flask-web 缓存Redis——架构缓存模式淘汰策略雪崩穿透
Posted 胖虎是只mao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了flask-web 缓存Redis——架构缓存模式淘汰策略雪崩穿透相关的知识,希望对你有一定的参考价值。
一、缓存的架构
计算机体系结构中的缓存:
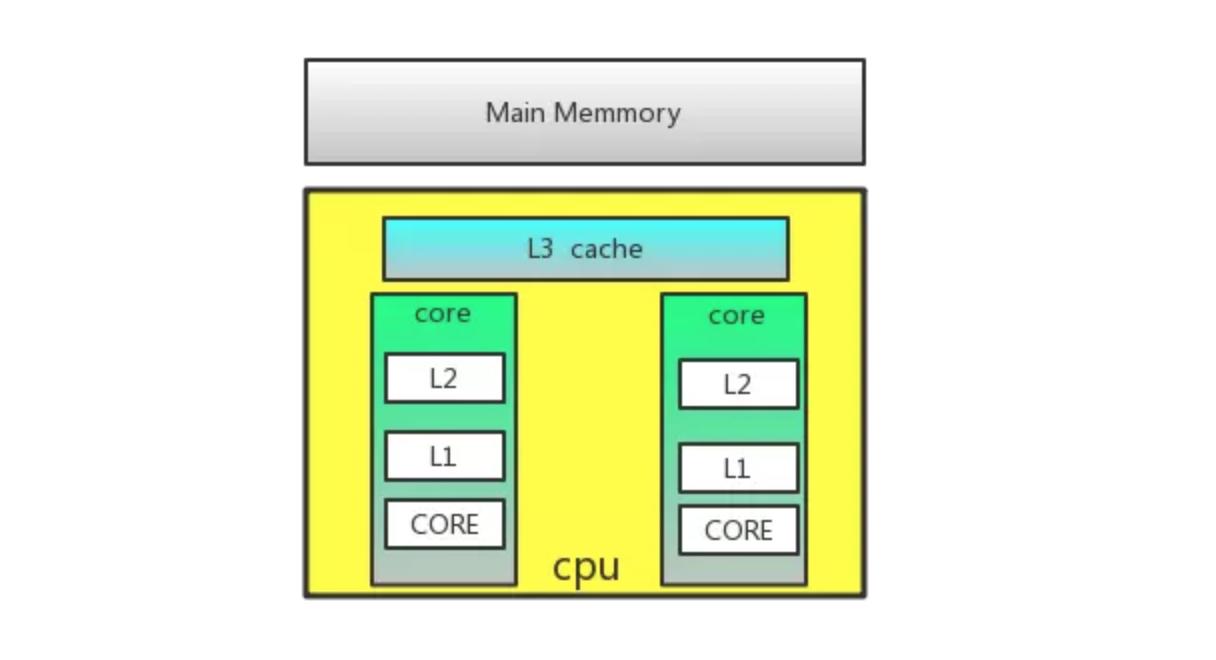
多级缓存
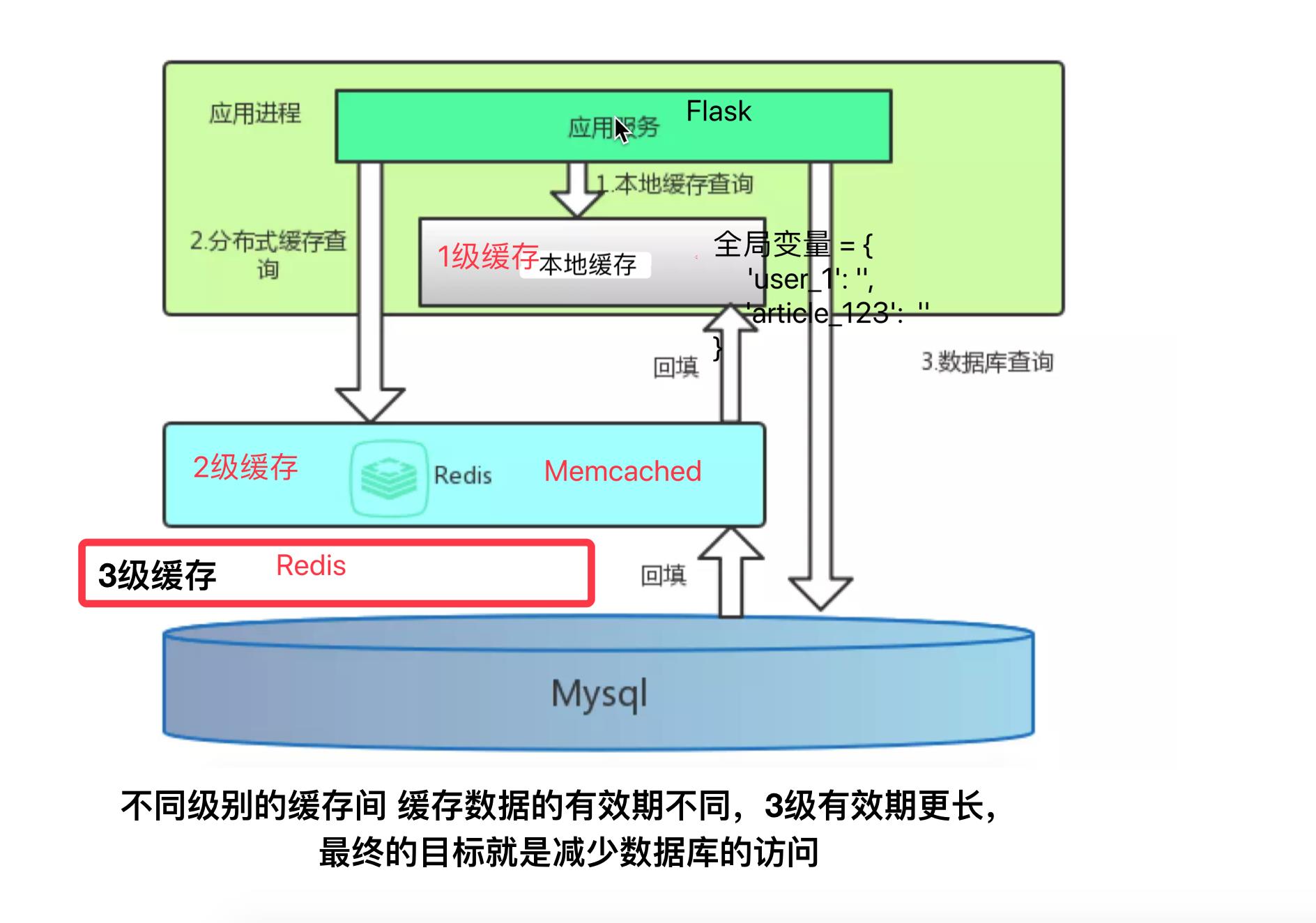
构建本地缓存方法: 使用全局变量,一般适用于保存非常非常高频的数据
项目的方案
- SQLAlchemy起到一定的本地缓存作用
在同一请求中多次相同的查询只查询数据库一次,SQLAlchemy做了本地缓存(类似Django中的Queryset查询结果集),queryset查询集(查询结果集) 其中一个作用就是缓存 (起到了本地缓存的作用) - 使用Redis构建一层缓存,可以用redis cluster 作为一级外部分布式缓存
二、缓存数据
缓存数据的类型
在设计缓存的数据时,可以缓存以下类型的数据
-
一个数值
例如:
- 验证码
- 用户状态
如:user:{user_id}: enable
-
数据库记录,
-
Caching at the object level
以数据库对象的角度考虑, 应用更普遍
例如, 用户的基本信息,一条记录
user = User.query.filter_by(id=1).first() user -> User对象 { 'user_id':1, 'user_name': 'python', 'age': 28, 'introduction': '' } -
Caching at the database query level
以数据库查询的角度考虑,应用场景较特殊,一般仅针对较复杂的查询进行使用,就是有一条联合查询会被经常查询,但是过滤参数每次都不会变化,可以用这种方法
