论文笔记基于语义依赖和上下文矩的深度掩码记忆网络在方面级情感分类中的应用(英文题目太长)
Posted 王六六的IT日常
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文笔记基于语义依赖和上下文矩的深度掩码记忆网络在方面级情感分类中的应用(英文题目太长)相关的知识,希望对你有一定的参考价值。
Deep Mask Memory Network with Semantic Dependency and Context Moment for Aspect Level Sentiment Classification
这篇论文来自IJCAI-2019,其结果也是目前非Bert模型中已发表论文的最高水平。
这个模型相较于上面那一篇要复杂很多,是一篇名副其实的IJCAI论文。
这篇论文较于上一篇的改进之处在于:
- 整合了语义分析信息到记忆网络中而不是位置信息。
- 设计了辅助任务来学习整个句子的情感分布,这可以为目标aspect的情感分类提供想要的背景信息。
该论文提出模型被称作deep mask memory network with semantic dependency and context moment (DMMN-SDCM)。它基于记忆网络,引入语义分析信息来指导attention机制并有效学习其他aspect(非目标aspect)提供的信息。同时论文提出的context moment嵌入到了整个句子的情感分类,被设计用于为目标aspect提供背景信息。
模型主要包括以下三个部分:
- the semantic-dependency mask attention
- the inter-aspect semantic modeling
- the context-moment sentiment learning
- 除此之外还有基础的的embedding模块、memory building模块、实现分类的classification模块。
DMMN-SDCM整体架构
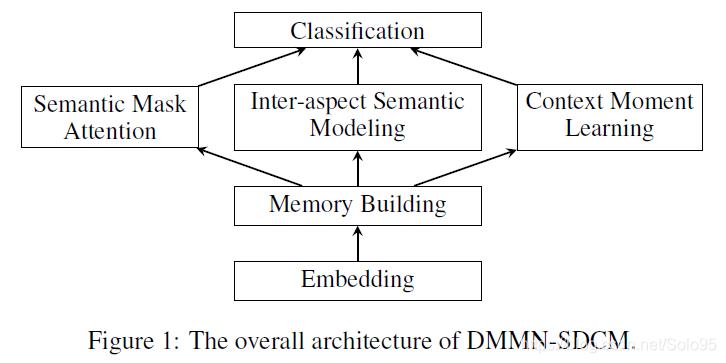
Embedding模块没有什么可讲的。
参考:苏剑林. (Dec. 03, 2016). 《词向量与Embedding究竟是怎么回事? 》
词向量,英文名叫Word Embedding,按照字面意思,应该是词嵌入。
词嵌入是一种语义空间到向量空间的映射,简单说就是把每个词语都转换为固定维数的向量,并且保证语义接近的两个词转化为向量后,这两个向量的相似度也高。
Embedding层就是以one hot为输入、中间层节点为字向量维数的全连接层!而这个全连接层的参数,就是一个“字向量表”!从这个层面来看,字向量没有做任何事情!它就是one hot,别再嘲笑one hot的问题了,字向量就是one hot的全连接层的参数!
Embedding 嵌入,我们可以将其理解为一种降维行为。可以将高维数据映射到低维空间来解决稀疏输入数据的问题。
embedding层做了什么呢?
它把我们的稀疏矩阵,通过一些线性变换(在CNN中用全连接层进行转换,也称为查表操作),变成了一个密集矩阵,这个密集矩阵用了N个特征来表征所有的文字,在这个密集矩阵中,表象上代表着密集矩阵跟单个字的一一对应关系,实际上还蕴含了大量的字与字之间,词与词之间甚至句子与句子之间的内在关系他们之间的关系,用的是嵌入层学习来的参数进行表征。
从稀疏矩阵到密集矩阵的过程,叫做embedding,很多人也把它叫做查表,因为他们之间也是一个一一映射的关系。
更重要的是,这种关系在反向传播的过程中,是一直在更新的,因此能在多次epoch后,使得这个关系变成相对成熟,即:正确的表达整个语义以及各个语句之间的关系。这个成熟的关系,就是embedding层的所有权重参数。Embedding是NPL领域最重要的发明之一,他把独立的向量一下子就关联起来了。
这就相当于你是你爸的儿子,你爸是A的同事,B是A的儿子,似乎跟你是八竿子才打得着的关系。结果你一看B,是你的同桌。Embedding层就是用来发现这个秘密的武器。
- Memory Building模块使用一个双向的LSTM网络来获取记忆 m 1 ∗ , m 2 2 , . . . , m n ∗ m_1^*,m_2^2,...,m_n^* m1∗,m22,...,mn∗,其中 m i ∗ = ( h i ← , h i → ) m_i^*=(\\overleftarrow{h_i},\\overrightarrow{h_i}) mi∗=(hi,hi)
- The semantic-dependency-mask attention模块提取语义信息,并且为不同层选择不同的记忆元素来指导attention机制,该模块的输出记作 v s d v_{sd} vsd
