟机后, 会执行通过 Provision 配置的自动化脚本, 自动化的安装服务
Vagrant 初体验, 创建一个虚拟机
步骤
-
编写脚本, 配置虚拟机
- 定义 Vagrant 配置
- 新增一台虚拟机的配置
- 配置虚拟机所使用的操作系统
- 配置网络
- 配置虚拟机的硬件配置
-
执行命令创建虚拟机
-
登入虚拟机, 查看同步的目录
-
编写脚本
Vagrant.configure("2") do |config| config.vm.define "edge" do |config| config.vm.box = 'centos/7' config.disksize.size = '50GB' config.vm.network 'private_network', ip: '192.168.56.101' config.vm.hostname = 'edge' config.vm.provider 'virtualbox' do |vb| vb.gui = false vb.name = 'edge' vb.memory = 2048 vb.cpus = 1 vb.customize ["modifyvm", :id, "--cpuexecutioncap", "50"] end end end -
在脚本所在目录执行命令
# 因为用到了修改磁盘大小的插件, 需要安装 vagrant plugin install vagrant-disksize # 建立虚拟机 vagrant up -
登入虚拟机, 查看同步的目录
# 登录 vagrant ssh edge # 查看同步的目录 cd /vagrant
Vagrant 还有一个很强大的功能, 就是在创建虚拟机完毕时, 执行初始化任务
-
关闭已经创建的虚拟机
vagrant destroy -
编写脚本
Vagrant.configure("2") do |config| config.vm.define "edge" do |config| config.vm.box = 'centos/7' config.disksize.size = '50GB' config.vm.network 'private_network', ip: '192.168.56.101' config.vm.hostname = 'edge' config.vm.provider 'virtualbox' do |vb| vb.gui = false vb.name = 'edge' vb.memory = 2048 vb.cpus = 1 vb.customize ["modifyvm", :id, "--cpuexecutioncap", "50"] end config.vm.provision "shell", path: "script.sh" end end -
编写 Shell 脚本
echo "Hello everyone" -
运行查看
vagrant up
目前, 除了 Shell 的 Provision, Vagrant 还支持 Ansible, Chef, Docker, Puppet 等
3.3. 使用 Vagrant 构建一个虚拟机集群
接下来, 要使用 Vagrant 构建一个集群了, 在开始之前, 根据我们的情况, 要规划一下集群
| 主机名 | 角色 | 配置 |
|---|---|---|
| master01 | Master | 1 cores, 16G -> 6G, 32G -> 8G |
| workder 01 - 02 | Worker | 1 cores, 16G -> 4G, 32G -> 5G |
- 如果只有 8G 内存, 建议去下载 Cloudera quick start vm
- Cloudera CDH 的每一个服务的内存配置, 是按照比例来的
然后, 进行集群搭建
-
编写脚本
Vagrant.configure("2") do |config| config.vm.define "master01" do |master01| master01.vm.box = 'centos/7' master01.disksize.size = '50GB' master01.vm.network 'private_network', ip: '192.168.56.101' master01.vm.hostname = 'master01' master01.vm.provider 'virtualbox' do |vb| vb.gui = false vb.name = 'master01' vb.memory = 6000 vb.cpus = 1 vb.customize ["modifyvm", :id, "--cpuexecutioncap", "50"] end end config.vm.define "worker01" do |worker01| worker01.vm.box = 'centos/7' worker01.disksize.size = '50GB' worker01.vm.network 'private_network', ip: '192.168.56.102' worker01.vm.hostname = 'worker01' worker01.vm.provider 'virtualbox' do |vb| vb.gui = false vb.name = 'worker01' vb.memory = 2048 vb.cpus = 1 vb.customize ["modifyvm", :id, "--cpuexecutioncap", "50"] end end config.vm.define "worker02" do |worker02| worker02.vm.box = 'centos/7' worker02.disksize.size = '50GB' worker02.vm.network 'private_network', ip: '192.168.56.103' worker02.vm.hostname = 'worker02' worker02.vm.provider 'virtualbox' do |vb| vb.gui = false vb.name = 'worker02' vb.memory = 2048 vb.cpus = 1 vb.customize ["modifyvm", :id, "--cpuexecutioncap", "50"] end end config.vm.define "edge" do |edge| edge.vm.box = 'centos/7' edge.disksize.size = '50GB' edge.vm.network 'private_network', ip: '192.168.56.104' edge.vm.hostname = 'edge' edge.vm.provider 'virtualbox' do |vb| vb.gui = false vb.name = 'edge' vb.memory = 1024 vb.cpus = 1 vb.customize ["modifyvm", :id, "--cpuexecutioncap", "50"] end end end -