query_result = User.query.join(User.profile).filter_by(id=1).first() -> sql = "select a.user_id, a.user_name, b.gender, b.birthday from tbl_user as a inner join tbl_profile as b on a.user_id=b.user_id where a.user_id=1;" # hash算法 md5 query = md5(sql) # 'fwoifhwoiehfiowy23982f92h929y3209hf209fh2' # redis setex(query, expiry, json.dumps(query_result)) 缓存的数据是数据库查询的结果 第一次 sql = select a.user_id, a.user_name, b.gender, b.birthday from tbl_user as a inner join tbl_profile as b on a.user_id=b.user_id where a.user_id=1; 得到数据库的查询结果 result_data 设置缓存 md5(sql) -> 计算结果 'fdh9ihf92dfhowidfhwoho' 'fdh9ihf92dfhowidfhwoho': result_data 以后使用缓存 生成要执行的sql , md5(sql) -> 'fdh9ihf92dfhowidfhwoho' 从缓存中尝试读取 'fdh9ihf92dfhowidfhwoho' 的缓存记录,如果有,直接使用,如果没有,再查询数据库
-
-
一个视图的响应结果
@route('/articles') @cache(exipry=30*60) def get_articles(): ch = request.args.get('ch') articles = Article.query.all() for article in articles: user = User.query.filter_by(id=article.user_id).first() comment = Comment.query.filter_by(article_id=article.id).all() results = {...} # 格式化输出 return results # redis # '/artciels?ch=1': json.dumps(results) -
