MyCat学习第一天之MyCat简介,配置文件详解,分片操作,分片规则
Posted 活跃的咸鱼
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MyCat学习第一天之MyCat简介,配置文件详解,分片操作,分片规则相关的知识,希望对你有一定的参考价值。
1. MyCat简介
1.1 MyCat是什么?
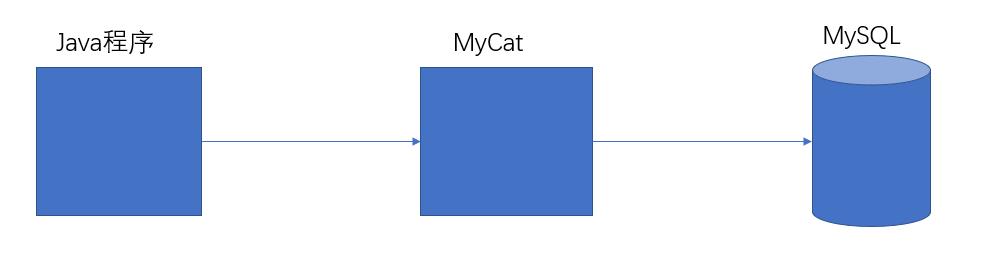
Mycat 是数据库中间件:连接java应用程序和数据库。
中间件:是一类连接软件组件和应用的计算机软件,以便于软件各部件之间的沟通。
没有MyCat之前java程序直接连接mysql数据库,耦合性高。

有MyCat之后java程序只用连接MyCat与数据库进行了解耦
1.2 为什么会出现MyCat?
随着互联网的发展,数据的量级也是成指数式的增长,从GB到TB到PB。对数据的各种操作也是愈加的困难,传统的关系性数据库已经无法满足快速查询与插入数据的需求,这个时候NoSQL的出现暂时解决了这一危机。它通过降低数据的安全性,减少对事务的支持,减少对复杂查询的支持,来获取性能上的提升。
但是,在有些场合NoSQL一些折衷是无法满足使用场景的,就比如有些使用场景是绝对要有事务与安全指标的。这个时候NoSQL肯定是无法满足的,所以还是需要使用关系性数据库。
如何使用关系型数据库解决海量存储的问题呢?此时就需要做数据库集群,为了提高查询性能将一个数据库的数据分散到不同的数据库中存储,为应对此问题就出现了——MyCat 。
MyCAT的目标是:低成本的将现有的单机数据库和应用平滑迁移到"云"端,解决海量数据存储和业务规模迅速增长情况下的数据存储和访问的瓶颈问题 。
1.3 MyCat 历史
1). Mycat 背后是阿里曾经开源的知名产品——Cobar。Cobar 的核心功能和优势是 MySQL 数据库分片,此产品曾经广为流传,据说最早的发起者对 Mysql 很精通,后来从阿里跳槽了,阿里随后开源了 Cobar,并维持到 2013 年年初,然后,就没有然后了。 Cobar 的思路和实现路径的确不错。基于 Java 开发的,实现了 MySQL 公开的二进制传输协议,巧妙地将自己伪装成一个 MySQLServer,目前市面上绝大多数 MySQL 客户端工具和应用都能兼容。
2). Mycat 是基于 cobar 演变而来,相对于cobar来说 , 有两个显著优势 : ①. 对 cobar的代码进行了彻底的重构,Mycat在I/O方面进行了重大改进,将原来的BIO改成了NIO, 并发量有大幅提高 ; ②. 增加了对Order By、Group By、limit等聚合功能的支持,同时兼容绝大多数数据库成为通用的数据库中间件 。
3). 简单的说,MyCAT就是:一个新颖的数据库中间件产品支持mysql集群,或者 mariadbcluster,提供高可用性数据分片集群。你可以像使用mysql一样使用 mycat 。对于开发人员来说根本感觉不到mycat的存在
1.4 MyCat的优势
数据库中间件产品有哪些?
- Cobar:属于阿里B2B事业群,始于2008年,在阿里服役3年多,接管3000+个MySQL数据库的schema,集群日处理在线SQL请求50亿次以上。由于Cobar发起人的离职,Cobar停止维护。
- Mycat:是开源社区在阿里cobar基础上进行二次开发,解决了cobar存在的问题,并且加入了许多新
的功能在其中。青出于蓝而胜于蓝。 - OneProxy:基于MySQL官方的proxy思想利用c进行开发的,OneProxy是一款商业收费的中间件。舍
弃了一些功能,专注在性能和稳定性上。 - kingshard:由小团队用go语言开发,还需要发展,需要不断完善。
- Vitess:是Youtube生产在使用,架构很复杂。不支持MySQL原生协议,使用需要大量改造成本。
- Atlas:是360团队基于mysql proxy改写,功能还需完善,高并发下不稳定。
- MaxScale:是mariadb(MySQL原作者维护的一个版本) 研发的中间件
- MySQLRoute:是MySQL官方Oracle公司发布的中间件
相比其他数据库中间件MyCat的优势:
-
性能可靠稳定:基于阿里开源的Cobar产品而研发,Cobar的稳定性、可靠性、优秀的架构和性能以及众多成熟的使用案例使得MYCAT一开始就拥有一个很好的起点,站在巨人的肩膀上,我们能看到更远。业界优秀的开源项目和创新思路被广泛融入到MYCAT的基因中,使得MYCAT在很多方面都领先于目前其他一些同类的开源项目,甚至超越某些商业产品。
-
强大的技术团队:MyCat 现在由一支强大的技术团队维护 , 吸引和聚集了一大批业内大数据和云计算方面的资深工程师、架构师、DBA,优秀的团队保障了MyCat的稳定高效运行。而且MyCat不依托于任何商业公司,而且得到大批开源爱好者的支持。
-
体系完善:MyCat已经形成了一系列的周边产品,比较有名的是 Mycat-web、Mycat-NIO、Mycat-Balance等,已经形成了一个比较完整的解决方案,而不仅仅是一个中间件。
-
社区活跃
1.5 MyCat的使用场景
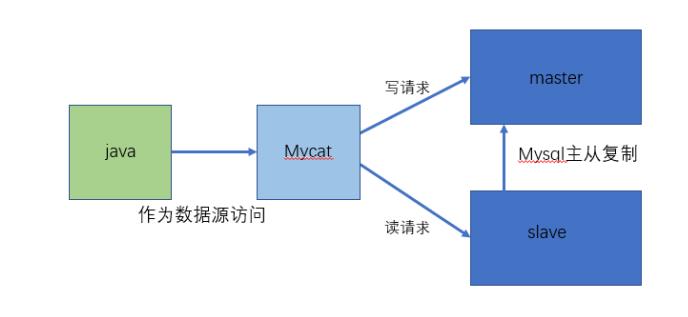
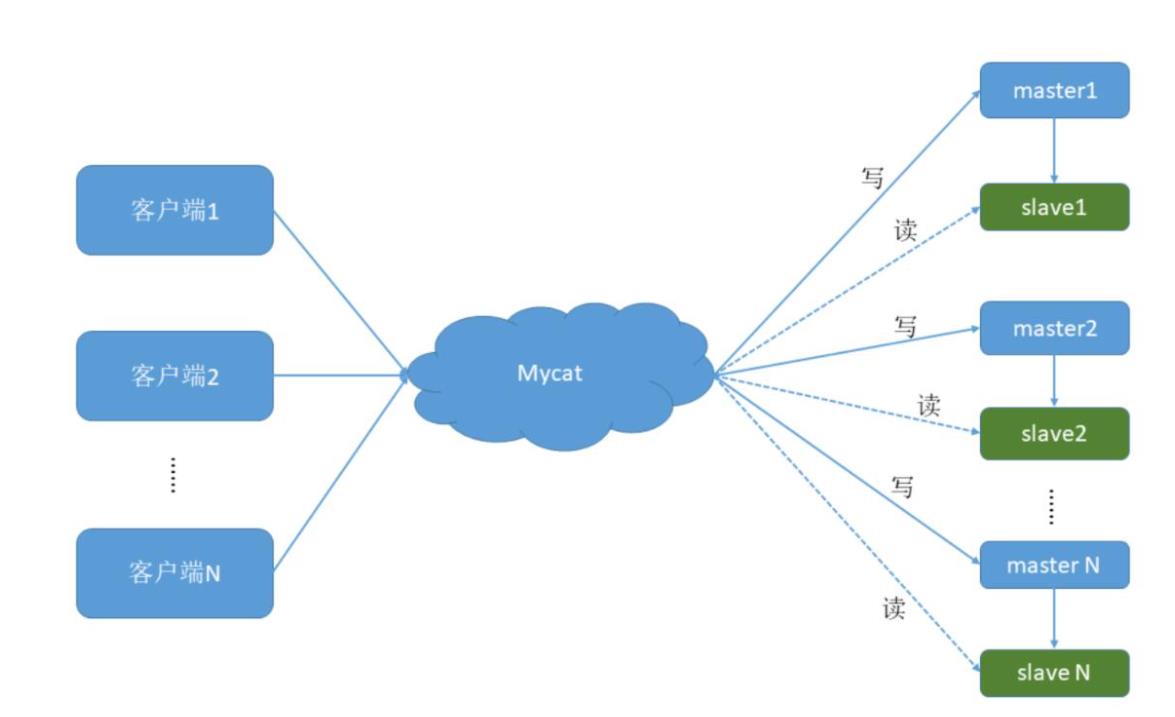
