App爬虫之路:海量食谱数据爬取存储到Mysql!!!
Posted Code皮皮虾
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了App爬虫之路:海量食谱数据爬取存储到Mysql!!!相关的知识,希望对你有一定的参考价值。
前言
App数据抓包分析
打开豆果美食APP

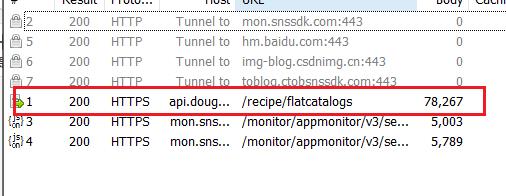
得到对应的JSON数据

对应代码
url = "https://api.douguo.net/recipe/flatcatalogs"
data = {
"client": "4,",
"_vs": "0",
}
count = 0
response = handle_request(url, data)
# 转化为json格式
index_response_dict = json.loads(response.text)
使用在线JSON解析网站进行解析,可以发现我们得到了需要的数据
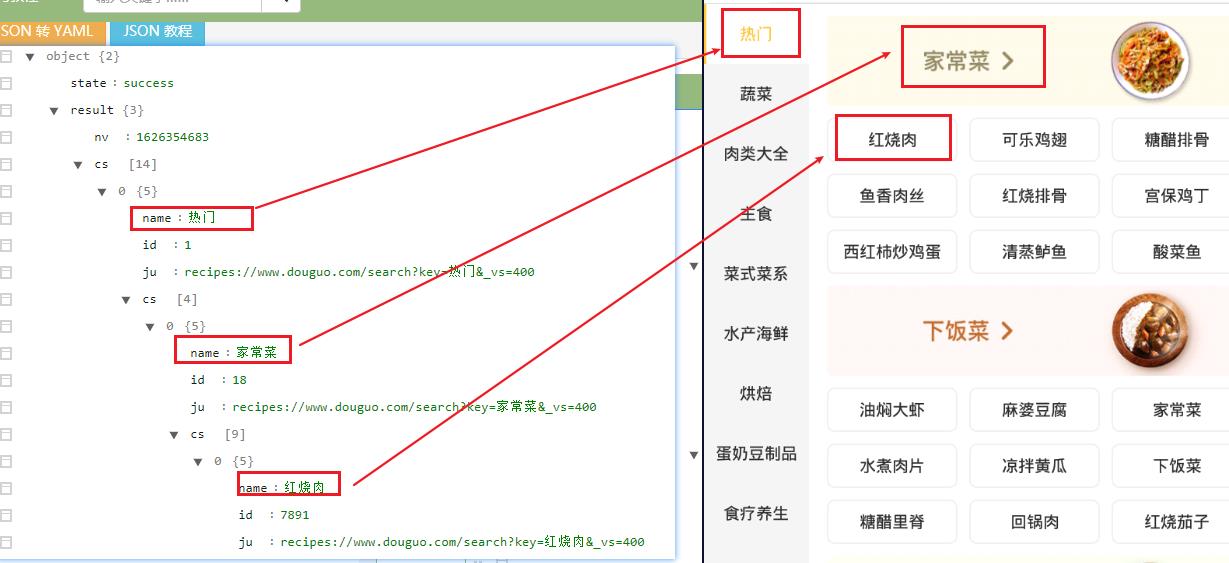
那我们就进入红烧肉吧😁,发现有三种排序的方式
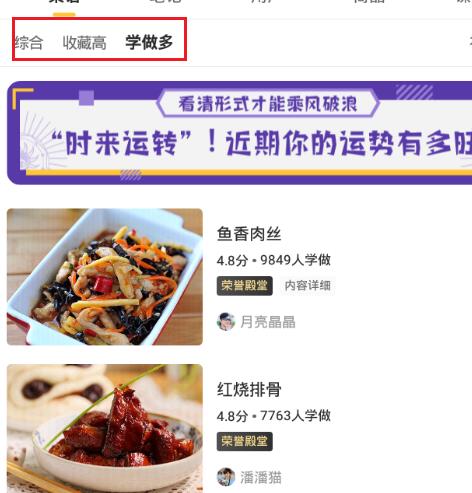
那我们在fiddler中可以发现三个对应的HTTPS请求
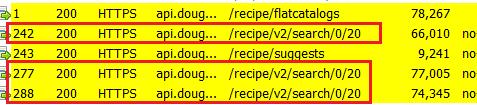
表面上看长得一摸一样,但三个都是POST请求,所以参数不同,根据我的实践,发现三种分类对应三个order字段的不同值