一个页面
@route('/articles') @cache(exipry=30*60) def get_articles(): ch = request.args.get('ch') articles = Article.query.all() for article in articles: user = User.query.filter_by(id=article.user_id).first() comment = Comment.query.all() results = {...} return render_template('article_temp', results) # redis # '/artciels?ch=1': html
实际项目怎么使用缓存
Caching at the object level
不以视图作为缓存数据的思考,以数据库中哪些数据被频繁使用访问,以这一点作为思考点,所以选择使用缓存数据库中数据记录的级别来缓存。
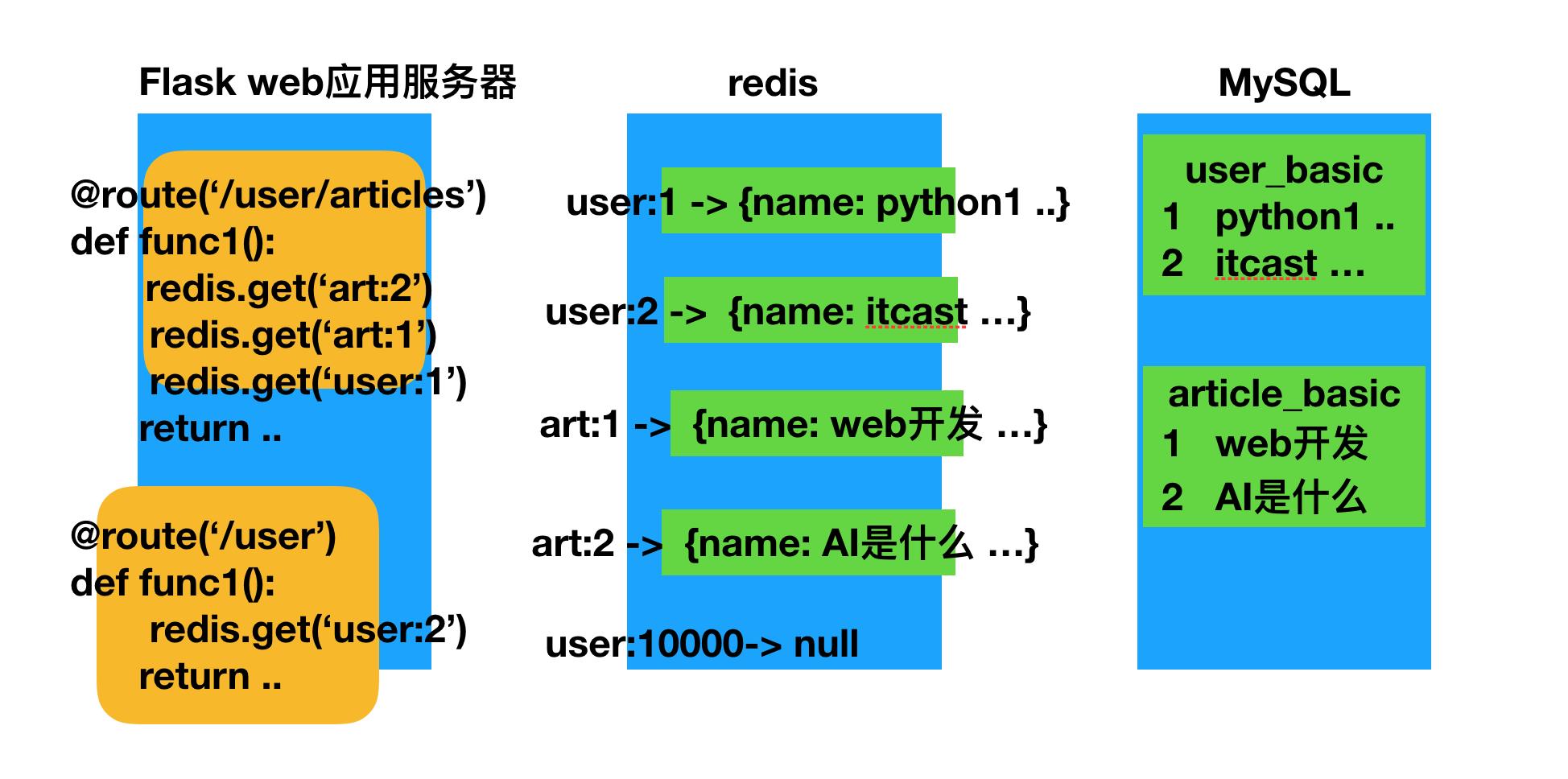
三、缓存数据的保存方式
-
序列化字符串
如:
# 序列化json字符# setex('user:{user_id}:info') setex('user:1:info', expiry, json.dumps(user_dict))-
优点
存储字符串节省空间
-
缺点
序列化有时间开销
更新不方便(一般直接删除)
对于早已的memcached服务器,只有字符串类型可以选择
-
-
Redis的其他数据类型,如hash、set、zset
如
hmset('user:1:info', user_dict)- 优点
读写时不需要序列化转换
可以更新内部数据 - 缺点
相比字符串,采用复合结构存储空间占用大
- 优点
四、缓存有效期与淘汰策略
有效期 TTL (Time to live)
设置有效期的作用:
- 节省空间
- 做到数据弱一致性,有效期失效后,可以保证数据的一致性
Redis的过期策略
