java工程师面试题一-----基础篇
Posted ꧁༺空༒白༻꧂
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了java工程师面试题一-----基础篇相关的知识,希望对你有一定的参考价值。
1、Java基础
1.1、请你说明String和StringBuffer和StringBuilder的区别
-
字符修改上的区别(主要)
String:不可变字符串;
StringBuffer:可变字符串、效率低、线程安全
StringBuilder:可变字符序列、效率高、线程不安全
-
初始化区别
String:可以空赋值
另外的会空赋值会有Null pointer access: The variable result can only be null at this location警告
-
小结
String:操作少量的数据
StringBuffer:多线程操作字符串缓冲区下操作大量数据
StringBuilder:单线程操作字符串缓冲区下操作大量数据
-
表格参照
String StringBuffer StringBuilder 字符串不变; 它们的值在创建后不能被更改。 字符串缓冲区支持可变字符串。 因为String对象是不可变的,它们可以被共享。但是每次对String操作就会产生新的String对象,不仅效率低下,而且浪费大量优先的内存空间 线程安全,可变的字符序列。 字符串缓冲区就像一个 String,但可以修改。它不会产生新的对象,每个StringBuffer对象都有一定的缓冲区容量,当字符串大小没有操过容量时,不会产生新的容量,反之,自动生成新容量线程安全,可变的字符序列。 字符串缓冲区就像一个 String,但可以修改。在保证线程较为安全的情况下下,他在大多数实现中更快不可变 可变 可变 / 线程安全 线程不安全 / 多线程操作字符串 单线程操作字符串
1.2、请你说明一下int和Integer有什么区别
-
区别(主要)
-
Integer是int的包装类,int则是java的一种基本数据类型
-
Integer变量必须实例化后才能使用,而int变量不需要
-
Integer实际是对象的引用,当new一个Integer时,实际上是生成一个指针指向此对象;而int则是直接存储数据值 。
-
Integer的默认值是null,int的默认值是0
-
-
扩展AtomicInteger原子类
Java中的运算操作,例如自增自减,没有进行额外的同步操作是,多线程环境下就是线程不安全的
public class AtomicIntegerTest { private static final int THREADS_CONUT = 20; public static int count = 0; public static void increase() { count++; } public static void main(String[] args) { Thread[] threads = new Thread[THREADS_CONUT]; for (int i = 0; i < THREADS_CONUT; i++) { threads[i] = new Thread(new Runnable() { @Override public void run() { for (int i = 0; i < 1000; i++) { increase(); } } }); threads[i].start(); } while (Thread.activeCount() > 1) { Thread.yield(); } System.out.println(count); } }高并发下有一个论据**“基于volatile变量的运算在并发下是安全的”**,我们将count的修饰改为volatile,发现还是不对的,这就是因为核心点在Java里面的运算(自增)并不是原子性的。
public class AtomicIntegerTest { private static final int THREADS_CONUT = 20; public static volatile int count = 0; public static void increase() { count++; } public static void main(String[] args) { Thread[] threads = new Thread[THREADS_CONUT]; for (int i = 0; i < THREADS_CONUT; i++) { threads[i] = new Thread(new Runnable() { @Override public void run() { for (int i = 0; i < 1000; i++) { increase(); } } }); threads[i].start(); } while (Thread.activeCount() > 1) { Thread.yield(); } System.out.println(count); } }将count的修饰改为AtomicInteger,发现结果不会再变化,并且输出为正确的结果
import java.util.concurrent.atomic.AtomicInteger; public class AtomicIntegerTest { private static final int THREADS_CONUT = 20; public static AtomicInteger count = new AtomicInteger(0); public static void increase() { count.incrementAndGet(); } public static void main(String[] args) { Thread[] threads = new Thread[THREADS_CONUT]; for (int i = 0; i < THREADS_CONUT; i++) { threads[i] = new Thread(new Runnable() { @Override public void run() { for (int i = 0; i < 1000; i++) { increase(); } } }); threads[i].start(); } while (Thread.activeCount() > 1) { Thread.yield(); } System.out.println(count); } }
1.3、数组(Array)和列表(ArrayList)的区别?什么时候应该使用Array而不是ArrayList?