1). 高可用性与MySQL读写分离
高可用:利用MyCat可以轻松实现热备份,当一台服务器停机时,可以由集群中的另一台服务器自动接管业务,无需人工干预,从而保证高可用。
读写分离:通过MySQL数据库的binlog日志完成主从复制,并可以通过MyCat轻松实现读写分离,实现insert、update、delete走主库,而在select时走从库,从而缓解单台服务器的访问压力。
2). 业务数据分级存储保障
企业的数据量总是无休止的增长,这些数据的格式不一样,访问效率不一样,重要性也不一样。可以针对不同级别的数据,采用不同的存储设备,通过分级存储管理软件实现数据客体在存储设备之间自动迁移及自动访问切换。
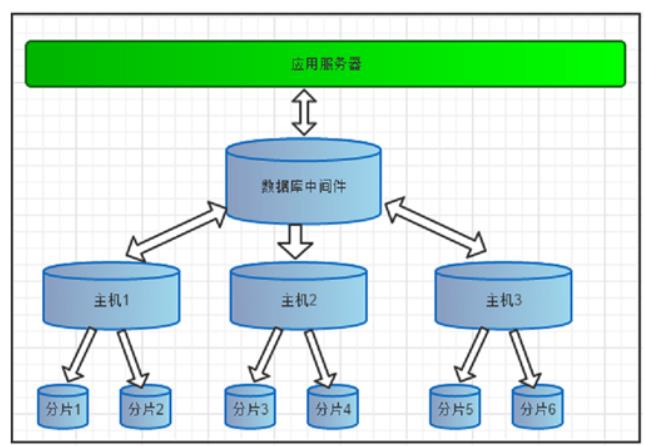
3). 大表水平拆分,集群并行计算
数据切分是MyCat的核心功能,是指通过某种特定的条件,将存放在同一个数据库的数据,分散存储在多个数据库中,以达到分散单台设备负载的效果。当数据库量超过800万行且需要做分片时,就可以考虑使用MyCat实现数据切分。
垂直拆分(分库)、水平拆分(分表)、垂直+水平拆分(分库分表)
4). 数据库路由器
MyCat基于MySQL实例的连接池复用机制,可以让每个应用最大程度共享一个MySQL实例的所有连接池,让数据库的并发访问能力大大提升。
5). 整合多种数据源
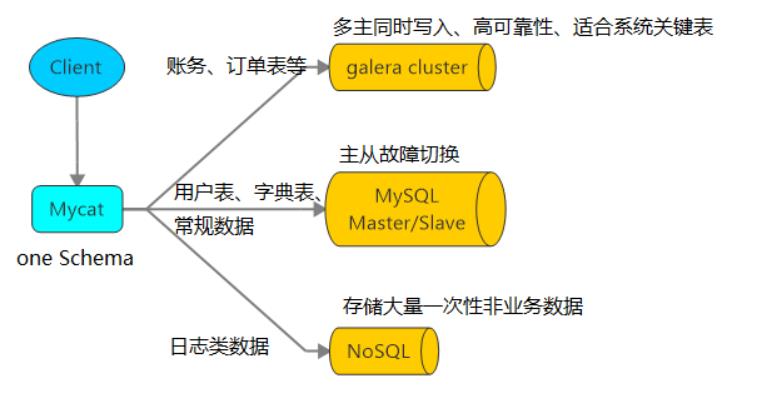
当一个项目中使用了多个数据库(Oracle,MySQL,SQL Server,PostgreSQL),并配置了多个数据源,操作起来就比较烦锁,这时就可以使用MyCat进行整合,最终我们的应用程序只需要访问一个数据源即可。
2. MyCat入门案例
在开始入门案例前先来了解一下MyCat的相关核心概念。
2.1 MyCat核心概念
分片
简单来说,就是指通过某种特定的条件,将我们存放在同一个数据库中的数据分散存放到多个数据库(主机)上面,以达到分散单台设备负载的效果。
数据的切分(Sharding)
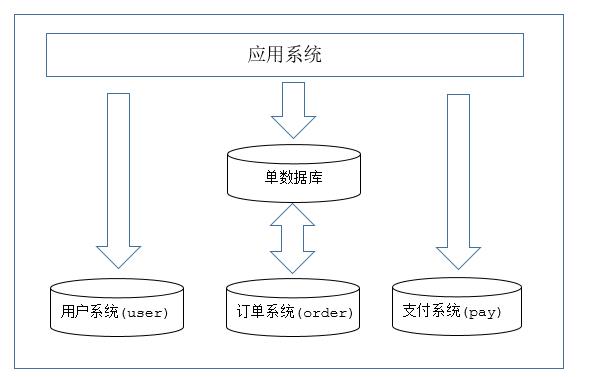
将同一个数据库中的数据切分到多个数据库,根据其切分规则的类型,可以分为两种切分模式。
- 一种是按照不同类型的表比如订单相关的表,用户相关的表,支付相关的表(或者Schema)来切分到不同的数据库(主机)中,这种切分可以称之为数据的垂直(纵向)切分。
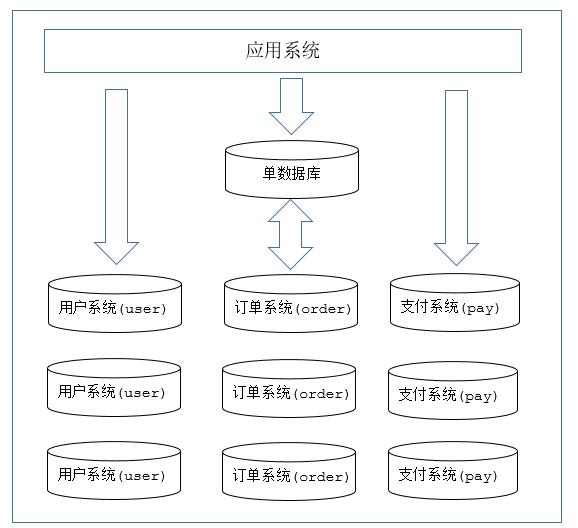
2.另外一种则是根据表中的数据的逻辑关系,当订单相关的表,用户相关的表,支付相关的表中的数据量过大我们可以考虑将同一个表中的数据按照某种条件拆分到多台数据库(主机)上面,这种切分称之为数据的水平(横向)切分。每个主机上储存相同的表结构但是储存的数据不同。
MyCat 分片策略
MyCat配置文件中可以配置一个逻辑库和几个逻辑表,每一个表又对应多个数据节点,而又由数据节点关联不同真实存在的数据库。
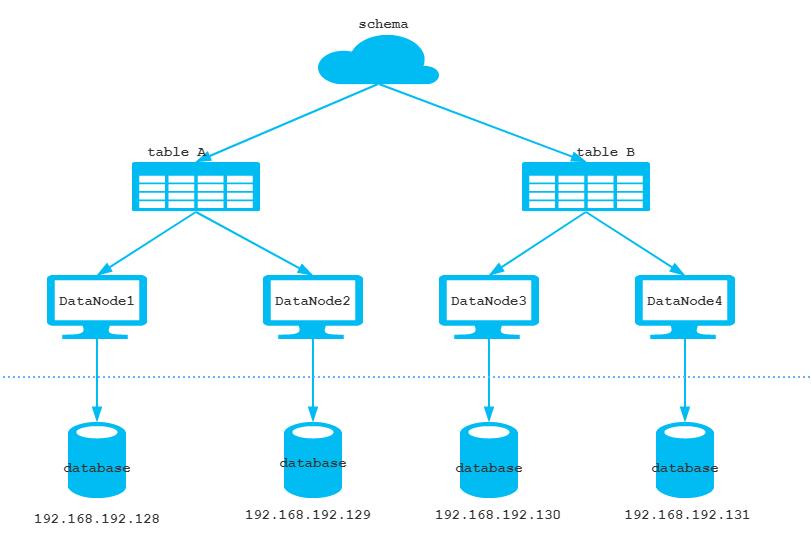
虚线以上的schema,table,datanode,都是逻辑结构, 虚线以下的数据库才是真实存在的物理结构
逻辑库(schema)
MyCat是一个数据库中间件,通常对实际应用来说,并不需要知道中间件的存在,业务开发人员只需要知道数据库的概念,所以数据库中间件可以被看做是一个或多个数据库集群构成的逻辑库。
逻辑表(table)
既然有逻辑库,那么就会有逻辑表,分布式数据库中,对应用来说,读写数据的表就是逻辑表。逻辑表,可以是数据切分后,分布在一个或多个分片库中,也可以不做数据切分,不分片,只有一个表构成。逻辑表可以分为以下几种表:
- 分片表:指那些原有的很大数据的表,需要切分到多个数据库的表,这样,每个分片都有一部分数据,所有分片构成了完整的数据。 总而言之就是需要进行分片的表。
- 非分片表:一个数据库中并不是所有的表都很大,某些表是可以不用进行切分的,非分片是相对分片表来说的,就是那些不需要进行数据切分的表。
- ER表:关系型数据库是基于实体关系模型(Entity Relationship Model)的, MyCat中的ER表便来源于此。 MyCat提出了基于ER关系的数据分片策略 , 子表的记录与其所关联的父表的记录存放在同一个数据分片中, 通过表分组(Table Group)保证数据关联查询不会跨库操作。
- 全局表:在一个大型的项目中,会存在一部分字典表(码表) , 在其中存储的是项目中的一些基础的数据 , 而这些基础的数据 , 数据量都不大 , 在各个业务表中可能都存在关联 。当业务表由于数据量大而分片后 , 业务表与附属的数据字典表之间的关联查询就变成了比较棘手的问题 , 在MyCat中可以通过数据冗余来解决这类表的关联查询 , 即所有分片都复制这一份数据(数据字典表),因此可以把这些冗余数据的表定义为全局表。
分片节点(dataNode)
数据切分后,一个大表被分到不同的分片数据库上面,每个表分片所在的数据库就是分片节点(dataNode)。
节点主机(dataHost)
数据切分后,每个分片节点(dataNode)不一定都会独占一台机器,同一机器上面可以有多个分片数据库,这样一个或多个分片节点(dataNode)所在的机器就是节点主机(dataHost),为了规避单节点主机并发数限制,尽量将读写压力高的分片节点(dataNode)均衡的放在不同的节点主机(dataHost)。