过期策略通常有以下三种:
-
定时过期
每个设置过期时间的key都需要创建一个定时器,到过期时间就会立即清除。该策略可以立即清除过期的数据,对内存很友好;但是会占用大量的CPU资源去处理过期的数据,从而影响缓存的响应时间和吞吐量。
setex('a', 300, 'aval') setex('b', 600, 'bval') -
惰性过期
只有当访问一个key时,才会判断该key是否已过期,过期则清除。该策略可以最大化地节省CPU资源,却对内存非常不友好。极端情况可能出现大量的过期key没有再次被访问,从而不会被清除,占用大量内存。
-
定期过期
每隔一定的时间,会扫描一定数量的数据库的expires字典中一定数量的key,并清除其中已过期的key。该策略是前两者的一个折中方案。通过调整定时扫描的时间间隔和每次扫描的限定耗时,可以在不同情况下使得CPU和内存资源达到最优的平衡效果。
expires字典会保存所有设置了过期时间的key的过期时间数据,其中,key是指向键空间中的某个键的指针,value是该键的毫秒精度的UNIX时间戳表示的过期时间。键空间是指该Redis集群中保存的所有键。
Redis中同时使用了惰性过期和定期过期两种过期策略。
Redis过期删除采用的是定期删除,默认是每100ms检测一次,遇到过期的key则进行删除,这里的检测并不是顺序检测,而是随机检测。那这样会不会有漏网之鱼?显然Redis也考虑到了这一点,当我们去读/写一个已经过期的key时,会触发Redis的惰性删除策略,直接回干掉过期的key
为什么不用定时删除策略?
定时删除,用一个定时器来负责监视key,过期则自动删除。虽然内存及时释放,但是十分消耗CPU资源。在大并发请求下,CPU要将时间应用在处理请求,而不是删除key,因此没有采用这一策略.
定期删除+惰性删除是如何工作的呢?
定期删除,redis默认每隔100ms检查,是否有过期的key,有过期key则删除。需要说明的是,redis不是每个100ms将所有的key检查一次,而是随机抽取进行检查(如果每隔100ms,全部key进行检查,redis岂不是卡死)。因此,如果只采用定期删除策略,会导致很多key到时间没有删除。
