大数据清洗1(numpy之Ndarray对象)
Posted 晨沉宸辰
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据清洗1(numpy之Ndarray对象)相关的知识,希望对你有一定的参考价值。
numpy之Ndarray对象
一、了解数据清洗
真实数据中,包含了很多大量的缺失值,大量的噪音,也有人为因素录入错误,所以不利于算法模型的训练。
二、了解numpy库
1. 发展:

2. 安装:

方法一:
方法二:
安装anacond
3. 特性

三、NumPy-Ndarray对象
NumPy 的核心是 ndarray 对象,这个对象封装了同质数据类型的n维数组。(数组,即为有序的元素
序列)
ndarray 是 n-dimension-array 的简写。
NumPy 约定俗成的导入方式如下:
import numpy as np
#全部行都能输出
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all"
- 方法一 : np.array函数
创建一个 ndarray 只需调用 NumPy 的 array 函数即可:
numpy.array()
#创建一维数组
arr1 = np.array([1, 3.14, -5, 2, 6.2, 0]) #要生成的array中的元素必须打包到一个序列作
为一个参数传入函数中
arr1
array([ 1. , 3.14, -5. , 2. , 6.2 , 0. ])
#创建二维数组
arr2 = np.array([[5,6,7,8,9],[4,3,2,1,0]])
arr2
array([[5, 6, 7, 8, 9],
[4, 3, 2, 1, 0]])
#通过ndmin参数控制生成数组的维度
arr3 = np.array([1,2,3,4,5], ndmin=2)
arr3
array([[1, 2, 3, 4, 5]])
- 方法二 : 随机数函数生成array
用随机整数函数生成array时,设置参数size来控制array的维度
import numpy as np
#创建一维数组
arr4 = np.random.randint(10,size=(4,)) #必须设置size参数,否则只生成一个随机数
arr4
array([2, 8, 7, 2])
#创建二维数组
arr5 = np.random.randint(20,size=(4,5))
arr5
array([[17, 11, 15, 5, 7],
[ 3, 6, 4, 10, 11],
[19, 7, 6, 10, 1],
[ 3, 5, 4, 14, 6]])
#元素取值从0到1服从均匀分布
np.random.rand(2,3,4)
array([[[0.28786882, 0.11619332, 0.18172704, 0.49428977],
[0.56576513, 0.22183517, 0.76749117, 0.57730807],
[0.16782331, 0.36747137, 0.46867358, 0.65426618]],
[[0.79308974, 0.66306179, 0.61302969, 0.990852 ],
[0.1194848 , 0.14856478, 0.85228103, 0.50952588],
[0.21726993, 0.99326629, 0.31529748, 0.25873317]]])
np.random.uniform(size = (2,3)) #默认生成从0~1的均匀分布,可以通过参数设置随机数生成范围
array([[0.80917529, 0.35367538, 0.46784249], [0.27417326,
0.79820039, 0.81413841]])
np.random.uniform(1,10,size = (2,3)) #默认生成从0~1的均匀分布,可以通过参数设置随机数生成
范围
array([[9.5328138 , 8.40596176, 5.63625209], [2.98898338,
7.71968267, 4.88383993]])
#元素取值从[0,1)随机浮点数并服从连续均匀分布,参数为元组形式
np.random.random((2,3))
array([[0.88830375, 0.9411933 , 0.50301225], [0.70204204,
0.70654201, 0.48102176]])
#元素取值服从标准正态分布
np.random.randn(2,3)
array([[-0.08393274, 0.52225887, 1.12151161], [-0.7584035 ,
0.17067587, 0.34958916]])
- 方法三 : 用arange函数创建array
可以用reshape函数来控制生成array的维度
#创建一维数组
arr6 = np.arange(1,10) #还可以设置步长
arr6
array([1, 2, 3, 4, 5, 6, 7, 8, 9])
#创建二维数组
arr7 = np.arange .(12).reshape((3,4))
arr7
array([[ 0, 1, 2, 3], [ 4, 5, 6, 7], [ 8, 9, 10, 11]])
-
方法四 : 创建特殊数组函数:
-
np.zeros 全0数组
-
np.ones 全1数组
-
np.full 按照某一数组的形状生成数组
-
np.linspace 线性序列数组(元素之间等差)
-
np.eye 单位矩阵数组
-
np.diag 对角矩阵数组
全0数组
#一维全0数组
np.zeros(5)
array([0., 0., 0., 0., 0.])
#指定形状的全0数组
np.zeros((3,3),dtype=float)
array([[0., 0., 0.], [0., 0., 0.], [0., 0., 0.]])
全1数组
#一维全1数组
np.ones(5)
array([1., 1., 1., 1., 1.])
#指定形状的全1数组
np.ones((3,3))
array([[1., 1., 1.], [1., 1., 1.], [1., 1., 1.]])
全n数组
#创建一维全n数组
np.full((3,),3)
array([3, 3, 3])
#创建指定形状的全n数组
np.full((3,3),3)
array([[3, 3, 3], [3, 3, 3], [3, 3, 3]])
线性序列数组,所有元素组成一个等差数列
#创建线性序列,可以倒序,起始值大于终止值
np.linspace(10,5,5)
array([10. , 8.75, 7.5 , 6.25, 5. ])
#linspace创建的array需要通过reshape函数改变形状维度,不能和retstep参数一起使用
np.linspace(0,50,21).reshape(3,7)
array([[ 0. , 2.5, 5. , 7.5, 10. , 12.5, 15. ], [17.5, 20. , 22.5,
25. , 27.5, 30. , 32.5], [35. , 37.5, 40. , 42.5, 45. , 47.5, 50. ]])
#显示步长
np.linspace(0,50,5,retstep=True)
(array([ 0. , 12.5, 25. , 37.5, 50. ]), 12.5)
#默认包含终止值,通过endpoint参数控制是否包含终止值
np.linspace(0,50,5,retstep=True, endpoint=False)
(array([ 0., 10., 20., 30., 40.]), 10.0)
三、数组的属性
1.了解
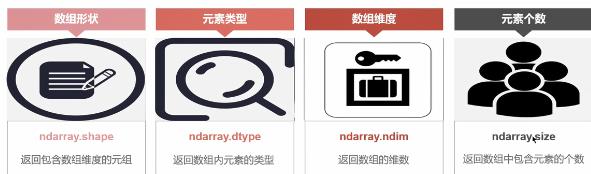
2、数组的属性
- ndarray.shape 返回一个包含数组维度的元组
- ndarray.dtype 返回数组元素的类型
- ndarray.ndim 返回数组的维数
- ndarray.size 返回数组中包含元素的个数
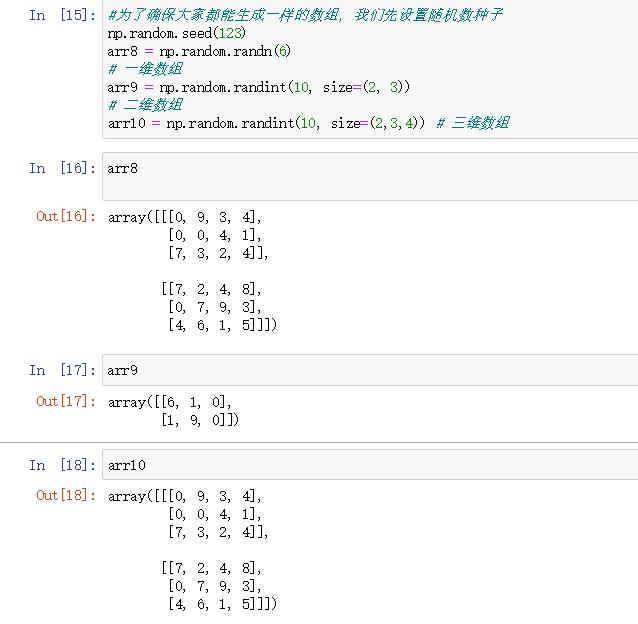
#为了确保大家都能生成一样的数组, 我们先设置随机数种子 np.random.seed(123) arr8 = np.random.randn(6) # 一维数组 arr9 = np.random.randint(10, size=(2, 3)) # 二维数组 arr10 = np.random.randint(10, size=(2,3,4)) # 三维数组
arr8
arr9
arr10
#查看数组的形状
arr8.shape
arr9.shape
arr10.shape