分片规则(rule)
前面讲了数据切分,一个大表被分成若干个分片表,就需要一定的规则,这样按照某种业务规则把数据分到某个分片的规则就是分片规则,数据切分选择合适的分片规则非常重要,将极大的避免后续数据处理的难度。
2.2 环境搭建
A. MySQL安装
1.先检查一下是否有安装过mysql
rpm -qa|grep mariadb
如果存在一下内容

请先卸载:
rpm -e --nodeps mariadb-libs
2 .做完上面检查工作具体的安装步骤可以参考这篇文章:Linux安装MySQL5.7只要按照他的步骤都可以安装完成。
B. JDK安装:
Mycat是采用java语言开发的开源的数据库中间件所以需要安装JDK
jdk下载:
https://pan.baidu.com/s/1SPfvpXZRS8A5NoRN8LhM8w 提取码:neiy
下载完通过xftp上传到指定文件目录下
解压:
tar -xzvf jdk-8u131-linux-x64.tar.gz
配置jdk环境变量
export JAVA_HOME=/usr/local/jdk1.8.0_181 #jdk安装目录
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib:$CLASSPATH
export JAVA_PATH=${JAVA_HOME}/bin:${JRE_HOME}/bin
export PATH=$PATH:${JAVA_PATH}
通过命令source /etc/profile让profile文件立即生效
source /etc/profile
检测jdk安装是否成功
java -version
C. MyCat安装
下载完成后上传到Linux指定目录下,然后直接解压即可。
tar -zxvf Mycat-server-1.6.7.3-release-20190927161129-
linux.tar.gz -C /usr/local
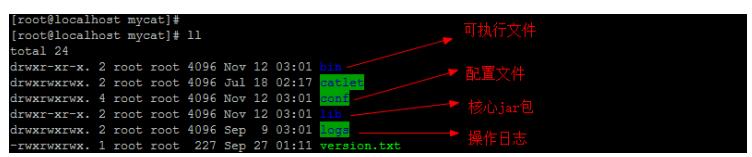
解压后的MyCat的目录结构介绍
2.3 分片配置测试
了解完了相关基本概念,并且环境也准备好了,下面我们就来完成分片配置测试。
将TB_TEST 表进行数据分片, 分为三个数据节点 , 每一个节点主机位于不同的服务器上
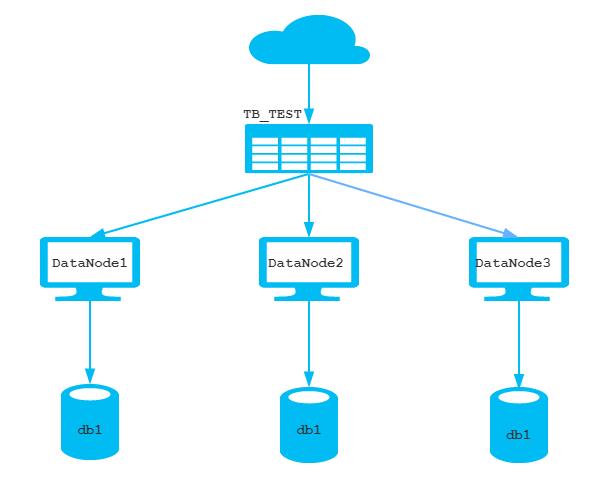
环境准备
三台服务器IP地址如下,
192.168.114.132
192.168.114.133
192.168.114.130
启动MySQL,然后分别创建数据库db1
#开启服务
service mysql start
#启动MySQL
./mysql -uroot -p123456
create database db2;
检查是否开启了防火墙
service iptables status
如果有防火墙的把防火墙关闭
service iptables stop
配置 schema.xml
1.打开schema.xml
vim /usr/local/mycat/conf/schema.xml
2.配置逻辑库名
<!-- 逻辑库配置 -->
<schema name="MY_CAT" checkSQLschema="false" sqlMaxLimit="100">
3.配置逻辑表名
<!-- 逻辑表配置 -->
<table name="TB_TEST" dataNode="dn1,dn2,dn3" rule="auto-sharding-long"
/>
4.数据节点配置
<!-- 数据节点配置 -->
<dataNode name="dn1" dataHost="host1" database="db2" />
<dataNode name="dn2" dataHost="host2" database="db2" />
<dataNode name="dn3" dataHost="host3" database="db2" />
5.节点主机配置,配置三台主机,
<dataHost name="host1" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1"
slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="192.168.114.130:3306" user="root"
password="123456"></writeHost>
</dataHost>
<dataHost name="host2" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1"
slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="192.168.114.132:3306" user="root"
password="123456"></writeHost>
</dataHost>
<dataHost name="host3" maxCon="1000" minCon="10" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1"
slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<writeHost host="hostM1" url="192.168.114.133:3306" user="root"
password="123456"></writeHost>
</dataHost>
配置 server.xml
1.打开server.xml
vim /usr/local/mycat/conf/server.xml
2.在system中添加UTF-8字符集设置,否则存储中文会出现问号
<property name="charset">utf8</property>
3.修改user的设置 我这里逻辑库名直接就是使用默认的所以不需要修改,如果要是逻辑库名不是这个的要在user下面修改配置:
<user name="root" defaultAccount="true">
<property name="password">123456</property>
<property name="schemas">MY_CAT</property>
</user>
<user name="user">
<property name="password">123456</property>
<property name="schemas">MY_CAT</property>
</user>
启动MyCat
MyCat相关命令
bin/mycat start
bin/mycat stop
bin/mycat status

命令行连接到MyCat,用户名和密码就是server.xml文件中配置的用户名密码。
mysql -h 127.0.0.1 -P 8066 -u root -p
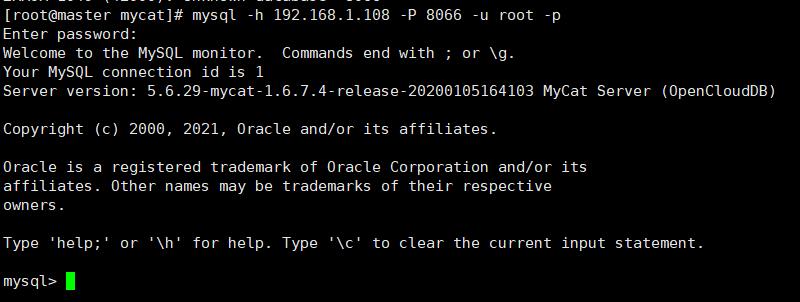
和mysql操作命令一样。我们来查看一下逻辑库和逻辑表。
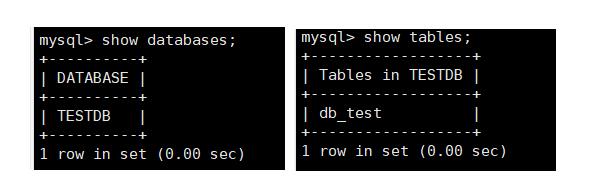
分片测试
进入mycat ,执行下列语句创建一个表
CREATE TABLE TB_TEST (
id BIGINT(20) NOT NULL,
title VARCHAR(100) NOT NULL ,
PRIMARY KEY (id)
) ENGINE=INNODB DEFAULT CHARSET=utf8 ;
创建成功后去查询一下其他三个db2数据库中是否存在
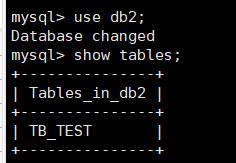
发现其他三个数据库中都存在表,说明mycat配置没有问题。
下面向表中插入一些数据进行验证:
INSERT INTO TB_TEST(ID,TITLE) VALUES(1,'goods1');
INSERT INTO TB_TEST(ID,TITLE) VALUES(2,'goods2');
INSERT INTO TB_TEST(ID,TITLE) VALUES(3,'goods3');
结果发现只有第一个节点中存在数据而其他两个节点中并没有数据,那什么情况下数据会写到其他二个节点中呢?
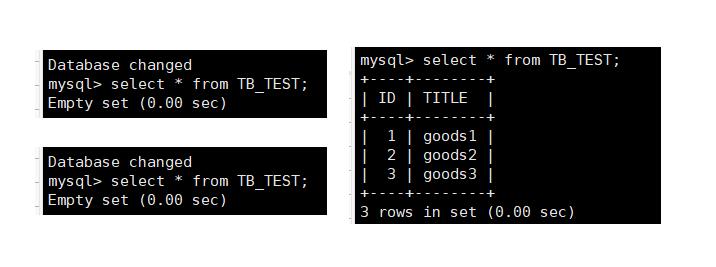
我们插入下面的数据就可以插入第二个节点和第三个节点
INSERT INTO TB_TEST(ID,TITLE) VALUES(5000001,'goods5000001');
INSERT INTO TB_TEST(ID,TITLE) VALUES(10000001,'goods5000001');
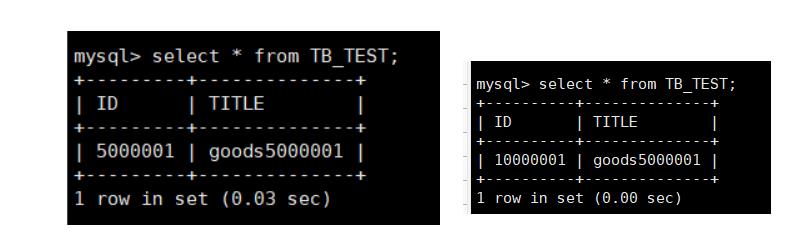
因为我们采用的分片规则是每节点存储500万条数据,所以当ID大于5000000则会存储到第二个节点上如果大于10000000则会在第三个节点,如果超过15000000将会报错。

2.4 MyCat原理介绍
MyCat原理中最重要的一个动词就是 “拦截”, 它拦截了用户发送过来的SQL语句, 首先对SQL语句做一些特定的分析,如分片分析、路由分析、读写分离分析、缓存分析等,然后将此SQL语句发往后端的真实数据库,并将返回的结果做适当处理,最终再返回给用户,如图所示。
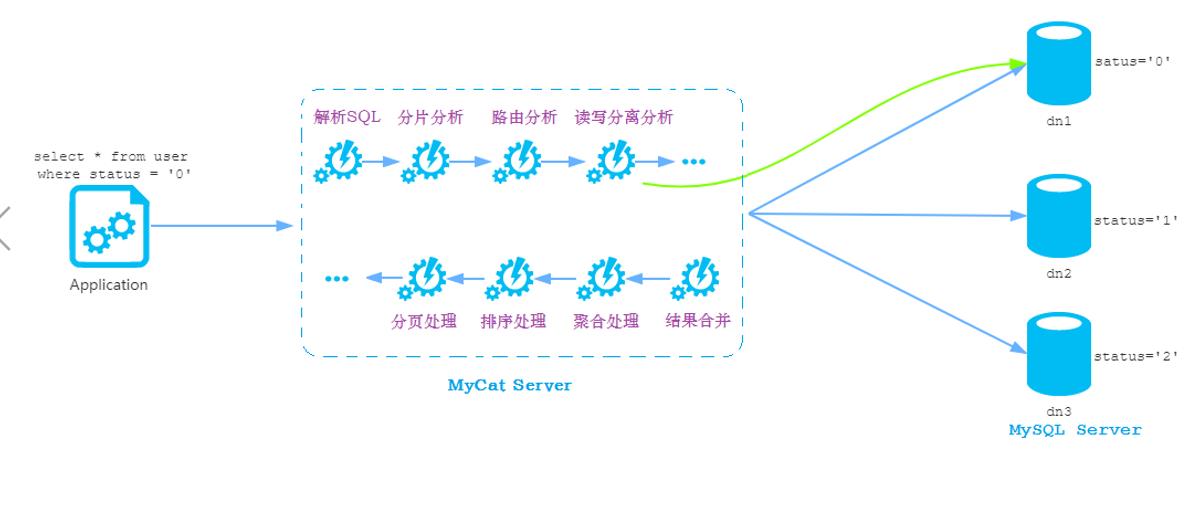
在图中,user表被分为三个分片节点dn1、dn2、dn3, 他们分布式在三个MySQLServer(dataHost)上,因此可以使用1-N台服务器来分片,分片规则(sharding rule)为典型的字符串枚举分片规则, 一个规则的定义是分片字段+分片函数。这里的分片字段为 status,分片函数则为字符串枚举方式。
MyCat收到一条SQL语句时,首先解析SQL语句涉及到的表,接着查看此表的定义,如果该表存在分片规则,则获取SQL语句里分片字段的值,并匹配分片函数,得到该SQL语句对应的分片列表,然后将SQL语句发送到相应的分片去执行,最后处理所有分片返回的数据并返回给客户端。以(“select * from user where status=‘0’” )为例, 查找 status=‘0’ ,按照分片函数, ‘0’ 值存放在dn1,于是SQL语句被发送到第一个节点中执行, 然后再将查询的结果返回给用户。如果发送的SQL语句为 “select * from user where status in (‘0’,‘1’)” , 那么SQL语句会被发送到dn1,dn2对应的主机上执行, 然后将结果集合并后输出给用户。