于是,惰性删除派上用场。也就是说在你获取某个key的时候,redis会检查一下,这个key如果设置了过期时间那么是否过期了?如果过期了此时就会删除。
采用定期删除+惰性删除就没其他问题了么?
不是的,如果定期删除没删除key。然后你也没即时去请求key,也就是说惰性删除也没生效。这样,redis的内存会越来越高。那么就应该采用内存淘汰机制。
五、 缓存淘汰 eviction
Redis自身实现了缓存淘汰
Redis的内存淘汰策略是指在Redis的用于缓存的内存不足时,怎么处理需要新写入且需要申请额外空间的数据。
- noeviction:当内存不足以容纳新写入数据时,新写入操作会报错。(默认)
allkeys-lru:当内存不足以容纳新写入数据时,在键空间中,移除最近最少使用的key。- allkeys-random:当内存不足以容纳新写入数据时,在键空间中,随机移除某个key。
volatile-lru:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,移除最近最少使用的key。(常用)- volatile-random:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,随机移除某个key。
- volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的键空间中,有更早过期时间的key优先移除。
redis 4.x 后支持LFU策略,最少频率使用
-
allkeys-lfu
-
volatile-lfu
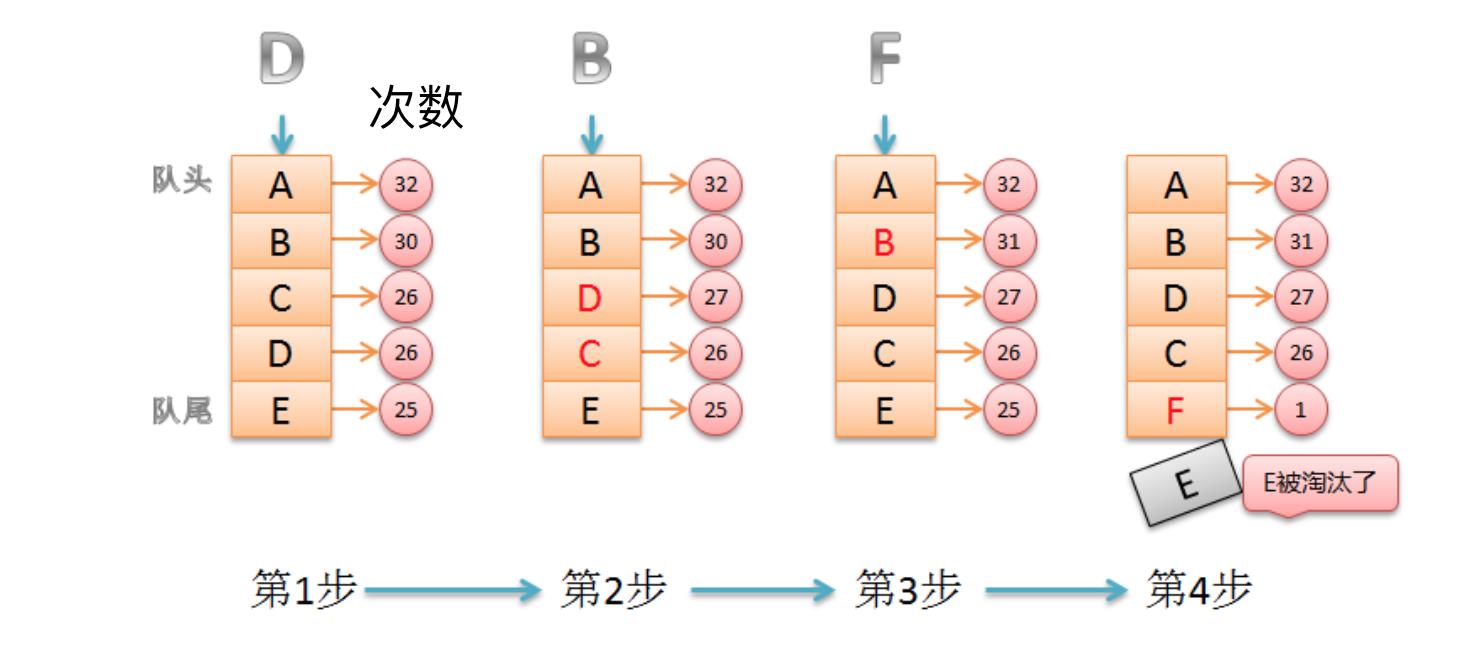
LRU
LRU(Least recently used,最近最少使用) 以操作过的时间选择
LRU算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。
基本思路:
-
新数据插入到列表头部;
-
每当缓存命中(即缓存数据被访问),则将数据移到列表头部;
-
当列表满的时候,将列表尾部的数据丢弃。