再来看看具体的JSON数据,可见是一一对应的
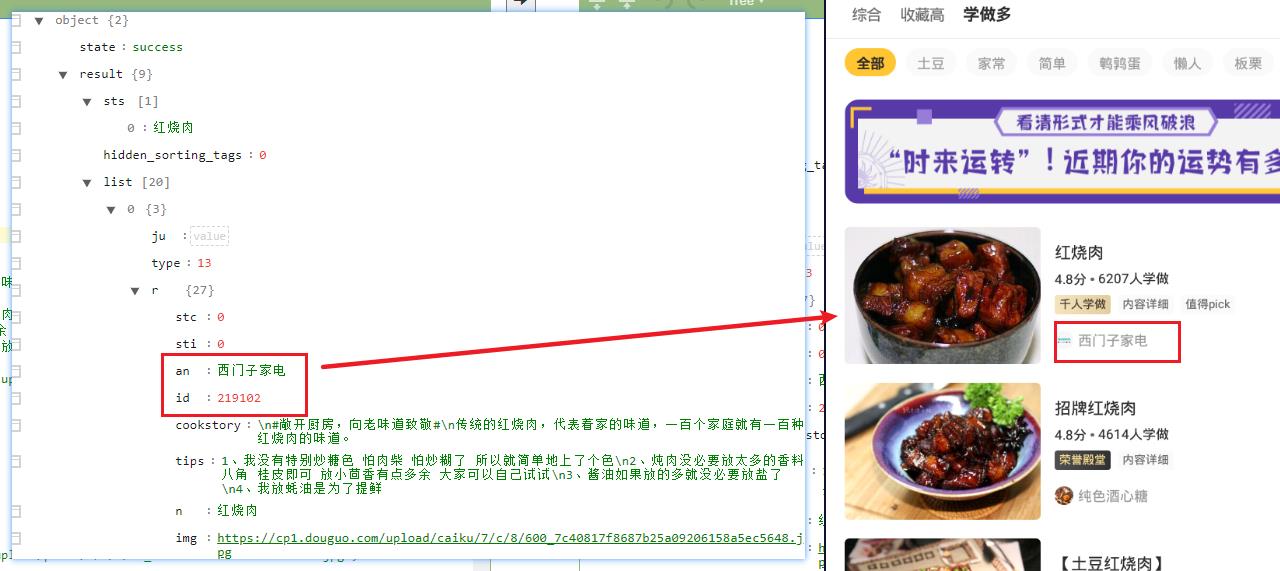
对应部分代码
caipu_list_url = "https://api.douguo.net/recipe/v2/search/0/20"
caipu_list_response = handle_request(url=caipu_list_url, data=data)
caipu_list_response_dict = json.loads(caipu_list_response.text)
然后的话还需要去请求详情页
请求路径中的数字就是上面得到的ID