3. MyCat配置文件详解
3.1 server.xml
system标签
| 属性 | 取值 | 含义 |
|---|---|---|
| charset | utf8 | 设置Mycat的字符集, 字符集需要与MySQL的字符集保持一致 |
| nonePasswordLogin | 0,1 | 0为需要密码登陆、1为不需要密码登陆 ,默认为0,设置为1则需要指定默认账户 |
| useHandshakeV10 | 0,1 | 使用该选项主要的目的是为了能够兼容高版本的jdbc驱动, 是否采用HandshakeV10Packet来与client进行通信, 1:是, 0:否 |
| useSqlStat | 0,1 | 开启SQL实时统计, 1 为开启 , 0 为关闭 ; 开启之后, MyCat会自动统计SQL语句的执行情况 ; mysql -h 127.0.0.1 -P 9066 -u root -p 查看MyCat执行的SQL, 执行效率比较低的SQL , SQL的整体执行情况、读写比例等 ; show @@sql ; show @@sql.slow ; show @@sql.sum ; |
| useGlobleTableCheck | 0,1 | 是否开启全局表的一致性检测。1为开启 ,0为关闭 。 |
| sqlExecuteTimeout | 1000 | SQL语句执行的超时时间 , 单位为 s ; |
| sequnceHandlerType | 0,1,2 | 用来指定Mycat全局序列类型,0 为本地文件,1 为数据库方式,2 为时间戳列方式,默认使用本地文件方式,文件方式主要用于测试 |
| sequnceHandlerPattern | 正则表达式 | 必须带有MYCATSEQ_或者 mycatseq_进入序列匹配流程 注意MYCATSEQ_有空格的情况 |
| subqueryRelationshipCheck | true,false | 子查询中存在关联查询的情况下,检查关联字段中是否有分片字段 .默认 false |
| useCompression | 0,1 | 开启mysql压缩协议 , 0 : 关闭, 1 : 开启 |
| fakeMySQLVersion | 5.5,5.6 | 设置模拟的MySQL版本号 |
| defaultSqlParser | 由于MyCat的最初版本使用了FoundationDB的SQL解析器, 在MyCat1.3后增加了Druid解析器, 所以要设置defaultSqlParser属性来指定默认的解析器; 解析器有两个 : druidparser 和 fdbparser, 在MyCat1.4之后,默认是druidparser, fdbparser已经废除了 | |
| processors | 1,2… | 指定系统可用的线程数量, 默认值为CPU核心 x 每个核心运行线程数量; processors 会影响processorBufferPool, processorBufferLocalPercent, processorExecutor属性, 所有, 在性能调优时, 可以适当地修改processors值 |
| processorBufferChunk | 指定每次分配Socket Direct Buffer默认值为4096字节, 也会影响BufferPool长度, 如果一次性获取字节过多而导致buffer不够用, 则会出现警告, 可以调大该值 | |
| processorExecutor | 指定NIOProcessor上共享 businessExecutor固定线程池的大小; MyCat把异步任务交给 businessExecutor线程池中, 在新版本的MyCat中这个连接池使用频次不高, 可以适当地把该值调小 | |
| packetHeaderSize | 指定MySQL协议中的报文头长度, 默认4个字节 | |
| maxPacketSize | 指定MySQL协议可以携带的数据最大大小, 默认值为16M | |
| idleTimeout | 30 | 指定连接的空闲时间的超时长度;如果超时,将关闭资源并回收, 默认30分钟 |
| txIsolation | 1,2,3,4 | 初始化前端连接的事务隔离级别,默认为 REPEATED_READ , 对应数字为3 READ_UNCOMMITED=1; READ_COMMITTED=2; REPEATED_READ=3; SERIALIZABLE=4; |
| sqlExecuteTimeout | 300 | 执行SQL的超时时间, 如果SQL语句执行超时,将关闭连接; 默认300秒; |
| serverPort | 8066 | 定义MyCat的使用端口, 默认8066 |
| managerPort | 9066 | 定义MyCat的管理端口, 默认9066 |
user标签
user标签主要用于定义登录MyCat的用户和权限 :
-
<user name=“root” defaultAccount=“true”> : name 属性用于声明用户名 ;
-