- The inter-aspect semantic modeling模块使用语义依赖信息和attention机制来获取其他aspect的有用信息,其输出记为 v i m v_{im} vim
- The context-moment sentiment learning使用一个被称为context moment learning的任务来学习整个句子中所有aspect的信息,其输出记为 v c m v_{cm} vcm
以上三个模块的输出构成了sentiment representation(情感表征): v = { v s d , v i m , v c m } v = \\left\\{ v_{sd}, v_{im},v_{cm} \\right\\} v={vsd,vim,vcm}
Classification模块就是一个前馈网络,将
v
v
v映射到目标分类:
y
=
s
o
f
t
m
a
x
(
W
c
v
+
b
c
)
y=softmax(W_cv+b_c)
y=softmax(Wcv+bc)
文中使用的loss包含三个部分,交叉熵+辅助任务loss +
L
2
L_2
L2正则:
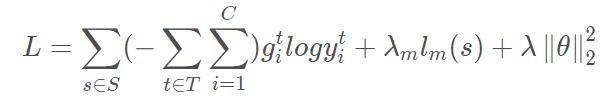
辅助任务的loss稍后介绍。
损失函数loss的作用
- 损失函数用来评价模型的预测值和真实值不一样的程度,深度学习训练模型的时候就是通过计算损失函数,更新模型参数,从而减小优化误差,直到损失函数值下降到目标值或者达到了训练次数。
- 不同的模型用的损失函数一般也不一样。损失函数设置的越好,通常模型的性能越好。
- loss函数可以自定义
损失函数loss和准确率accuracy的比较
- 在分类问题中,准确率accuracy更加直观,也更具有可解释性;对于回归问题,accuracy不可用,只能用loss
- 准确率accuracy不可微分,无法直接用于网络训练,而反向传播算法要求损失函数是可微的
- 损失函数loss可微分,可以求梯度,运用反向传播更新参数。
Semantic-Dependency-Mask Attention
该模块依据语义依赖分析树(semantic dependency parsing tree),来对不同计算跳数的context memory施加mask。在每一个计算步骤,该模块在aspect的表示和记忆单元之间使用attention机制。
语义分析树使用开源工具spaCy生成。
原作者将语义分析树上词到aspect的路径长度作为距离,来提取语义分析信息。施加掩码的语义分析信息如下:
m
i
∗
=
{
m
i
∗
,
if
d
i
s
t
(
w
i
,
w
t
)
≤
l
0
,
o
t
h
e
r
w
i
s
e
m_i^*= \\begin{cases} m_i^*, & \\text{if } dist(w_i,w_t)\\leq l \\\\ 0, & otherwise \\end{cases}
mi∗={mi∗,0,if dist(wi,wt)≤lotherwise
以上述方式得到整个层的
{
m
1
l
,
.
.
.
,
m
i
l
,
.
.
.
,
m
n
l
}
\\left\\{ m_1^l,...,m_i^l,... ,m_n^l \\right\\}
{m1l,...,mil,...,mnl}之后,以如下形式计算
l
l
l层的attention得分:
α
i
l
=
s
o
f
t
m
a
x
(
W
A
L
l
(
m
i
l
,
v
s
d
l
−
1
,
v
t
)
+
b
A
L
l
)
\\alpha_i^l= softmax(W_{AL}^l(m_i^l,v_{sd}^{l-1},v_t)+b_{AL}^l)
αil=softmax(WALl(mil,vsdl−1,vt)+bALl)
其中
v
s
d
v_{sd}
vsd是上一层的计算结果,
v
t
v_t
vt是aspect的表示。
attention输出
i
l
A
L
i_l^{AL}
ilAL 以如下方式进行计算:
i
l
A
L
=
∑
i
=
1
n
α
i
l
m
i
l
i_l^{AL} = \\sum_{i=1}^n \\alpha_i^l m_i^l
ilAL=i=1∑nαilmil
在最后一层,作者采用另一个先行层来施加线性变换,作为一个门控函数来控制传递的转化特征和输入特征的比例:
v
s
d
l
=
(
W
o
i
l
A
L
+
b
o
)
∗
T
+
v
s
d
l
−
1
∗
(
1
−
T
)
v_{sd}^l = (W_o i_l^{AL} + b_o) * T + v_{sd}^l-1 * (1-T)
vsdl=(WoilAL+bo)∗T+vsdl−1∗(1以上是关于论文笔记基于语义依赖和上下文矩的深度掩码记忆网络在方面级情感分类中的应用(英文题目太长)的主要内容,如果未能解决你的问题,请参考以下文章