#查看数组中元素的类型
arr8.dtype
arr9.dtype
arr10.dtype

#查看维度
arr8.ndim
arr9.ndim
arr10.ndim
#查看元素个数
arr8.size
arr9.size
arr10.size
四、NumPy的矢量化功能
- ndarray和Python原生序列的区别
NumPy 数组在创建时有固定的大小,不同于Python列表(可以动态改变)。
NumPy 数组中的元素都需要具有相同的数据类型,计算速度更快。
数组的元素如果也是数组(可以是 Python 的原生 array,也可以是 ndarray)的情况下,则构成了多
维数组。 - NumPy的矢量化(向量化)功能
- 数组表达式替换显式循环的做法通常称为向量化
将一个二维数组 a 的每个元素与长度相同的另外一个数组 b 中相应位置的元素相乘,使用 Python 原生 的数组实现如下
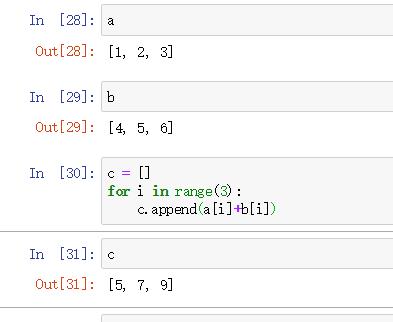
a = [1,2,3]
b = [4,5,6]
a
b

c = []
for i in range(3):
c.append(a[i]+b[i])
c=a*b #这样写可以么?
使用NumPy实现a与b的对应元素相乘
arr11 = np.array(a)
arr12 = np.array(b)
arr11
arr12