[ 最近使用的 {user_4} {user_3} {user_2} {user_1} X ] 最早已使用过的 添加 {user_5} ? [ 最近使用的 {user_5} {user_4} {user_3} {user_2} ] 操作过user_2的数据后 [ 最近使用的 {user_2} {user_5} {user_4} {user_3} ]
LFU
LFU(Least Frequently Used 最近最少使用算法) 以次数 频率来选择
它是基于“如果一个数据在最近一段时间内使用次数很少,那么在将来一段时间内被使用的可能性也很小”的思路。
```python
[
({user_4}, 3000)
({user_1}, 3)
({user_3}, 2680)
({user_2}, 50)
]
添加 {user_5} ?
[ 选择使用累计次数最少的淘汰
({user_4}, 3000)
({user_5}, 1)
({user_3}, 2680)
({user_2}, 50)
]
操作过user_2的数据后
[
({user_4}, 3000)
({user_5}, 1)
({user_3}, 2680)
({user_2}, 51)
]
user_6
```
LFU需要定期衰减。 每过一段时间,所有记录的此时减半
Redis淘汰策略的配置
redis.conf配置文件
-
maxmemory 最大使用内存数量
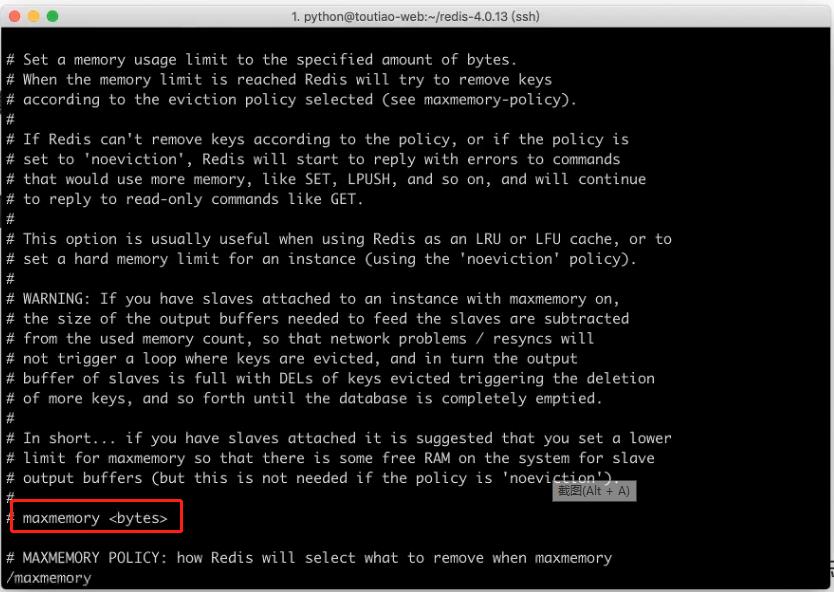
-
maxmemory-policy noeviction 淘汰策略
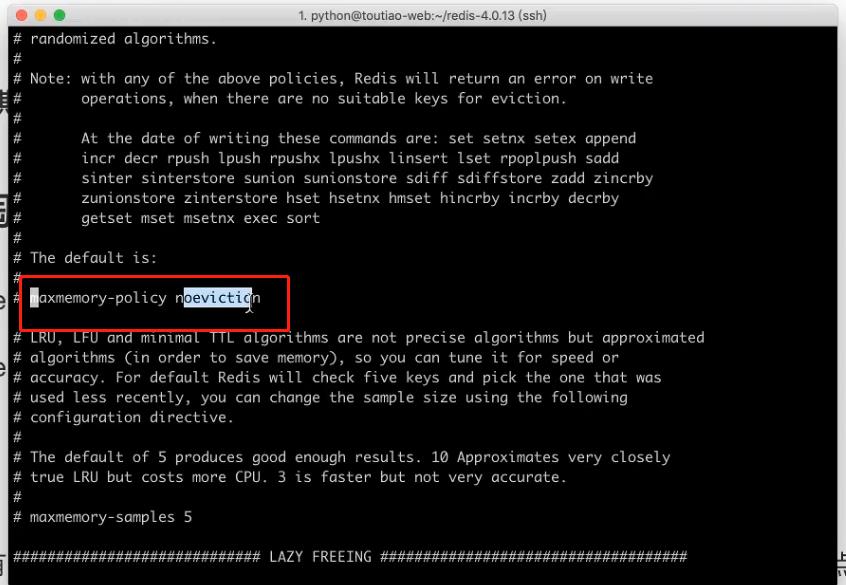
思考题
mysql里有2000w数据,redis中只存20w的数据,如何保证redis中的数据都是热点数据
为redis配置最大使用内存数量,和淘汰策略(LRU、LFU),淘汰后就是热门数据
项目方案
-
缓存数据都设置有效期
-
配置redis,使用
volatile-lru
六 、缓存模式
1) Cache Aside
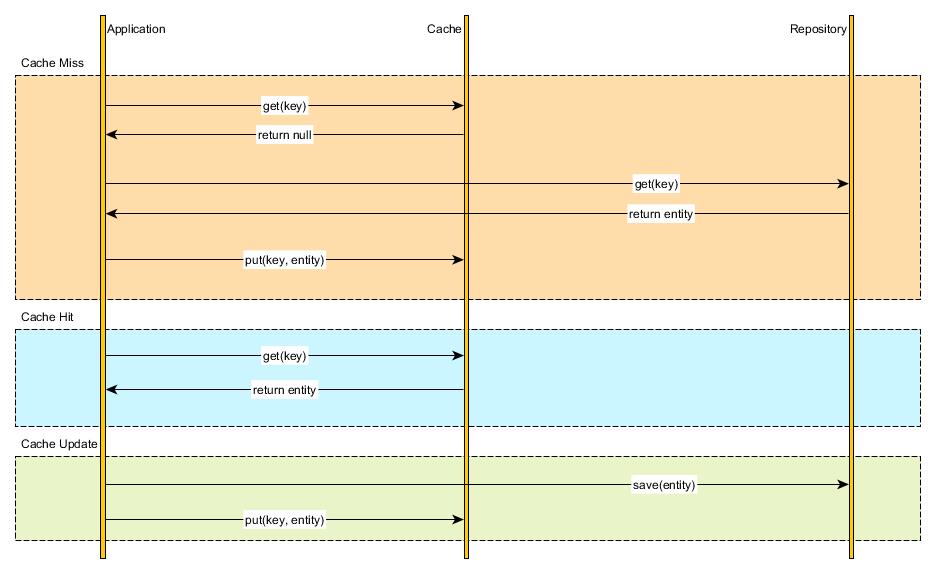
更新方式
-
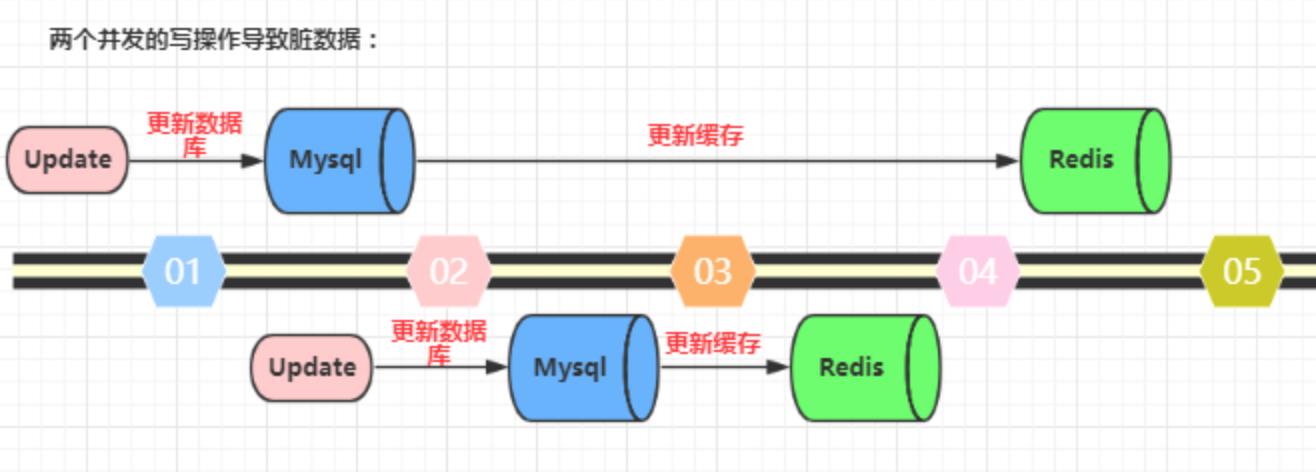