<property name=“password”>123456</property> : 指定该用户名访问MyCat的密码 ;
-
<property name=“schemas”>TESTDB</property> : 能够访问的逻辑库, 多个的话, 使用 “,” 分割
-
<property name=“readOnly”>true</property> : 是否只读
-
<property name=“benchmark”>0</property> : 指定前端的整体连接数量 , 0 或不设置表示不限制
-
<property name=“usingDecrypt”>0</property> : 是否对密码加密默认 0 否 , 1 是
-
<privileges check=“false”>: 对用户的 schema 及 下级的 table 进行精细化的 DML 权限控制;
<!-- 表级 DML 权限设置 -->
<!--
<privileges check="false">
<schema name="TESTDB" dml="0110" >
<table name="tb01" dml="0000"></table>
<table name="tb02" dml="1111"></table>
</schema>
</privileges>
-->
</user>
-
privileges 节点中的 check 属性是用 于标识是否开启 DML 权限检查, 默认 false 标识不检查,当然 privileges 节点不配置,等同 check=false, 由于 Mycat 一个用户的 schemas 属性可配置多个 schema ,所以 privileges 的下级节点 schema 节点同样 可配置多个,对多库多表进行细粒度的 DML 权限控制;
-
权限修饰符四位数字(0000 - 1111),对应的操作是 IUSD ( 增,改,查,删 )。同时配置了库跟表的权限,就近原则。以表权限为准。
firewall 标签
firewall标签用来定义防火墙;firewall下whitehost标签用来定义 IP白名单 ,blacklist用来定义 SQL黑名单。
<!-- 全局SQL防火墙设置 -->
<!--白名单可以使用通配符%或着*-->
<!--例如<host host="127.0.0.*" user="root"/>-->
<!--例如<host host="127.0.*" user="root"/>-->
<!--例如<host host="127.*" user="root"/>-->
<!--例如<host host="1*7.*" user="root"/>-->
<!--这些配置情况下对于127.0.0.1都能以root账户登录-->
<!--
<firewall>
<whitehost>
<host host="1*7.0.0.*" user="root"/>
</whitehost>
<blacklist check="false">
</blacklist>
</firewall>
-->
黑名单拦截明细配置:
| 配置项 | 缺省值 | 描述 |
|---|---|---|
| selelctAllow | true | 是否允许执行 SELECT 语句 |
| selectAllColumnAllow | true | 是否允许执行 SELECT * FROM T 这样的语句。如果设置为 false,不允许执行 select * from t,但可以select * from (select id, name from t) a。这个选项是防御程序通过调用 select * 获得数据表的结构信息。 |
| selectIntoAllow | true | SELECT 查询中是否允许 INTO 字句 |
| deleteAllow | true | 是否允许执行 DELETE 语句 |
| updateAllow | true | 是否允许执行 UPDATE 语句 |
| insertAllow | true | 是否允许执行 INSERT 语句 |
| replaceAllow | true | 是否允许执行 REPLACE 语句 |
| mergeAllow | true | 是否允许执行 MERGE 语句,这个只在 Oracle 中有用 |
| callAllow | true | 是否允许通过 jdbc 的 call 语法调用存储过程 |
| setAllow | true | 是否允许使用 SET 语法 |
| truncateAllow | true | truncate 语句是危险,缺省打开,若需要自行关闭 |
| createTableAllow | true | 是否允许创建表 |
| alterTableAllow | true | 是否允许执行 Alter Table 语句 |
| dropTableAllow | true | 是否允许修改表 |
| commentAllow | false | 是否允许语句中存在注释,Oracle 的用户不用担心,Wall 能够识别 hints和注释的区别 |
| noneBaseStatementAllow | false | 是否允许非以上基本语句的其他语句,缺省关闭,通过这个选项就能够屏蔽 DDL。 |