#实现对应元素相乘
arr11*arr12
#实现对应元素相加
arr11+arr12

#所有元素对一个数值的加减乘除
arr11+1
arr11*2
矢量化代码有很多优点,其中包括:
- 矢量化代码更简洁易读
- 更少的代码行通常意味着更少的错误
- 执行效率高,运行速度快
五、ndarray的各种变换操作
| 数组的维度变换 | 数组的类型变换 | 数组的类型变换 数组内元素类型变换 |
|---|---|---|
| ndarray.reshape | ndarray.tolist | ndarray.astyp |
| ndarray.resize |
1. 数组的维度变换
arr13 = np.random.randint(1, 100,(2, 2))
arr13
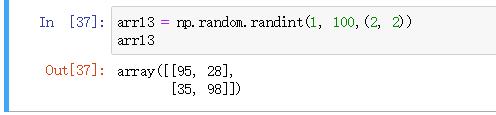
# reshape返回调整后的数组形状,不改变原数组
arr13.reshape(1,4)

arr13.shape
arr14 = arr13.copy()
arr14.shape
#resize返回调整后的形状,改变原数组
arr14.resize(4,1)
arr14.shape
2. 数组的类型变换
#tolist不改变原数组,将高维数组转换为嵌套列表,一维数组转换为列表
arr14.tolist()
list(arr14)
type(arr1.tolist())
3. 数组内元素类型的变换
arr13.dtype
#astype不改变原数组
arr13.astype(float)
arr13.astype(str)
五、广播
如果满足以下条件之一,那么数组被称为可广播的。
- 如果数组不具有相同的秩,则将较低等级数组的形状维度添加1,直到两个形状具有相同的大小.
- 其中一个数组的维度大小和元素个数为1,相当于对单个标量进行广播
- 在一个数组的大小为1且另一个数组的大小大于1的任何维度中,第一个数组的行为就像沿着该维 度复制一样
给出广播示意图
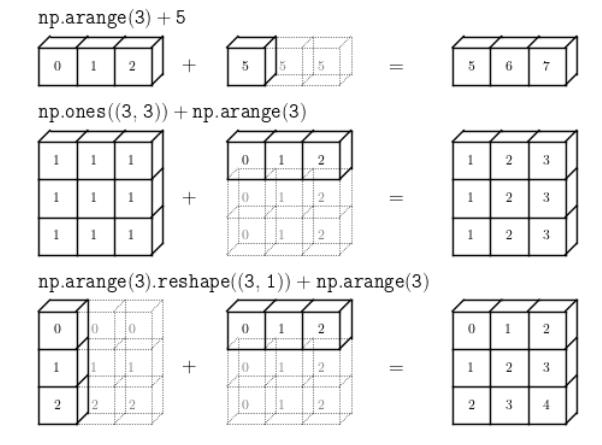
#列数相同,一行加多行
a=np.arange(3)
aarray([0, 1, 2])
b=np.array([1])
b
array([1])
#第一幅图
a+b
array([1, 2, 3])
#第一幅图
a+1
array([1, 2, 3])
c = np.ones((3,3))
c
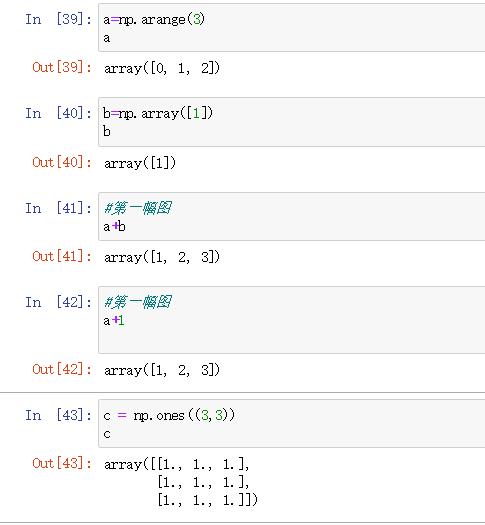
#第二幅图
a+c
d=a[:,np.newaxis]
d
#第三幅图
a+d
#单个标量和数组的运算
b+1
#不满足广播条件的数组无法进行广播
e= np.arange(4).reshape(2,2)
e
a+e
e+b
#b广播到和e相同的形状
以上是关于大数据清洗1(numpy之Ndarray对象)的主要内容,如果未能解决你的问题,请参考以下文章