先更新数据库,再更新缓存。这种做法最大的问题就是两个并发的写操作导致脏数据。如下图(以Redis和Mysql为例),两个并发更新操作,可能因为网络的延迟,阻塞。数据库先更新的反而后更新缓存,数据库后更新的反而先更新缓存。这样就会造成数据库和缓存中的数据不一致,应用程序中读取的都是脏数据。
-
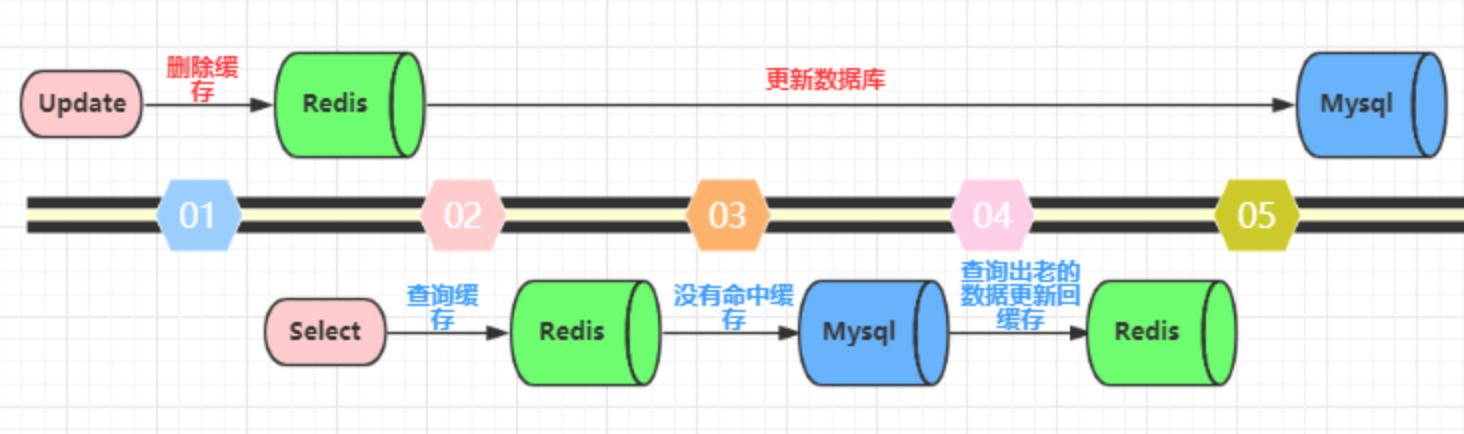
先删除缓存,再更新数据库。这个逻辑是错误的,因为两个并发的读和写操作导致脏数据。如下图(以Redis和Mysql为例)。假设更新操作先删除了缓存,此时正好有一个并发的读操作,没有命中缓存后从数据库中取出老数据并且更新回缓存,这个时候更新操作也完成了数据库更新。此时,数据库和缓存中的数据不一致,应用程序中读取的都是原来的数据(脏数据)。
-
先更新数据库,再删除缓存。这种做法其实不能算是坑,在实际的系统中也推荐使用这种方式。但是这种方式理论上还是可能存在问题。如下图(以Redis和Mysql为例),查询操作没有命中缓存,然后查询出数据库的老数据。此时有一个并发的更新操作,更新操作在读操作之后更新了数据库中的数据并且删除了缓存中的数据。然而读操作将从数据库中读取出的老数据更新回了缓存。这样就会造成数据库和缓存中的数据不一致,应用程序中读取的都是原来的数据(脏数据)。
-
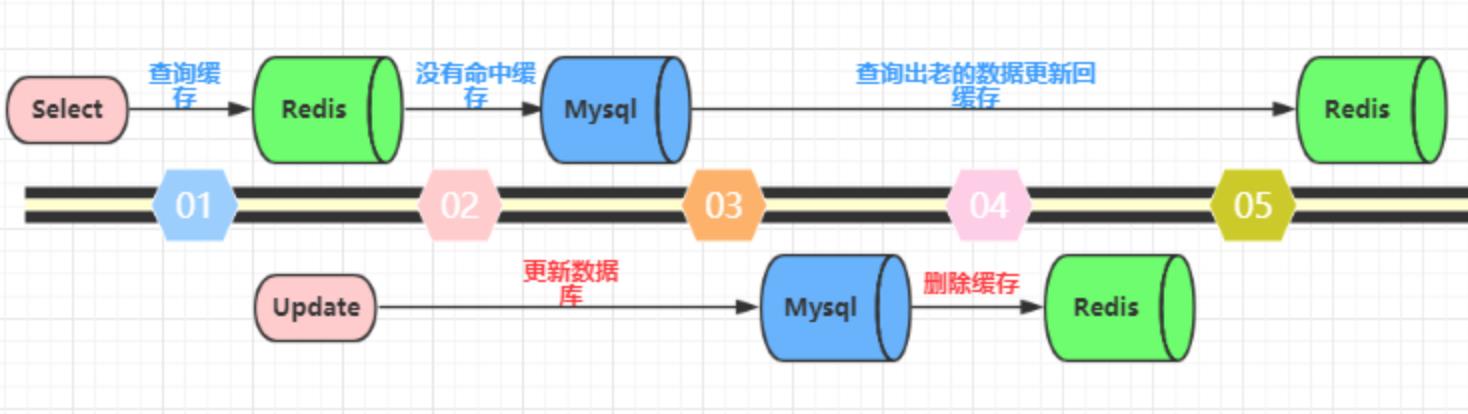
但是,仔细想一想,这种并发的概率极低。因为这个条件需要发生在读缓存时缓存失效,而且有一个并发的写操作。实际上数据库的写操作会比读操作慢得多,而且还要加锁,而读操作必需在写操作前进入数据库操作,又要晚于写操作更新缓存,所有这些条件都具备的概率并不大。但是为了避免这种极端情况造成脏数据所产生的影响,我们还是要为缓存设置过期时间。
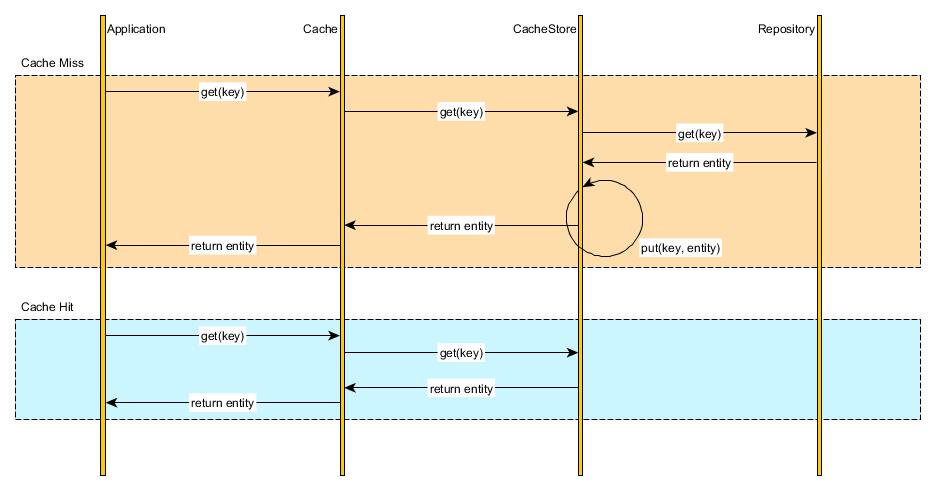
2) Read-through 通读 (读缓存,一般常用读缓存)
多出了一个缓存工具层,关注缓存层(抽象类工具)就可以
3) Write-through 通写
不由应用程序直接将数据写入数据库,而是写入缓存中,由缓存工具层将数据写入数据库
4) Write-behind caching
多条数据积累后,一次性写入数据库中