| multiStatementAllow | false | 是否允许一次执行多条语句,缺省关闭 |
| useAllow | true | 是否允许执行 mysql 的 use 语句,缺省打开 |
| describeAllow | true | 是否允许执行 mysql 的 describe 语句,缺省打开 |
| showAllow | true | 是否允许执行 mysql 的 show 语句,缺省打开 |
| commitAllow | true | 是否允许执行 commit 操作 |
| rollbackAllow | true | 是否允许执行 roll back 操作 |
| 拦截配置-永真条件 | ||
| selectWhereAlwayTrueCheck | true | 检查 SELECT 语句的 WHERE 子句是否是一个永真条件 |
| selectHavingAlwayTrueCheck | true | 检查 SELECT 语句的 HAVING 子句是否是一个永真条件 |
| deleteWhereAlwayTrueCheck | true | 检查 DELETE 语句的 WHERE 子句是否是一个永真条件 |
| deleteWhereNoneCheck | false | 检查 DELETE 语句是否无 where 条件,这是有风险的,但不是 SQL 注入类型的风险 |
| updateWhereAlayTrueCheck | true | 检查 UPDATE 语句的 WHERE 子句是否是一个永真条件 |
| updateWhereNoneCheck | false | 检查 UPDATE 语句是否无 where 条件,这是有风险的,但不是SQL 注入类型的风险 |
| conditionAndAlwayTrueAllow | false | 检查查询条件(WHERE/HAVING 子句)中是否包含 AND 永真条件 |
| conditionAndAlwayFalseAllow | false | 检查查询条件(WHERE/HAVING 子句)中是否包含 AND 永假条件 |
| conditionLikeTrueAllow | true | 检查查询条件(WHERE/HAVING 子句)中是否包含 LIKE 永真条件 |
| 其他拦截配置 | ||
| selectIntoOutfileAllow | false | SELECT … INTO OUTFILE 是否允许,这个是 mysql 注入攻击的常见手段,缺省是禁止的 |
| selectUnionCheck | true | 检测 SELECT UNION |
| selectMinusCheck | true | 检测 SELECT MINUS |
| selectExceptCheck | true | 检测 SELECT EXCEPT |
| selectIntersectCheck | true | 检测 SELECT INTERSECT |
| mustParameterized | false | 是否必须参数化,如果为 True,则不允许类似 WHERE ID = 1 这种不参数化的 SQL |
| strictSyntaxCheck | true | 是否进行严格的语法检测,Druid SQL Parser 在某些场景不能覆盖所有的SQL 语法,出现解析 SQL 出错,可以临时把这个选项设置为 false,同时把 SQL 反馈给 Druid 的开发者。 |
| conditionOpXorAllow | false | 查询条件中是否允许有 XOR 条件。XOR 不常用,很难判断永真或者永假,缺省不允许。 |
| conditionOpBitwseAllow | true | 查询条件中是否允许有"&"、"~"、"|"、"^"运算符。 |
| conditionDoubleConstAllow | false | 查询条件中是否允许连续两个常量运算表达式 |
| minusAllow | true | 是否允许 SELECT * FROM A MINUS SELECT * FROM B 这样的语句 |
| intersectAllow | true | 是否允许 SELECT * FROM A INTERSECT SELECT * FROM B 这样的语句 |
| constArithmeticAllow | true | 拦截常量运算的条件,比如说 WHERE FID = 3 - 1,其中"3 - 1"是常量运算表达式。 |
| limitZeroAllow | false | 是否允许 limit 0 这样的语句 |
| 禁用对象检测配置 | ||
| tableCheck | true | 检测是否使用了禁用的表 |
| schemaCheck | true | 检测是否使用了禁用的 Schema |
| functionCheck | true | 检测是否使用了禁用的函数 |
| objectCheck | true | 检测是否使用了“禁用对对象” |
| variantCheck | true | 检测是否使用了“禁用的变量” |
| readOnlyTables | 空 | 指定的表只读,不能够在 SELECT INTO、DELETE、UPDATE、INSERT、MERGE 中作为"被修改表"出现 |
3.2 schema.xml