区别
-
初始化状态
Array:在声明的同时必须进行实例化(至少初始化数组的大小)
ArrayList:可以只是先声明
-
初始化大小
Array:必须指定大小,创建后的数组大小固定
ArrayList:大小可以动态指定,数组大小可以在初始化时指定,若不指定,该对象空间可以任意增加
-
存储对象
Array:只能存储同构的对象(指类型相同的对象),若是int[]的数组就只能存储整形数据,object数组除外
ArrayList:可以存放任何不同类型的数据(里面存放的是被封装的object对象,本质就是内部使用“object[]_items”这一个私有字段来封装对象)
-
CLR(公共语言运行库)托管存放方式
Array:始终是连续存放
ArrayList:存放不一定连续
-
数据插入
Array:不能够随意添加删除其中的项
ArrayList:可以在任意位置插入删除项
适用场景
- 如果想要保存一些在整个程序运行期间都会存在而且不变的数据,可以使用一个全局数组Array。
- 如果只是想要以数组的形式保存数据,而不对数据进行增加、删除等操作,只是为了方便进行查找的话,可以使用ArrayList。
- 如果需要对元素进行频繁的移动或删除,或者是处理超大量的数据,使用ArrayList就不合适了,因为它的效率很低,可以选择使用LinkedList
扩展
-
Array和ArrayList相同点
- 都允许存储null值,但是array只能是object是这样,int型就是0,boolean值就是false
- 都允许存储重复的值
- 都是从第一个元素开始的索引
- 都能够对自身进行枚举(因为都实现了IEnumerable接口)
-
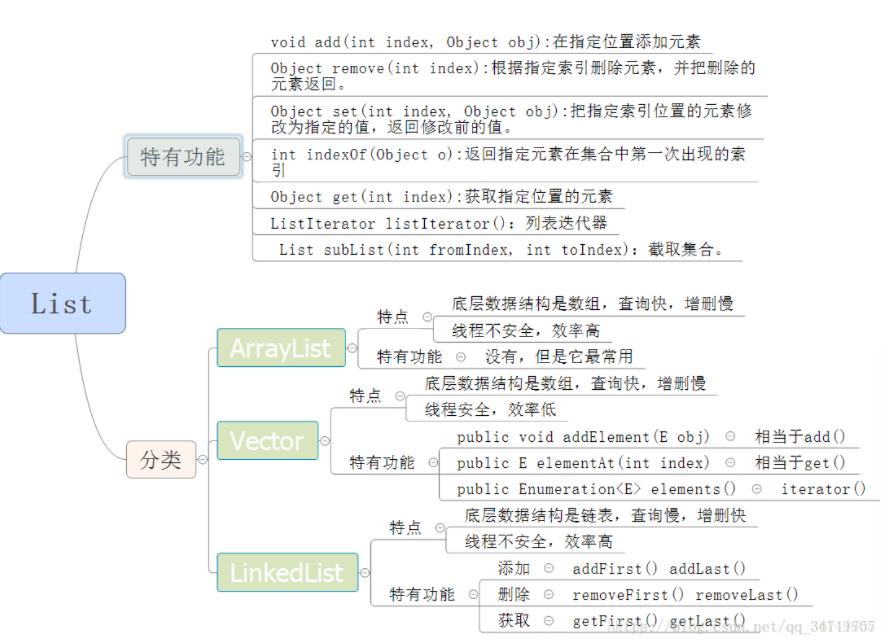
LinkedList
-
以双向链表实现存储数据,插入删除只需要改变前后两个结点指针指向
-
元素有序,输出输入顺序一致
-
允许元素为null
-
所有指定位置操作都是从头开始遍历的
-
不是同步容器,想要线程安全的时候,需要直接在初始化时用 Collections.synchronizedList 方法进行包装
-
方法比Array多了6个链表相关方法,参考链接https://blog.csdn.net/qq_36711757/article/details/80411721
-
1.4、什么是值传递和引用传递?
首先明确一点,Java一定是值传递!值传递!值传递!
值传递:基本类型的直接传递
按值传递重要特点:传递的是值的拷贝,也就是说传递后就互不相关了
public class Test {
public static void main(String[] args) {
int int1 = 10;
int int2 = int1;
System.out.println("int1==" + int1);
System.out.println("int2==" + int2);
int2 = 20;
System.out.println("改变之后");
System.out.println("int1==" + int1);
System.out.println("int2==" + int2);
}
}
//结果
int1==10
int2==10
改变之后
int1==10
int2==20
引用传递:对基本类型进行封装,对封装进行传递
指的是在方法调用时,传递的参数是按引用进行传递,其实传递的引用的地址,也就是变量所对应的内存空间的地址。
TestDemo testDemo1 = new TestDemo();
testDemo1.setTxtProtected("potected");
TestDemo testDemo2 = testDemo1;
TestDemo testDemo3 = new TestDemo();
testDemo3.setTxtProtected(testDemo1.getTxtProtected());
System.out.println("testDemo1==" + testDemo1.getTxtProtected());
System.out.println("testDemo2==" + testDemo2.getTxtProtected());
System.out.println("testDemo3==" + testDemo3.getTxtProtected());
testDemo2.setTxtProtected("testDemo2");
System.out.println("改变之后");
System.out.println("testDemo1==" + testDemo1.getTxtProtected());
System.out.println("testDemo2==" + testDemo2.getTxtProtected());
System.out.println("testDemo3==" + testDemo3.getTxtProtected());
//结果
testDemo1==potected
testDemo2==potected
testDemo3==potected
改变之后
testDemo1==testDemo2
testDemo2==testDemo2
testDemo3==potected
1.5、Java支持的数据类型有哪些?什么是自动拆装箱?