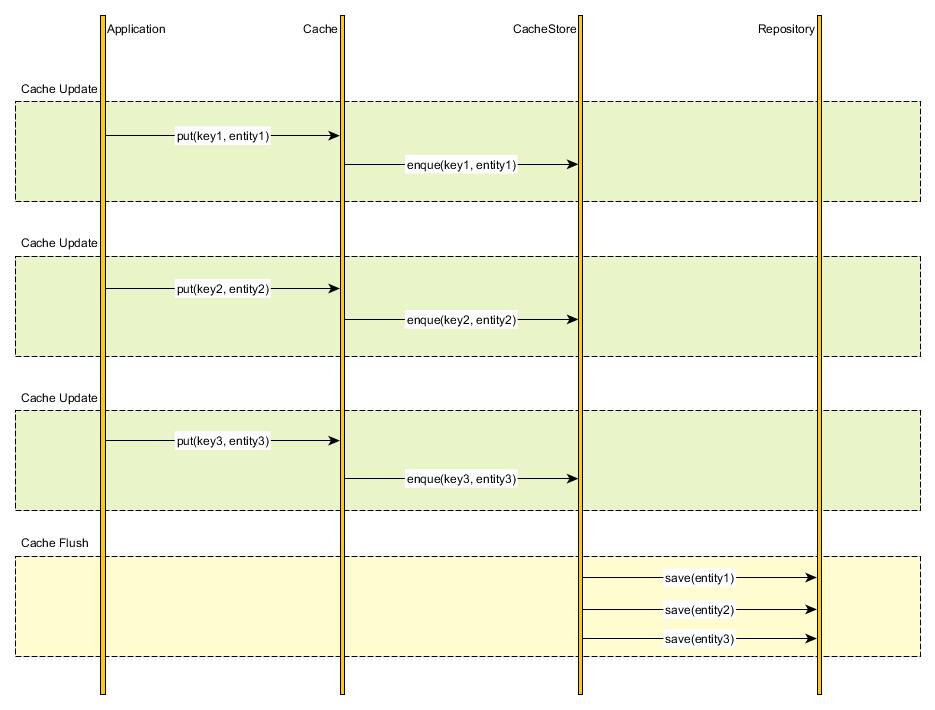
七、实际项目方案
- 使用
Read-throught+Cache aside
构建一层抽象出来的缓存操作层,负责数据库查询和Redis缓存存取,在Flask的视图逻辑中直接操作缓存层工具。 - 更新采用先更新数据库,再删除缓存
八、缓存问题
1 缓存穿透
缓存只是为了缓解数据库压力而添加的一层保护层,当从缓存中查询不到我们需要的数据就要去数据库中查询了。如果被黑客利用,频繁去访问缓存中没有的数据,那么缓存就失去了存在的意义,瞬间所有请求的压力都落在了数据库上,这样会导致数据库连接异常。
解决方案:
- 约定:对于返回为NULL的依然缓存,对于抛出异常的返回不进行缓存,注意不要把抛异常的也给缓存了。采用这种手段的会增加我们缓存的维护成本,需要在插入缓存的时候删除这个空缓存,当然我们可以通过设置较短的超时时间来解决这个问题。(常用)
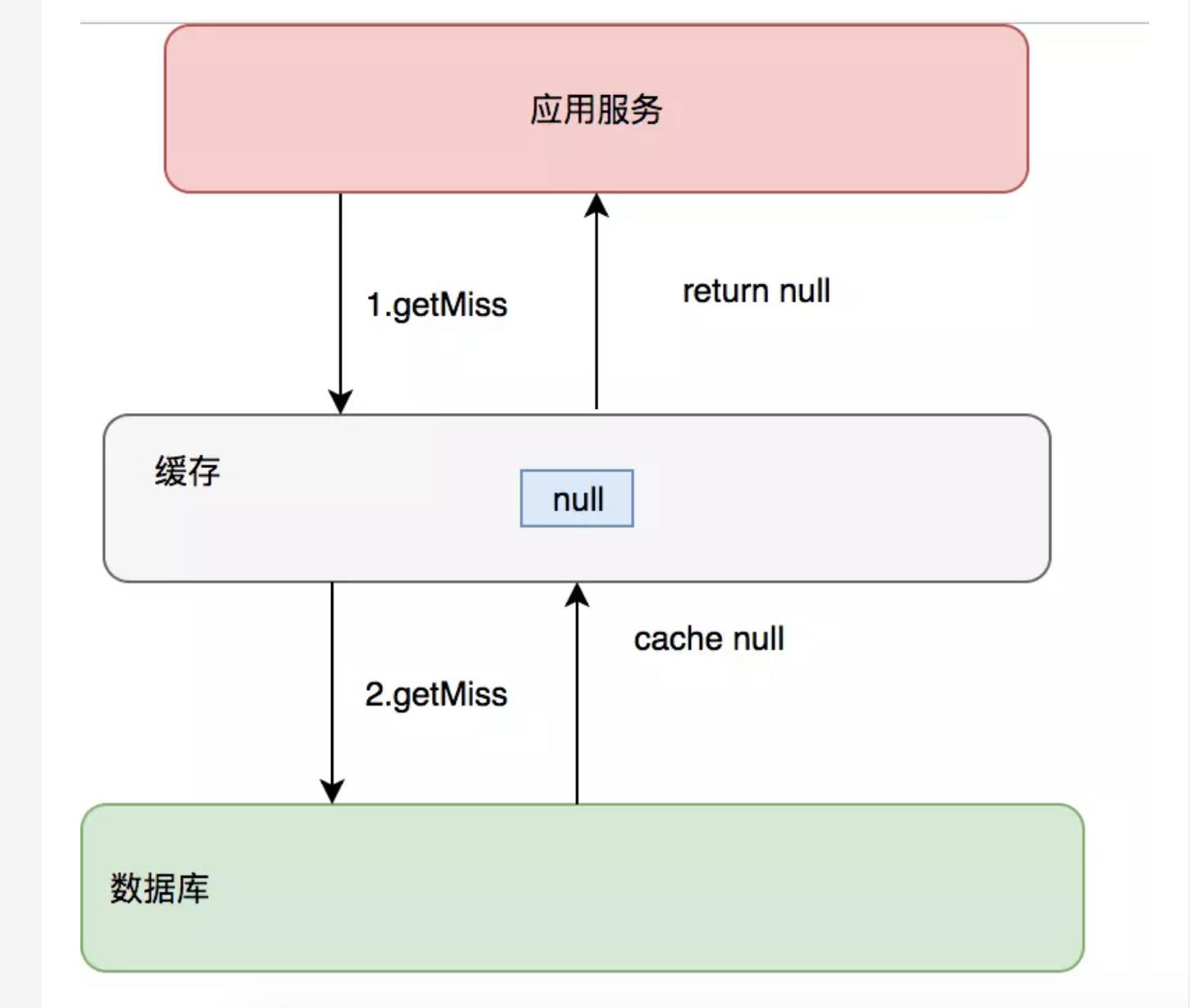
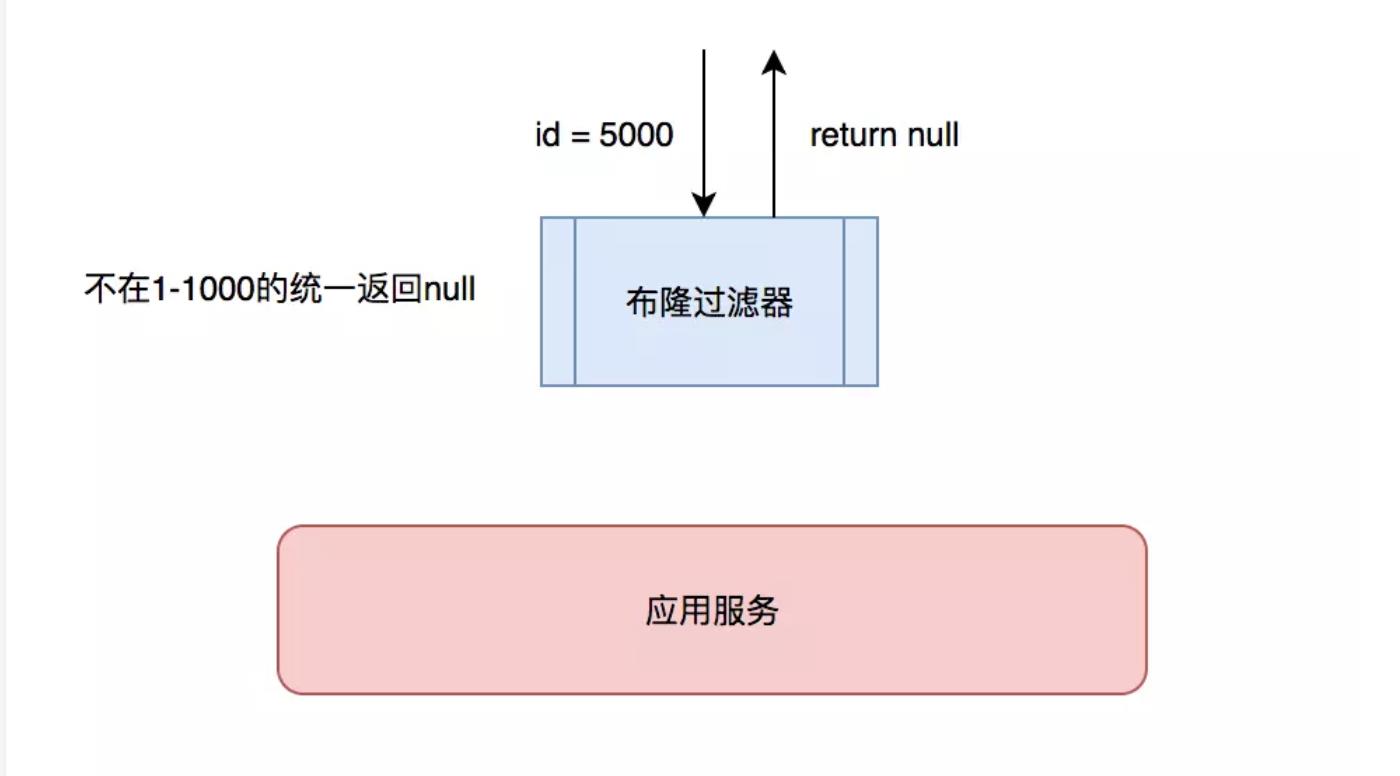
- 制定一些规则过滤一些不可能存在的数据,小数据用BitMap,大数据可以用布隆过滤器,比如你的订单ID 明显是在一个范围1-1000,如果不是1-1000之内的数据那其实可以直接给过滤掉。
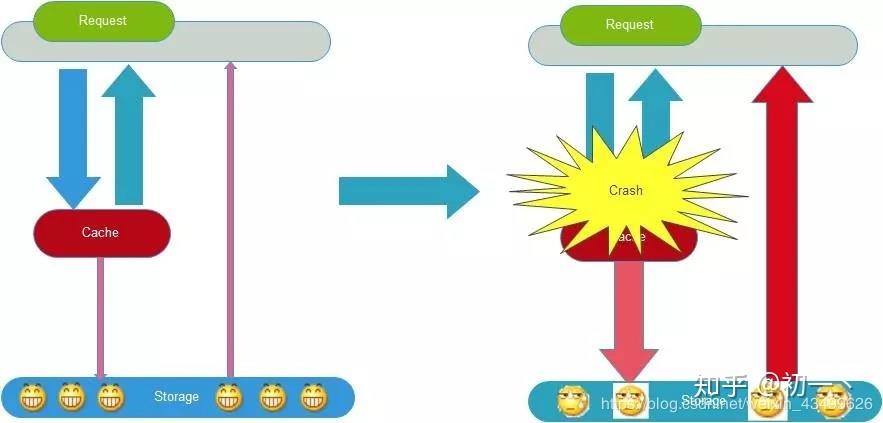
2 缓存雪崩
缓存雪崩是指缓存不可用或者大量缓存由于超时时间相同在同一时间段失效,大量请求直接访问数据库,数据库压力过大导致系统雪崩。
解决方案:
1、给缓存加上一定区间内的随机生效时间,不同的key设置不同的失效时间,避免同一时间集体失效。比如以前是设置10分钟的超时时间,那每个Key都可以随机8-13分钟过期,尽量让不同Key的过期时间不同。( 常用)
2、采用多级缓存,不同级别缓存设置的超时时间不同,及时某个级别缓存都过期,也有其他级别缓存兜底。
3、利用加锁或者队列方式避免过多请求同时对服务器进行读写操作。
以上是关于flask-web 缓存Redis——架构缓存模式淘汰策略雪崩穿透的主要内容,如果未能解决你的问题,请参考以下文章