schema.xml 作为MyCat中最重要的配置文件之一 , 涵盖了MyCat的逻辑库 、 表 、 分片规则、分片节点及数据源的配置。
schema 标签
<schema name="MY_CAT" checkSQLschema="false" sqlMaxLimit="100">
<table name="TB_TEST" dataNode="dn1,dn2,dn3" rule="auto-sharding-long" />
</schema>
schema 标签用于定义 MyCat实例中的逻辑库 , 一个MyCat实例中, 可以有多个逻辑库 , 可以通过 schema 标签来划分不同的逻辑库。MyCat中的逻辑库的概念 , 等同于MySQL中的database概念 , 需要操作某个逻辑库下的表时, 也需要切换逻辑库:
use MY_CAT;
schema 标签的属性如下 :
-
name: 指定逻辑库的库名 , 可以自己定义任何字符串 ;
-
checkSQLschema: 取值为 true / false ;
如果设置为true时 , 如果我们执行的语句为 “select * from ITCAST.TB_TEST;” , 则MyCat会自动把schema字符去掉, 把SQL语句修改为 “select * from TB_TEST;” 可以避免SQL发送到后端数据库执行时, 报table不存在的异常 。
不过当我们在编写SQL语句时, 指定了一个不存在schema, MyCat是不会帮我们自动去除的 ,这个时候数据库就会报错, 所以在编写SQL语句时,最好不要加逻辑库的库名, 直接查询表即可。 -
sqlMaxLimit: 当该属性设置为某个数值时,每次执行的SQL语句如果没有加上limit语句, MyCat也会自动在limit语句后面加上对应的数值 。也就是说, 如果设置了该值为100,则执行 select * from TB_TEST 与 select * from TB_TEST limit 100 是相同的效果 。所以在正常的使用中, 建立设置该值 , 这样就可以避免每次有过多的数据返回。
子标签table
table 标签定义了MyCat中逻辑库schema下的逻辑表 , 所有需要拆分的表都需要在table标签中定义 。
<table name="TB_TEST" dataNode="dn1,dn2,dn3" rule="auto-sharding-long" />
属性如下 :
-
name : 定义逻辑表的表名 , 在该逻辑库下必须唯一。
-
dataNode: 定义的逻辑表所属的dataNode , 该属性需要与dataNode标签中的name属性的值对应。 如果一张表拆分的数据,存储在多个数据节点上,多个节点的名称使用","分隔 。

-
rule: 该属性用于指定逻辑表的分片规则的名字, 规则的名字是在rule.xml文件中定义的, 必须与tableRule标签中name属性对应。

-
ruleRequired: 该属性用于指定表是否绑定分片规则, 如果配置为true, 但是没有具体的rule, 程序会报错。
-
primaryKey :逻辑表对应真实表的主键
如: 分片规则是使用主键进行分片, 使用主键进行查询时, 就会发送查询语句到配置的所有的datanode上; 如果使用该属性配置真实表的主键, 那么MyCat会缓存主键与具体datanode的信息, 再次使用主键查询就不会进行广播式查询了, 而是直接将SQL发送给具体的datanode。 -
type : 该属性定义了逻辑表的类型,目前逻辑表只有全局表和普通表。
全局表:type的值是 global , 代表 全局表 。
普通表:无 -
autoIncrement:mysql对非自增长主键,使用last_insert_id() 是不会返回结果的,只会返回0。所以,只有定义了自增长主键的表,才可以用last_insert_id()返回主键值。
mycat提供了自增长主键功能,但是对应的mysql节点上数据表,没有auto_increment,那么在mycat层调用last_insert_id()也是不会返回结果的。
如果使用这个功能, 则最好配合数据库模式的全局序列。使用 autoIncrement=“true” 指定该表使用自增长主键,这样MyCat才不会抛出 “分片键找不到” 的异常。 autoIncrement的默认值为 false。 -
needAddLimit: 指定表是否需要自动在每个语句的后面加上limit限制, 默认为true。
dataNode 标签
<dataNode name="dn1" dataHost="host1" database="db1" />
dataNode标签中定义了MyCat中的数据节点, 也就是我们通常说的数据分片。一个dataNode标签就是一个独立的数据分片。
具体的属性 :
| 属性 | 含义 | 描述 |
|---|---|---|
| name | 数据节点的名称 | 需要唯一 ; 在table标签中会引用这个名字, 标识表与分片的对应关系 |
| dataHost | 数据库实例主机名称 | 引用自 dataHost 标签中name属性 |
| database | 定义分片所属的数据库 |
dataHost 标签
<dataHost name="host1" maxCon=Mycat配置文件详解