对应部分代码
detail_url = "https://api.douguo.net/recipe/v2/detail/" + str(shicai_id)
detail_data = {
"client": "4",
"author_id": "0",
"_vs": "11104",
"_ext": '{"query":{"kw":' + str(
shicai) + ',"src":"11104","idx":"3","type":"13","id":' + str(
shicai_id) + '}}',
"is_new_user": "1",
}
detail_response = handle_request(detail_url, detail_data)
#解析为json格式
detail_response_dict = json.loads(detail_response.text)
完整代码
import requests
import json
import pymysql
from multiprocessing import Queue
# 创建队列
queue_list = Queue()
headers = {
"client": "4",
"version": "7008.2",
"device": "SM-G973N",
"sdk": "22,5.1.1",
"channel": "qqkp",
"resolution": "1280*720",
"display-resolution": "1280*720",
"dpi": "1.5",
"pseudo-id": "b2b0e205b84a6ca1",
"brand": "samsung",
"scale": "1.5",
"timezone": "28800",
"language": "zh",
"cns": "2",
"carrier": "CMCC",
"User-Agent": "Mozilla/5.0 (Linux; android 5.1.1; MI 9 Build/NMF26X; wv) AppleWebKit/537.36 (Khtml, like Gecko) Version/4.0 Chrome/74.0.3729.136 Mobile Safari/537.36",
"act-code": "1626316304",
"act-timestamp": "1626316305",
"uuid": "12697ae9-66dd-4071-94e5-778c10ce6dd1",
"battery-level": "1.00",
"battery-state": "3",
"bssid": "82:06:3A:49:9E:44",
"syscmp-time": "1619000613000",
"rom-version": "beyond1qlteue-user 5.1.1 PPR1.190810.011 500210421 release-keys",
"terms-accepted": "1",
"newbie": "1",
"reach": "1",
"app-state": "0",
"Content-Type": "application/x-www-form-urlencoded; charset=utf-8",
"Accept-Encoding": "gzip, deflate",
"Connection": "Keep-Alive",
"Host": "api.douguo.net",
}
sql = "insert into 表名称(shicai,user_name,caipu_name,describes,zuoliao_list,tips,cook_step) values(%s,%s,%s,%s,%s,%s,%s)"
def handle_request(url, data):
response = requests.post(url=url, headers=headers, data=data)
return response
# 请求首页
def handle_index():
url = "https://api.douguo.net/recipe/flatcatalogs"
data = {
"client": "4,",
"_vs": "0",
}
count = 0
response = handle_request(url, data)
# 转化为json格式
index_response_dict = json.loads(response.text)
for index_item in index_response_dict['result']['cs']:
for index_item_1 in index_item['cs']:
if count > 5:
return
for item in index_item_1['cs']:
item_data = {
"client": "4",
"keyword": item['name'],
"order": "3",
"_vs": "400",
}
queue_list.put(item_data)
count += 1
def handle_caipu_list(data):
print("当前处理的食材:", data['keyword'])
caipu_list_url = "https://api.douguo.net/recipe/v2/search/0/20"
caipu_list_response = handle_request(url=caipu_list_url, data=data)
caipu_list_response_dict = json.loads(caipu_list_response.text)
for item in caipu_list_response_dict['result']['list']:
shicai = data['keyword']
user_name = item['r']['an']
shicai_id = item['r']['id']
describes = item['r']['cookstory'].replace("\\n", "").replace(" ", "")
caipu_name = item['r']['n']
zuoliao_list = item['r']['major']
detail_url = "https://api.douguo.net/recipe/v2/detail/" + str(shicai_id)
detail_data = {
"client": "4",
"author_id": "0",
"_vs": "11104",
"_ext": '{"query":{"kw":' + str(
shicai) + ',"src":"11104","idx":"3","type":"13","id":' + str(
shicai_id) + '}}',
"is_new_user": "1",
}
detail_response = handle_request(detail_url, detail_data)
detail_response_dict = json.loads(detail_response.text)
tips = detail_response_dict['result']['recipe']['tips']
cook_step = detail_response_dict['result']['recipe']['cookstep']
print("当前入库的菜谱是:", caipu_name)
# 执行插入语句
cur.execute(sql, (shicai, user_name, caipu_name, describes, str(zuoliao_list), tips, str(cook_step)))
def init_mysql():
dbparams = {
'host': '127.0.0.1',
'port': 3306,
'user': '用户名',
'password': '密码',
'database': '数据库名称',
'charset': 'utf8'
}
conn = pymysql.connect(**dbparams)
cur = conn.cursor()
return conn, cur
def close_mysql(conn, cur):
cur.close()
conn.close()
if __name__ == '__main__':
# mysql初始化
conn, cur = init_mysql()
handle_index()
while queue_list.qsize() > 0:
handle_caipu_list(queue_list.get())
# 提交事务
conn.commit()
close_mysql(conn,cur)
爬取结果
代码测试,只爬取了部分


最后
我是 Code皮皮虾,一个热爱分享知识的 皮皮虾爱好者,未来的日子里会不断更新出对大家有益的博文,期待大家的关注!!!
创作不易,如果这篇博文对各位有帮助,希望各位小伙伴可以一键三连哦!,感谢支持,我们下次再见~~~
分享大纲
更多精彩内容分享,请点击 Hello World (●’◡’●)
本文爬虫源码已由 GitHub https://github.com/2335119327/PythonSpider 已经收录(内涵更多本博文没有的爬虫,有兴趣的小伙伴可以看看),之后会持续更新,欢迎Star。
以上是关于App爬虫之路:海量食谱数据爬取存储到Mysql!!!的主要内容,如果未能解决你的问题,请参考以下文章