运行集群
vagrant up
这个时候, 我们已经建立起来了测试集群, 但是有一个问题, 似乎无法在外部登录
- 使用 MobaXterm 使用 SSH 登录虚拟机
- 发现无法登录
原因是, Vagrant 自动创建出来的虚拟机是关闭了 SSH 登录功能的, 只能使用 vagrant ssh 登录, 这是为了保障安全性, 但是测试集群的话, 其实我们还是需要它方便, 解决办法也很简单, 修改 SSH 配置, 再打包一下系统, 让 Vagrant 下次创建的时候使用我们修改过的系统
-
修改 SSH 登录
# 修改文件 /etc/ssh/sshd_config PasswordAuthentication no -
打包
vagrant package -
脚本中使用
Vagrant.configure("2") do |config| config.ssh.password = "vagrant" # 此处使用密码登录 config.vm.define "master01" do |master01| master01.vm.box = './pkgs/package.box' # 此处引用打包好的 box master01.disksize.size = '50GB' master01.vm.network 'private_network', ip: '192.168.56.101' master01.vm.hostname = 'master01' master01.vm.provider 'virtualbox' do |vb| vb.gui = false vb.name = 'master01' vb.memory = 6000 vb.cpus = 1 vb.customize ["modifyvm", :id, "--cpuexecutioncap", "50"] end end config.vm.define "worker01" do |worker01| worker01.vm.box = './pkgs/package.box' worker01.disksize.size = '50GB' worker01.vm.network 'private_network', ip: '192.168.56.102' worker01.vm.hostname = 'worker01' worker01.vm.provider 'virtualbox' do |vb| vb.gui = false vb.name = 'worker01' vb.memory = 2048 vb.cpus = 1 vb.customize ["modifyvm", :id, "--cpuexecutioncap", "50"] end end config.vm.define "worker02" do |worker02| worker02.vm.box = './pkgs/package.box' worker02.disksize.size = '50GB' worker02.vm.network 'private_network', ip: '192.168.56.103' worker02.vm.hostname = 'worker02' worker02.vm.provider 'virtualbox' do |vb| vb.gui = false vb.name = 'worker02' vb.memory = 2048 vb.cpus = 1 vb.customize ["modifyvm", :id, "--cpuexecutioncap", "50"] end end config.vm.define "edge" do |edge| edge.vm.box = './pkgs/package.box' edge.disksize.size = '50GB' edge.vm.network 'private_network', ip: '192.168.56.104' edge.vm.hostname = 'edge' edge.vm.provider 'virtualbox' do |vb| vb.gui = false vb.name = 'edge' vb.memory = 1024 vb.cpus = 1 vb.customize ["modifyvm", :id, "--cpuexecutioncap", "50"] end edge.vm.provision "shell" do |s| s.path = "install_ansible.sh" s.privileged = true end end end
下面再次查看, 即可使用 MobaXterm 登录虚拟机
4. 自动化部署服务 (了解, 运维领域)
- 目标
- 能够通过自动化脚本安装 CM 服务
- 步骤
- 痛点和 Ansible
- 使用 Vagrant 整合 Ansible
- 离线安装 Ansible
4.1. 痛点和 Ansible
好了, 我们现在要开始安装 CM 服务了, 大概有如下步骤
-
配置好每一台机器的系统环境
- 修改主机名
- 关闭防火墙
- 关闭 SELinux
- 安装 JDK
- 安装 mysql
- … 一上午过去了
-
在每一台机器上安装 SCM Agents
- Master 01 上下载 Agents
- Worker 01上下载 Agents
- Worker 02 上下载 Angents
- 配置 Master 01
- 配置 Worker 01
- 配置 Worker 02
- 启动 Maser 01 的 Agents
- … 一小时又过去了, 逐渐恼怒 😡
-
在 Master 01 上安装 SCM
- 创建 Linux 用户, hadoop, hive, yarn, hdfs, oozie 等所有服务都要有一个系统用户
- 创建 MySQL 用户, 大概六七个
- 安装 SCM
- 启动
- 报错
- … 一下午过去了, 老子不学习! 😡😡
-
安装 CDH …
好了, 这些痛点我们都懂, 于是引入 Ansible, Ansible 非常重要, 几乎是运维领域的银弹, 但是如果大家不打算在运维领域发展, 了解即可, Ansible 可以帮助我们做如下事情
- 上述所有步骤, Ansible 可以帮助我们以配置的形式编写
- Ansible 可以帮助我们在多台机器上执行配置文件表示的过程
Ansible 有如下概念
| 名称 | 解释 |
|---|---|