基本数据类型
-
整数型:byte(8)、short(16)、int(32)、long(64)
-
浮点型:float(32)、double(64)
-
字符型:char(16位的Unicode字符)
-
布尔型:boolean
引用类型(注意String是引用类型)
- 引用类型声明的变量,是指该变量在内存中实际上存储的是个引用地址,创建的对象实际是在堆中
自动拆装箱
-
指基本数据类型和引用数据类型之间的自动转换,如Integer 和 int 可以自动转换; Float和float可以自动转换
-
//基本类型转换成包装类型,称为装箱 Integer intObjct = new Integer(2); //装箱 //Integer intObjct = 2 //自动装箱 //自动装箱,如果一个基本类型值出现在需要对象的环境中,会自动装箱 //拆箱 int a = 3 + new Integer(3); //加法需要的是数值,所以会自动拆箱 Integer b = 3 + new Integer(3); //自动拆箱,再自动装箱 Double x = 3.0; //Double x = 3; //编译器不给过 //double y = 3; //而这个可以
1.6、为什么会出现4.0-3.6=0.40000001这种现象?
-
这种误差的主要原因
- 浮点数值采用二进制系统表示,而在二进制系统中无法精确表示分数1/10
- 如果不想有任何误差,使用BigDecimal类
-
分析原因
数位表达法有关,如十进制下的520,相当于5·102+2·101+0·10^0
同理:分数也会由二进制表示小数的时候只能用任意个不同的1/(2^n)之和表示,而不能精确表示的就会产生误差
-
扩展
- BigDecimal不变的,任意精度的带符号的十进制数字。 A
BigDecimal由任意精度整数未缩放值和32位整数级别组成 。 如果为零或正数,则刻度是小数点右侧的位数。 如果是负数,则数字的非标定值乘以10,以达到等级的否定的幂。 因此,BigDecimal所代表的BigDecimal值为(unscaledValue × 10-scale)。 - 如果基本的整数和浮点数精度不能够满足需求, 那么可以使用java.math 包中的两个 很有用的类:Biglnteger 和 BigDecimal 这两个类可以处理包含任意长度数字序列的数值。 Biglnteger类实现了任意精度的整数运算, BigDecimal 实现了任意精度的浮点数运算。
- 原文链接:https://blog.csdn.net/qq_40164190/article/details/105338777
- BigDecimal不变的,任意精度的带符号的十进制数字。 A
1.7、java8的新特性,请简单介绍一下
- 将放在一篇新的文章讲解
1.8、请你说明符号“==”比较的是什么?
-
类型区别
-
基本数据类型:比较值
-
对象引用类型:比较对象的内存地址
-
不同类型:转换同一类型比较
-
-
扩展
===:先比较数据类型,再比较值,如果数据类型不匹配,返回false,即"严格等"的运算符
==:先比较数据类型,再比较值,如果数据源类型不匹配,则会将其数据类型转为同一数据类型,再比较
1.9、Obiect若不重写hashCode()的话,hashCode()如何计算出来的?
-
Object 的 hashcode 方法是本地方法,也就是用 c 或 c++ 实现的,该方法直接返回对象的内存地址。
-
如果没有重写hashCode(),则任何对象的hashCode()的值都不相等(需要重写)
1.10、为什么重写equals还要重写hashcode?
-
HashMap中的key比较流程:
①先求出key的hashcode(),比较其值是否相等
②若相等再比较equals(),若相等则认为他们是相等的
③若equals()不相等则认为他们不相等。
-
那么假设重写equals不重写hashcode
根据上一题所说“如果没有重写hashCode(),则任何对象的hashCode()的值都不相等”
hashcode的值被认为是不同的值,那么就不会往下进行equals的比较。
-
知识延申
equals和hashcode的关系:
1、如果两个对象相同(即用equals比较返回true),那么它们的hashCode值一定要相同;
2、如果两个对象的hashCode相同,它们并不一定相同
1.11、若对一个类不重写,它的eguals()方法是如何比较的?
- 比较对象的地址。
以上是关于java工程师面试题一-----基础篇的主要内容,如果未能解决你的问题,请参考以下文章