| Playbook | 剧本, 是 Ansible 中的总控, 根配置文件 比如说这次运行 Ansible 的最终任务是搭建好一个 CM 集群, 那我们应该就有一个 Playbook 叫做 cm_playbook.yml |
| Roles | Ansible 任务中的角色 例如为了完成 CM 集群的搭建, 可能要配置操作系统, 那应该就把配置操作系统所需要执行的所有配置都放在一个叫做 system_common 的 Roles 中 |
| Inventory | Ansible 中的服务器地址配置 Ansible 需要在多个主机中执行任务, Inventory 的作用就是告诉 Ansible 主机的地址等信息 |
首先来看看 PlayBook
- name: Create hosts file in locally
hosts: 192.168.56.101
any_errors_fatal: True
become: yes
roles:
- hosts
- name: Set yum locally
hosts: cdh_cluster
any_errors_fatal: True
become: yes
roles:
- yum_locally
-
在
192.168.56.101中配置 hosts 文件 -
在
cdh_cluster所对应的机器中配置本地 Yum 仓库 -
cdh_cluster是一个分组, 这个分组在Inventory中配置 -
hosts和yum_locally就是角色
然后再来看看 Roles yum_locally
- name: Set yum repo locally
yum_repository:
name: itcast-locally
description: Local yum repo
baseurl: http://master01/
failovermethod: priority
file: itcast
priority: 1
gpgcheck: no
enabled: yes
- name: Clean yum meata
command: yum clean all
- 第一个任务是通过 Ansible 提供的 Yum repository 插件, 配置本地 Yum 仓库
- 第二个任务是执行一个命令
yum clean all清理 Yum 缓存
4.2. 使用 Vagrant 整合 Ansible
Ansible 是一个非常知名的自动化运维工具, 不仅仅只是为了搭建测试环境, 在测试环境和正式环境中, 其应用都很广泛, 先来看看在正式环境中该如何使用 Ansible
- 在 13 台机器中, 选择一台作为主控
- 在主控机器中放入 Ansible 脚本
- 执行命令运行 Ansible, Ansible 会在 Playbook 中标示的机器上运行
ansible-playbook --inventory-file=/vagrant/inventory -v /vagrant/playbooks/cdh_cm.yml
明白了如何在正式环境使用 Ansible 以后, 使用 Vagrant 搭建测试环境的时候也可以使用 Ansible 脚本, Vagrant 提供了对应的 Provision
-
编写 Ansible playbook, 文件名为
testing.yml- hosts: worker_servers tasks: debug: msg: "Hello from {{ inventory_hostname }}" -
编写 Inventory, 文件名为
inventory[master_servers] master01 ansible_host=192.168.56.101 ansible_user=vagrant ansible_ssh_pass=vagrant [worker_servers] worker01 ansible_host=192.168.56.102 ansible_user=vagrant ansible_ssh_pass=vagrant worker02 ansible_host=192.168.56.103 ansible_user=vagrant ansible_ssh_pass=vagrant -
编写 Vagrantfile
Vagrant.configure("2") do |config| config.ssh.password = "vagrant" config.vm.define "master01" do |master01| master01.vm.box = './pkgs/package.box' master01.disksize.size = '50GB' master01.vm.network 'private_network', ip: '192.168.56.101' master01.vm.hostname = 'master01' master01.vm.provider 'virtualbox' do |vb| vb.gui = false vb.name = 'master01' vb.memory = 6000 vb.cpus = 1 vb.customize ["modifyvm", :id, "--cpuexecutioncap", "50"] end end config.vm.define "worker01" do |worker01| worker01.vm.box = './pkgs/package.box' worker01.disksize.size = '50GB' worker01.vm.network 'private_network', ip: '192.168.56.102' worker01.vm.hostname = 'worker01' worker01.vm.provider 'virtualbox' do |vb| vb.gui = false vb.name = 'worker01' vb.memory = 2048 vb.cpus = 1 vb.customize ["modifyvm", :id, "--cpuexecutioncap", "50"] end end config.vm.define "worker02" do |worker02| worker02.vm.box = './pkgs/package.box' worker02.disksize.size = '50GB' worker02.vm.network 'private_network', ip: '192.168.56.103' worker02.vm.hostname = 'worker02' worker02.vm.provider 'virtualbox' do |vb| vb.gui = false vb.name = 'w以上是关于大数据集群环境搭建的主要内容,如果未能解决你的问题,请参考以下文章